Visão geral do Armazenamento do Azure no HDInsight
O Armazenamento do Azure é uma solução robusta de armazenamento de uso geral que se integra perfeitamente ao HDInsight. O HDInsight pode utilizar um contentor de blobs no Armazenamento do Azure como o sistema de ficheiros predefinido para o cluster. Através de uma interface HDFS, o conjunto completo de componentes no HDInsight pode operar diretamente em dados estruturados ou não estruturados armazenados como blobs.
Recomendamos o uso de contêineres de armazenamento separados para o armazenamento de cluster padrão e os dados corporativos. A separação é isolar os logs do HDInsight e os arquivos temporários dos seus próprios dados corporativos. Também recomendamos excluir o contêiner de blob padrão, que contém logs de aplicativos e do sistema, após cada uso para reduzir o custo de armazenamento. Certifique-se de que obtém os registos antes de eliminar o contentor.
Se optar por proteger a sua conta de armazenamento com as restrições Firewalls e redes virtuais em Redes selecionadas, certifique-se de que ativa a exceção Permitir serviços Microsoft fidedignos.... A exceção é para que o HDInsight possa acessar sua conta de armazenamento.
Arquitetura de armazenamento do HDInsight
O diagrama a seguir fornece uma exibição abstrata da arquitetura HDInsight do Armazenamento do Azure:
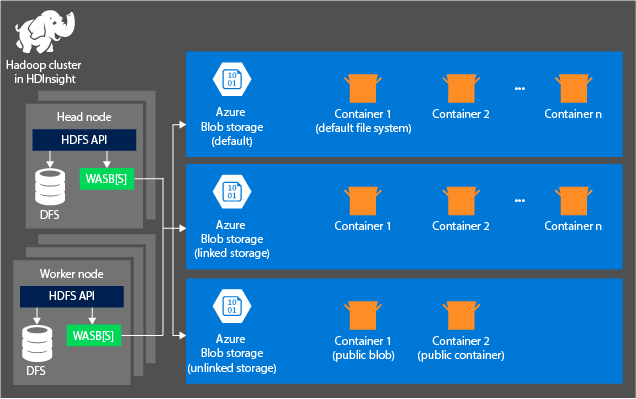
O HDInsight fornece acesso ao sistema de ficheiros distribuído que está ligado localmente aos nós de computação. É possível aceder a este sistema de ficheiros ao utilizar o URI completamente qualificado, por exemplo:
hdfs://<namenodehost>/<path>
Por meio do HDInsight, você também pode acessar dados no Armazenamento do Azure. A sintaxe é a seguinte:
wasb://<containername>@<accountname>.blob.core.windows.net/<path>
Para contas que têm um namespace hierárquico (Azure Data Lake Storage Gen2), a sintaxe é a seguinte:
abfs://<containername>@<accountname>.dfs.core.windows.net/<file.path>/
Considere os seguintes princípios ao usar uma conta de Armazenamento do Azure com clusters HDInsight:
Contentores nas contas do Storage ligadas a um cluster: como o nome e a chave da conta são associados ao cluster durante a criação, tem acesso total aos blobs desses contentores.
Contêineres públicos ou blobs públicos em contas de armazenamento que não estão conectadas a um cluster: você tem permissão somente leitura para os blobs nos contêineres.
Nota
Os contêineres públicos permitem que você obtenha uma lista de todos os blobs disponíveis nesse contêiner e obtenha metadados de contêiner. Os blobs públicos permitem aceder aos blobs apenas se souber o URL exato. Para obter mais informações, veja Manage anonymous read access to containers and blobs (Gerir o acesso de leitura anónima a contentores e blobs).
Contêineres privados em contas de armazenamento que não estão conectadas a um cluster: você não pode acessar os blobs nos contêineres, a menos que defina a conta de armazenamento ao enviar os trabalhos WebHCat.
