Guia de início rápido: criar cluster Apache Hadoop no Azure HDInsight usando o portal do Azure
Neste artigo, você aprenderá a criar clusters Apache Hadoop no HDInsight usando o portal do Azure e, em seguida, executar trabalhos do Apache Hive no HDInsight. A maioria das tarefas do Hadoop são tarefas de lote. Cria um cluster, executa algumas tarefas e, em seguida, elimina o cluster. Neste artigo, irá realizar as três tarefas. Para obter explicações detalhadas sobre as configurações disponíveis, consulte Configurar clusters no HDInsight. Para obter mais informações sobre o uso do portal para criar clusters, consulte Criar clusters no portal.
Neste guia de início rápido, irá utilizar o portal do Azure para criar um cluster do Hadoop no HDInsight. Também pode criar um cluster através do modelo Azure Resource Manager.
Atualmente, o HDInsight vem com sete tipos diferentes de cluster. Cada tipo de cluster suporta um conjunto diferente de componentes. Todos os tipos de cluster suportam o Hive. Para obter uma lista de componentes suportados no HDInsight, consulte O que há de novo nas versões de cluster do Apache Hadoop fornecidas pelo HDInsight?
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Criar um cluster Apache Hadoop
Nesta secção, irá criar um cluster do Hadoop no HDInsight através do portal do Azure.
Inicie sessão no portal do Azure.
No menu superior, selecione + Criar um recurso.
Selecione Analytics>Azure HDInsight para ir para a página Criar cluster HDInsight.
Na guia Noções básicas, forneça as seguintes informações:
