Tutorial: Carregar dados e executar consultas em um cluster Apache Spark no Azure HDInsight
Neste tutorial, você aprenderá como criar um dataframe a partir de um arquivo csv e como executar consultas interativas do Spark SQL em um cluster Apache Spark no Azure HDInsight. No Spark, um pacote de dados é uma coleção distribuída de dados organizados em colunas com nomes. Do ponto de vista conceptual, o pacote de dados equivale a uma tabela numa base de dados relacional ou a um pacote de dados em R/Python.
Neste tutorial, irá aprender a:
- Criar um pacote de dados a partir de um ficheiro CSV
- Executar consultas no pacote de dados
Pré-requisitos
Um cluster do Apache Spark no HDInsight. Consulte Criar um cluster do Apache Spark.
Criar um Bloco de Notas do Jupyter Notebook
O Jupyter Notebook é um ambiente de bloco de notas interativo que suporta várias linguagens de programação. O bloco de notas permite-lhe interagir com os seus dados, combinar código com texto markdown e realizar visualizações simples.
Edite o URL
https://SPARKCLUSTER.azurehdinsight.net/jupytersubstituindoSPARKCLUSTERpelo nome do cluster do Spark. Em seguida, insira o URL editado em um navegador da Web. Se lhe for pedido, introduza as credenciais de início de sessão do cluster.Na página da Web do Jupyter, Para os clusters do Spark 2.4, selecione Novo>PySpark para criar um bloco de anotações. Para a versão do Spark 3.1, selecione Novo>PySpark3 para criar um bloco de anotações porque o kernel do PySpark não está mais disponível no Spark 3.1.
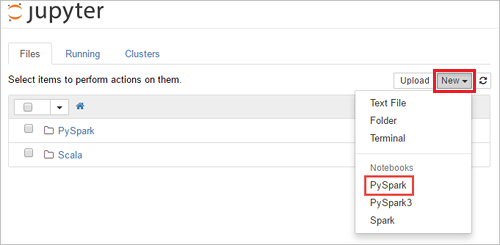
Um novo bloco de anotações é criado e aberto com o nome Untitled(
Untitled.ipynb).Nota
Usando o kernel PySpark ou PySpark3 para criar um bloco de anotações, a
sparksessão é criada automaticamente para você quando você executa a primeira célula de código. Não precisa de criar explicitamente a sessão.
Criar um pacote de dados a partir de um ficheiro CSV
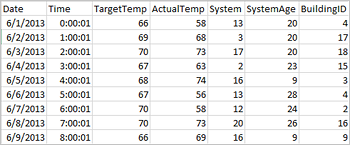
Os aplicativos podem criar dataframes diretamente de arquivos ou pastas no armazenamento remoto, como o Armazenamento do Azure ou o Armazenamento do Azure Data Lake; de uma mesa de colmeia; ou de outras fontes de dados suportadas pelo Spark, como Azure Cosmos DB, Azure SQL DB, DW e assim por diante. A seguinte captura de ecrã mostra um instantâneo do ficheiro HVAC.csv utilizado neste tutorial. O ficheiro CSV é fornecido com todos os clusters do Spark no HDInsight. Os dados ilustram as variações de temperatura de alguns edifícios.
Cole o código a seguir em uma célula vazia do Jupyter Notebook e pressione SHIFT + ENTER para executar o código. O código importa os tipos necessários para este cenário:
from pyspark.sql import * from pyspark.sql.types import *Quando você executa uma consulta interativa no Jupyter, a janela do navegador da Web ou a legenda da guia mostra um status (Ocupado) junto com o título do bloco de anotações. Também vê um círculo sólido junto ao texto do PySpark no canto superior direito. Após a conclusão da tarefa, este é alterado para um círculo vazio.
