Guia de início rápido: executar consultas do Apache Hive no Azure HDInsight com o Apache Zeppelin
Neste início rápido, você aprenderá a usar o Apache Zeppelin para executar consultas do Apache Hive no Azure HDInsight. Os clusters de Consulta Interativa do HDInsight incluem blocos de anotações do Apache Zeppelin que você pode usar para executar consultas interativas do Hive.
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
Um cluster de Consulta Interativa do HDInsight. Consulte Criar cluster para criar um cluster HDInsight. Certifique-se de escolher o tipo de cluster de Consulta Interativa .
Criar uma nota do Apache Zeppelin
Substitua
CLUSTERNAMEpelo nome do cluster no seguinte URLhttps://CLUSTERNAME.azurehdinsight.net/zeppelin. Em seguida, insira o URL em um navegador da Web.Introduza o seu nome de utilizador e palavra-passe de início de sessão no cluster. Na página do Zeppelin, você pode criar uma nova nota ou abrir notas existentes. O HiveSample contém algumas consultas Hive de exemplo.
Selecione Criar nova nota.
Na caixa de diálogo Criar nova nota, digite ou selecione os seguintes valores:
- Nota Nome: Introduza um nome para a nota.
- Interpretador padrão: Selecione jdbc na lista suspensa.
Selecione Criar nota.
Insira a seguinte consulta do Hive na seção de código e pressione Shift + Enter:
%jdbc(hive) show tables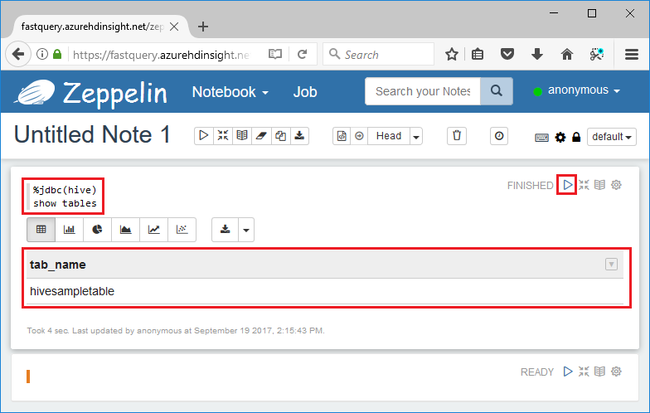
A
%jdbc(hive)instrução na primeira linha diz ao bloco de anotações para usar o interpretador JDBC do Hive.A consulta deve retornar uma tabela Hive chamada hivesampletable.
A seguir estão mais duas consultas do Hive que você pode executar em hivesampletable:
%jdbc(hive) select * from hivesampletable limit 10 %jdbc(hive) select ${group_name}, count(*) as total_count from hivesampletable group by ${group_name=market,market|deviceplatform|devicemake} limit ${total_count=10}Em comparação com o Hive tradicional, os resultados da consulta voltam muito mais rápido.
Mais exemplos
Criar uma tabela. Execute o código no Bloco de Anotações do Zeppelin:
%jdbc(hive) CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;Carregue dados na nova tabela. Execute o código no Bloco de Anotações do Zeppelin:
%jdbc(hive) LOAD DATA INPATH 'wasbs:///example/data/sample.log' INTO TABLE log4jLogs;Insira um único registo. Execute o código no Bloco de Anotações do Zeppelin:
%jdbc(hive) INSERT INTO TABLE log4jLogs2 VALUES ('A', 'B', 'C', 'D', 'E', 'F', 'G');
Consulte o manual de linguagem do Hive para obter mais sintaxe.
Clean up resources (Limpar recursos)
Depois de concluir o início rápido, convém excluir o cluster. Com o HDInsight, seus dados são armazenados no Armazenamento do Azure, para que você possa excluir com segurança um cluster quando ele não estiver em uso. Você também é cobrado por um cluster HDInsight, mesmo quando ele não está em uso. Como as cobranças para o cluster são muitas vezes mais do que as taxas para armazenamento, faz sentido econômico excluir clusters quando eles não estão em uso.
Para excluir um cluster, consulte Excluir um cluster HDInsight usando seu navegador, PowerShell ou a CLI do Azure.
Próximos passos
Neste início rápido, você aprendeu como usar o Apache Zeppelin para executar consultas do Apache Hive no Azure HDInsight. Para saber mais sobre consultas do Hive, o próximo artigo mostrará como executar consultas com o Visual Studio.