Property Descrição Subscrição Na lista suspensa, selecione a assinatura do Azure usada para o cluster. Grupo de recursos Na lista pendente, selecione o grupo de recursos existente ou selecione Criar novo. Nome do cluster Introduza um nome globalmente exclusivo. O nome pode ter até 59 caracteres, incluindo letras, números e hífenes. O primeiro e o último caracteres do nome não podem ser hífenes. País/Região Na lista suspensa, selecione uma região onde o cluster é criado. Selecione uma localização mais próxima de si para obter um melhor desempenho. Tipo de cluster Selecione Selecionar tipo de cluster. Em seguida, selecione Hadoop como o tipo de cluster. Versão Na lista suspensa, selecione uma versão. Use a versão padrão se não souber o que escolher. Nome de utilizador e palavra-passe de início de sessão no cluster O nome de entrada padrão é admin. A senha deve ter pelo menos 10 caracteres e deve conter pelo menos um dígito, uma letra maiúscula e uma letra minúscula, um caractere não alfanumérico (exceto caracteres ' ` "). Certifique-se de que não fornece palavras-passe comuns, como "Pass@word1".Nome de utilizador de Secure Shell (SSH) O nome de usuário padrão é sshuser. Pode indicar outro nome de utilizador SSH.Usar senha de entrada de cluster para SSH Marque essa caixa de seleção para usar a mesma senha para o usuário SSH que você forneceu para o usuário de logon do cluster. 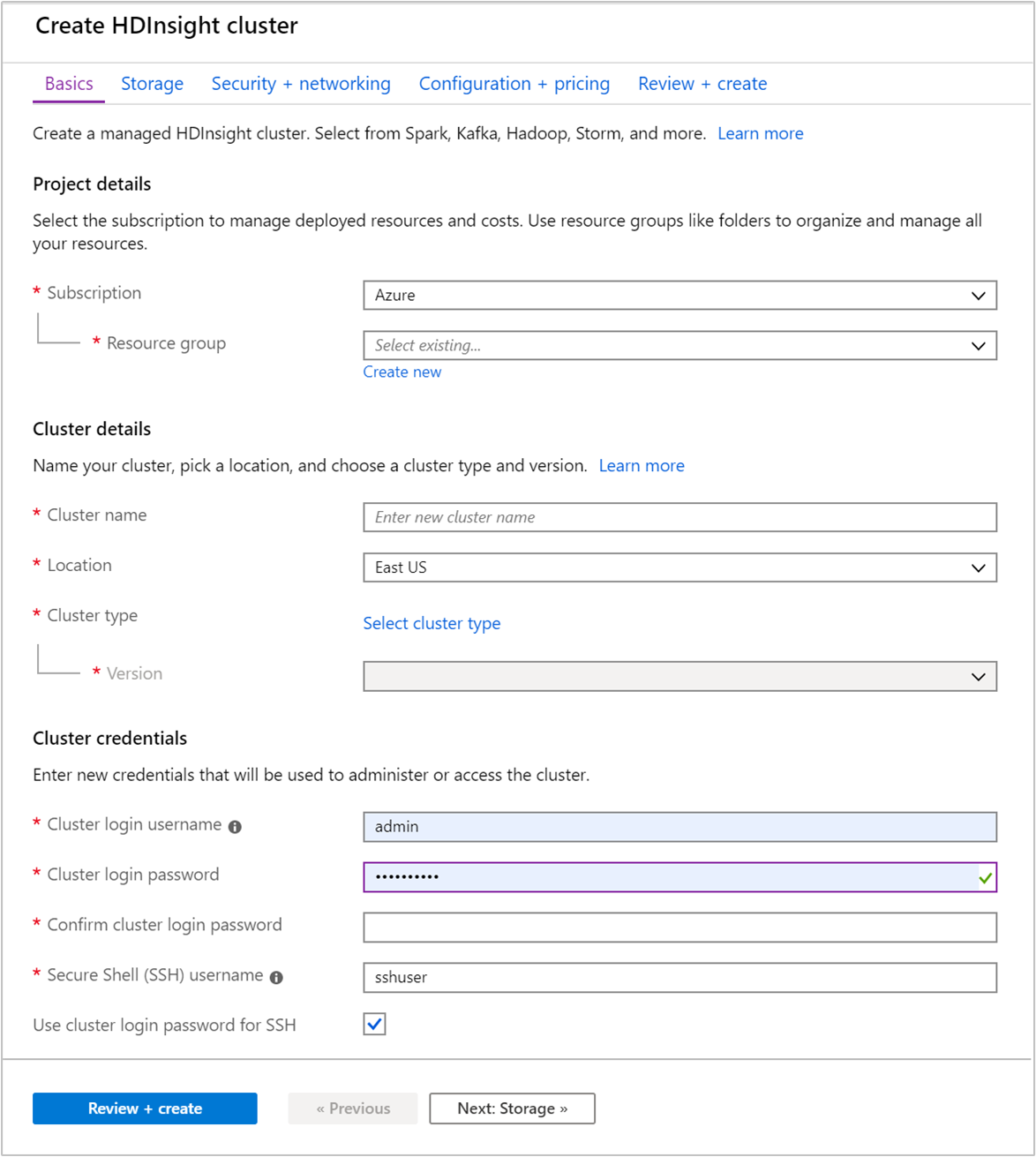
Selecione Next : Storage >> para avançar para as configurações de armazenamento.
