Como usar o conector Flink/Delta
Nota
Vamos desativar o Azure HDInsight no AKS em 31 de janeiro de 2025. Antes de 31 de janeiro de 2025, você precisará migrar suas cargas de trabalho para o Microsoft Fabric ou um produto equivalente do Azure para evitar o encerramento abrupto de suas cargas de trabalho. Os clusters restantes na sua subscrição serão interrompidos e removidos do anfitrião.
Apenas o apoio básico estará disponível até à data da reforma.
Importante
Esta funcionalidade está atualmente em pré-visualização. Os Termos de Utilização Suplementares para Pré-visualizações do Microsoft Azure incluem mais termos legais que se aplicam a funcionalidades do Azure que estão em versão beta, em pré-visualização ou ainda não disponibilizadas para disponibilidade geral. Para obter informações sobre essa visualização específica, consulte Informações de visualização do Azure HDInsight no AKS. Para perguntas ou sugestões de recursos, envie uma solicitação no AskHDInsight com os detalhes e siga-nos para obter mais atualizações na Comunidade do Azure HDInsight.
Usando o Apache Flink e o Delta Lake juntos, você pode criar uma arquitetura de data lakehouse confiável e escalável. O conector Flink/Delta permite gravar dados em tabelas Delta com transações ACID e exatamente uma vez processando. Isso significa que seus fluxos de dados são consistentes e livres de erros, mesmo se você reiniciar o pipeline Flink a partir de um ponto de verificação. O Flink/Delta Connector garante que seus dados não sejam perdidos ou duplicados e que correspondam à semântica Flink.
Neste artigo, você aprenderá a usar o conector Flink-Delta.
- Leia os dados da tabela delta.
- Escreva os dados em uma tabela delta.
- Consulte-o no Power BI.
O que é o conector Flink/Delta
Flink/Delta Connector é uma biblioteca JVM para ler e gravar dados de aplicativos Apache Flink em tabelas Delta utilizando a biblioteca JVM Delta Standalone. O conector fornece exatamente uma garantia de entrega.
O conector Flink/Delta inclui:
DeltaSink para gravar dados do Apache Flink em uma tabela Delta. DeltaSource para leitura de tabelas Delta usando Apache Flink.
Apache Flink-Delta Connector inclui:
Dependendo da versão do conector, você pode usá-lo com as seguintes versões do Apache Flink:
Connector's version Flink's version
0.4.x (Sink Only) 1.12.0 <= X <= 1.14.5
0.5.0 1.13.0 <= X <= 1.13.6
0.6.0 X >= 1.15.3
0.7.0 X >= 1.16.1 --- We use this in Flink 1.17.0
Pré-requisitos
- Cluster HDInsight Flink 1.17.0 no AKS
- Conector Flink-Delta 0.7.0
- Use o MSI para acessar o ADLS Gen2
- IntelliJ para desenvolvimento
Ler dados da tabela delta
Delta Source pode funcionar em um dos dois modos, descritos a seguir.
Modo Delimitado Adequado para trabalhos em lote, onde queremos ler o conteúdo da tabela Delta apenas para a versão específica da tabela. Crie uma fonte desse modo usando a API DeltaSource.forBoundedRowData.
Modo contínuo Adequado para trabalhos de streaming, onde queremos verificar continuamente a tabela Delta para novas alterações e versões. Crie uma fonte desse modo usando a API DeltaSource.forContinuousRowData.
Exemplo: Criação de código-fonte para tabela Delta, para ler todas as colunas no modo delimitado. Adequado para trabalhos em lote. Este exemplo carrega a versão mais recente da tabela.
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Define the source Delta table path
String deltaTablePath_source = "abfss://container@account_name.dfs.core.windows.net/data/testdelta";
// Create a bounded Delta source for all columns
DataStream<RowData> deltaStream = createBoundedDeltaSourceAllColumns(env, deltaTablePath_source);
public static DataStream<RowData> createBoundedDeltaSourceAllColumns(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}
Escrevendo para a pia Delta
Atualmente, o Delta Sink expõe as seguintes métricas do Flink:

Criação de coletor para tabelas não particionadas
Neste exemplo, mostramos como criar um DeltaSink e conectá-lo a um org.apache.flink.streaming.api.datastream.DataStreamarquivo .
