Bancos de dados, topologias de implantação e backup
Azure DevOps Server 2022 | Azure DevOps Server 2020 | Azure DevOps Server 2019
Você pode ajudar a proteger sua implantação contra perda de dados criando um agendamento regular de backups para os bancos de dados dos quais Azure DevOps Server depende. Para restaurar completamente a implantação de Azure DevOps Server, primeiro faça backup de todos os bancos de dados Azure DevOps Server.
Se sua implantação incluir SQL Server Reporting Services, você também deverá fazer backup dos bancos de dados que o Azure DevOps usa nesses componentes. Para evitar erros de sincronização ou erros de incompatibilidade de dados, você deve sincronizar todos os backups com o mesmo carimbo de data/hora. A maneira mais fácil de garantir uma sincronização bem-sucedida é usando transações marcadas. Ao marcar rotineiramente transações relacionadas em cada banco de dados, você estabelece uma série de pontos de recuperação comuns nos bancos de dados. Para obter diretrizes passo a passo para fazer backup de uma implantação de servidor único que usa relatórios, consulte Criar um agendamento e um plano de backup.
Backup de bancos de dados
Proteja sua implantação do Azure DevOps contra perda de dados criando backups de banco de dados. A tabela a seguir e as ilustrações que acompanham mostram quais bancos de dados devem ser copiados e fornecem exemplos de como esses bancos de dados podem ser distribuídos fisicamente em uma implantação.
| Tipo de Banco de Dados | Product | Componente necessário? |
|---|---|---|
| Banco de dados de configuração | Azure DevOps Server | Sim |
| Banco de dados de depósito | Azure DevOps Server | Sim |
| Bancos de dados de coleção de projetos | Azure DevOps Server | Sim |
| Bancos de dados de relatórios | SQL Server Reporting Services | Não |
| Bancos de dados de análise | SQL Server Analysis Services | Não |
Topologias de implantação
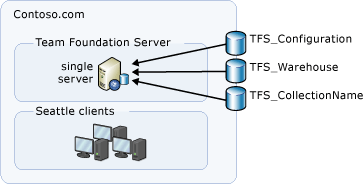
Com base na configuração de implantação, todos os bancos de dados que exigem backup podem estar no mesmo servidor físico, como nesta topologia de exemplo.
Observação
Este exemplo não inclui o Reporting Services ou o Produtos do SharePoint, portanto, você não precisa fazer backup de nenhum banco de dados associado a relatórios, análises ou Produtos do SharePoint.
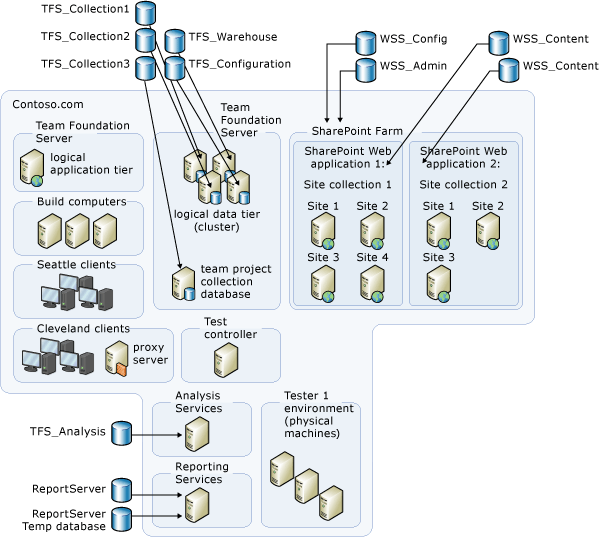
Como alternativa, os bancos de dados podem ser distribuídos em vários servidores e farms de servidores. Neste exemplo de topologia, você deve fazer backup dos seguintes bancos de dados, que são dimensionados em seis servidores ou farms de servidores:
O banco de dados de configuração
O banco de dados do depósito
os bancos de dados de coleção de projetos localizados no cluster do SQL Server
o banco de dados de coleção localizado no servidor autônomo que está executando o SQL Server
os bancos de dados localizados no servidor que está executando o Reporting Services
o banco de dados localizado no servidor que está executando o Analysis Services
os bancos de dados administrativos do Produtos do SharePoint e os bancos de dados do conjunto de sites para aplicativos Web do SharePoint
Se os bancos de dados do SharePoint forem dimensionados em vários servidores, você não poderá usar o recurso Backups Agendados para fazer backup deles. Você deve configurar manualmente os backups para esses bancos de dados e garantir que esses backups sejam sincronizados com os backups de banco de dados Azure DevOps Server. Para obter mais informações, confira Backup manual do Azure DevOps Services.
