Implantações de várias regiões para recuperação de desastres nos Aplicativos Lógicos do Azure
Este artigo fornece orientações e estratégias sobre como configurar uma implantação de várias regiões para seus fluxos de trabalho de aplicativos lógicos nos Aplicativos Lógicos do Azure. Uma implantação em várias regiões ajuda a proteger dados, recuperar rapidamente de desastres e outros eventos causadores de interrupções, restaurar recursos exigidos por funções críticas de negócios e manter a continuidade dos negócios.
Para obter mais informações sobre os recursos de confiabilidade nos Aplicativos Lógicos do Azure, incluindo resiliência intrarregional por meio de zonas de disponibilidade, consulte Confiabilidade em Aplicativos Lógicos do Azure.
Considerações
Os fluxos de trabalho de aplicativos lógicos ajudam você a integrar e orquestrar dados mais facilmente entre aplicativos, serviços de nuvem e sistemas locais, reduzindo a quantidade de código que você precisa escrever. Ao planejar redundância em várias regiões, certifique-se de considerar não apenas seus aplicativos lógicos, mas também estes recursos do Azure que você usa com seus aplicativos lógicos:
Conexões que você cria a partir de fluxos de trabalho de aplicativos lógicos para outros aplicativos, serviços e sistemas. Para obter mais informações, consulte Conexões com recursos posteriormente neste tópico.
Gateways de dados locais, que são recursos do Azure que você cria e usa em seus aplicativos lógicos para acessar dados em sistemas locais. Cada recurso de gateway representa uma instalação de gateway de dados separada em um computador local. Para obter mais informações, consulte Gateways de dados locais mais adiante neste tópico.
Contas de integração onde você define e armazena os artefatos que os aplicativos lógicos usam para cenários de integração empresarial B2B (business-to-business). Por exemplo, você pode configurar a recuperação de desastres entre regiões para contas de integração.
Para obter mais informações sobre confiabilidade em Aplicativos Lógicos do Azure, incluindo resiliência intrarregional por meio de zonas de disponibilidade e implantações de várias regiões, consulte Confiabilidade em Aplicativos Lógicos do Azure.
Implantação primária e secundária
Uma implantação de várias regiões consiste em um aplicativo lógico primário e secundário. O aplicativo lógico primário está configurado para failover para o aplicativo lógico secundário em outra região onde os Aplicativos Lógicos do Azure também estão disponíveis. Dessa forma, se o primário sofrer perdas, interrupções ou falhas, o secundário pode assumir o trabalho. Essa estratégia de implantação requer que seu aplicativo lógico secundário e os recursos dependentes já estejam implantados e prontos na região secundária.
Nota
Se seu aplicativo lógico também funciona com artefatos B2B, como parceiros comerciais, contratos, esquemas, mapas e certificados, que são armazenados em uma conta de integração, sua conta de integração e aplicativos lógicos devem usar o mesmo local.
Se você seguir boas práticas de DevOps, já usará modelos do Bicep ou do Azure Resource Manager para definir e implantar seus aplicativos lógicos e seus recursos dependentes. Os modelos Bicep e Resource Manager oferecem a capacidade de usar uma única definição de implantação e, em seguida, usar arquivos de parâmetro para fornecer os valores de configuração a serem usados para cada destino de implantação. Esse recurso significa que você pode implantar o mesmo aplicativo lógico em ambientes diferentes, por exemplo, desenvolvimento, teste e produção. Você também pode implantar o mesmo aplicativo lógico em diferentes regiões do Azure, que dão suporte a implantações de várias regiões, como para estratégias de recuperação de desastres.
Para que o failover seja bem-sucedido, seus aplicativos lógicos e locais devem atender a estes requisitos:
A instância secundária do aplicativo lógico tem acesso aos mesmos aplicativos, serviços e sistemas que a instância do aplicativo lógico principal.
Ambas as instâncias do aplicativo lógico têm o mesmo tipo de host. Portanto, ambas as instâncias são implantadas em regiões em Aplicativos Lógicos do Azure multilocatários globais ou regiões em Aplicativos Lógicos do Azure de locatário único. Para obter práticas recomendadas e mais informações sobre como usar várias regiões para continuidade de negócios e recuperação de desastres (BC/DR), consulte Replicação entre regiões no Azure: continuidade de negócios e recuperação de desastres.