As contas do Storage definidas durante o processo de criação e as respetivas chaves são armazenadas em %HADOOP_HOME%/conf/core-site.xml nos nós do cluster. Por padrão, o HDInsight usa as contas de armazenamento definidas no arquivo core-site.xml. Você pode modificar essa configuração usando o Apache Ambari. Para obter mais informações sobre as configurações da conta de armazenamento que podem ser modificadas ou colocadas no arquivo core-site.xml, consulte estes artigos:
- Suporte do Azure Hadoop: Armazenamento de Blob do Azure
- Suporte do Hadoop Azure: ABFS — Azure Data Lake Storage Gen2
Vários trabalhos WebHCat, incluindo Apache Hive. E o MapReduce, o streaming do Apache Hadoop e o Apache Pig trazem uma descrição de contas de armazenamento e metadados. (Esse aspeto é atualmente verdadeiro para o Pig com contas de armazenamento, mas não para metadados.) Para obter mais informações, consulte Usando um cluster HDInsight com contas de armazenamento e metastores alternativos.
Os blobs podem ser utilizados para dados estruturados e não estruturados. Os contêineres de Blob armazenam dados como pares chave/valor e não têm hierarquia de diretório. No entanto, o nome da chave pode incluir um caractere de barra ( / ) para fazer parecer que um arquivo está armazenado dentro de uma estrutura de diretório. Por exemplo, a chave de um blob pode ser input/log1.txt. Não existe nenhum diretório real input , mas devido ao caractere de barra no nome da chave, a chave se parece com um caminho de arquivo.
Vantagens do Armazenamento do Azure
Clusters de computação e recursos de armazenamento que não são colocalizados têm custos de desempenho implícitos. Esses custos são atenuados pela maneira como os clusters de computação são criados perto dos recursos da conta de armazenamento dentro da região do Azure. Nessa região, os nós de computação podem acessar com eficiência os dados pela rede de alta velocidade dentro do Armazenamento do Azure.
Ao armazenar os dados no Armazenamento do Azure em vez do HDFS, você obtém vários benefícios:
Partilha e reutilização de dados: os dados no HDFS estão localizados dentro do cluster de cálculo. Apenas as aplicações que têm acesso ao cluster de cálculo podem utilizar os dados ao utilizar as APIs do HDFS. Os dados no Armazenamento do Azure, por outro lado, podem ser acessados por meio das APIs HDFS ou das APIs REST de armazenamento de Blob. Devido a esse arranjo, um conjunto maior de aplicativos (incluindo outros clusters HDInsight) e ferramentas pode ser usado para produzir e consumir os dados.
Arquivamento de dados: quando os dados são armazenados no Armazenamento do Azure, os clusters HDInsight usados para computação podem ser excluídos com segurança sem perder dados do usuário.
Custo de armazenamento de dados: armazenar dados no DFS a longo prazo é mais caro do que armazenar os dados no Armazenamento do Azure. Porque o custo de um cluster de computação é maior do que o custo do Armazenamento do Azure. Além disso, como os dados não precisam ser recarregados para cada geração de cluster de computação, você também está economizando custos de carregamento de dados.
Aumento horizontal elástico: embora o HDFS forneça um sistema de ficheiros ampliado horizontalmente, o dimensionamento é determinado pelo número de nós que cria para o cluster. Alterar a escala pode ser mais complicado do que os recursos de dimensionamento elástico que você obtém automaticamente no Armazenamento do Azure.
Replicação geográfica: seu Armazenamento do Azure pode ser replicado geograficamente. Embora a replicação geográfica ofereça recuperação geográfica e redundância de dados, um failover para o local replicado geograficamente afeta gravemente seu desempenho e pode incorrer em custos adicionais. Portanto, escolha a replicação geográfica com cautela e somente se o valor dos dados justificar o custo adicional.
Determinados trabalhos e pacotes do MapReduce podem criar resultados intermediários que você não gostaria de armazenar no Armazenamento do Azure. Nesse caso, pode optar por armazenar os dados no HDFS local. O HDInsight usa o DFS para vários desses resultados intermediários em trabalhos do Hive e outros processos.
Nota
A maioria dos comandos HDFS (por exemplo, ls, copyFromLocale mkdir) funciona como esperado no Armazenamento do Azure. Somente os comandos específicos da implementação HDFS nativa (conhecida como DFS), como fschk e dfsadmin, mostram um comportamento diferente no Armazenamento do Azure.