Em ambos os exemplos, você não precisa fazer backup de nenhum dos clientes que se conectam ao servidor. No entanto, talvez seja necessário limpar manualmente os caches de Azure DevOps Server nos computadores cliente antes que eles possam se reconectar à implantação restaurada.
Bancos de dados para backup
A lista a seguir fornece detalhes adicionais sobre o que você deve fazer backup, dependendo dos recursos de implantação.
Importante
Todos os bancos de dados na lista a seguir são bancos de dados do SQL Server. Embora você possa usar o SQL Server Management Studio para fazer backup de bancos de dados individuais a qualquer momento, evite usar esses backups individuais quando possível. Você poderá experimentar resultados inesperados se restaurar de backups individuais porque os bancos de dados que o Azure DevOps usa estão todos relacionados. Se você fizer backup de apenas um banco de dados, os dados desse banco de dados poderão não ser sincronizados com os dados dos outros bancos de dados.
- Bancos de dados para Azure DevOps Server – a camada de dados lógicos para Azure DevOps Server inclui vários bancos de dados SQL Server, incluindo o banco de dados de configuração, o banco de dados de warehouse e um banco de dados para cada coleção de projetos na implantação. Esses bancos de dados podem estar todos no mesmo servidor, distribuídos em várias instâncias na mesma implantação do SQL Server ou distribuídos em vários servidores. Independentemente de sua distribuição física, você deve fazer backup de todos os bancos de dados no mesmo carimbo de data/hora para ajudar a proteger contra a perda de dados. Você pode executar backups de banco de dados manual ou automaticamente usando planos de manutenção executados em horários ou intervalos específicos.
Importante
A lista de bancos de dados do Azure DevOps não é estática. Um novo banco de dados é criado sempre que você cria uma coleção. Ao criar uma coleção, certifique-se de adicionar o banco de dados dessa coleção ao seu plano de manutenção.
- Bancos de dados para Reporting Services e Analysis Services – se sua implantação usar SQL Server Reporting Services ou SQL Server Analysis Services para gerar relatórios para Azure DevOps Server, você deverá fazer backup dos bancos de dados de relatório e análise. No entanto, você ainda deve regenerar determinados bancos de dados após a restauração, como o warehouse.
- Chave de criptografia para o servidor de relatório – o servidor de relatório tem uma chave de criptografia da qual você deve fazer backup. Essa chave protege as informações confidenciais armazenadas no banco de dados para o servidor de relatório. Você pode fazer backup manualmente dessa chave usando a ferramenta Configuração do Reporting Services ou uma ferramenta de linha de comando.
Preparação avançada para backups
Ao implantar o Azure DevOps, você deve manter um registro das contas criadas e de todos os nomes de computador, senhas e opções de configuração especificados. Você também deve manter uma cópia de todos os materiais de recuperação, documentos e backups de banco de dados e log de transações em um local seguro. Para se proteger contra um desastre, como um incêndio ou um terremoto, você deve manter duplicatas dos backups do servidor em um local diferente do local dos servidores. Essa estratégia ajudará a protegê-lo contra a perda de dados críticos. Como prática recomendada, você deve manter três cópias da mídia de backup e deve manter pelo menos uma cópia fora do local em um ambiente controlado.
Importante
Execute uma restauração de dados de avaliação periodicamente para verificar se o backup dos arquivos foi feito corretamente. Uma restauração de avaliação pode revelar problemas de hardware que não aparecem com uma verificação somente de software.
Ao fazer backup e restaurar um banco de dados, você deve fazer backup dos dados em uma mídia com um endereço de rede (por exemplo, fitas e discos que foram compartilhados como unidades de rede). Seu plano de backup deve incluir provisões para o gerenciamento de mídia, como as seguintes táticas:
- Um plano de rastreamento e gerenciamento para armazenar e reciclar conjuntos de backup.
- Um agendamento para substituir a mídia de backup.
- Em um ambiente de vários servidores, uma decisão de usar backups centralizados ou distribuídos.
- Uma forma de rastrear a vida útil da mídia.
- Um procedimento para minimizar os efeitos da perda de um conjunto de backup ou mídia de backup (por exemplo, uma fita).
- Uma decisão de armazenar conjuntos de backup no local ou fora do local e uma análise de como essa decisão pode afetar o tempo de recuperação.
Como os dados do Azure DevOps são armazenados em bancos de dados do SQL Server, você não precisa fazer backup dos computadores nos quais os clientes do Azure DevOps estão instalados. Se ocorrer uma falha de mídia ou desastre que envolva esses computadores, você poderá reinstalar o software cliente e reconectar-se ao servidor. Ao reinstalar o software cliente, os usuários terão uma alternativa mais limpa e confiável para restaurar um computador cliente a partir de um backup.