Exemplo: Azure multilocatário
Este exemplo mostra instâncias de aplicativo lógico primário e secundário, que são implantadas em regiões separadas no Azure multilocatário global. Um único modelo do Gerenciador de Recursos define as instâncias do aplicativo lógico e os recursos dependentes exigidos por esses aplicativos lógicos. Arquivos de parâmetros separados especificam os valores de configuração a serem usados para cada local de implantação:
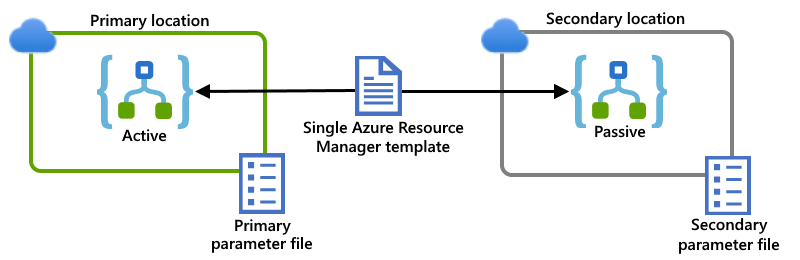
Ligações a recursos
Os Aplicativos Lógicos do Azure fornecem operações para mais de 1.000 conectores que seu fluxo de trabalho de aplicativo lógico pode usar para trabalhar com outros aplicativos, serviços, sistemas e outros recursos, como contas de Armazenamento do Azure, bancos de dados do SQL Server, contas de email corporativas ou escolares e assim por diante. Se seu aplicativo lógico precisar de acesso a esses recursos, você criará conexões que autenticam o acesso a esses recursos. Cada conexão é um recurso do Azure separado que existe em um local específico e não pode ser usado por recursos em outros locais.
Para sua estratégia de redundância de várias regiões, considere os locais onde existem recursos dependentes em relação às instâncias do aplicativo lógico:
Sua instância principal e recursos dependentes existem em locais diferentes. Nesse caso, sua instância secundária pode se conectar aos mesmos recursos ou pontos de extremidade dependentes. No entanto, você deve criar conexões especificamente para sua instância secundária. Dessa forma, se o local principal ficar indisponível, as conexões do secundário não serão afetadas.
Por exemplo, suponha que seu aplicativo lógico principal se conecte a um serviço externo, como o Salesforce. Normalmente, a disponibilidade e a localização do serviço externo são independentes da disponibilidade do seu aplicativo lógico. Nesse caso, sua instância secundária pode se conectar ao mesmo serviço, mas deve ter sua própria conexão na região secundária.
A instância principal e os recursos dependentes existem no mesmo local. Nesse caso, os recursos dependentes devem ter backups ou versões replicadas em um local diferente para que sua instância secundária ainda possa acessar esses recursos.
Por exemplo, suponha que seu aplicativo lógico principal se conecte a um serviço que esteja no mesmo local ou região, por exemplo, o Banco de Dados SQL do Azure. Se toda essa região ficar indisponível, o serviço Banco de Dados SQL do Azure nessa região também provavelmente não estará disponível. Nesse caso, você desejaria que sua instância secundária usasse um banco de dados replicado ou de backup na região secundária, juntamente com uma conexão separada com esse banco de dados que também está localizado na região secundária.
Gateways de dados no local
Se seu aplicativo lógico for executado no Azure multilocatário e precisar de acesso a recursos locais, como bancos de dados do SQL Server, você precisará instalar o gateway de dados local em um computador local. Em seguida, você pode criar um recurso de gateway de dados no portal do Azure para que seu aplicativo lógico possa usar o gateway ao criar uma conexão com o recurso.
O recurso de gateway de dados está associado a um local ou região do Azure, assim como seu recurso de aplicativo lógico. Em sua estratégia de redundância de várias regiões, certifique-se de que o gateway de dados permaneça disponível para seu aplicativo lógico usar. Você pode habilitar a alta disponibilidade para seu gateway quando tiver várias instalações de gateway.
