Configurar políticas do Apache Ranger para o Spark SQL no HDInsight com o Pacote de Segurança Empresarial
Este artigo descreve como configurar políticas do Apache Ranger para o Spark SQL com o Enterprise Security Package no HDInsight.
Neste artigo, vai aprender a:
- Crie políticas do Apache Ranger.
- Verifique as políticas Ranger aplicadas.
- Aplique diretrizes para definir o Apache Ranger para Spark SQL.
Pré-requisitos
- Um cluster Apache Spark no HDInsight versão 5.1 com pacote de segurança empresarial
Conectar-se à interface do usuário de administração do Apache Ranger
A partir de um navegador, conecte-se à interface de usuário de administração do Ranger usando o URL
https://ClusterName.azurehdinsight.net/Ranger/.Mude
ClusterNamepara o nome do cluster do Spark.Entre usando suas credenciais de administrador do Microsoft Entra. As credenciais de administrador do Microsoft Entra não são as mesmas que as credenciais de cluster HDInsight ou as credenciais SSH (Secure Shell) do nó HDInsight do Linux.
Criar utilizadores de domínio
Para obter informações sobre como criar sparkuser usuários de domínio, consulte Criar um cluster HDInsight com ESP. Em um cenário de produção, os usuários do domínio vêm do locatário do Microsoft Entra.
Criar uma política Ranger
Nesta seção, você cria duas políticas da Ranger:
- Uma política de acesso para acessar
hivesampletablea partir do Spark SQL - Uma política de mascaramento para ofuscar as colunas em
hivesampletable
Criar uma política de acesso Ranger
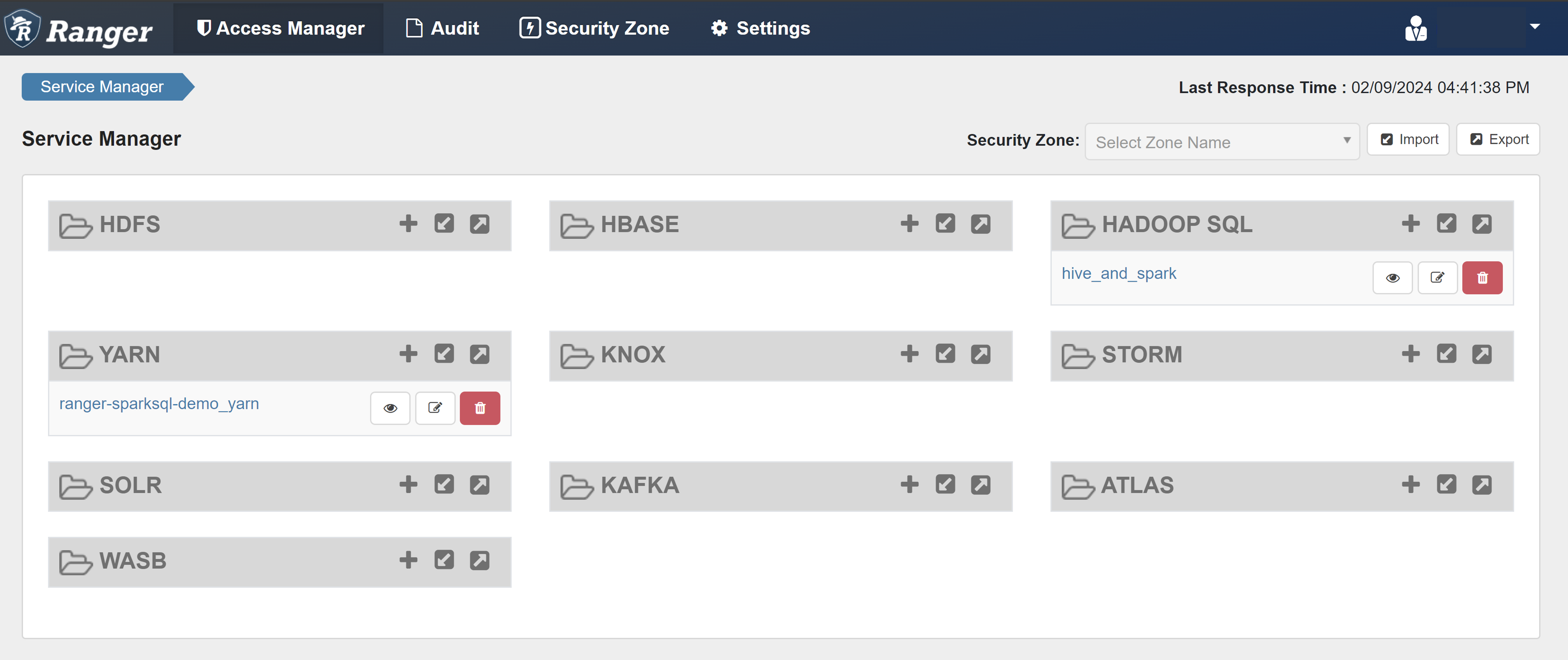
Abra a interface do usuário admin do Ranger.
Em HADOOP SQL, selecione hive_and_spark.
Na guia Acesso, selecione Adicionar Nova Política.