Você pode fazer backup de um servidor usando os recursos de Backups Agendados disponíveis ou criando manualmente planos de manutenção no SQL Server para fazer backup dos bancos de dados relacionados à implantação do Azure DevOps. Os bancos de dados do Azure DevOps funcionam em relação uns com os outros e, se você criar um plano manual, deverá fazer backup deles e restaurá-los ao mesmo tempo. Para obter mais informações sobre estratégias de backup de bancos de dados, consulte Fazer backup e restaurar bancos de dados do SQL Server.
Tipos de backups
Entender os tipos de backups disponíveis ajuda a determinar as melhores opções para fazer backup de sua implantação. Por exemplo, se você estiver trabalhando com uma implantação grande e quiser se proteger contra perda de dados usando recursos de armazenamento limitados com eficiência, poderá configurar backups diferenciais, bem como backups de dados completos. Se você estiver usando o SQL Server Always On, poderá fazer backups do banco de dados secundário. Você também pode tentar usar a compactação de backup ou dividir backups em vários arquivos. Aqui estão breves descrições de suas opções de backup:
Backups completos de dados (bancos de dados)
Um backup completo do banco de dados é necessário para a capacidade de recuperação de sua implantação. Um backup completo inclui parte do log de transações para que você possa recuperar o backup completo. Os backups completos são independentes, pois representam todo o banco de dados como ele existia quando você fez o backup. Para obter mais informações, consulte Backups completos do banco de dados.
Backups de dados diferenciais (bancos de dados)
Um backup de banco de dados diferencial registra apenas os dados que foram alterados desde o último backup de banco de dados completo, que é chamado de base diferencial. Os backups de banco de dados diferenciais são menores e mais rápidos do que os backups de banco de dados completos. Essa opção economiza tempo de backup ao custo de maior complexidade. Para bancos de dados grandes, os backups diferenciais podem ocorrer em intervalos mais curtos do que os backups de banco de dados, o que reduz a exposição à perda de trabalho. Para obter mais informações, consulte Backups de banco de dados diferenciais.
Você também deve fazer backup de seus logs de transações regularmente. Esses backups são necessários para recuperar dados quando você usa o modelo de backup de banco de dados completo. Se você fizer backup de logs de transações, poderá recuperar o banco de dados até o ponto de falha ou para um ponto anterior no tempo.
Backups de log de transações
O log de transações é um registro serial de todas as modificações que ocorreram em um banco de dados, além da transação que executou cada modificação. O log de transações registra o início de cada transação, as alterações nos dados e, se necessário, informações suficientes para desfazer as modificações feitas durante essa transação. O log cresce continuamente à medida que as operações registradas ocorrem no banco de dados.
Ao fazer backup de logs de transações, você pode recuperar o banco de dados para um ponto anterior no tempo. Por exemplo, você pode restaurar o banco de dados para um ponto antes que dados indesejados fossem inseridos ou ocorresse uma falha. Além dos backups de banco de dados, os backups de log de transações devem fazer parte de sua estratégia de recuperação. Para obter mais informações, confira Backups de log de transações (SQL Server).
Os backups de log de transações geralmente usam menos recursos do que os backups completos. Portanto, você pode criar backups de log de transações com mais frequência do que backups completos, o que reduz o risco de perda de dados. No entanto, às vezes, um backup de log de transações é maior do que um backup completo. Por exemplo, um banco de dados com uma alta taxa de transação faz com que o log de transações cresça rapidamente. Nessa situação, você deve criar backups de log de transações com mais frequência. Para obter mais informações, confira Solucionar problemas em um log de transações completo (Erro 9002 do SQL Server).
Você pode executar os seguintes tipos de backups de log de transações:
- Um backup de log puro contém apenas registros de log de transações por um intervalo, sem alterações em massa.
- Um backup de log em massa contém páginas de log e dados que foram alteradas por operações em massa. A recuperação pontual não é permitida.
- Um backup da parte final do log é obtido de um banco de dados possivelmente danificado para capturar os registros de log que ainda não foram submetidos a backup. Um backup da parte final do log é feito após uma falha para evitar a perda de trabalho e pode conter dados de log puro ou em massa.
Como a sincronização de dados é crítica para a restauração bem-sucedida de Azure DevOps Server, você deve usar transações marcadas como parte de sua estratégia de backup se estiver configurando backups manualmente. Para obter mais informações, consulte Criar um agendamento e plano de backup e Fazer backup manualmente Azure DevOps Server.