Funções ativo-ativo vs. ativo-passivo
Você pode configurar seus locais primários e secundários para que as instâncias do aplicativo lógico nesses locais possam desempenhar estas funções:
| Papel primário-secundário | Description |
|---|---|
| Ativo-ativo | As instâncias do aplicativo lógico primário e secundário em ambos os locais lidam ativamente com solicitações seguindo um destes padrões: - Balanceamento de carga: você pode fazer com que ambas as instâncias escutem um ponto de extremidade e o tráfego de balanceamento de carga para cada instância, conforme necessário. - Consumidores concorrentes: você pode fazer com que ambas as instâncias atuem como consumidores concorrentes para que as instâncias compitam por mensagens de uma fila. Se uma instância falhar, a outra instância assumirá a carga de trabalho. |
| Ativo-passivo | A instância do aplicativo lógico primário lida ativamente com toda a carga de trabalho, enquanto a instância secundária é passiva (desabilitada ou inativa). O secundário aguarda um sinal de que o primário está indisponível ou não está funcionando devido a interrupção ou falha e assume a carga de trabalho como a instância ativa. |
| Combinação | Alguns aplicativos lógicos desempenham um papel ativo-ativo, enquanto outros aplicativos lógicos desempenham um papel ativo-passivo. |
Exemplos ativos-ativos
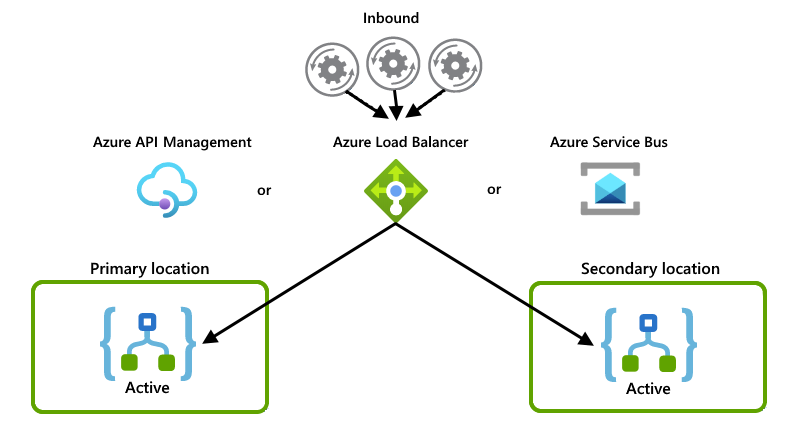
Estes exemplos mostram a configuração ativa-ativa em que ambas as instâncias do aplicativo lógico lidam ativamente com solicitações ou mensagens. Algum outro sistema ou serviço distribui as solicitações ou mensagens entre instâncias, por exemplo, uma destas opções:
Um balanceador de carga "físico", como uma peça de hardware que roteia o tráfego
Um balanceador de carga "suave", como o Azure Load Balancer ou o Azure API Management. Com o Gerenciamento de API, você pode especificar políticas que determinam como balancear a carga do tráfego de entrada. Ou, você pode usar um serviço que dá suporte ao rastreamento de estado, por exemplo, o Barramento de Serviço do Azure.
Embora este exemplo mostre principalmente o Azure Load Balancer, você pode usar a opção que melhor atende às necessidades do seu cenário:
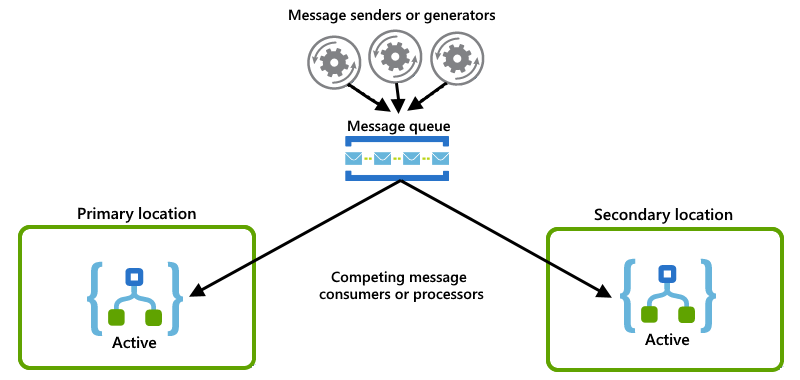
Cada instância do aplicativo lógico atua como um consumidor e faz com que ambas as instâncias compitam por mensagens de uma fila:
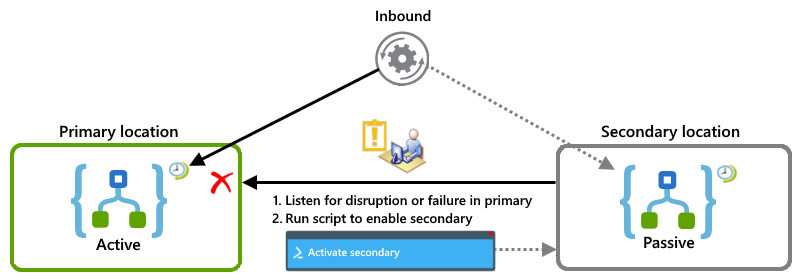
Exemplos ativo-passivo
Este exemplo mostra a configuração ativo-passivo em que a instância do aplicativo lógico primário está ativa em um local, enquanto a instância secundária permanece inativa em outro local. Se o primário sofrer uma interrupção ou falha, você poderá fazer com que um operador execute um script que ative o secundário para assumir a carga de trabalho.