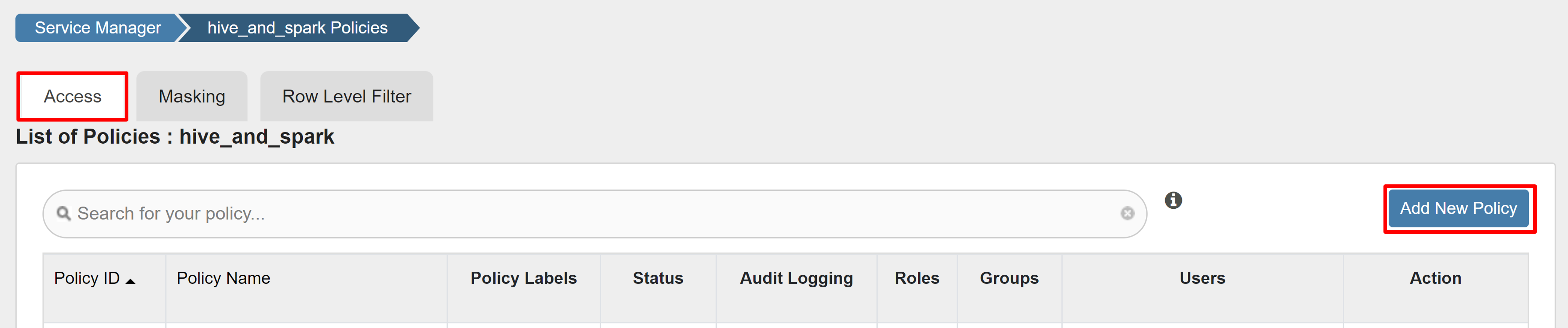
Introduza os seguintes valores:
Property valor Nome da Política read-hivesampletable-all base de dados default tabela HiveSampleTable coluna * Selecionar Utilizador sparkuserPermissões selecione 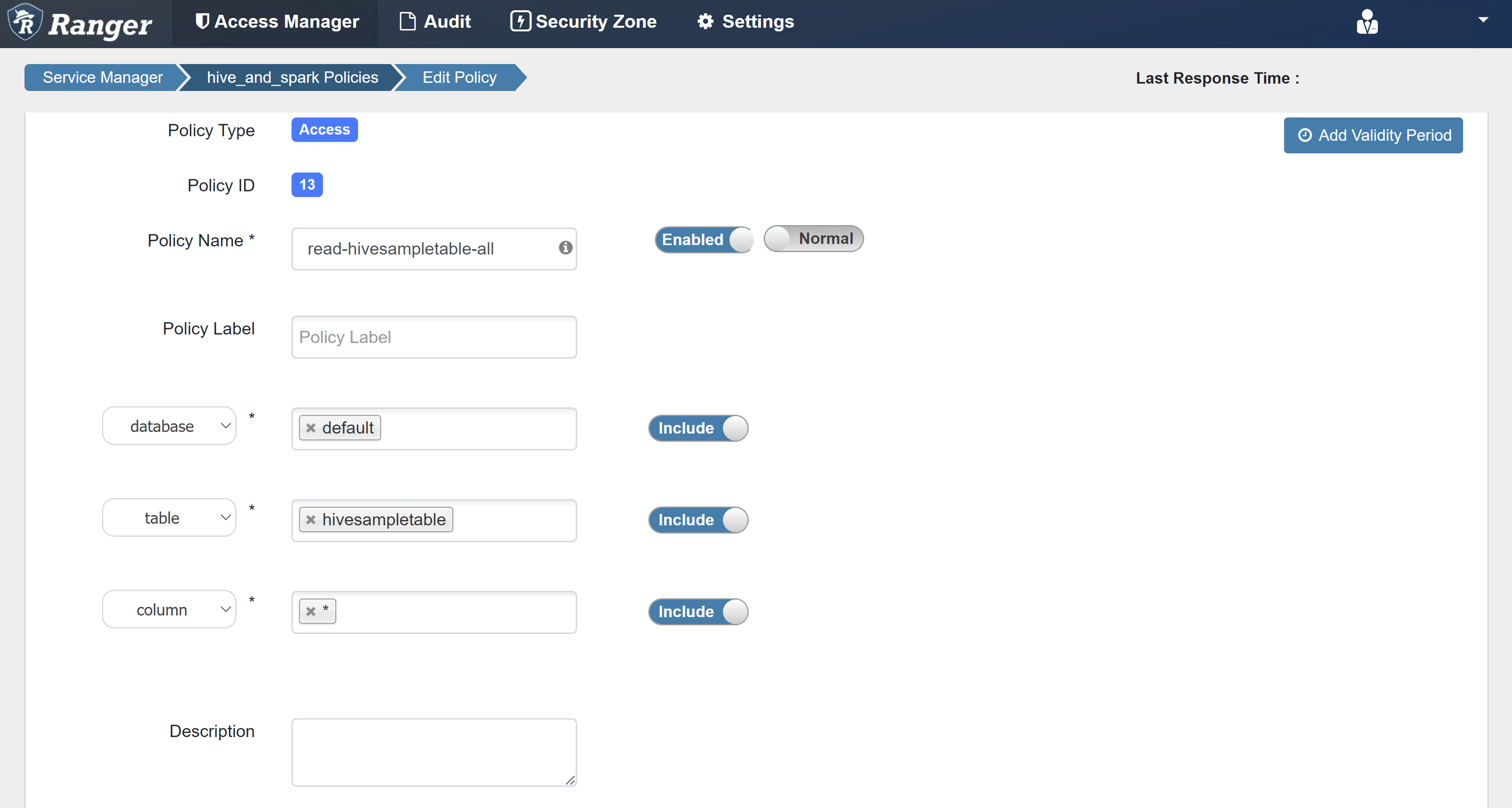
Se um usuário de domínio não for preenchido automaticamente para Selecionar Usuário, aguarde alguns momentos para que o Ranger sincronize com o ID do Microsoft Entra.