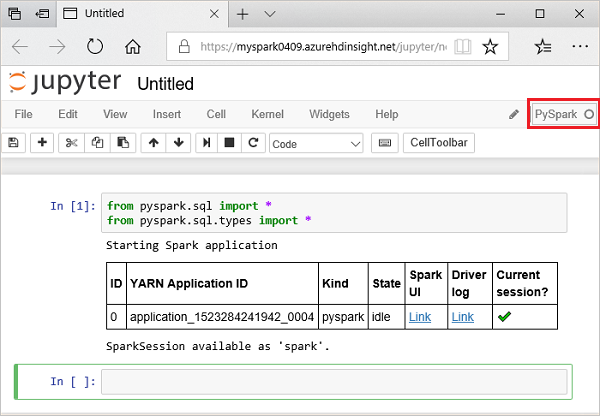
Observe a ID da sessão retornada. Na imagem acima, o ID da sessão é 0. Se desejar, você pode recuperar os detalhes da sessão navegando até
https://CLUSTERNAME.azurehdinsight.net/livy/sessions/ID/statementsonde CLUSTERNAME é o nome do cluster do Spark e ID é o número da ID da sessão.Execute o seguinte código para criar um pacote de dados e uma tabela temporária (hvac) ao utilizar o seguinte código.
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
Executar consultas no datanami
Após a criação da tabela, pode executar uma consulta interativa nos dados.
Execute o seguinte código numa célula vazia do bloco de notas:
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"É apresentado o seguinte resultado em forma de tabela.
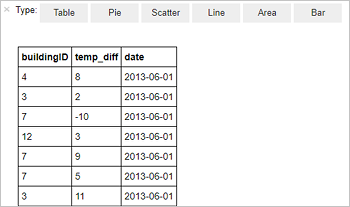
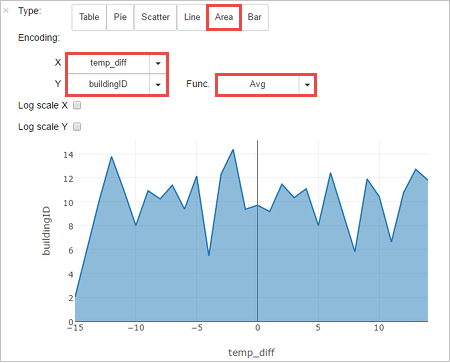
Também pode ver os resultados noutras visualizações. Para ver um gráfico de área do mesmo resultado, selecione Area (Área) e, em seguida, defina outros valores, conforme mostrado.
Na barra de menus do bloco de anotações, navegue até Salvar arquivo>e Ponto de verificação.
Se tenciona iniciar o próximo tutorial agora, deixe o bloco de notas aberto. Caso contrário, desligue o bloco de anotações para liberar os recursos do cluster: na barra de menus do bloco de anotações, navegue até Fechar e Parar Arquivo>.
Clean up resources (Limpar recursos)
Com o HDInsight, seus dados e Jupyter Notebooks são armazenados no Armazenamento do Azure ou no Armazenamento do Azure Data Lake, para que você possa excluir com segurança um cluster quando ele não estiver em uso. Você também é cobrado por um cluster HDInsight, mesmo quando ele não está em uso. Como as cobranças para o cluster são muitas vezes mais do que as taxas para armazenamento, faz sentido econômico excluir clusters quando eles não estão em uso. Se tenciona começar já a trabalhar no próximo tutorial, convém manter o cluster.
Abra o cluster no portal do Azure e, em seguida, selecione Eliminar.
Também pode selecionar o nome do grupo de recursos para abrir a página do grupo de recursos e, em seguida, selecionar Eliminar grupo de recursos. Ao eliminar o grupo de recursos, está a eliminar o cluster do Spark no HDInsight e a conta de armazenamento predefinida.
Próximos passos
Neste tutorial, você aprendeu como criar um dataframe a partir de um arquivo csv e como executar consultas interativas do Spark SQL em um cluster Apache Spark no Azure HDInsight. Avance para o próximo artigo para ver como os dados registrados no Apache Spark podem ser extraídos para uma ferramenta de análise de BI, como o Power BI.