Extrair recursos de N-Gram da referência do componente Texto
Este artigo descreve um componente no designer do Azure Machine Learning. Use o componente Extrair recursos N-Gram do texto para featurizar dados de texto não estruturados.
Configuração do componente Extrair recursos N-Gram do texto
O componente suporta os seguintes cenários para usar um dicionário de n-gramas:
Crie um novo dicionário de n-gramas a partir de uma coluna de texto livre.
Use um conjunto existente de recursos de texto para criar uma coluna de texto livre.
Pontuar ou implantar um modelo que usa n-gramas.
Criar um novo dicionário de n-gramas
Adicione o componente Extrair recursos N-Gram do texto ao seu pipeline e conecte o conjunto de dados que tem o texto que você deseja processar.
Use a coluna Texto para escolher uma coluna do tipo cadeia de caracteres que contenha o texto que você deseja extrair. Como os resultados são detalhados, você pode processar apenas uma única coluna de cada vez.
Defina o modo Vocabulário como Criar para indicar que está a criar uma nova lista de funcionalidades de n-gramas.
Defina o tamanho de N-gramas para indicar o tamanho máximo dos n-gramas a extrair e armazenar.
Por exemplo, se você inserir 3, unigramas, bigramas e trigramas serão criados.
A função de ponderação especifica como criar o vetor de recurso de documento e como extrair vocabulário de documentos.
Peso binário: atribui um valor de presença binário aos n-gramas extraídos. O valor para cada n-grama é 1 quando existe no documento e 0 caso contrário.
Peso TF: Atribui uma pontuação de frequência de termo (TF) aos n-gramas extraídos. O valor para cada n-grama é a sua frequência de ocorrência no documento.
Peso IDF: Atribui uma pontuação de frequência de documento inversa (IDF) aos n-gramas extraídos. O valor de cada n-grama é o log do tamanho do corpus dividido pela sua frequência de ocorrência em todo o corpus.
IDF = log of corpus_size / document_frequencyPeso TF-IDF: Atribui uma pontuação de frequência de termo / frequência de documento inverso (TF/IDF) aos n-gramas extraídos. O valor para cada n-grama é a sua pontuação TF multiplicada pela sua pontuação IDF.
Defina Comprimento mínimo da palavra para o número mínimo de letras que podem ser usadas em qualquer palavra em um n-grama.
Use Comprimento máximo da palavra para definir o número máximo de letras que podem ser usadas em qualquer palavra em um n-grama.
Por padrão, são permitidos até 25 caracteres por palavra ou token.
Use a frequência absoluta mínima do documento de n-gramas para definir as ocorrências mínimas necessárias para que qualquer n-grama seja incluído no dicionário de n-gramas.
Por exemplo, se você usar o valor padrão de 5, qualquer n-grama deve aparecer pelo menos cinco vezes no corpus para ser incluído no dicionário de n-gramas.
Defina Rácio máximo de documentos de n-gramas para o rácio máximo do número de linhas que contêm um n-grama específico, sobre o número de linhas no corpus global.
Por exemplo, uma proporção de 1 indicaria que, mesmo que um n-grama específico esteja presente em cada linha, o n-grama pode ser adicionado ao dicionário de n-gramas. Mais tipicamente, uma palavra que ocorre em todas as fileiras seria considerada uma palavra de ruído e seria removida. Para filtrar palavras de ruído dependentes do domínio, tente reduzir essa proporção.
Importante
A taxa de ocorrência de determinadas palavras não é uniforme. Varia de documento para documento. Por exemplo, se você estiver analisando comentários de clientes sobre um produto específico, o nome do produto pode ser muito freqüente e próximo de uma palavra de ruído, mas ser um termo significativo em outros contextos.
Selecione a opção Normalizar vetores de recurso de n-grama para normalizar os vetores de recurso. Se essa opção estiver ativada, cada vetor de recurso de n-grama será dividido por sua norma L2.
Envie o pipeline.
Usar um dicionário de n-gramas existente
Adicione o componente Extrair recursos N-Gram do texto ao seu pipeline e conecte o conjunto de dados que tem o texto que você deseja processar à porta do conjunto de dados.
Use a coluna Texto para selecionar a coluna de texto que contém o texto que você deseja featurizar. Por padrão, o componente seleciona todas as colunas do tipo string. Para obter melhores resultados, processe uma única coluna de cada vez.
Adicione o conjunto de dados salvo que contém um dicionário de n-gramas gerado anteriormente e conecte-o à porta de vocabulário de entrada. Você também pode conectar a saída de vocabulário Resultado de uma instância upstream do componente Extrair recursos de N-Gramas do texto.
Para o modo Vocabulário, selecione a opção Atualização somente leitura na lista suspensa.
A opção ReadOnly representa o corpus de entrada para o vocabulário de entrada. Em vez de calcular as frequências dos termos a partir do novo conjunto de dados de texto (na entrada esquerda), os pesos de n-gramas do vocabulário de entrada são aplicados como estão.