Na guia Armazenamento, forneça os seguintes valores:
Property Description Tipo de armazenamento primário Use o valor padrão Armazenamento do Azure. Método de seleção Use o valor padrão Selecionar da lista. Conta de armazenamento primária Use a lista suspensa para selecionar uma conta de armazenamento existente ou selecione Criar novo. Se criar uma nova conta, o nome tem de ter entre 3 e 24 carateres e pode incluir apenas números e letras minúsculas Contentor Use o valor preenchido automaticamente. 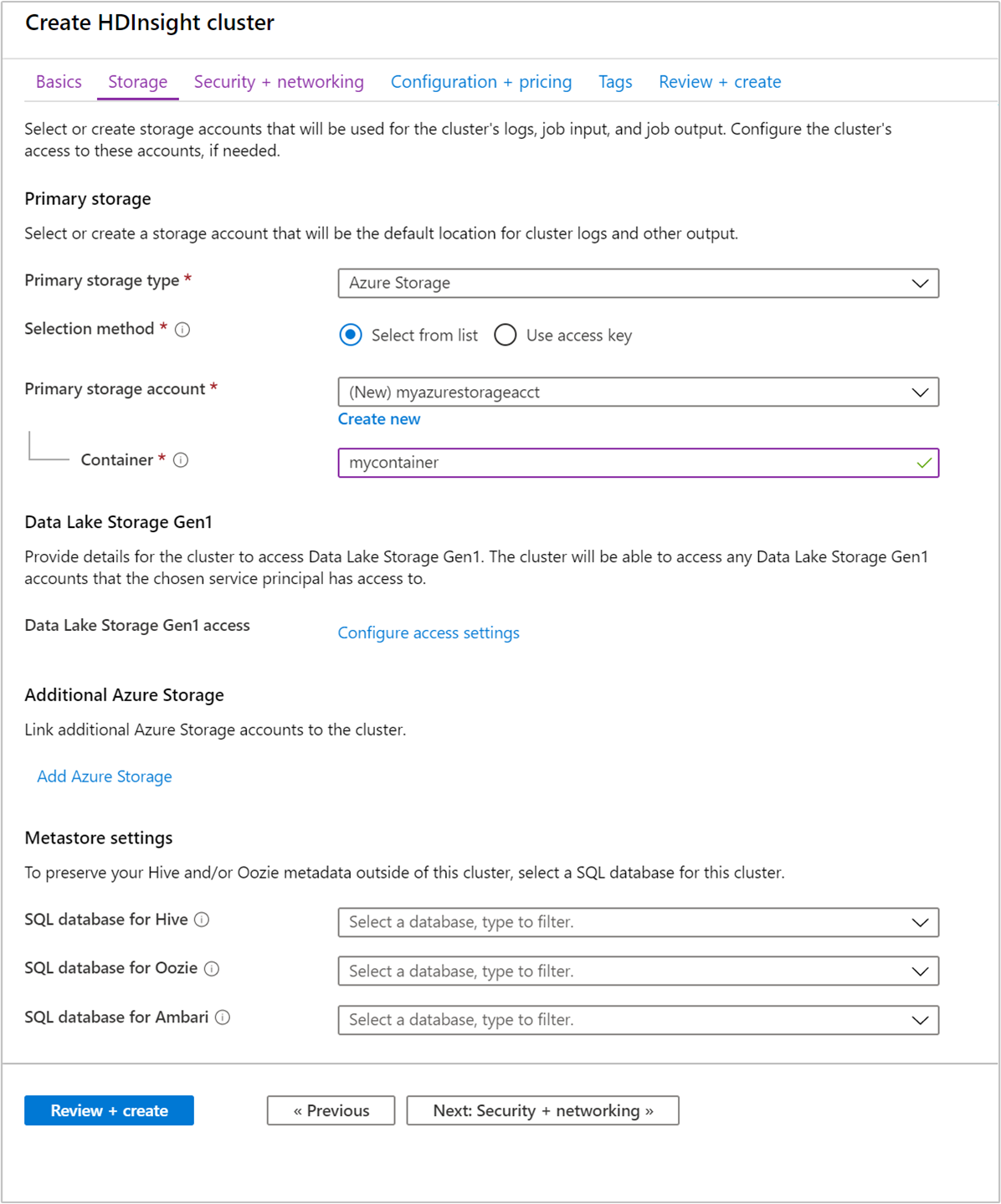
Cada cluster tem uma conta de Armazenamento do Azure ou uma
Azure Data Lake Storage Gen2dependência. É conhecida como a conta de armazenamento padrão. O cluster HDInsight e sua conta de armazenamento padrão devem ser colocalizados na mesma região do Azure. A exclusão de clusters não exclui a conta de armazenamento.Selecione a guia Revisar + criar .
Na guia Revisar + criar, verifique os valores selecionados nas etapas anteriores.
