Usar o Delta Lake no Azure HDInsight no AKS com cluster Apache Spark™ (Visualização)
Nota
Vamos desativar o Azure HDInsight no AKS em 31 de janeiro de 2025. Antes de 31 de janeiro de 2025, você precisará migrar suas cargas de trabalho para o Microsoft Fabric ou um produto equivalente do Azure para evitar o encerramento abrupto de suas cargas de trabalho. Os clusters restantes na sua subscrição serão interrompidos e removidos do anfitrião.
Apenas o apoio básico estará disponível até à data da reforma.
Importante
Esta funcionalidade está atualmente em pré-visualização. Os Termos de Utilização Suplementares para Pré-visualizações do Microsoft Azure incluem mais termos legais que se aplicam a funcionalidades do Azure que estão em versão beta, em pré-visualização ou ainda não disponibilizadas para disponibilidade geral. Para obter informações sobre essa visualização específica, consulte Informações de visualização do Azure HDInsight no AKS. Para perguntas ou sugestões de recursos, envie uma solicitação no AskHDInsight com os detalhes e siga-nos para obter mais atualizações na Comunidade do Azure HDInsight.
O Azure HDInsight no AKS é um serviço gerenciado baseado em nuvem para análise de big data que ajuda as organizações a processar grandes quantidades de dados. Este tutorial mostra como usar o Delta Lake no Azure HDInsight no AKS com cluster Apache Spark™.
Pré-requisito
Criar um cluster Apache Spark™ no Azure HDInsight no AKS
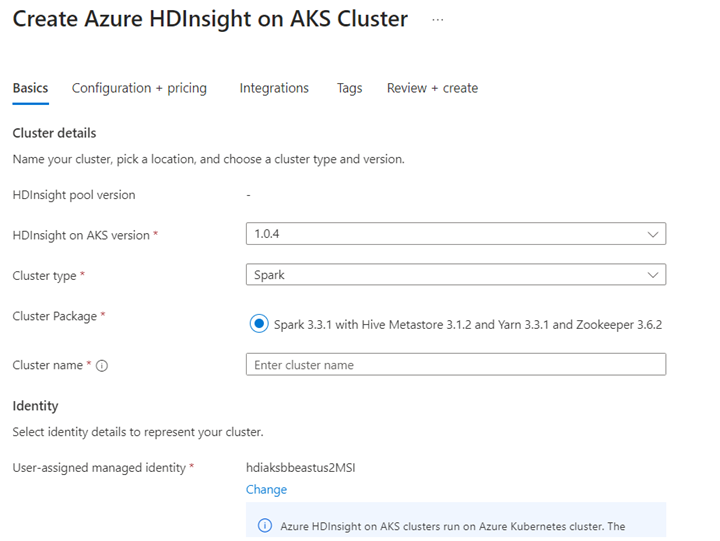
Execute o cenário Delta Lake no Jupyter Notebook. Crie um bloco de anotações Jupyter e selecione "Spark" ao criar um bloco de anotações, já que o exemplo a seguir está no Scala.
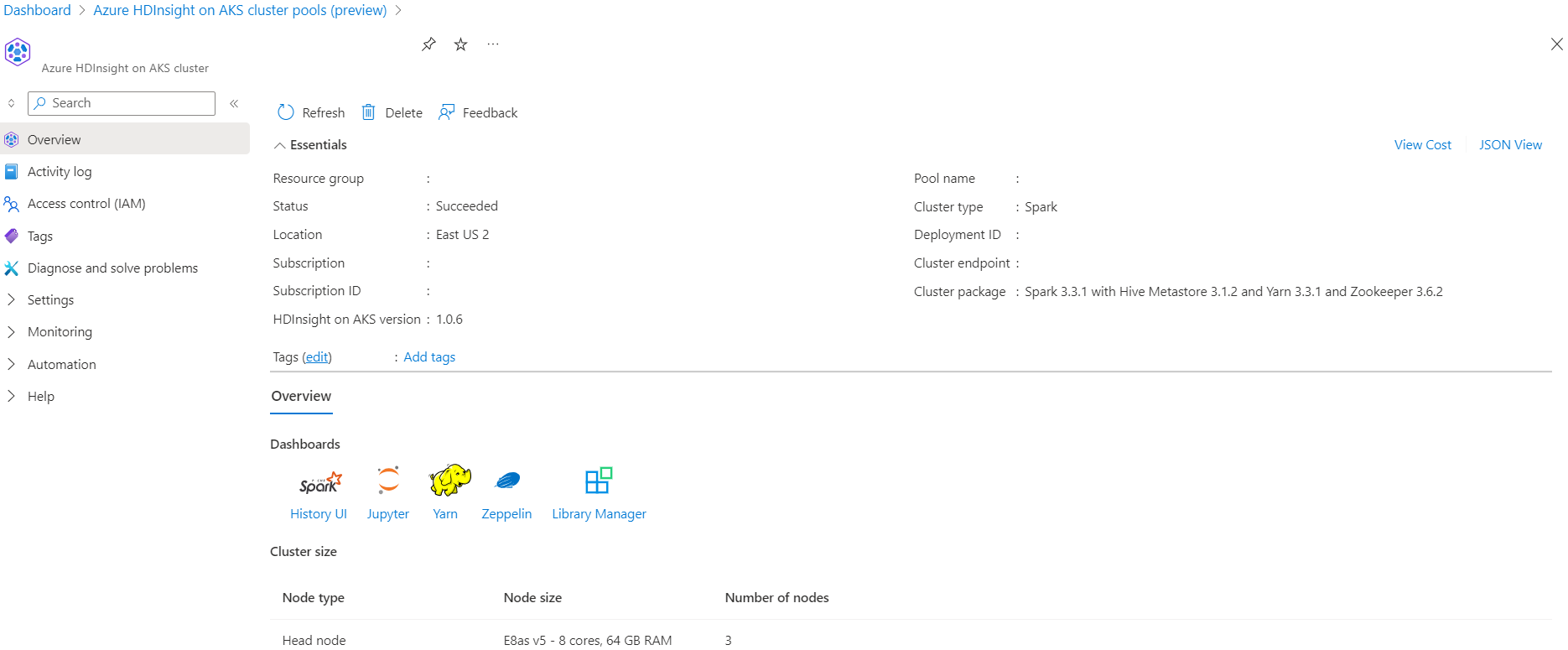