Selecione Adicionar para salvar a política.
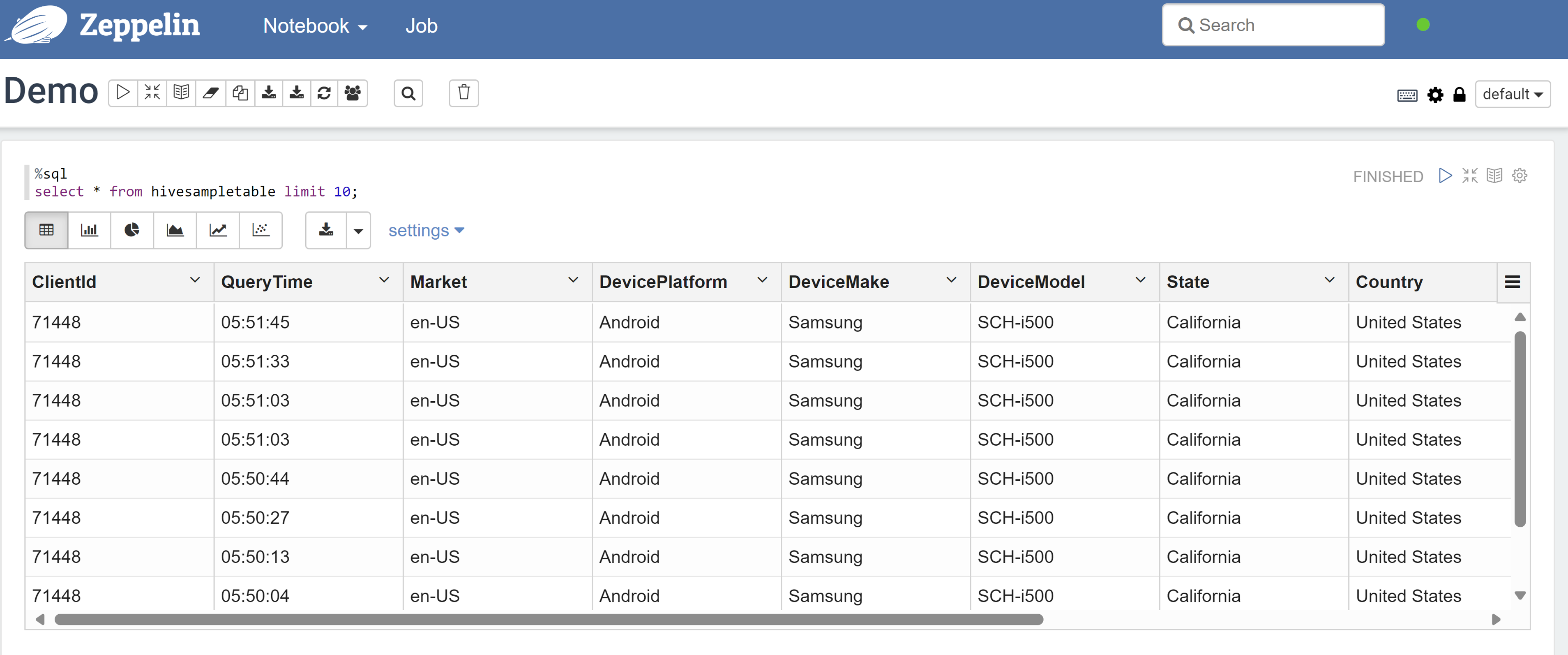
Abra um bloco de anotações do Zeppelin e execute o seguinte comando para verificar a política:
%sql select * from hivesampletable limit 10;Eis o resultado antes da aplicação de uma política:
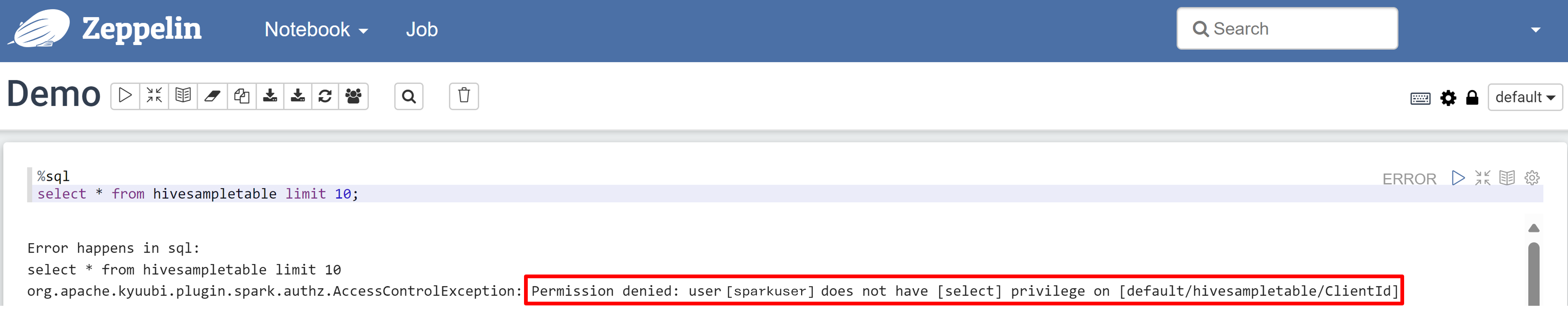
Eis o resultado após a aplicação de uma política:




Criar uma política de mascaramento Ranger
O exemplo a seguir mostra como criar uma política para mascarar uma coluna:
Na guia Mascaramento, selecione Adicionar nova política.
