Visão geral do Apache Spark Streaming
O Apache Spark Streaming fornece processamento de fluxo de dados em clusters HDInsight Spark. Com a garantia de que qualquer evento de entrada é processado exatamente uma vez, mesmo que ocorra uma falha de nó. Um Spark Stream é um trabalho de longa execução que recebe dados de entrada de uma ampla variedade de fontes, incluindo Hubs de Eventos do Azure. Também: Hub IoT do Azure, Apache Kafka, Apache Flume, X, ZeroMQsoquetes TCP brutos ou do monitoramento de sistemas de arquivos Apache Hadoop YARN. Ao contrário de um processo exclusivamente orientado por eventos, um Spark Stream armazena dados de entrada em lotes em janelas de tempo. Como uma fatia de 2 segundos e, em seguida, transforma cada lote de dados usando operações de mapeamento, redução, junção e extração. Em seguida, o Spark Stream grava os dados transformados em sistemas de arquivos, bancos de dados, painéis e no console.
Os aplicativos do Spark Streaming devem aguardar uma fração de segundo para coletar cada micro-batch um dos eventos antes de enviar esse lote para processamento. Por outro lado, um aplicativo controlado por eventos processa cada evento imediatamente. A latência do Spark Streaming normalmente é inferior a alguns segundos. Os benefícios da abordagem de microlotes são o processamento de dados mais eficiente e cálculos agregados mais simples.
Apresentando o DStream
O Spark Streaming representa um fluxo contínuo de dados de entrada usando um fluxo discretizado chamado DStream. Um DStream pode ser criado a partir de fontes de entrada, como Hubs de Eventos ou Kafka. Ou aplicando transformações em outro DStream.
Um DStream fornece uma camada de abstração sobre os dados brutos do evento.
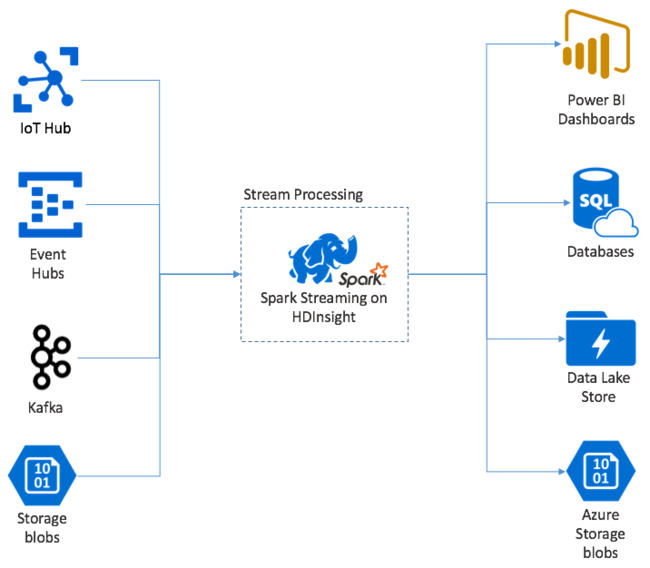
Comece com um único evento, digamos, uma leitura de temperatura de um termostato conectado. Quando esse evento chega ao seu aplicativo Spark Streaming, ele é armazenado de forma confiável, onde é replicado em vários nós. Essa tolerância a falhas garante que a falha de qualquer nó não resulte na perda do seu evento. O núcleo do Spark usa uma estrutura de dados que distribui dados entre vários nós no cluster. Onde cada nó geralmente mantém seus próprios dados na memória para obter o melhor desempenho. Essa estrutura de dados é chamada de conjunto de dados distribuído resiliente (RDD).
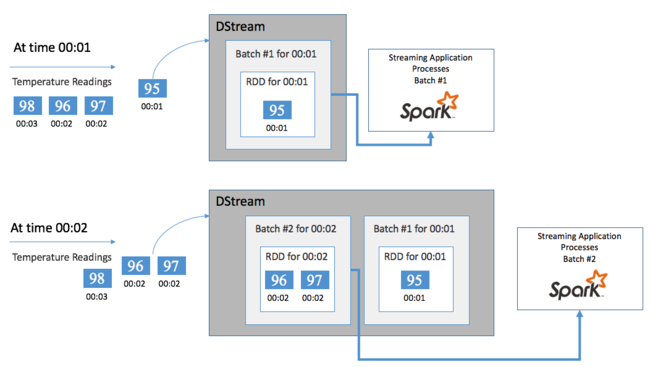
Cada RDD representa eventos coletados em um período de tempo definido pelo usuário chamado intervalo de lote. À medida que cada intervalo de lote passa, um novo RDD é produzido que contém todos os dados desse intervalo. O conjunto contínuo de RDDs é coletado em um DStream. Por exemplo, se o intervalo de lote tiver um segundo de comprimento, o DStream emite um lote a cada segundo contendo um RDD que contém todos os dados ingeridos durante esse segundo. Ao processar o DStream, o evento de temperatura aparece em um desses lotes. Um aplicativo Spark Streaming processa os lotes que contêm os eventos e, finalmente, atua sobre os dados armazenados em cada RDD.