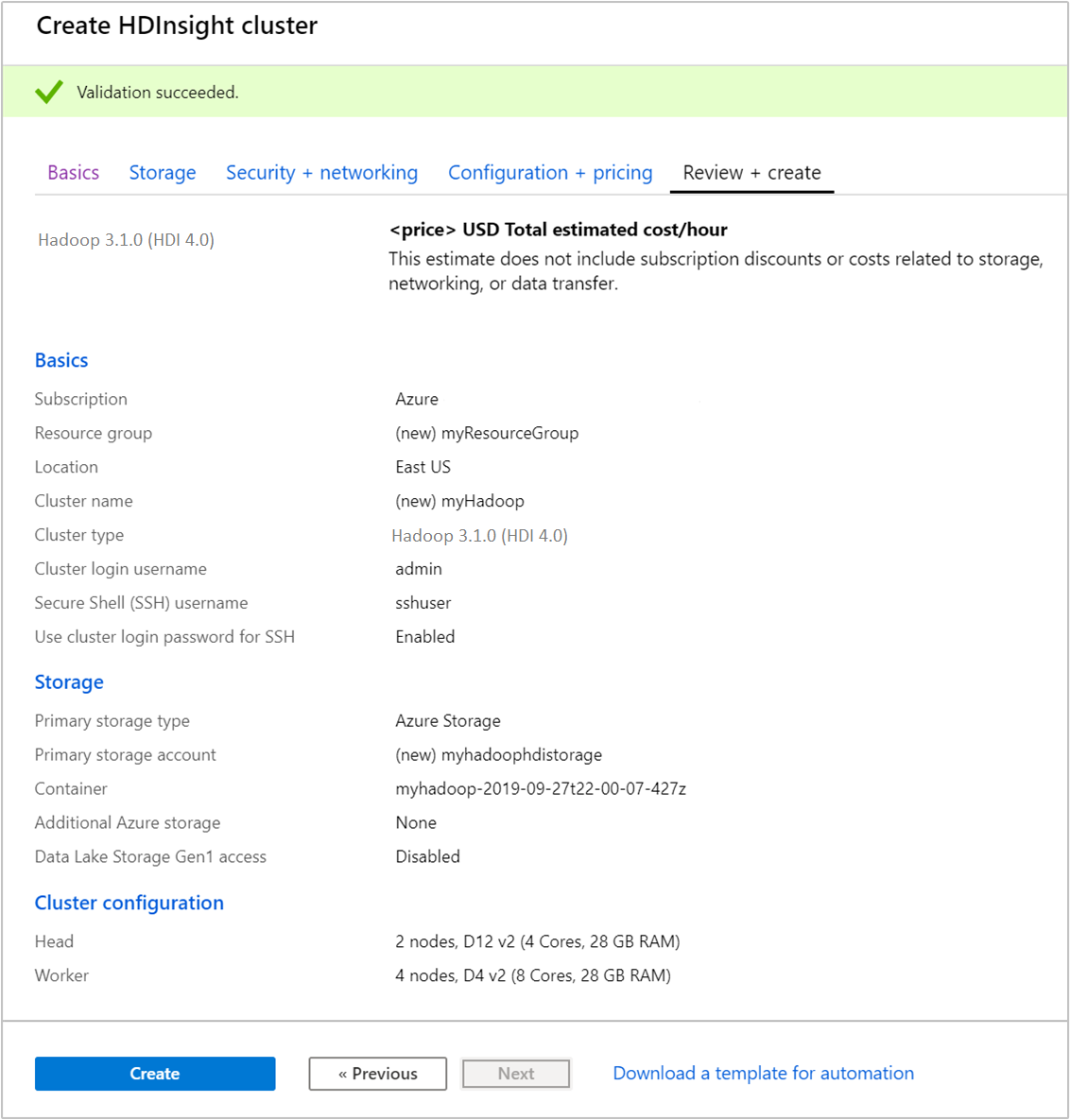
Selecione Criar. A criação de um cluster demora cerca de 20 minutos.