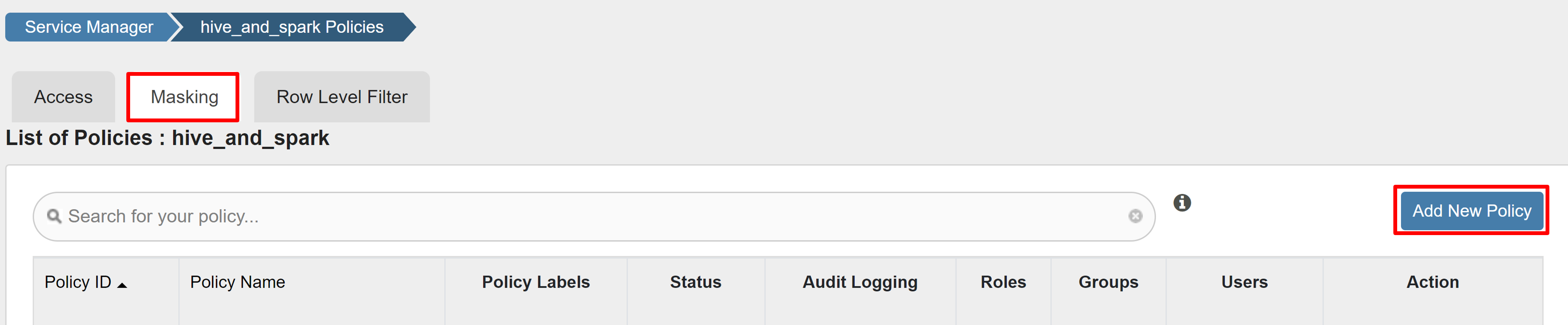
Introduza os seguintes valores:
Property valor Nome da Política máscara-hivesampletable Banco de dados do Hive default Tabela de colmeia HiveSampleTable Coluna Hive devicemake Selecionar Utilizador sparkuserTipos de Acesso selecione Selecione a opção de mascaramento Hash 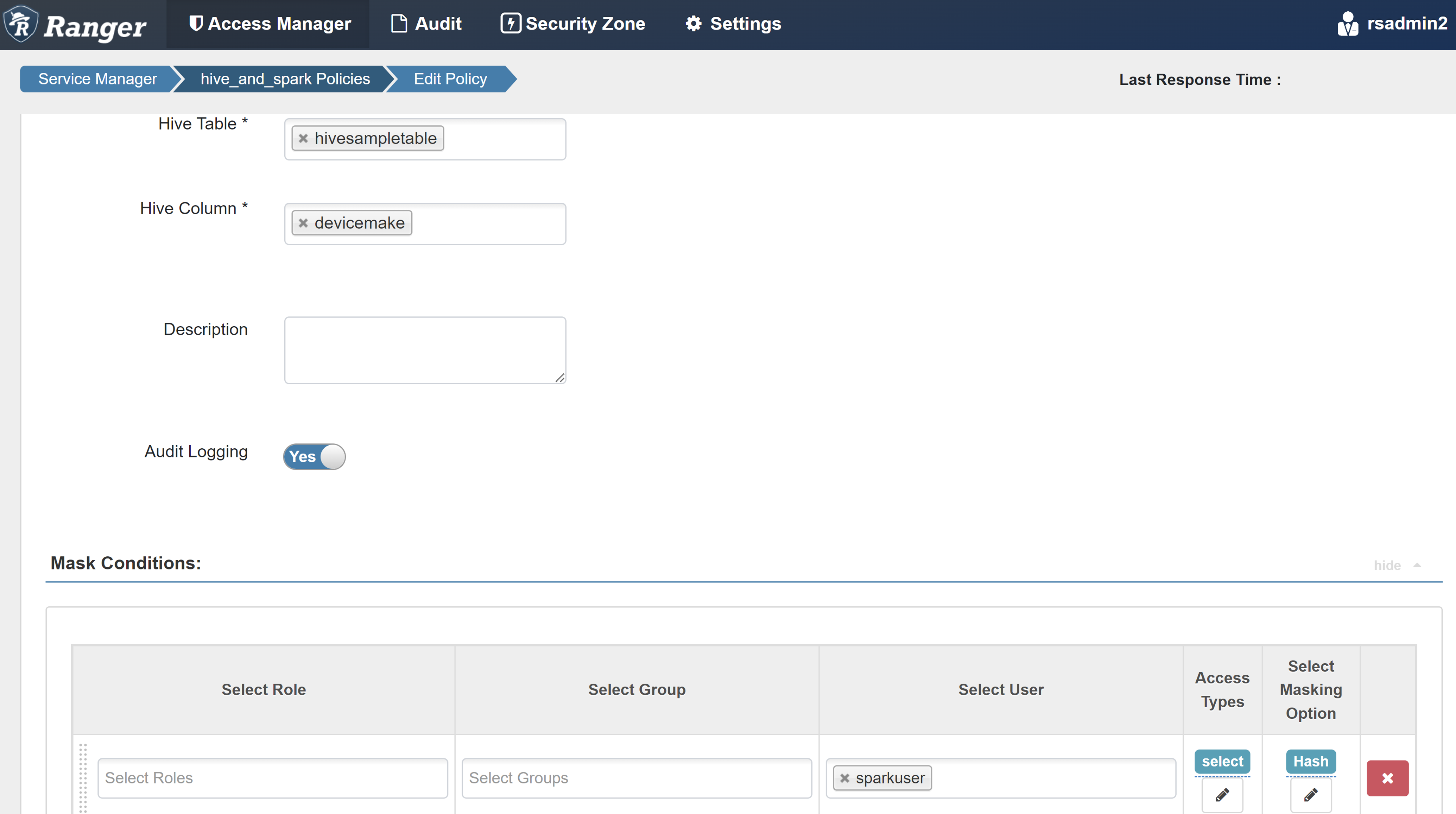
Selecione Salvar para salvar a política.
