Usar C# com streaming do MapReduce no Apache Hadoop no HDInsight
Saiba como usar C# para criar uma solução MapReduce no HDInsight.
O streaming do Apache Hadoop permite executar trabalhos do MapReduce usando um script ou executável. Aqui, o .NET é usado para implementar o mapeador e o redutor para uma solução de contagem de palavras.
.NET no HDInsight
Os clusters HDInsight usam Mono (https://mono-project.com) para executar aplicativos .NET. O Mono versão 4.2.1 está incluído no HDInsight versão 3.6. Para obter mais informações sobre a versão do Mono incluída no HDInsight, consulte Componentes do Apache Hadoop disponíveis com versões do HDInsight.
Para obter mais informações sobre a compatibilidade do Mono com versões do .NET Framework, consulte Compatibilidade do Mono.
Como funciona o streaming do Hadoop
O processo básico usado para streaming neste documento é o seguinte:
- O Hadoop passa dados para o mapeador (mapper.exe neste exemplo) no STDIN.
- O mapeador processa os dados e emite pares chave/valor delimitados por tabulação para STDOUT.
- A saída é lida pelo Hadoop e, em seguida, passada para o redutor (reducer.exe neste exemplo) em STDIN.
- O redutor lê os pares chave/valor delimitados por tabulação, processa os dados e, em seguida, emite o resultado como pares chave/valor delimitados por tabulação no STDOUT.
- A saída é lida pelo Hadoop e gravada no diretório de saída.
Para obter mais informações sobre streaming, consulte Hadoop Streaming.
Pré-requisitos
Visual Studio.
Uma familiaridade com a escrita e criação de código C# destinado ao .NET Framework 4.5.
Uma maneira de carregar arquivos .exe para o cluster. As etapas neste documento usam as Ferramentas Data Lake para Visual Studio para carregar os arquivos no armazenamento primário do cluster.
Se estiver usando o PowerShell, você precisará do Módulo Az.
Um cluster Apache Hadoop no HDInsight. Consulte Introdução ao HDInsight no Linux.
O esquema de URI para o armazenamento primário de clusters. Esse esquema seria
wasb://para o Armazenamento do Azure,abfs://para o Azure Data Lake Storage Gen2 ouadl://para o Azure Data Lake Storage Gen1. Se a transferência segura estiver habilitada para o Armazenamento do Azure ou o Armazenamento Data Lake Gen2, o URI seráwasbs://ouabfss://, respectivamente.
Criar o mapeador
No Visual Studio, crie um novo aplicativo de console do .NET Framework chamado mapeador. Use o seguinte código para o aplicativo:
using System;
using System.Text.RegularExpressions;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
string line;
//Hadoop passes data to the mapper on STDIN
while((line = Console.ReadLine()) != null)
{
// We only want words, so strip out punctuation, numbers, etc.
var onlyText = Regex.Replace(line, @"\.|;|:|,|[0-9]|'", "");
// Split at whitespace.
var words = Regex.Matches(onlyText, @"[\w]+");
// Loop over the words
foreach(var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t1",word);
}
}
}
}
}
Depois de criar o aplicativo, compile-o para produzir o /bin/Debug/mapper.exe arquivo no diretório do projeto.
Criar o redutor
No Visual Studio, crie um novo aplicativo de console do .NET Framework chamado redutor. Use o seguinte código para o aplicativo:
using System;
using System.Collections.Generic;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
//Dictionary for holding a count of words
Dictionary<string, int> words = new Dictionary<string, int>();
string line;
//Read from STDIN
while ((line = Console.ReadLine()) != null)
{
// Data from Hadoop is tab-delimited key/value pairs
var sArr = line.Split('\t');
// Get the word
string word = sArr[0];
// Get the count
int count = Convert.ToInt32(sArr[1]);
//Do we already have a count for the word?
if(words.ContainsKey(word))
{
//If so, increment the count
words[word] += count;
} else
{
//Add the key to the collection
words.Add(word, count);
}
}
//Finally, emit each word and count
foreach (var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t{1}", word.Key, word.Value);
}
}
}
}
Depois de criar o aplicativo, compile-o para produzir o /bin/Debug/reducer.exe arquivo no diretório do projeto.