Estrutura de um aplicativo Spark Streaming
Um aplicativo Spark Streaming é um aplicativo de longa execução que recebe dados de fontes de ingestão. Aplica transformações para processar os dados e, em seguida, envia os dados para um ou mais destinos. A estrutura de um aplicativo Spark Streaming tem uma parte estática e uma parte dinâmica. A parte estática define de onde vêm os dados, que processamento fazer nos dados. E para onde devem ir os resultados. A parte dinâmica está executando o aplicativo indefinidamente, aguardando um sinal de parada.
Por exemplo, o seguinte aplicativo simples recebe uma linha de texto sobre um soquete TCP e conta o número de vezes que cada palavra aparece.
Definir a aplicação
A definição da lógica do aplicativo tem quatro etapas:
- Crie um StreamingContext.
- Crie um DStream a partir do StreamingContext.
- Aplique transformações ao DStream.
- Produza os resultados.
Essa definição é estática e nenhum dado é processado até que você execute o aplicativo.
Criar um StreamingContext
Crie um StreamingContext a partir do SparkContext que aponte para o cluster. Ao criar um StreamingContext, você especifica o tamanho do lote em segundos, por exemplo:
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
Criar um DStream
Com a instância StreamingContext, crie um DStream de entrada para sua fonte de entrada. Nesse caso, o aplicativo está atento ao aparecimento de novos arquivos no armazenamento anexado padrão.
val lines = ssc.textFileStream("/uploads/Test/")
Aplicar transformações
Você implementa o processamento aplicando transformações no DStream. Esta aplicação recebe uma linha de texto de cada vez do arquivo, divide cada linha em palavras. E, em seguida, usa um padrão de redução de mapa para contar o número de vezes que cada palavra aparece.
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
Resultados das realizações
Envie os resultados da transformação para os sistemas de destino aplicando operações de saída. Neste caso, o resultado de cada execução através do cálculo é impresso na saída do console.
wordCounts.print()
Executar a aplicação
Inicie o aplicativo de streaming e execute até que um sinal de terminação seja recebido.
ssc.start()
ssc.awaitTermination()
Para obter detalhes sobre a API do Spark Stream, consulte Apache Spark Streaming Programming Guide.
O aplicativo de exemplo a seguir é independente, para que você possa executá-lo dentro de um Jupyter Notebook. Este exemplo cria uma fonte de dados simulada na classe DummySource que gera o valor de um contador e a hora atual em milissegundos a cada cinco segundos. Um novo objeto StreamingContext tem um intervalo de lote de 30 segundos. Sempre que um lote é criado, o aplicativo de streaming examina o RDD produzido. Em seguida, converte o RDD em um Spark DataFrame e cria uma tabela temporária sobre o DataFrame.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Aguarde cerca de 30 segundos após iniciar a aplicação acima. Em seguida, você pode consultar o DataFrame periodicamente para ver o conjunto atual de valores presentes no lote, por exemplo, usando esta consulta SQL:
%%sql
SELECT * FROM demo_numbers
A saída resultante se parece com a seguinte saída:
| valor | hora |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
Existem seis valores, uma vez que o DummySource cria um valor a cada 5 segundos e o aplicativo emite um lote a cada 30 segundos.
Janelas de correr
Para fazer cálculos agregados no seu DStream durante algum período de tempo, por exemplo, para obter uma temperatura média nos últimos dois segundos, use as sliding window operações incluídas no Spark Streaming. Uma janela deslizante tem uma duração (o comprimento da janela) e o intervalo durante o qual o conteúdo da janela é avaliado (o intervalo do slide).
Janelas de correr podem se sobrepor, por exemplo, você pode definir uma janela com um comprimento de dois segundos, que desliza a cada um segundo. Essa ação significa que toda vez que você fizer um cálculo de agregação, a janela incluirá dados do último segundo da janela anterior. E quaisquer novos dados no próximo um segundo.