Gorjeta
Use esta opção quando estiver marcando um classificador de texto.
Para todas as outras opções, consulte as descrições das propriedades na seção anterior.
Envie o pipeline.
Crie um pipeline de inferência que usa n-gramas para implantar um ponto de extremidade em tempo real
Um pipeline de treinamento que contém o recurso Extrair N-Gramas do Modelo de Texto e Pontuação para fazer previsão no conjunto de dados de teste é construído na seguinte estrutura:
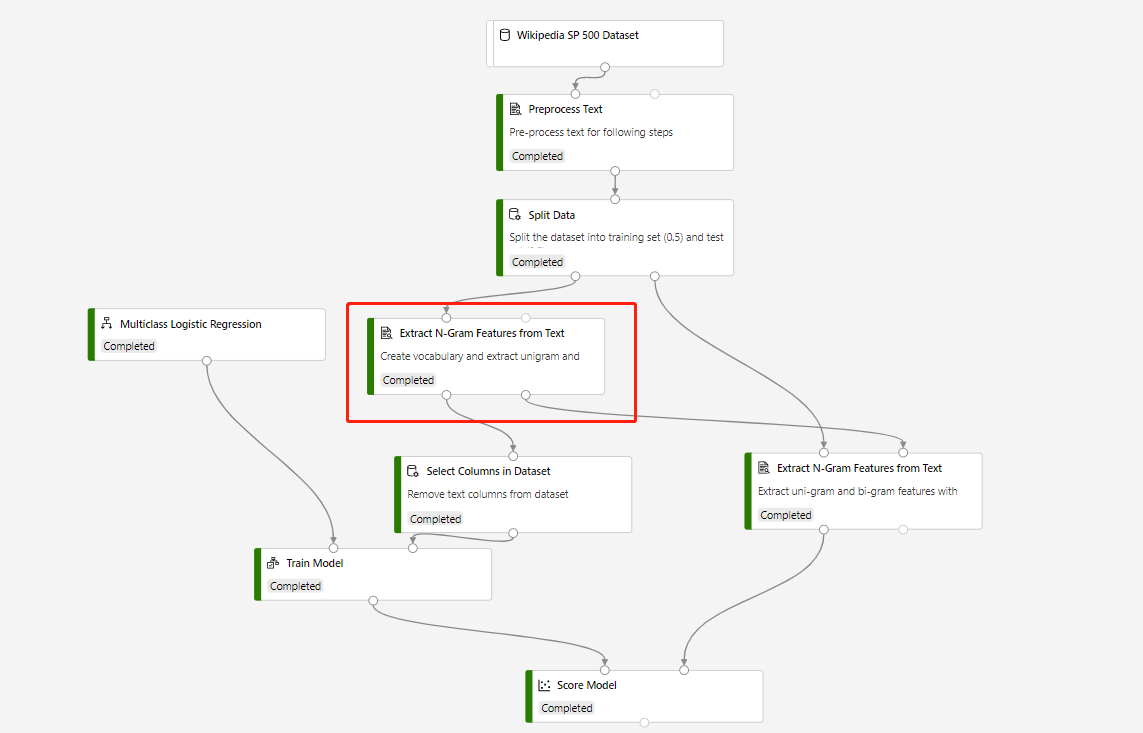
O modo de vocabulário do componente circular Extrair N-Gramas do componente de texto é Criar e o modo de vocabulário do componente que se conecta ao componente Modelo de pontuação é Somente leitura.
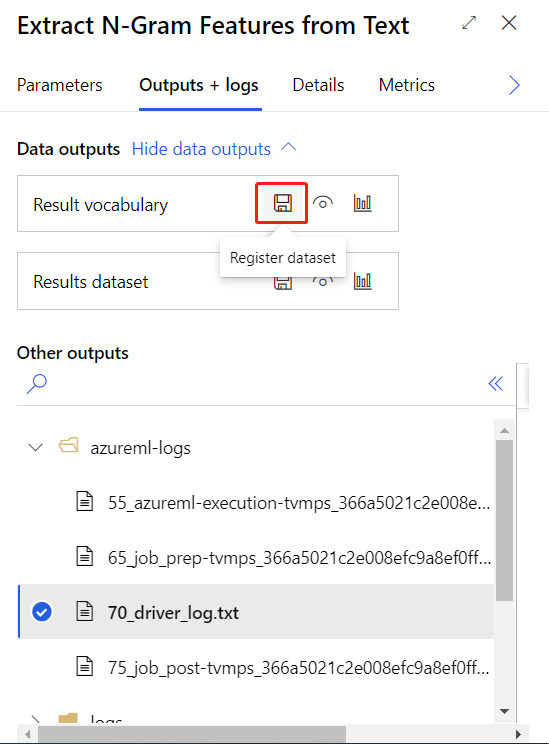
Depois de enviar o pipeline de treinamento acima com êxito, você pode registrar a saída do componente circulado como conjunto de dados.