Carregar para o armazenamento
Em seguida, você precisa carregar os aplicativos mapeadores e redutores para o armazenamento do HDInsight.
No Visual Studio, selecione Exibir Gerenciador de>Servidores.
Clique com o botão direito do rato em Azure, selecione Ligar à Subscrição do Microsoft Azure... e conclua o processo de início de sessão.
Expanda o cluster HDInsight no qual você deseja implantar este aplicativo. Uma entrada com o texto (Conta de armazenamento padrão) é listada.
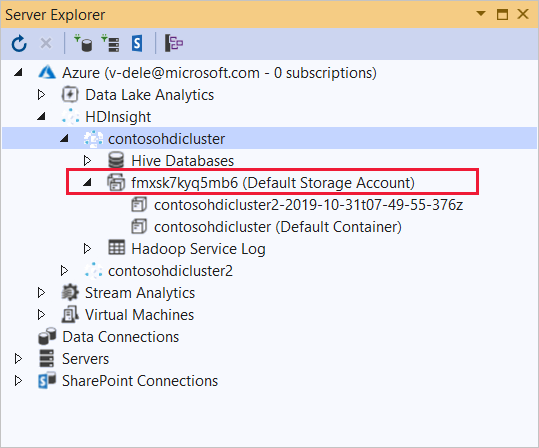
Se a entrada (Conta de Armazenamento Padrão) puder ser expandida, você estará usando uma Conta de Armazenamento do Azure como armazenamento padrão para o cluster. Para exibir os arquivos no armazenamento padrão para o cluster, expanda a entrada e clique duas vezes em (Contêiner Padrão).
Se a entrada (Conta de Armazenamento Padrão) não puder ser expandida, você estará usando o Armazenamento do Azure Data Lake como o armazenamento padrão para o cluster. Para exibir os arquivos no armazenamento padrão do cluster, clique duas vezes na entrada (Conta de armazenamento padrão).
Para carregar os arquivos .exe, use um dos seguintes métodos:
Se você estiver usando uma Conta de Armazenamento do Azure, selecione o ícone Carregar Blob.

Na caixa de diálogo Carregar Novo Arquivo, em Nome do arquivo, selecione Procurar. Na caixa de diálogo Carregar Blob, vá para a pasta bin\debug do projeto mapeador e escolha o arquivo mapper.exe. Finalmente, selecione Abrir e, em seguida , OK para concluir o upload.
Para o Armazenamento do Azure Data Lake, clique com o botão direito do mouse em uma área vazia na listagem de arquivos e selecione Carregar. Finalmente, selecione o arquivo mapper.exe e, em seguida, selecione Abrir.
Quando o mapper.exe upload terminar, repita o processo de upload para o arquivo reducer.exe .
Executar um trabalho: Usando uma sessão SSH
O procedimento a seguir descreve como executar um trabalho MapReduce usando uma sessão SSH:
Use o comando ssh para se conectar ao cluster. Edite o comando abaixo substituindo CLUSTERNAME pelo nome do cluster e digite o comando:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netUse um dos seguintes comandos para iniciar o trabalho MapReduce:
Se o armazenamento padrão for o Armazenamento do Azure:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files wasbs:///mapper.exe,wasbs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutSe o armazenamento padrão for Data Lake Storage Gen1:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files adl:///mapper.exe,adl:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutSe o armazenamento padrão for Data Lake Storage Gen2:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files abfs:///mapper.exe,abfs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout
A lista a seguir descreve o que cada parâmetro e opção representa:
Parâmetro Description hadoop-streaming.jar Especifica o arquivo jar que contém a funcionalidade MapReduce de streaming. -ficheiros Especifica os arquivos mapper.exe e reducer.exe para este trabalho. A wasbs:///declaração ,adl:///, ouabfs:///protocolo antes de cada arquivo é o caminho para a raiz do armazenamento padrão para o cluster.-mapeador Especifica o arquivo que implementa o mapeador. -redutor Especifica o arquivo que implementa o redutor. -entrada Especifica os dados de entrada. -realização Especifica o diretório de saída. Quando o trabalho MapReduce for concluído, use o seguinte comando para exibir os resultados:
hdfs dfs -text /example/wordcountout/part-00000O texto a seguir é um exemplo dos dados retornados por este comando:
you 1128 young 38 younger 1 youngest 1 your 338 yours 4 yourself 34 yourselves 3 youth 17
Executar um trabalho: Usando o PowerShell
Use o seguinte script do PowerShell para executar um trabalho do MapReduce e baixar os resultados.