Cenário
- Leia NYC Taxi Parquet Formato de dados - Lista de arquivos Parquet URLs são fornecidos pela NYC Taxi & Limousine Commission.
- Para cada url (arquivo) execute alguma transformação e armazene no formato Delta.
- Calcule a distância média, o custo médio por milha e o custo médio da Tabela Delta usando carga incremental.
- Armazene o valor calculado da Etapa #3 no formato Delta na pasta de saída KPI.
- Crie uma tabela delta na pasta de saída do formato delta (atualização automática).
- A pasta de saída KPI tem várias versões da distância média e do custo médio por milha para uma viagem.
Fornecer configurações necessárias para o lago delta
Delta Lake com matriz de compatibilidade Apache Spark - Delta Lake, altere a versão Delta Lake com base na versão Apache Spark.
%%configure -f
{ "conf": {"spark.jars.packages": "io.delta:delta-core_2.12:1.0.1,net.andreinc:mockneat:0.4.8",
"spark.sql.extensions":"io.delta.sql.DeltaSparkSessionExtension",
"spark.sql.catalog.spark_catalog":"org.apache.spark.sql.delta.catalog.DeltaCatalog"
}
}

Listar o arquivo de dados
Nota
Esses URLs de arquivo são de NYC Taxi & Limousine Commission.
import java.io.File
import java.net.URL
import org.apache.commons.io.FileUtils
import org.apache.hadoop.fs._
// data file object is being used for future reference in order to read parquet files from HDFS
case class DataFile(name:String, downloadURL:String, hdfsPath:String)
// get Hadoop file system
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val fileUrls= List(
"https://d37ci6vzurychx.cloudfront.net/trip-data/fhvhv_tripdata_2022-01.parquet"
)
// Add a file to be downloaded with this Spark job on every node.
val listOfDataFile = fileUrls.map(url=>{
val urlPath=url.split("/")
val fileName = urlPath(urlPath.size-1)
val urlSaveFilePath = s"/tmp/${fileName}"
val hdfsSaveFilePath = s"/tmp/${fileName}"
val file = new File(urlSaveFilePath)
FileUtils.copyURLToFile(new URL(url), file)
// copy local file to HDFS /tmp/${fileName}
// use FileSystem.copyFromLocalFile(boolean delSrc, boolean overwrite, Path src, Path dst)
fs.copyFromLocalFile(true,true,new org.apache.hadoop.fs.Path(urlSaveFilePath),new org.apache.hadoop.fs.Path(hdfsSaveFilePath))
DataFile(urlPath(urlPath.size-1),url, hdfsSaveFilePath)
})

Criar diretório de saída
O local onde você deseja criar a saída de formato delta, altere a transformDeltaOutputPath variável e avgDeltaOutputKPIPath se necessário,
avgDeltaOutputKPIPath- para armazenar KPI médio em formato deltatransformDeltaOutputPath- armazenar saída transformada em formato delta
import org.apache.hadoop.fs._
// this is used to store source data being transformed and stored delta format
val transformDeltaOutputPath = "/nyctaxideltadata/transform"
// this is used to store Average KPI data in delta format
val avgDeltaOutputKPIPath = "/nyctaxideltadata/avgkpi"
// this is used for POWER BI reporting to show Month on Month change in KPI (not in delta format)
val avgMoMKPIChangePath = "/nyctaxideltadata/avgMoMKPIChangePath"
// create directory/folder if not exist
def createDirectory(dataSourcePath: String) = {
val fs:FileSystem = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val path = new Path(dataSourcePath)
if(!fs.exists(path) && !fs.isDirectory(path)) {
fs.mkdirs(path)
}
}
createDirectory(transformDeltaOutputPath)
createDirectory(avgDeltaOutputKPIPath)
createDirectory(avgMoMKPIChangePath)

