O que é o Designer (v1) no Azure Machine Learning?
O designer do Azure Machine Learning é uma interface de arrastar e soltar usada para treinar e implantar modelos no estúdio do Azure Machine Learning. Este artigo descreve as tarefas que você pode fazer no designer.
Importante
O Designer no Azure Machine Learning dá suporte a dois tipos de pipelines que usam componentes clássicos pré-criados (v1) ou personalizados (v2). Os dois tipos de componentes não são compatíveis com pipelines e o designer v1 não é compatível com CLI v2 e SDK v2. Este artigo se aplica a pipelines que usam componentes pré-construídos clássicos (v1).
Os componentes pré-construídos clássicos (v1) incluem tarefas típicas de processamento de dados e aprendizado de máquina, como regressão e classificação. O Azure Machine Learning continua a dar suporte aos componentes pré-criados clássicos existentes, mas nenhum novo componente pré-criado está sendo adicionado. Além disso, a implantação de componentes pré-construídos clássicos (v1) não oferece suporte a pontos de extremidade online gerenciados (v2).
Os componentes personalizados (v2) permitem-lhe encapsular o seu próprio código como componentes, permitindo a partilha entre espaços de trabalho e a criação contínua nas interfaces do Azure Machine Learning studio, CLI v2 e SDK v2. É melhor usar componentes personalizados para novos projetos, porque eles são compatíveis com o Azure Machine Learning v2 e continuam a receber novas atualizações. Para obter mais informações sobre componentes personalizados e Designer (v2), consulte Azure Machine Learning designer (v2).
O GIF animado a seguir mostra como você pode criar um pipeline visualmente no Designer arrastando e soltando ativos e conectando-os.

Para saber mais sobre os componentes disponíveis no designer, consulte a Referência de algoritmo e componente. Para começar a usar o designer, consulte Tutorial: Treinar um modelo de regressão sem código.
Treinamento e implantação de modelos
O designer usa seu espaço de trabalho do Azure Machine Learning para organizar recursos compartilhados, como:
- Pipelines
- Dados
- Recursos computacionais
- Modelos registados
- Trabalhos de pipeline publicados
- Pontos finais em tempo real
O diagrama a seguir ilustra como você pode usar o designer para criar um fluxo de trabalho de aprendizado de máquina de ponta a ponta. Você pode treinar, testar e implantar modelos, tudo na interface do designer.
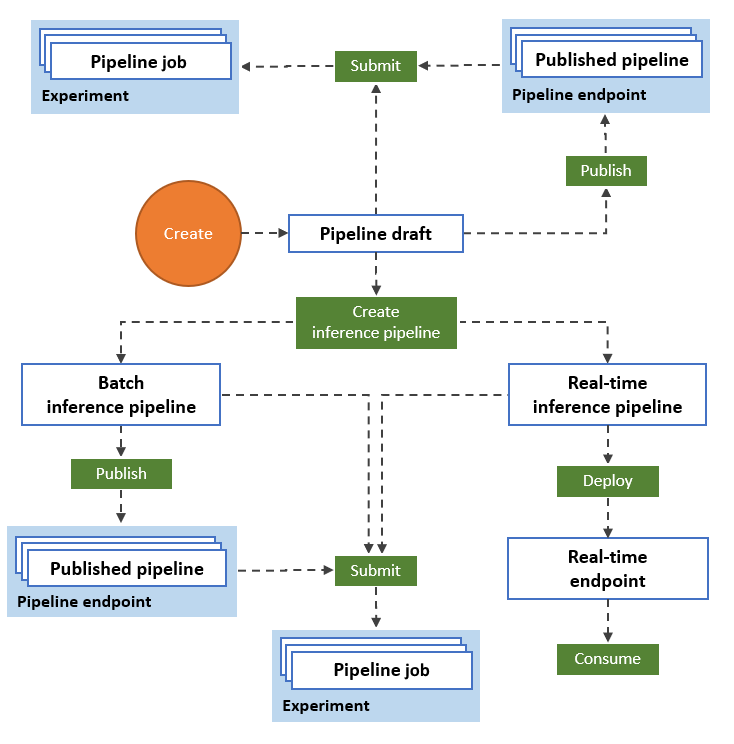
- Arraste e solte ativos de dados e componentes na tela visual do designer e conecte os componentes para criar um rascunho de pipeline.