Abra um bloco de anotações do Zeppelin e execute o seguinte comando para verificar a política:
%sql select clientId, deviceMake from hivesampletable;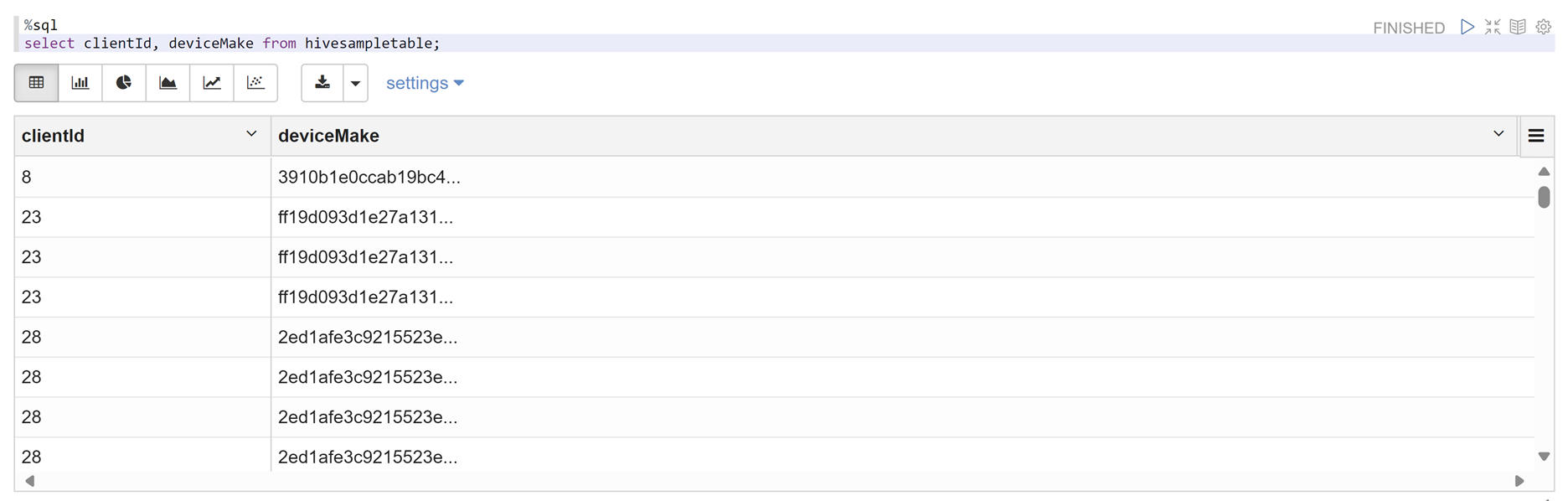



Nota
Por padrão, as políticas para Hive e Spark SQL são comuns no Ranger.
Aplicar diretrizes para configurar o Apache Ranger para Spark SQL
Os cenários a seguir exploram diretrizes para criar um cluster HDInsight 5.1 Spark usando um novo banco de dados Ranger e um banco de dados Ranger existente.
Cenário 1: Usar um novo banco de dados Ranger ao criar um cluster HDInsight 5.1 Spark
Quando você usa um novo banco de dados Ranger para criar um cluster, o repositório Ranger relevante que contém as políticas Ranger para Hive e Spark é criado sob o nome hive_and_spark no serviço Hadoop SQL no banco de dados Ranger.

Se você editar as políticas, elas serão aplicadas ao Hive e ao Spark.
Considere estes pontos:
Se você tiver dois bancos de dados de metastore com o mesmo nome usado para catálogos Hive (por exemplo, DB1) e Spark (por exemplo, DB1):
- Se o Spark usar o catálogo do Spark (
metastore.catalog.default=spark), as políticas serão aplicadas ao banco de dados DB1 do catálogo do Spark. - Se o Spark usar o catálogo do Hive (
metastore.catalog.default=hive), as políticas serão aplicadas ao banco de dados DB1 do catálogo do Hive.
Da perspetiva do Ranger, não há como diferenciar entre DB1 dos catálogos Hive e Spark.