Combinação com ativo-ativo e ativo-passivo
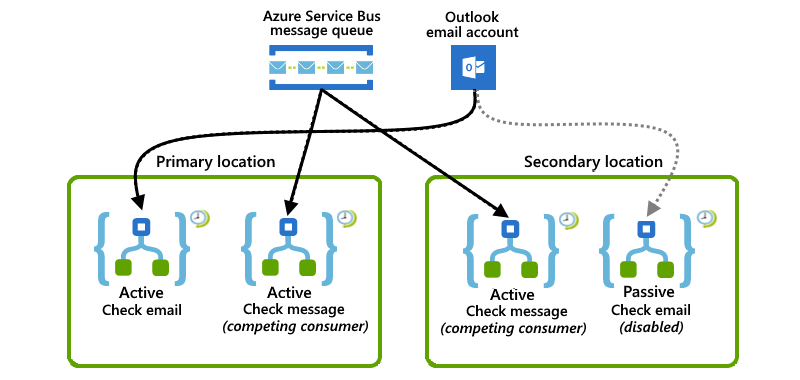
Este exemplo mostra uma configuração combinada em que o local primário tem ambas as instâncias ativas do aplicativo lógico, enquanto o local secundário tem instâncias do aplicativo lógico ativo-passivo. Se o local principal sofrer uma interrupção ou falha, o aplicativo lógico ativo no local secundário, que já está lidando com uma carga de trabalho parcial, poderá assumir toda a carga de trabalho.
No local principal, um aplicativo lógico ativo escuta uma fila do Barramento de Serviço do Azure em busca de mensagens, enquanto outro aplicativo lógico ativo verifica se há emails usando um gatilho de sondagem do Office 365 Outlook.
No local secundário, um aplicativo lógico ativo funciona com o aplicativo lógico no local principal ouvindo e competindo por mensagens da mesma fila do Service Bus. Enquanto isso, um aplicativo lógico inativo passivo aguarda em espera para verificar se há e-mails quando o local principal fica indisponível, mas é desativado para evitar a releitura de e-mails.
Estado e histórico do aplicativo lógico
Quando seu aplicativo lógico é acionado e começa a ser executado, o estado do aplicativo é armazenado no mesmo local onde o aplicativo foi iniciado e é intransferível para outro local. Se ocorrer uma falha ou interrupção, todas as instâncias de fluxo de trabalho em andamento serão abandonadas. Quando você tem um local primário e secundário configurado, novas instâncias de fluxo de trabalho começam a ser executadas no local secundário.
Reduzir instâncias em andamento abandonadas
Para minimizar o número de instâncias de fluxo de trabalho em andamento abandonadas, você pode escolher entre vários padrões de mensagem que pode implementar, por exemplo:
Padrão de deslizamento de roteamento fixo
Esse padrão de mensagem empresarial que divide um processo de negócios em estágios menores. Para cada estágio, você configura um aplicativo lógico que lida com a carga de trabalho para esse estágio. Para se comunicar entre si, seus aplicativos lógicos usam um protocolo de mensagens assíncrono, como filas ou tópicos do Barramento de Serviço do Azure. Ao dividir um processo em estágios menores, você reduz o número de processos de negócios que podem ficar presos em uma instância de aplicativo lógico com falha. Para obter mais informações gerais sobre esse padrão, consulte Padrões de integração empresarial - Guia de roteamento.