Em seguida, você pode criar pipeline de inferência em tempo real. Depois de criar o pipeline de inferência, você precisa ajustar seu pipeline de inferência manualmente, da seguinte forma:
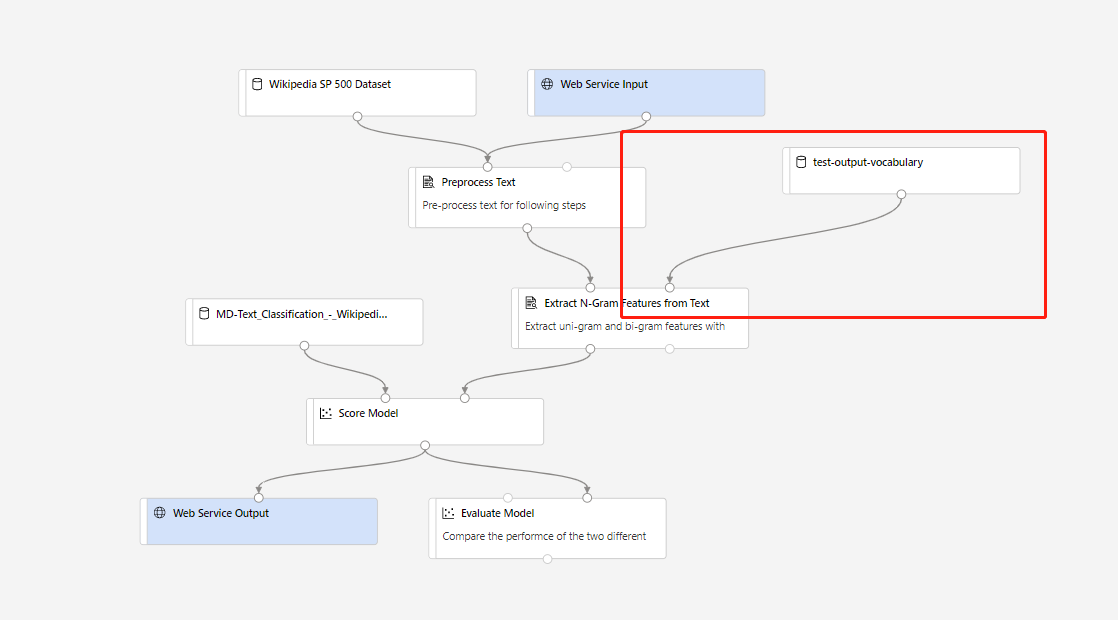
Em seguida, envie o pipeline de inferência e implante um ponto de extremidade em tempo real.
Resultados
O componente Extrair recursos N-Gram do texto cria dois tipos de saída:
Conjunto de dados de resultados: Esta saída é um resumo do texto analisado combinado com os n-gramas que foram extraídos. As colunas que você não selecionou na opção Coluna de texto são passadas para a saída. Para cada coluna de texto analisada, o componente gera estas colunas:
- Matriz de ocorrências de n-gramas: O componente gera uma coluna para cada n-grama encontrado no corpus total e adiciona uma pontuação em cada coluna para indicar o peso do n-grama para essa linha.
Vocabulário de resultados: O vocabulário contém o dicionário de n-gramas real, juntamente com os escores de frequência do termo que são gerados como parte da análise. Você pode salvar o conjunto de dados para reutilização com um conjunto diferente de entradas ou para uma atualização posterior. Você também pode reutilizar o vocabulário para modelagem e pontuação.
Vocabulário dos resultados
O vocabulário contém o dicionário n-grama com os escores de frequência do termo que são gerados como parte da análise. As pontuações DF e IDF são geradas independentemente de outras opções.
- ID: Um identificador gerado para cada n-grama exclusivo.
- NGram: O n-grama. Os espaços ou outros separadores de palavras são substituídos pelo caractere sublinhado.
- DF: Pontuação de frequência do termo n-grama no corpus original.
- IDF: A pontuação de frequência inversa do documento para o n-grama no corpus original.
Você pode atualizar manualmente esse conjunto de dados, mas pode introduzir erros. Por exemplo:
- Um erro é gerado se o componente encontrar linhas duplicadas com a mesma chave no vocabulário de entrada. Certifique-se de que não há duas linhas no vocabulário com a mesma palavra.
- O esquema de entrada dos conjuntos de dados de vocabulário deve corresponder exatamente, incluindo nomes e tipos de coluna.
- A coluna ID e a coluna DF devem ser do tipo inteiro.
- A coluna IDF deve ser do tipo float.
Nota
Não conecte a saída de dados diretamente ao componente Train Model. Você deve remover colunas de texto livre antes que elas sejam inseridas no Modelo de trem. Caso contrário, as colunas de texto livre serão tratadas como características categóricas.
Próximos passos
Consulte o conjunto de componentes disponíveis para o Azure Machine Learning.