Nesses casos, recomendamos que:
- Use o catálogo do Hive para o Hive e o Spark.
- Mantenha diferentes nomes de banco de dados, tabela e coluna para catálogos do Hive e do Spark para que as políticas não sejam aplicadas a bancos de dados entre catálogos.
- Se o Spark usar o catálogo do Spark (
Se você usar o catálogo do Hive para Hive e Spark, considere o exemplo a seguir.
Digamos que você crie uma tabela chamada table1 através do Hive com o usuário xyz atual. Ele cria um arquivo HDFS (Hadoop Distributed File System) chamado table1.db cujo proprietário é o usuário xyz .
Agora imagine que você use o usuário abc para iniciar a sessão do Spark SQL. Nesta sessão de user abc, se você tentar escrever qualquer coisa na table1, ela estará fadada a falhar porque o proprietário da tabela é xyz.
Nesse caso, recomendamos que você use o mesmo usuário no Hive e no Spark SQL para atualizar a tabela. Esse usuário deve ter privilégios suficientes para executar operações de atualização.
Cenário 2: Usar um banco de dados Ranger existente (com políticas existentes) ao criar um cluster HDInsight 5.1 Spark
Quando você cria um cluster HDInsight 5.1 usando um banco de dados Ranger existente, um novo repositório Ranger é criado novamente nesse banco de dados com o nome do novo cluster neste formato: hive_and_spark.

Digamos que você já tenha as políticas definidas no repositório Ranger sob o nome oldclustername_hive no banco de dados Ranger existente dentro do serviço Hadoop SQL. Você deseja compartilhar as mesmas políticas no novo cluster HDInsight 5.1 Spark. Para atingir esse objetivo, use as etapas a seguir.
Nota
Um usuário que tenha privilégios de administrador do Ambari pode executar atualizações de configuração.
Abra a interface do usuário do Ambari a partir do novo cluster HDInsight 5.1.
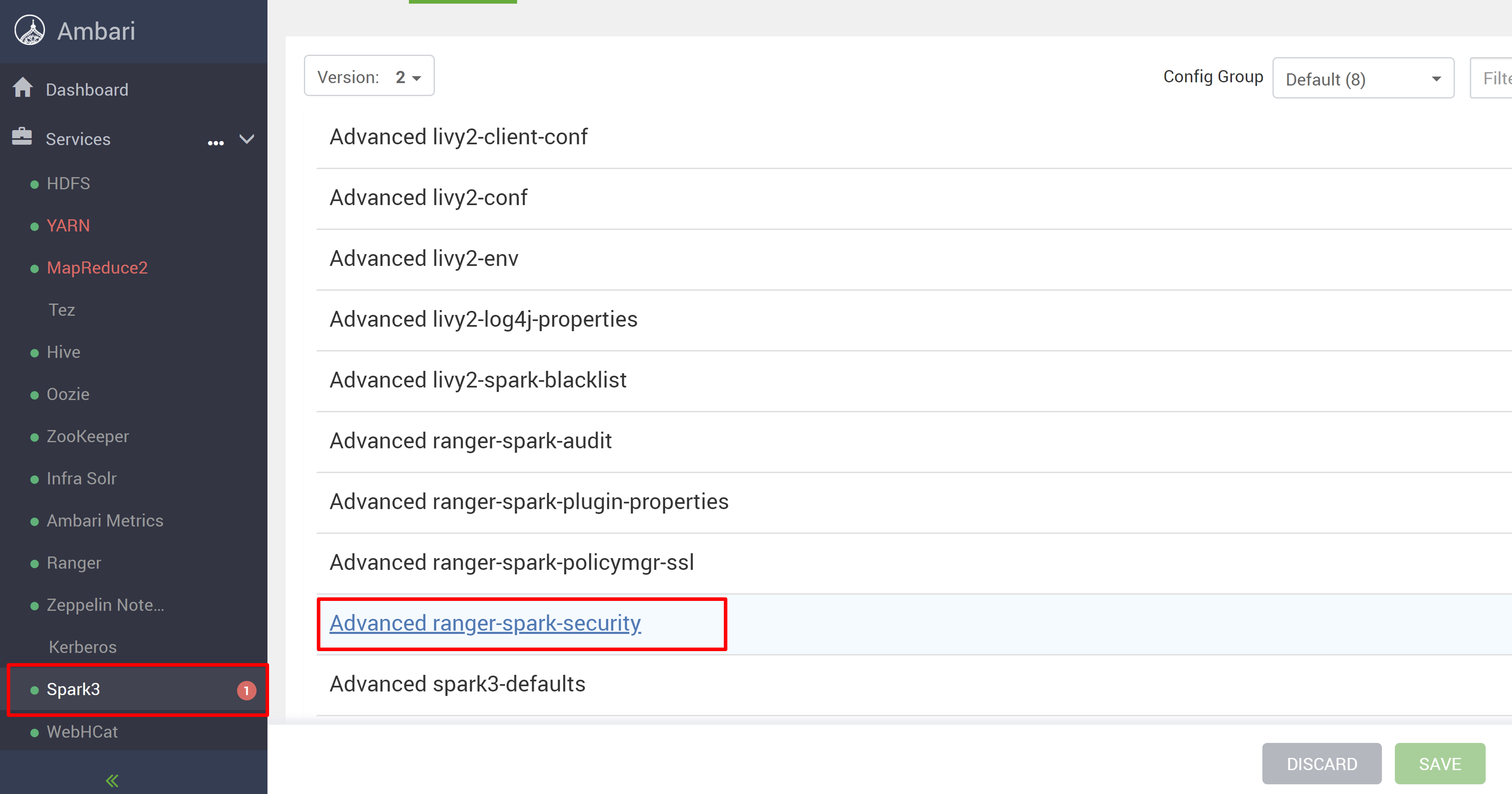
Vá para o serviço Spark3 e, em seguida, vá para Configs.
