Otimização do uso de memória para Apache Spark
Este artigo descreve como otimizar o gerenciamento de memória do cluster Apache Spark para obter o melhor desempenho no Azure HDInsight.
Descrição geral
O Spark opera colocando dados na memória. Portanto, gerenciar recursos de memória é um aspeto fundamental para otimizar a execução de trabalhos do Spark. Há várias técnicas que você pode aplicar para usar a memória do cluster de forma eficiente.
- Prefira partições de dados menores e leve em conta o tamanho, os tipos e a distribuição dos dados em sua estratégia de particionamento.
- Considere a serialização Java mais recente e mais eficiente
Kryo data serialization, em vez da serialização Java padrão. - Prefira usar o YARN, pois ele se separa
spark-submitpor lote. - Monitore e ajuste as definições de configuração do Spark.
Para sua referência, a estrutura de memória do Spark e alguns parâmetros de memória do executor chave são mostrados na próxima imagem.
Considerações sobre memória de faísca
Se você estiver usando o Apache Hadoop YARN, o YARN controlará a memória usada por todos os contêineres em cada nó do Spark. O diagrama a seguir mostra os objetos principais e suas relações.
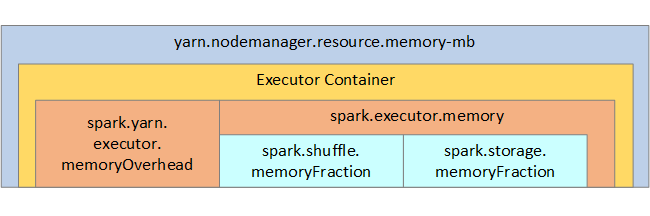
Para endereçar mensagens de "falta de memória", tente:
- Analise os embaralhamentos de gerenciamento do DAG. Reduza com a redução do lado do mapa, pré-particione (ou bucketize) os dados de origem, maximize os embaralhamentos únicos e reduza a quantidade de dados enviados.
- Prefira
ReduceByKeycom seu limite de memória fixa paraGroupByKey, que fornece agregações, janelas e outras funções, mas tem um limite de memória ilimitada. - Prefira
TreeReduce, que faz mais trabalho nos executores ou partições, paraReduce, que faz todo o trabalho no driver. - Use DataFrames em vez dos objetos RDD de nível inferior.
- Crie ComplexTypes que encapsulam ações, como "Top N", várias agregações ou operações de janela.
Para obter etapas adicionais de solução de problemas, consulte Exceções OutOfMemoryError para Apache Spark no Azure HDInsight.