Este exemplo mostra um padrão de guia de roteamento em que cada aplicativo lógico representa um estágio e usa uma fila do Service Bus para se comunicar com o próximo aplicativo lógico no processo.
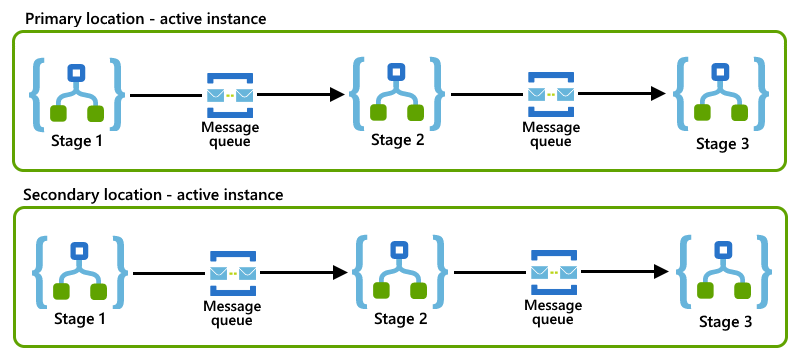
Se as instâncias do aplicativo lógico primário e secundário seguirem o mesmo padrão de guia de roteamento em seus locais, você poderá implementar o padrão de consumidores concorrentes configurando funções ativas-ativas para essas instâncias.
Acesso ao histórico de acionamento e execução
Para obter mais informações sobre as execuções de fluxo de trabalho anteriores do seu aplicativo lógico, você pode revisar o gatilho e o histórico de execuções do aplicativo. O histórico de execução de um aplicativo lógico é armazenado no mesmo local ou região onde esse aplicativo lógico foi executado, o que significa que você não pode migrar esse histórico para um local diferente. Se sua instância principal fizer failover para uma instância secundária, você só poderá acessar o gatilho de cada instância e executar o histórico nos respetivos locais onde essas instâncias foram executadas. No entanto, você pode obter informações independentes de localização sobre o histórico do seu aplicativo lógico configurando seus aplicativos lógicos para enviar eventos de diagnóstico para um espaço de trabalho do Azure Log Analytics. Em seguida, você pode revisar a integridade e o histórico em aplicativos lógicos executados em vários locais.
Orientação do tipo de gatilho
O tipo de gatilho que você usa em seus aplicativos lógicos determina suas opções de como você pode configurar aplicativos lógicos em vários locais em uma estratégia de recuperação de desastres. Aqui estão os tipos de gatilho disponíveis que você pode usar em fluxos de trabalho de aplicativos lógicos:
Acionador de periodicidade
O gatilho de recorrência é independente de qualquer serviço ou ponto de extremidade específico e é acionado apenas com base em um cronograma especificado e sem outros critérios, por exemplo:
- Uma frequência e um intervalo fixos, como a cada 10 minutos
- Um horário mais avançado, como a última segunda-feira de cada mês, às 17h00
Quando seu aplicativo lógico começa com um gatilho de Recorrência, você precisa configurar suas instâncias de aplicativo lógico primário e secundário com as funções ativo-passivo. Para reduzir o RTO (Recovery Time Objetive, objetivo de tempo de recuperação), que se refere à duração do destino para restaurar um processo de negócios após uma interrupção ou desastre, você pode configurar as instâncias do aplicativo lógico com uma combinação de funções ativas-passivas e passivas-ativas. Nessa configuração, você divide a agenda entre os locais.
Por exemplo, suponha que você tenha um aplicativo lógico que precisa ser executado a cada 10 minutos. Você pode configurar seus aplicativos lógicos e locais para que, se o local principal ficar indisponível, o local secundário possa assumir o trabalho:
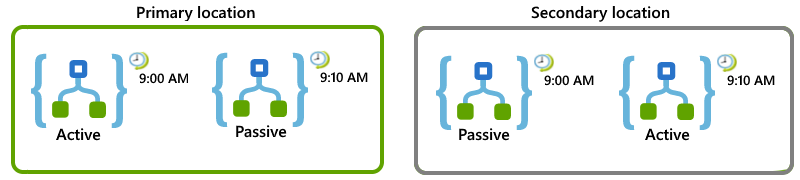
No local principal, configure funções ativas-passivas para estes aplicativos lógicos:
Para o aplicativo lógico ativado ativado, defina o gatilho Recorrência para começar na parte superior da hora e repetir a cada 20 minutos, por exemplo, 9h00, 9h20 e assim por diante.