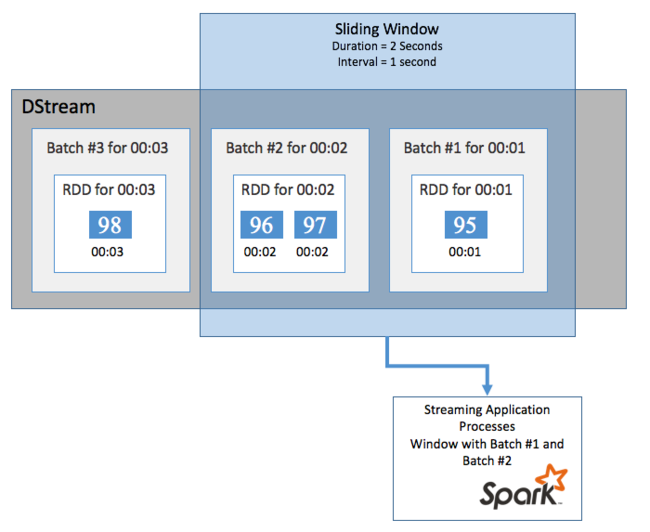
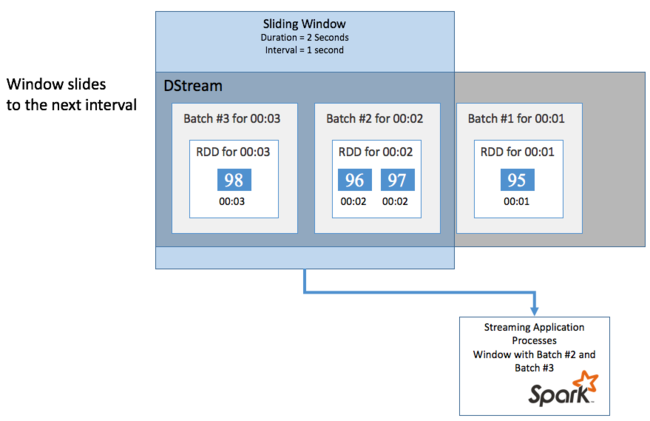
O exemplo a seguir atualiza o código que usa o DummySource, para coletar os lotes em uma janela com uma duração de um minuto e um slide de um minuto.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Após o primeiro minuto, há 12 entradas - seis entradas de cada um dos dois lotes coletados na janela.
| valor | hora |
|---|---|
| 1 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
As funções de janela deslizante disponíveis na API do Spark Streaming incluem window, countByWindow, reduceByWindow e countByValueAndWindow. Para obter detalhes sobre essas funções, consulte Transformações no DStreams.
Pontos de verificação
Para oferecer resiliência e tolerância a falhas, o Spark Streaming depende de pontos de verificação para garantir que o processamento de fluxo possa continuar ininterruptamente, mesmo em caso de falhas de nós. O Spark cria pontos de verificação para armazenamento durável (Armazenamento do Azure ou Armazenamento Data Lake). Esses pontos de verificação armazenam metadados do aplicativo de streaming, como a configuração e as operações definidas pelo aplicativo. Além disso, todos os lotes que foram enfileirados, mas ainda não processados. Às vezes, os pontos de verificação também incluirão salvar os dados nos RDDs para reconstruir mais rapidamente o estado dos dados a partir do que está presente nos RDDs gerenciados pelo Spark.
Implantando aplicativos do Spark Streaming
Normalmente, você cria um aplicativo Spark Streaming localmente em um arquivo JAR. Em seguida, implante-o no Spark no HDInsight copiando o arquivo JAR para o armazenamento anexado padrão. Você pode iniciar seu aplicativo com as APIs LIVY REST disponíveis no cluster usando uma operação POST. O corpo do POST inclui um documento JSON que fornece o caminho para o seu JAR. E o nome da classe cujo método principal define e executa o aplicativo de streaming e, opcionalmente, os requisitos de recursos do trabalho (como o número de executores, memória e núcleos). Além disso, todas as definições de configuração exigidas pelo código do aplicativo.
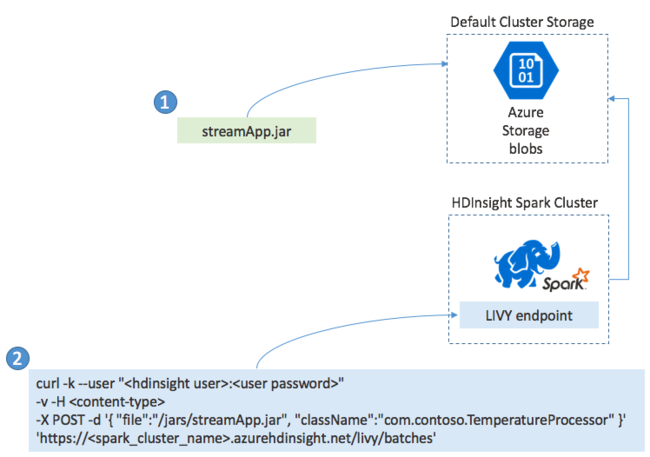
O status de todos os aplicativos também pode ser verificado com uma solicitação GET em relação a um ponto de extremidade LIVY. Finalmente, você pode encerrar um aplicativo em execução emitindo uma solicitação DELETE contra o ponto de extremidade LIVY. Para obter detalhes sobre a API LIVY, consulte Trabalhos remotos com o Apache LIVY