- Envie um trabalho de pipeline que use os recursos de computação em seu espaço de trabalho do Azure Machine Learning.
- Converta seus pipelines de treinamento em pipelines de inferência.
- Publique seus pipelines em um ponto de extremidade de pipeline REST para enviar novos pipelines que são executados com parâmetros e ativos de dados diferentes.
- Publique um pipeline de treinamento para reutilizar um único pipeline para treinar vários modelos enquanto altera parâmetros e ativos de dados.
- Publique um pipeline de inferência em lote para fazer previsões sobre novos dados usando um modelo treinado anteriormente.
- Implante um pipeline de inferência em tempo real em um endpoint online para fazer previsões sobre novos dados em tempo real.
Dados
Um ativo de dados de aprendizado de máquina facilita o acesso e o trabalho com seus dados. O designer inclui vários ativos de dados de exemplo para você experimentar. Você pode registrar mais ativos de dados conforme necessário.
Componentes
Um componente é um algoritmo que você pode executar em seus dados. O estruturador tem vários componentes desde funções de entrada de dados a processos de preparação, classificação e validação.
Um componente pode ter parâmetros que você usa para configurar os algoritmos internos do componente. Quando você seleciona um componente na tela, os parâmetros do componente e outras configurações são exibidos em um painel de propriedades à direita da tela. Você pode modificar os parâmetros e definir os recursos de computação para componentes individuais nesse painel.
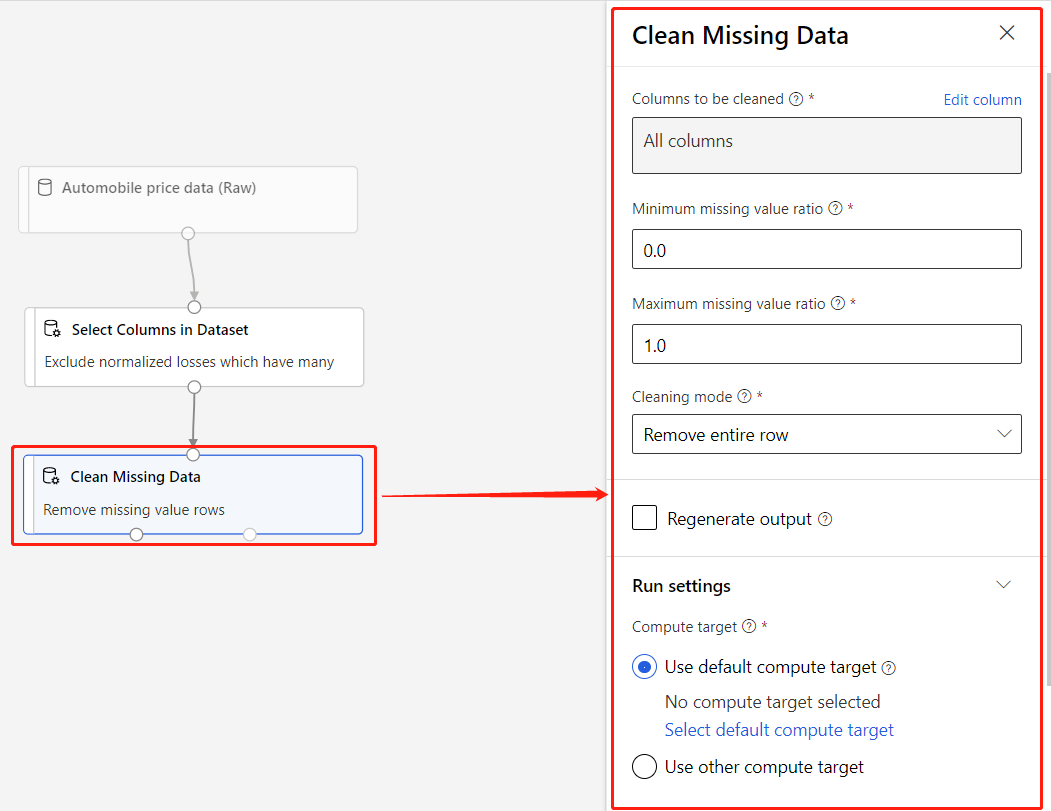
Para obter mais informações sobre a biblioteca de algoritmos de aprendizado de máquina disponíveis, consulte a Referência de algoritmo e componente. Para obter ajuda com a escolha de um algoritmo, consulte o Azure Machine Learning Algorithm Cheat Sheet.