import io.delta.flink.sink.DeltaSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.RowType;
import org.apache.hadoop.conf.Configuration;
// Define the sink Delta table path
String deltaTablePath_sink = "abfss://container@account_name.dfs.core.windows.net/data/testdelta_output";
// Define the source Delta table path
RowType rowType = RowType.of(
DataTypes.STRING().getLogicalType(), // Date
DataTypes.STRING().getLogicalType(), // Time
DataTypes.STRING().getLogicalType(), // TargetTemp
DataTypes.STRING().getLogicalType(), // ActualTemp
DataTypes.STRING().getLogicalType(), // System
DataTypes.STRING().getLogicalType(), // SystemAge
DataTypes.STRING().getLogicalType() // BuildingID
);
createDeltaSink(deltaStream, deltaTablePath_sink, rowType);
public static DataStream<RowData> createDeltaSink(
DataStream<RowData> stream,
String deltaTablePath,
RowType rowType) {
DeltaSink<RowData> deltaSink = DeltaSink
.forRowData(
new Path(deltaTablePath),
new Configuration(),
rowType)
.build();
stream.sinkTo(deltaSink);
return stream;
}
Código completo
Leia os dados de uma tabela delta e colete para outra tabela delta.
package contoso.example;
import io.delta.flink.sink.DeltaSink;
import io.delta.flink.source.DeltaSource;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.RowType;
import org.apache.hadoop.conf.Configuration;
public class DeltaSourceExample {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Define the sink Delta table path
String deltaTablePath_sink = "abfss://container@account_name.dfs.core.windows.net/data/testdelta_output";
// Define the source Delta table path
String deltaTablePath_source = "abfss://container@account_name.dfs.core.windows.net/data/testdelta";
// Define the source Delta table path
RowType rowType = RowType.of(
DataTypes.STRING().getLogicalType(), // Date
DataTypes.STRING().getLogicalType(), // Time
DataTypes.STRING().getLogicalType(), // TargetTemp
DataTypes.STRING().getLogicalType(), // ActualTemp
DataTypes.STRING().getLogicalType(), // System
DataTypes.STRING().getLogicalType(), // SystemAge
DataTypes.STRING().getLogicalType() // BuildingID
);
// Create a bounded Delta source for all columns
DataStream<RowData> deltaStream = createBoundedDeltaSourceAllColumns(env, deltaTablePath_source);
createDeltaSink(deltaStream, deltaTablePath_sink, rowType);
// Execute the Flink job
env.execute("Delta datasource and sink Example");
}
public static DataStream<RowData> createBoundedDeltaSourceAllColumns(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}
public static DataStream<RowData> createDeltaSink(
DataStream<RowData> stream,
String deltaTablePath,
RowType rowType) {
DeltaSink<RowData> deltaSink = DeltaSink
.forRowData(
new Path(deltaTablePath),
new Configuration(),
rowType)
.build();
stream.sinkTo(deltaSink);
return stream;
}
}
Maven Pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>contoso.example</groupId>
<artifactId>FlinkDeltaDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<hadoop-version>3.3.4</hadoop-version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-standalone_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-flink</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Empacote o jar e envie-o para o cluster Flink para ser executado
Carregue o frasco para a ABFS.
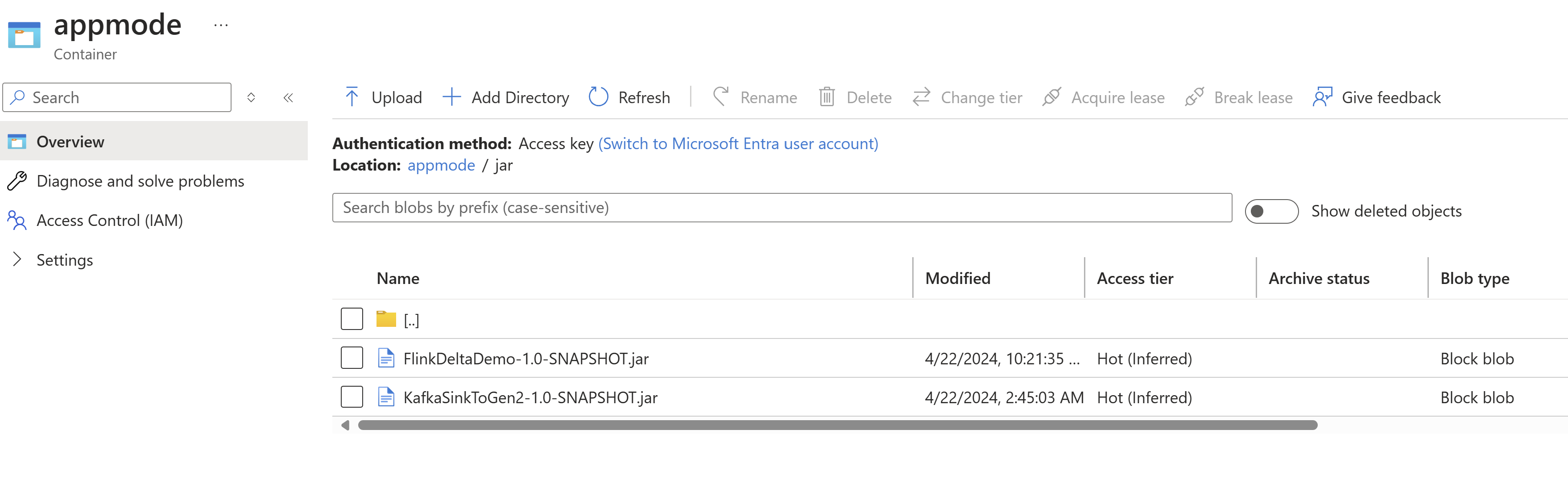
Passe as informações do jar de trabalho no cluster AppMode.