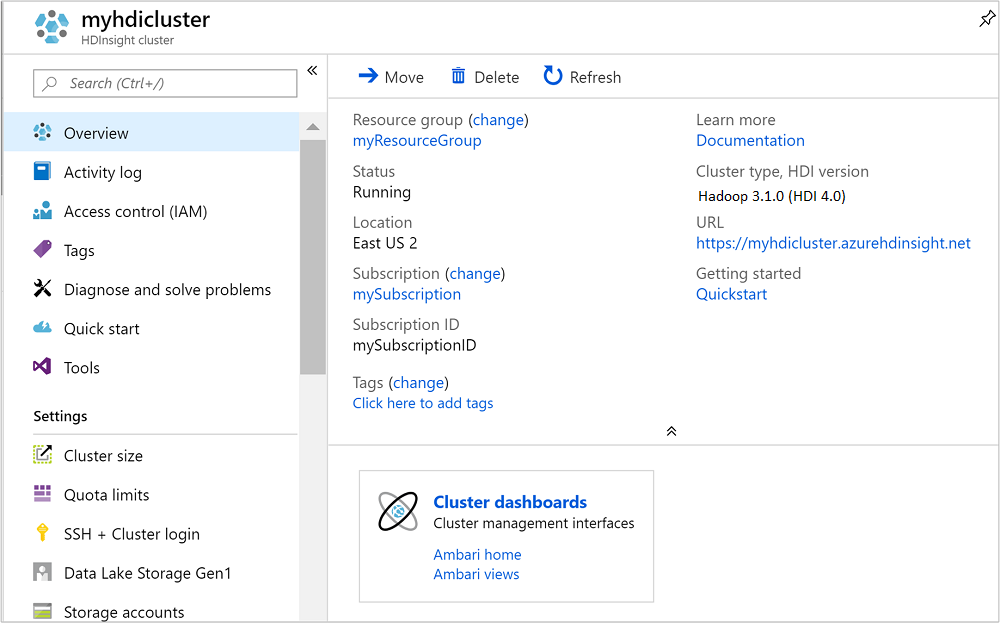
Após a criação do cluster, verá a página de descrição geral do cluster no portal do Azure.
Executar consultas do Apache Hive
O Apache Hive é o componente mais popular utilizado no HDInsight. Existem várias formas de executar tarefas do Hive no HDInsight. Neste início rápido, você usa a visualização Ambari Hive do portal. Para conhecer outros métodos de submissão de tarefas do Hive, consulte Utilizar o Hive no HDInsight.
Nota
O Apache Hive View não está disponível no HDInsight 4.0.
Para abrir o Ambari, a partir da captura de ecrã anterior, selecione Dashboard de Clusters. Você também pode navegar até
https://ClusterName.azurehdinsight.netondeClusterNameestá o cluster criado na seção anterior.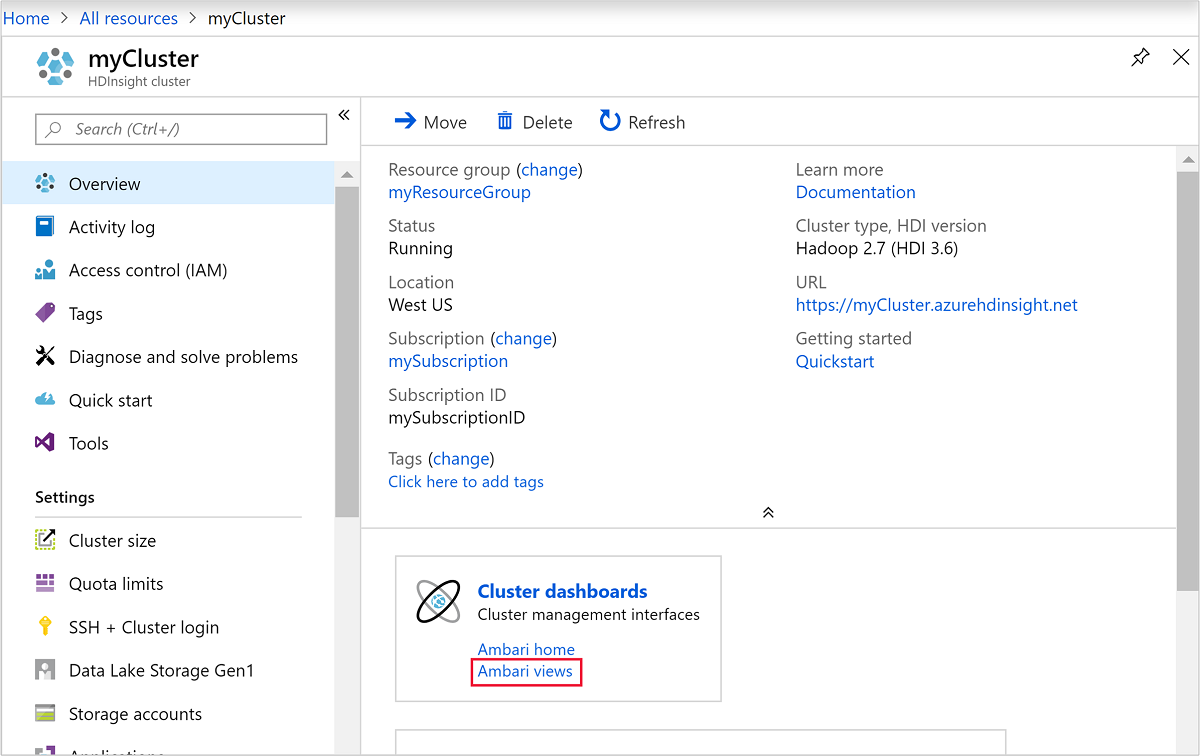