Abra a configuração Advanced ranger-spark-security .
ou Você também pode abrir esta configuração em /etc/spark3/conf usando SSH.
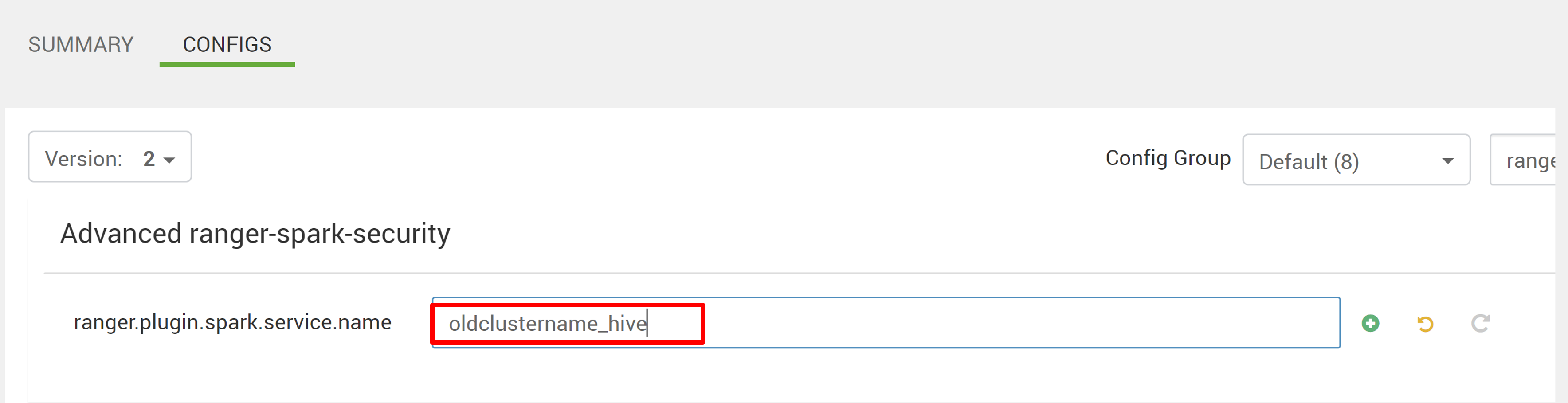
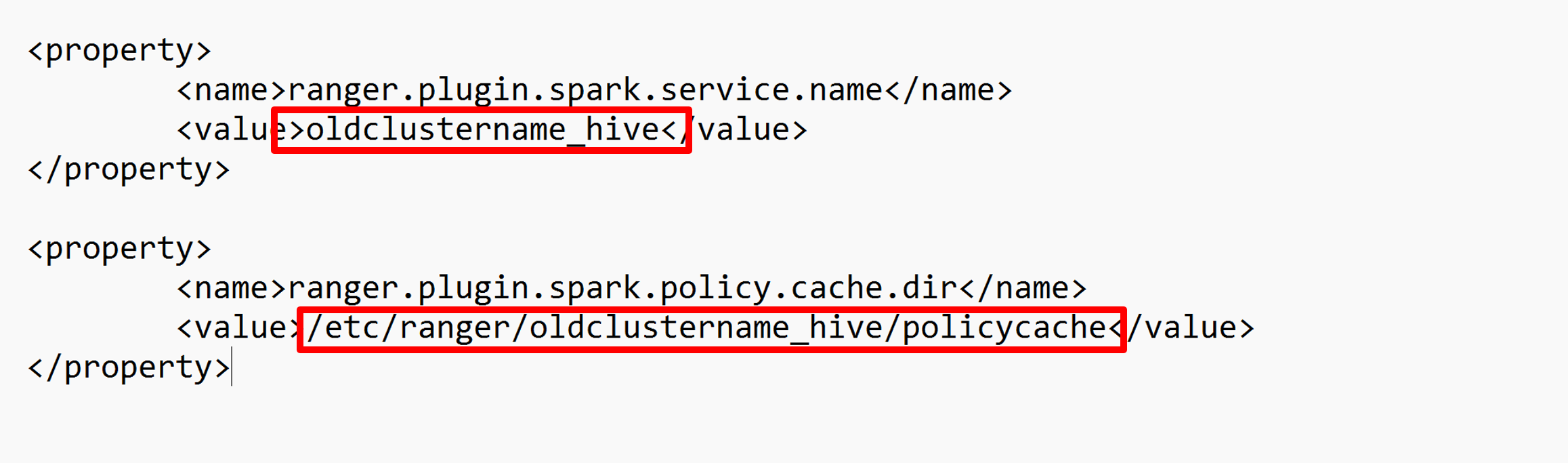
Edite duas configurações (ranger.plugin.spark.service.name e ranger.plugin.spark.policy.cache.dir) para apontar para o oldclustername_hive de repositório de política antigo e salve as configurações.