# Login to your Azure subscription
$context = Get-AzContext
if ($context -eq $null)
{
Connect-AzAccount
}
$context
# Get HDInsight info
$clusterName = Read-Host -Prompt "Enter the HDInsight cluster name"
$creds=Get-Credential -Message "Enter the login for the cluster"
# Path for job output
$outputPath="/example/wordcountoutput"
# Progress indicator
$activity="C# MapReduce example"
Write-Progress -Activity $activity -Status "Getting cluster information..."
#Get HDInsight info so we can get the resource group, storage, etc.
$clusterInfo = Get-AzHDInsightCluster -ClusterName $clusterName
$resourceGroup = $clusterInfo.ResourceGroup
$storageActArr=$clusterInfo.DefaultStorageAccount.split('.')
$storageAccountName=$storageActArr[0]
$storageType=$storageActArr[1]
# Progress indicator
#Define the MapReduce job
# Note: using "/mapper.exe" and "/reducer.exe" looks in the root
# of default storage.
$jobDef=New-AzHDInsightStreamingMapReduceJobDefinition `
-Files "/mapper.exe","/reducer.exe" `
-Mapper "mapper.exe" `
-Reducer "reducer.exe" `
-InputPath "/example/data/gutenberg/davinci.txt" `
-OutputPath $outputPath
# Start the job
Write-Progress -Activity $activity -Status "Starting MapReduce job..."
$job=Start-AzHDInsightJob `
-ClusterName $clusterName `
-JobDefinition $jobDef `
-HttpCredential $creds
#Wait for the job to complete
Write-Progress -Activity $activity -Status "Waiting for the job to complete..."
Wait-AzHDInsightJob `
-ClusterName $clusterName `
-JobId $job.JobId `
-HttpCredential $creds
Write-Progress -Activity $activity -Completed
# Download the output
if($storageType -eq 'azuredatalakestore') {
# Azure Data Lake Store
# Fie path is the root of the HDInsight storage + $outputPath
$filePath=$clusterInfo.DefaultStorageRootPath + $outputPath + "/part-00000"
Export-AzDataLakeStoreItem `
-Account $storageAccountName `
-Path $filePath `
-Destination output.txt
} else {
# Az.Storage account
# Get the container
$container=$clusterInfo.DefaultStorageContainer
#NOTE: This assumes that the storage account is in the same resource
# group as HDInsight. If it is not, change the
# --ResourceGroupName parameter to the group that contains storage.
$storageAccountKey=(Get-AzStorageAccountKey `
-Name $storageAccountName `
-ResourceGroupName $resourceGroup)[0].Value
#Create a storage context
$context = New-AzStorageContext `
-StorageAccountName $storageAccountName `
-StorageAccountKey $storageAccountKey
# Download the file
Get-AzStorageBlobContent `
-Blob 'example/wordcountoutput/part-00000' `
-Container $container `
-Destination output.txt `
-Context $context
}
Esse script solicita o nome e a senha da conta de login do cluster, juntamente com o nome do cluster HDInsight. Quando o trabalho é concluído, a saída é baixada para um arquivo chamado output.txt. O texto a output.txt seguir é um exemplo dos dados no arquivo:
you 1128
young 38
younger 1
youngest 1
your 338
yours 4
yourself 34
yourselves 3
youth 17