Introduza o nome de utilizador e a palavra-passe do Hadoop que especificou ao criar o cluster. O nome de usuário padrão é
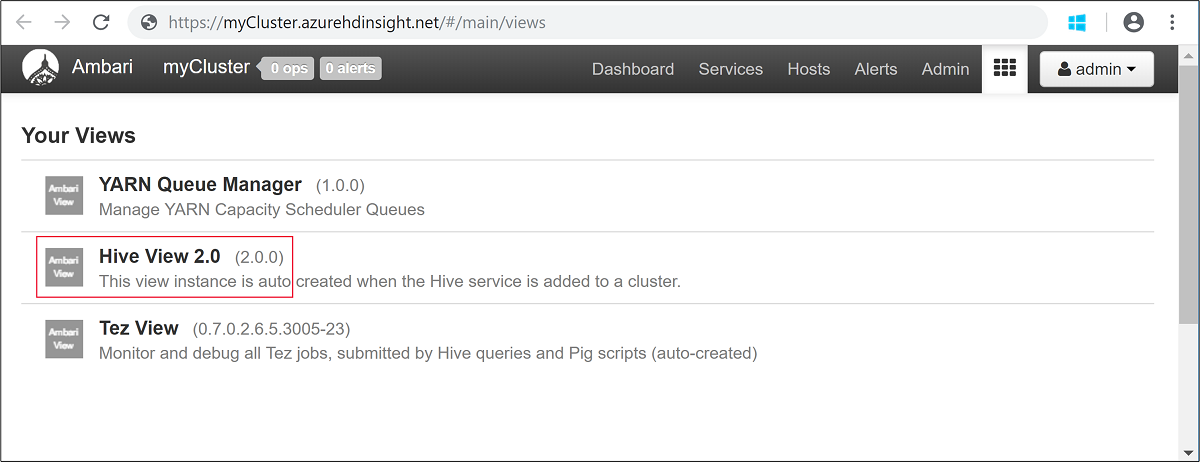
admin.Abra a Vista do Hive conforme mostrado na captura de ecrã seguinte:
No separador CONSULTAS, cole as seguintes declarações HiveQL na folha de cálculo:
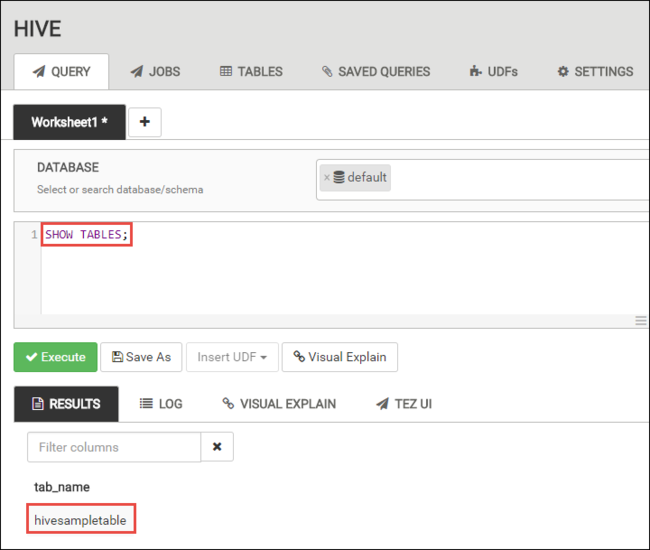
SHOW TABLES;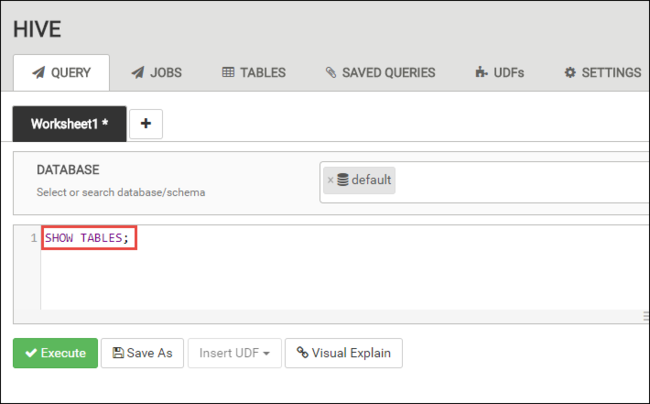
Selecione Execute (Executar). O separador RESULTADOS aparece por baixo do separador CONSULTA e apresenta informações sobre a tarefa.
Quando a consulta for concluída, a guia QUERY exibirá os resultados da operação. Deverá ver uma tabela denomizada hivesampletable. Esta tabela do Hive de exemplo inclui todos os clusters do HDInsight.
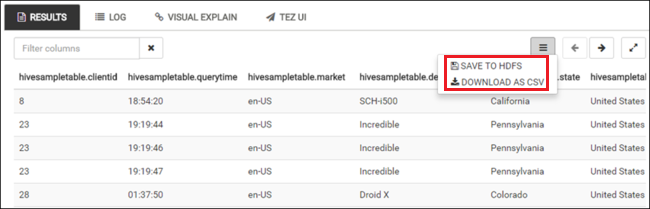
Repita os passos 4 e 5 para executar a seguinte consulta:
SELECT * FROM hivesampletable;Também pode guardar os resultados da consulta. Selecione o botão de menu à direita e especifique se pretende transferir os resultados como um ficheiro CSV ou armazená-los na conta de armazenamento associada ao cluster.
Depois de concluir um trabalho do Hive, você pode exportar os resultados para o Banco de Dados SQL do Azure ou para o banco de dados do SQL Server, também pode visualizar os resultados usando o Excel. Para obter mais informações sobre como usar o Hive no HDInsight, consulte Usar o Apache Hive e o HiveQL com o Apache Hadoop no HDInsight para analisar um arquivo de exemplo do Apache Log4j.