Ambari:
Arquivo XML:
Reinicie os serviços Ranger e Spark da Ambari.
Abra a interface do usuário admin do Ranger e clique no botão de edição no serviço HADOOP SQL .
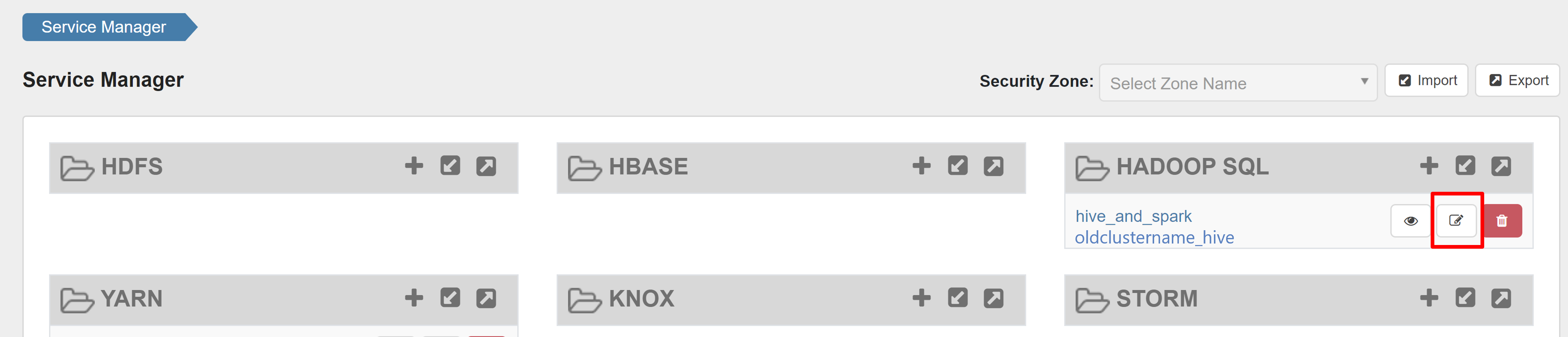
Para oldclustername_hive serviço, adicione rangersparklookup user na lista policy.download.auth.users e tag.download.auth.users e clique em salvar.






As políticas são aplicadas em bancos de dados no catálogo do Spark. Se você quiser acessar os bancos de dados no catálogo do Hive:
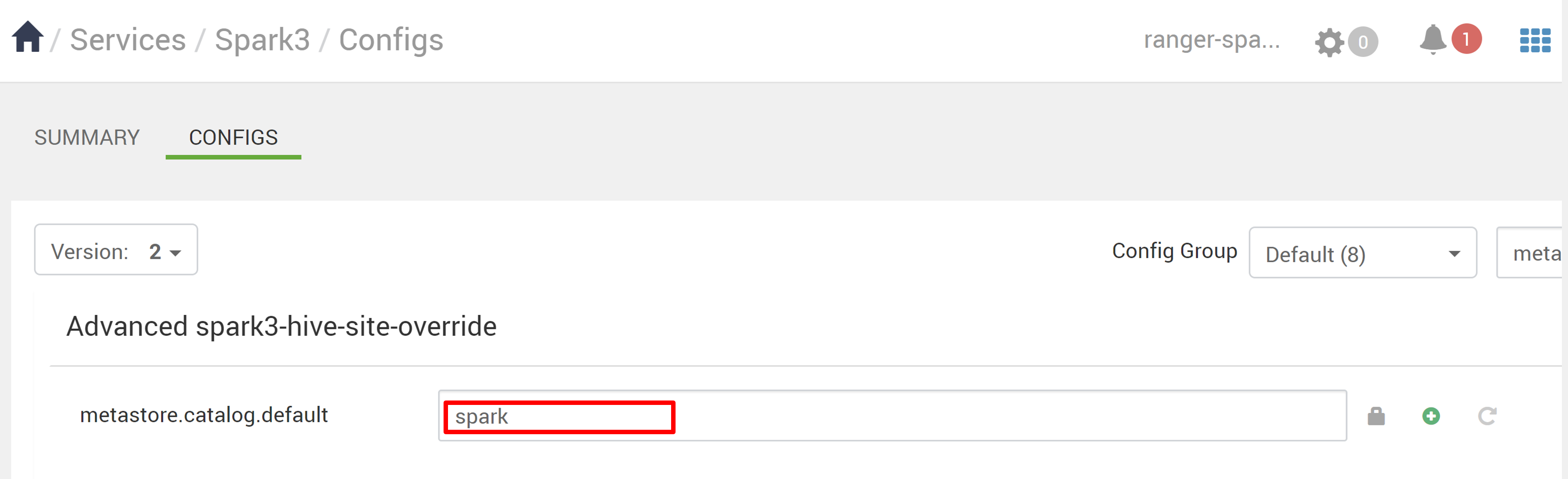
No Ambari, vá para Spark3>Configs.
Altere metastore.catalog.default de faísca para colmeia.

Problemas conhecidos
- A integração do Apache Ranger com o Spark SQL não funciona se o administrador do Ranger estiver inativo.
- Nos logs de auditoria da Ranger, quando você passa o mouse sobre a coluna Recurso , ela não pode mostrar toda a consulta executada.