Para o aplicativo de lógica passiva desabilitada, defina o gatilho de Recorrência para a mesma programação, mas comece aos 10 minutos após a hora e repita a cada 20 minutos, por exemplo, 9h10, 9h30 e assim por diante.
No local secundário, configure passivo-ativo para estes aplicativos lógicos:
Para o aplicativo lógico desativado passivo , defina o gatilho de Recorrência com a mesma programação do aplicativo lógico ativo no local principal, que está no topo da hora e se repete a cada 20 minutos, por exemplo, 9h00, 9h10 e assim por diante.
Para o aplicativo lógico ativado ativo, defina o gatilho de Recorrência para a mesma programação do aplicativo lógico passivo no local principal, que deve começar aos 10 minutos após a hora e repetir a cada 20 minutos, por exemplo, 9h10, 9h20 e assim por diante.
Agora, se um evento perturbador acontecer no local principal, ative o aplicativo de lógica passiva no local alternativo. Dessa forma, se encontrar a falha levar tempo, essa configuração limita o número de recorrências perdidas durante esse atraso.
Acionador de consultas
Para verificar regularmente se novos dados para processamento estão disponíveis a partir de um serviço ou ponto de extremidade específico, seu aplicativo lógico pode usar um gatilho de sondagem que chama repetidamente o serviço ou ponto de extremidade com base em uma agenda de recorrência fixa. Os dados que o serviço ou ponto de extremidade fornece podem ter um destes tipos:
- Dados estáticos, que descrevem dados que estão sempre disponíveis para leitura
- Dados voláteis, que descrevem dados que não estão mais disponíveis após a leitura
Para evitar a leitura repetida dos mesmos dados, seu aplicativo lógico precisa lembrar quais dados foram lidos anteriormente, mantendo o estado no lado do cliente ou no servidor, serviço ou sistema.
Os aplicativos lógicos que funcionam com o estado do lado do cliente usam gatilhos que podem manter o estado.
Por exemplo, um gatilho que lê uma nova mensagem de uma caixa de entrada de e-mail requer que o gatilho possa se lembrar da mensagem lida mais recentemente. Dessa forma, o gatilho inicia o aplicativo lógico somente quando a próxima mensagem não lida chega.
Os aplicativos lógicos que funcionam com servidor, serviço ou estado do lado do sistema usam valores de propriedade ou configurações que estão no servidor, serviço ou sistema.
Por exemplo, um gatilho baseado em consulta que lê uma linha de um banco de dados requer que a linha tenha uma
isReadcoluna definida comoFALSE. Sempre que o gatilho lê uma linha, o aplicativo lógico atualiza essa linha alterando aisReadcoluna deFALSEparaTRUE.Essa abordagem do lado do servidor funciona de forma semelhante para filas do Service Bus ou tópicos com semântica de enfileiramento em que um gatilho pode ler e bloquear uma mensagem enquanto o aplicativo lógico processa a mensagem. Quando o aplicativo lógico conclui o processamento, o gatilho exclui a mensagem da fila ou tópico.
Do ponto de vista da recuperação de desastres, ao configurar as instâncias primária e secundária do aplicativo lógico, certifique-se de considerar esses comportamentos com base no fato de o aplicativo lógico rastrear o estado no lado do cliente ou no lado do servidor:
Para um aplicativo lógico que funciona com o estado do lado do cliente, certifique-se de que seu aplicativo lógico não leia a mesma mensagem mais de uma vez. Apenas um local pode ter uma instância de aplicativo lógico ativa a qualquer momento específico. Verifique se a instância do aplicativo lógico no local alternativo está inativa ou desabilitada até que a instância principal faça failover para o local alternativo.
Por exemplo, o gatilho do Office 365 Outlook mantém o estado do lado do cliente e rastreia o carimbo de data/hora do email lido mais recentemente para evitar a leitura de uma duplicata.
Para um aplicativo lógico que funciona com o estado do lado do servidor, você pode configurar suas instâncias de aplicativo lógico para desempenhar funções ativas-ativas, onde funcionam como consumidores concorrentes, ou funções ativas-passivas, onde a instância alternativa aguarda até que a instância primária faça failover para o local alternativo.