Pipelines
Um pipeline consiste em ativos de dados e componentes analíticos que você conecta. Os pipelines ajudam-no a reutilizar o seu trabalho e a organizar os seus projetos.
Os gasodutos têm muitas utilizações. Você pode criar pipelines que:
- Treine um único modelo.
- Treine vários modelos.
- Faça previsões em tempo real ou em lote.
- Limpe apenas os dados.
Rascunhos de gasodutos
À medida que você edita um pipeline no designer, seu progresso é salvo como um rascunho de pipeline. Você pode editar um rascunho de pipeline a qualquer momento adicionando ou removendo componentes, configurando destinos de computação ou definindo parâmetros.
Um pipeline válido tem as seguintes características:
- Os ativos de dados podem se conectar apenas a componentes.
- Os componentes podem se conectar somente a ativos de dados ou a outros componentes.
- Todas as portas de entrada para componentes devem ter alguma conexão com o fluxo de dados.
- Todos os parâmetros necessários para cada componente devem ser definidos.
Quando estiver pronto para executar o rascunho do pipeline, salve o pipeline e envie um trabalho de pipeline.
Trabalhos em pipeline
Cada vez que você executa um pipeline, a configuração do pipeline e seus resultados são armazenados em seu espaço de trabalho como um trabalho de pipeline. Os trabalhos de pipeline são agrupados em experimentos para organizar o histórico de trabalhos.
Você pode voltar a qualquer trabalho de pipeline para inspecioná-lo para solução de problemas ou auditoria. Clone um trabalho de pipeline para criar um novo rascunho de pipeline para editar.
Recursos de computação
Os destinos de computação são anexados ao seu espaço de trabalho do Azure Machine Learning no estúdio do Azure Machine Learning. Use recursos de computação do seu espaço de trabalho para executar seu pipeline e hospedar seus modelos implantados como pontos de extremidade online ou como pontos de extremidade de pipeline para inferência em lote. Os destinos de computação suportados são os seguintes:
| Destino de computação | Formação | Implementação |
|---|---|---|
| Computação do Azure Machine Learning | ✓ | |
| Azure Kubernetes Service (AKS) | ✓ |
Implementar
Para fazer inferências em tempo real, você deve implantar um pipeline como um ponto de extremidade online. O ponto de extremidade online cria uma interface entre um aplicativo externo e seu modelo de pontuação. O endpoint é baseado em REST, uma escolha de arquitetura popular para projetos de programação web. Uma chamada para um ponto de extremidade online retorna os resultados da previsão para o aplicativo em tempo real.
Para fazer uma chamada para um ponto de extremidade online, passe a chave de API que foi criada quando você implantou o ponto de extremidade. Os pontos de extremidade online devem ser implantados em um cluster AKS. Para saber como implantar seu modelo, consulte Tutorial: Implantar um modelo de aprendizado de máquina com o designer.
Publicar
Você também pode publicar um pipeline em um ponto de extremidade de pipeline. Semelhante a um ponto de extremidade online, um ponto de extremidade de pipeline permite enviar novos trabalhos de pipeline de aplicativos externos usando chamadas REST. No entanto, você não pode enviar ou receber dados em tempo real usando um ponto de extremidade de pipeline.
Os pontos de extremidade de pipeline publicados são flexíveis e podem ser usados para treinar ou treinar novamente modelos, fazer inferência em lote ou processar novos dados. Você pode publicar vários pipelines em um único ponto de extremidade de pipeline e especificar qual versão de pipeline deve ser executada.
Um pipeline publicado é executado nos recursos de computação definidos no rascunho do pipeline para cada componente. O designer cria o mesmo objeto PublishedPipeline que o SDK.
Conteúdos relacionados
- Aprenda os fundamentos da análise preditiva e do aprendizado de máquina com o Tutorial: Preveja o preço do automóvel com o designer.
- Saiba como modificar amostras de designer existentes para adaptá-las às suas necessidades.