Criar dados de formato delta a partir do formato Parquet
Os dados de entrada são de
listOfDataFile, onde os dados baixados de https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.pagePara demonstrar a viagem no tempo e a versão, carregue os dados individualmente
Execute a transformação e calcule o seguinte KPI de negócios em carga incremental:
- A distância média
- O custo médio por milha
- O custo médio
Salve dados transformados e KPI no formato delta
import org.apache.spark.sql.functions.udf import org.apache.spark.sql.DataFrame // UDF to compute sum of value paid by customer def totalCustPaid = udf((basePassengerFare:Double, tolls:Double,bcf:Double,salesTax:Double,congSurcharge:Double,airportFee:Double, tips:Double) => { val total = basePassengerFare + tolls + bcf + salesTax + congSurcharge + airportFee + tips total }) // read parquet file from spark conf with given file input // transform data to compute total amount // compute kpi for the given file/batch data def readTransformWriteDelta(fileName:String, oldData:Option[DataFrame], format:String="parquet"):DataFrame = { val df = spark.read.format(format).load(fileName) val dfNewLoad= df.withColumn("total_amount",totalCustPaid($"base_passenger_fare",$"tolls",$"bcf",$"sales_tax",$"congestion_surcharge",$"airport_fee",$"tips")) // union with old data to compute KPI val dfFullLoad= oldData match { case Some(odf)=> dfNewLoad.union(odf) case _ => dfNewLoad } dfFullLoad.createOrReplaceTempView("tempFullLoadCompute") val dfKpiCompute = spark.sql("SELECT round(avg(trip_miles),2) AS avgDist,round(avg(total_amount/trip_miles),2) AS avgCostPerMile,round(avg(total_amount),2) avgCost FROM tempFullLoadCompute") // save only new transformed data dfNewLoad.write.mode("overwrite").format("delta").save(transformDeltaOutputPath) //save compute KPI dfKpiCompute.write.mode("overwrite").format("delta").save(avgDeltaOutputKPIPath) // return incremental dataframe for next set of load dfFullLoad } // load data for each data file, use last dataframe for KPI compute with the current load def loadData(dataFile: List[DataFile], oldDF:Option[DataFrame]):Boolean = { if(dataFile.isEmpty) { true } else { val nextDataFile = dataFile.head val newFullDF = readTransformWriteDelta(nextDataFile.hdfsPath,oldDF) loadData(dataFile.tail,Some(newFullDF)) } } val starTime=System.currentTimeMillis() loadData(listOfDataFile,None) println(s"Time taken in Seconds: ${(System.currentTimeMillis()-starTime)/1000}")
Ler o formato delta usando a tabela delta
- ler dados transformados
- ler dados de KPI
import io.delta.tables._ val dtTransformed: io.delta.tables.DeltaTable = DeltaTable.forPath(transformDeltaOutputPath) val dtAvgKpi: io.delta.tables.DeltaTable = DeltaTable.forPath(avgDeltaOutputKPIPath)
Esquema de impressão
- Imprima o esquema da tabela delta para dados de KPI transformados e médios1.
// transform data schema dtTransformed.toDF.printSchema // Average KPI Data Schema dtAvgKpi.toDF.printSchema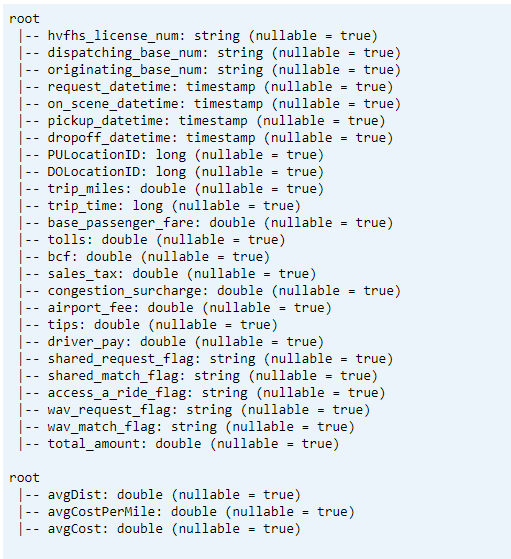
Exibir o último KPI calculado da tabela de dados
dtAvgKpi.toDF.show(false)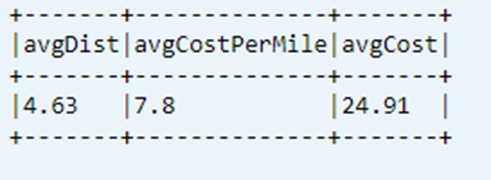


Exibir histórico de KPI computado
Esta etapa exibe o histórico da tabela de transações KPI de _delta_log
dtAvgKpi.history().show(false)

Exibir dados de KPI após cada carregamento de dados
- Usando a viagem no tempo, você pode visualizar as alterações de KPI após cada carregamento
- Você pode armazenar todas as alterações de versão no formato CSV em , para
avgMoMKPIChangePathque o Power BI possa ler essas alterações
val dfTxLog = spark.read.json(s"${transformDeltaOutputPath}/_delta_log/*.json")
dfTxLog.select(col("add")("path").alias("file_path")).withColumn("version",substring(input_file_name(),-6,1)).filter("file_path is not NULL").show(false)

Referência
- Apache, Apache Spark, Spark e nomes de projetos de código aberto associados são marcas comerciais da Apache Software Foundation (ASF).