Por exemplo, a leitura de uma fila de mensagens, como uma fila do Barramento de Serviço do Azure, usa o estado do lado do servidor porque o serviço de enfileiramento mantém bloqueios nas mensagens para impedir que outros clientes leiam as mesmas mensagens.
Nota
Se seu aplicativo lógico precisar ler mensagens em uma ordem específica, por exemplo, de uma fila do Service Bus, você poderá usar o padrão de consumidor concorrente, mas somente quando combinado com sessões do Service Bus, que também é conhecido como padrão de comboio sequencial. Caso contrário, você deve configurar suas instâncias de aplicativo lógico com as funções ativo-passivo.
Gatilho de solicitação
O gatilho Request torna seu aplicativo lógico chamável de outros aplicativos, serviços e sistemas e normalmente é usado para fornecer esses recursos:
Uma API REST direta para seu aplicativo lógico que outras pessoas podem chamar
Por exemplo, use o gatilho Solicitação para iniciar seu aplicativo lógico para que outros aplicativos lógicos possam chamar o gatilho usando a ação Chamar fluxo de trabalho - Aplicativos lógicos.
Um webhook ou mecanismo de retorno de chamada para seu aplicativo lógico
Uma maneira de executar manualmente operações ou rotinas de usuário para chamar seu aplicativo lógico, por exemplo, usando um script do PowerShell que executa uma tarefa específica
Do ponto de vista da recuperação de desastres, o gatilho Request é um recetor passivo porque o aplicativo lógico não faz nenhum trabalho e aguarda até que algum outro serviço ou sistema chame explicitamente o gatilho. Como um ponto de extremidade passivo, você pode configurar suas instâncias primárias e secundárias das seguintes maneiras:
Ativo-ativo: ambas as instâncias lidam ativamente com solicitações ou chamadas. O chamador ou roteador equilibra ou distribui o tráfego entre essas instâncias.
Ativo-passivo: somente a instância primária está ativa e lida com todo o trabalho, enquanto a instância secundária aguarda até que a principal sofra interrupção ou falha. O chamador ou roteador determina quando chamar a instância secundária.
Como uma arquitetura recomendada, você pode usar o Gerenciamento de API do Azure como um proxy para os aplicativos lógicos que usam gatilhos de solicitação. O Gerenciamento de API fornece resiliência inter-regional integrada e a capacidade de rotear o tráfego entre vários endpoints.
Gatilho Webhook
Um gatilho de webhook fornece a capacidade de seu aplicativo lógico assinar um serviço passando uma URL de retorno de chamada para esse serviço. Seu aplicativo lógico pode ouvir e aguardar que um evento específico aconteça nesse ponto de extremidade de serviço. Quando o evento acontece, o serviço chama o gatilho de webhook usando a URL de retorno de chamada, que executa o aplicativo lógico. Quando ativado, o gatilho do webhook se inscreve no serviço. Quando desativado, o gatilho cancela a inscrição do serviço.
Do ponto de vista da recuperação de desastres, configure instâncias primárias e secundárias que usem gatilhos de webhook para desempenhar funções ativas-passivas, pois apenas uma instância deve receber eventos ou mensagens do ponto de extremidade inscrito.
Avaliar a integridade da instância primária
Para que uma estratégia de failover de várias regiões funcione, sua solução precisa de maneiras de executar estas tarefas:
- Verificar a disponibilidade da instância principal
- Monitorar a integridade da instância primária
- Ativar a instância secundária
Esta seção descreve uma solução que você pode usar diretamente ou como base para seu próprio design. Aqui está uma visão geral visual de alto nível para esta solução:
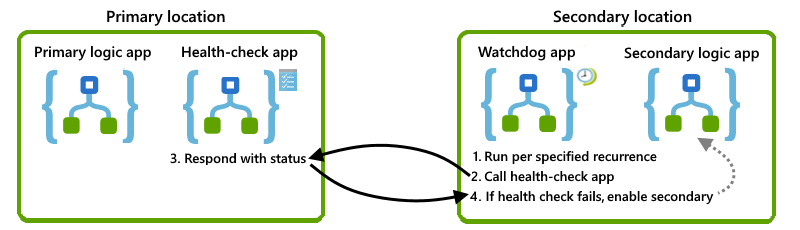
Verificar a disponibilidade da instância principal
Para determinar se a instância primária está disponível, em execução e capaz de funcionar, você pode criar um aplicativo lógico de "verificação de integridade" que esteja no mesmo local da instância primária. Em seguida, você pode chamar esse aplicativo de verificação de integridade de um local alternativo. Se o aplicativo de verificação de integridade responder com êxito, a infraestrutura subjacente para o serviço de Aplicativos Lógicos do Azure nessa região estará disponível e funcionando. Se o aplicativo de verificação de integridade não responder, você poderá presumir que o local não está mais íntegro.