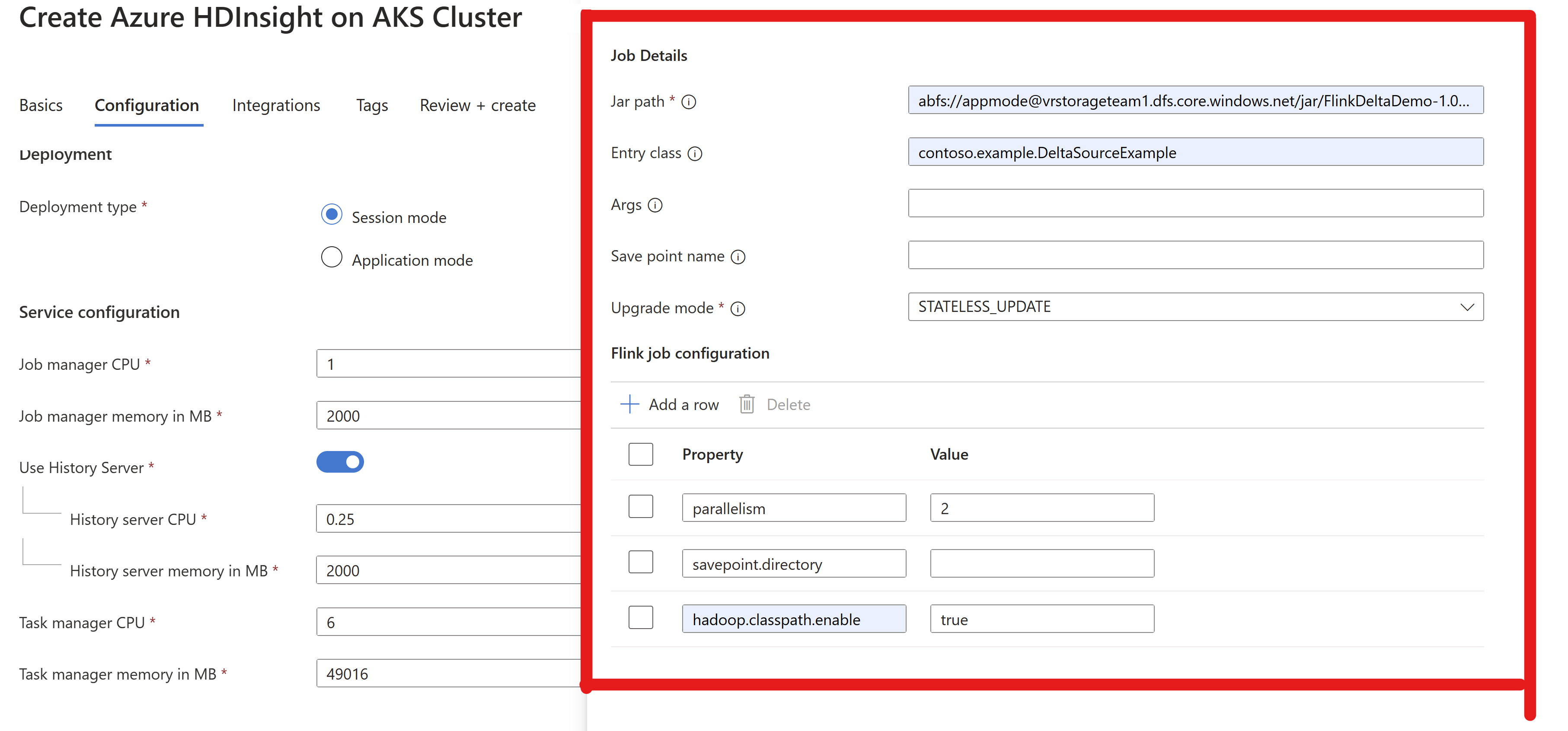
Nota
Ative sempre durante
hadoop.classpath.enablea leitura/gravação na ADLS.Envie o cluster, você deve ser capaz de ver o trabalho em Flink UI.