Clean up resources (Limpar recursos)
Depois de concluir o início rápido, convém excluir o cluster. Com o HDInsight, seus dados são armazenados no Armazenamento do Azure, para que você possa excluir com segurança um cluster quando ele não estiver em uso. Você também é cobrado por um cluster HDInsight, mesmo quando ele não está em uso. Como as cobranças para o cluster são muitas vezes mais do que as taxas para armazenamento, faz sentido econômico excluir clusters quando eles não estão em uso.
Nota
Se você estiver prosseguindo imediatamente para o próximo artigo para saber como executar operações ETL usando o Hadoop no HDInsight, convém manter o cluster em execução. Isso ocorre porque no tutorial você precisa criar um cluster Hadoop novamente. No entanto, se você não estiver passando pelo próximo artigo imediatamente, deverá excluir o cluster agora.
Para eliminar o cluster e/ou a conta de armazenamento predefinida
Volte ao separador do browser onde tem o portal do Azure. Deverá estar na página de descrição geral do cluster. Se apenas quiser eliminar o cluster, mas quiser manter a conta de armazenamento predefinida, selecione Eliminar.
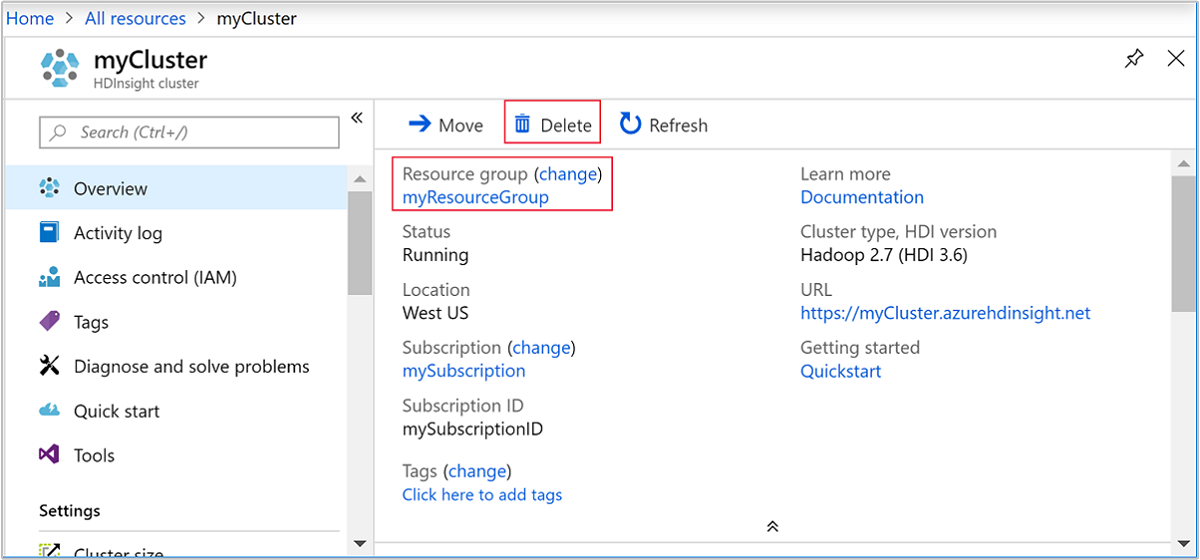
Se desejar excluir o cluster e a conta de armazenamento padrão, selecione o nome do grupo de recursos (realçado na captura de tela anterior) para abrir a página do grupo de recursos.
Selecione Eliminar grupo de recursos para eliminar o grupo de recursos que contém o cluster e a conta de armazenamento predefinida. Tenha em atenção que a eliminação do grupo de recursos elimina a conta de armazenamento. Se pretender manter a conta do Storage, opte por eliminar apenas o cluster.
Próximos passos
Neste guia de início rápido, você aprendeu como criar um cluster HDInsight baseado em Linux usando um modelo do Gerenciador de Recursos e como executar consultas básicas do Hive. No artigo seguinte, vai aprender a realizar uma operação de ETL (extração, transformação e carregamento) com o Hadoop no HDInsight.