Para esta tarefa, crie um aplicativo lógico básico de verificação de integridade que execute estas tarefas:
Recebe uma chamada do aplicativo watchdog usando o gatilho Request.
Responda com um status indicando se o aplicativo lógico verificado ainda funciona usando a ação Resposta.
Importante
O aplicativo lógico de verificação de integridade deve usar uma ação Resposta para que o aplicativo responda de forma síncrona, não assíncrona.
Opcionalmente, para determinar melhor se o local principal está íntegro, você pode considerar a integridade de quaisquer outros serviços que interajam com o aplicativo lógico de destino nesse local. Basta expandir o aplicativo de lógica de verificação de integridade para avaliar a saúde desses outros serviços também.
Criar um aplicativo lógico de vigilância
Para monitorar a integridade da instância primária e chamar o aplicativo lógico de verificação de integridade, crie um aplicativo lógico "watchdog" em um local alternativo. Por exemplo, você pode configurar o aplicativo de lógica de vigilância para que, se a chamada da lógica de verificação de integridade falhar, o cão de guarda possa enviar um alerta para sua equipe de operações para que eles possam investigar a falha e por que a instância principal não responde.
Importante
Certifique-se de que seu aplicativo lógico de vigilância esteja em um local diferente do local principal. Se os Aplicativos Lógicos do Azure no local principal tiverem problemas, o fluxo de trabalho do aplicativo lógico de vigilância pode não ser executado.
Para essa tarefa, no local secundário, crie um aplicativo lógico de vigilância que execute estas tarefas:
Execute com base em uma recorrência fixa ou programada usando o gatilho Recorrência.
Você pode definir a recorrência para um valor abaixo do nível de tolerância para seu RTO (Recovery Time Objetive, objetivo de tempo de recuperação).
Chame o fluxo de trabalho do aplicativo lógico de verificação de integridade no local principal usando a ação HTTP.
Você também pode criar um aplicativo lógico de vigilância mais sofisticado, que, após várias falhas, chama outro aplicativo lógico que lida automaticamente com a mudança para o local secundário quando o primário falha.
Ativar sua instância secundária
Para ativar automaticamente a instância secundária, você pode criar um aplicativo lógico que chame a API de gerenciamento, como o conector do Azure Resource Manager, para ativar os aplicativos lógicos apropriados no local secundário. Você pode expandir seu aplicativo de vigilância para chamar esse aplicativo lógico de ativação depois que um número específico de falhas acontecer.
Coletar dados de diagnóstico
Você pode configurar o log para suas execuções de aplicativo lógico e enviar os dados de diagnóstico resultantes para serviços como o Armazenamento do Azure, Hubs de Eventos do Azure e Azure Log Analytics para manipulação e processamento adicionais.
Se quiser usar esses dados com o Azure Log Analytics, você pode disponibilizar os dados para os locais primário e secundário configurando as configurações de Diagnóstico do seu aplicativo lógico e enviando os dados para vários espaços de trabalho do Log Analytics. Para obter mais informações, consulte Configurar logs do Azure Monitor e coletar dados de diagnóstico para Aplicativos Lógicos do Azure.
Se quiser enviar os dados para o Armazenamento do Azure ou Hubs de Eventos do Azure, você pode disponibilizar os dados para os locais primário e secundário configurando a redundância geográfica. Para mais informações, consulte estes artigos:
Próximos passos
- Projetar aplicativos confiáveis do Azure
- Lista de verificação de resiliência para serviços específicos do Azure
- Gerenciamento de dados para resiliência no Azure
- Backup e recuperação de desastres para aplicativos do Azure
- Recupere-se de uma interrupção de serviço em toda a região
- Contratos de Nível de Serviço (SLAs) da Microsoft para serviços do Azure