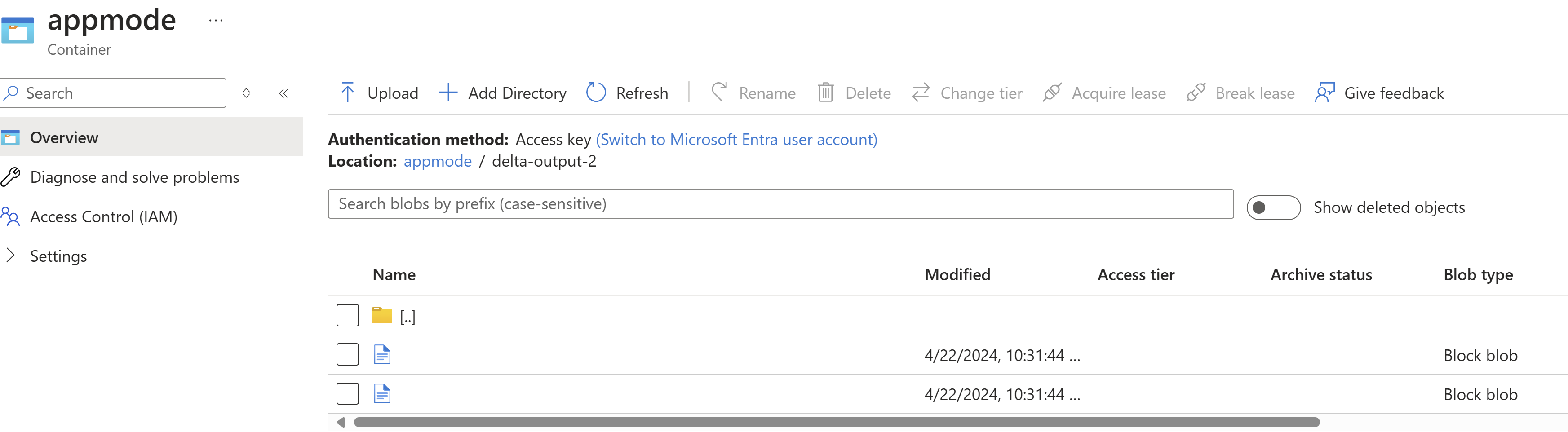
Encontre resultados em ADLS.




Integração do Power BI
Quando os dados estiverem no coletor delta, você poderá executar a consulta na área de trabalho do Power BI e criar um relatório.
Abra a área de trabalho do Power BI para obter os dados usando o conector ADLS Gen2.
URL da conta de armazenamento.

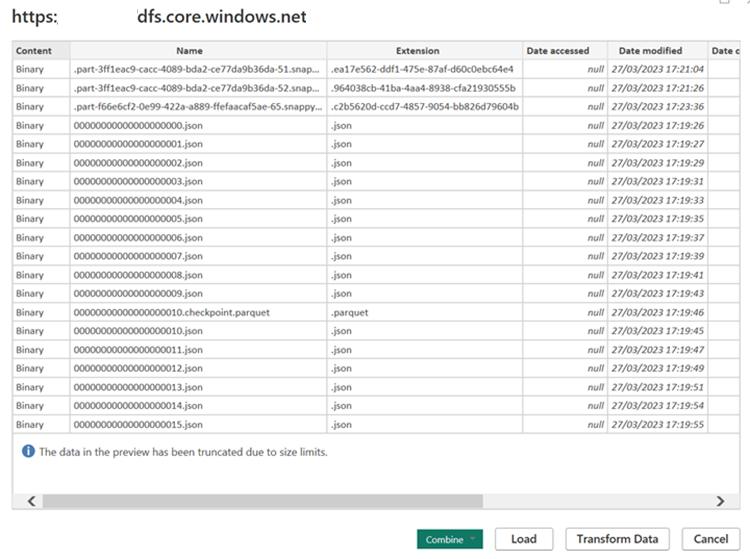
Crie M-query para a origem e invoque a função, que consulta os dados da conta de armazenamento.
Quando os dados estiverem prontamente disponíveis, você poderá criar relatórios.
Referências
- Apache, Apache Flink, Flink e nomes de projetos de código aberto associados são marcas comerciais da Apache Software Foundation (ASF).