Backups de serviço da camada de aplicativo
O único backup necessário para a camada de aplicativo lógico é para a chave de criptografia do Reporting Services. Se você usar o recurso Backups Agendados para fazer backup de sua implantação, esse backup dessa chave será feito como parte do plano. Você pode supor que deve fazer backup de sites usados como portais de projeto.
Embora você possa fazer backup de uma camada de aplicativo com mais facilidade do que de uma camada de dados, ainda há várias etapas para restaurar uma camada de aplicativo. Você deve instalar outra camada de aplicativo para Azure DevOps Server, redirecionar coleções de projetos para usar a nova camada de aplicativo e redirecionar os sites de portal para projetos.
Nomes de banco de dados padrão
Se você não personalizar os nomes de seus bancos de dados, poderá usar a tabela a seguir para identificar os bancos de dados usados em sua implantação de Azure DevOps Server. Como mencionado anteriormente, nem todas as implantações têm todos esses bancos de dados. Por exemplo, se você não configurou Azure DevOps Server com Reporting Services, não terá os bancos de dados ReportServer ou ReportServerTempDB. Da mesma forma, você não terá o banco de dados para o System Center Virtual Machine Manager (SCVMM), VirtualManagerDB, a menos que configure Azure DevOps Server para dar suporte ao Lab Management. Além disso, os bancos de dados que Azure DevOps Server usa podem ser distribuídos em mais de uma instância do SQL Server ou em mais de um servidor.
Observação
Por padrão, o prefixo TFS_ é adicionado aos nomes de todos os bancos de dados criados automaticamente quando você instala Azure DevOps Server ou enquanto ele está operando.
| Backup de banco de dados | Descrição |
|---|---|
| TFS_Configuration | O banco de dados de configuração para Azure DevOps Server contém o catálogo, os nomes de servidor e os dados de configuração para a implantação. O nome desse banco de dados pode incluir caracteres adicionais entre TFS_ e Configuração, como o nome de usuário da pessoa que instalou Azure DevOps Server. Por exemplo, o nome do banco de dados pode ser TFS_UserNameConfiguration |
| TFS_Warehouse | O banco de dados do depósito contém os dados para criar o depósito que o Reporting Services usa. O nome desse banco de dados pode incluir caracteres adicionais entre TFS_ e Warehouse, como o nome de usuário da pessoa que instalou Azure DevOps Server. Por exemplo, o nome do banco de dados pode ser TFS_UserNameWarehouse. |
| TFS_CollectionName | O banco de dados de uma coleção de projetos contém todos os dados dos projetos dessa coleção. Esses dados incluem código-fonte, configurações de compilação e configurações de gerenciamento de laboratório. O número de bancos de dados de coleção será igual ao número de coleções. Por exemplo, se você tiver três coleções em sua implantação, deverá fazer backup desses três bancos de dados de coleção. O nome de cada banco de dados pode incluir caracteres adicionais entre TFS_ e CollectionName, como o nome de usuário da pessoa que criou a coleção. Por exemplo, o nome de um banco de dados de coleção pode ser TFS_UserNameCollectionName. |
| TFS_Analysis | O banco de dados para SQL Server Analysis Services contém as fontes de dados e os cubos para sua implantação de Azure DevOps Server. O nome desse banco de dados pode incluir caracteres adicionais entre TFS_ e Análise, como o nome de usuário da pessoa que instalou o Analysis Services. Por exemplo, o nome do banco de dados pode ser TFS_UserNameAnalysis. Observação: você pode fazer backup desse banco de dados, mas deve reconstruir o warehouse a partir do banco de dados TFS_Warehouse restaurado. |
| ReportServer | O banco de dados do Reporting Services contém os relatórios e as configurações de relatório para sua implantação de Azure DevOps Server. Observação: se o Reporting Services estiver instalado em um servidor separado de Azure DevOps Server, esse banco de dados poderá não estar presente no servidor da camada de dados para Azure DevOps Server. Nesse caso, você deve configurá-lo, fazer backup e restaurá-lo separadamente de Azure DevOps Server. Você deve sincronizar a manutenção dos bancos de dados para evitar erros de sincronização. |
| ReportServerTempDB | O banco de dados temporário do Reporting Services armazena temporariamente informações quando você executa relatórios específicos. Observação: se o Reporting Services estiver instalado em um servidor separado do Azure DevOps Server, esse banco de dados poderá não estar presente no servidor da camada de dados para Azure DevOps Server. Nesse caso, você deve configurar, fazer backup e restaurá-lo separadamente de Azure DevOps Server. No entanto, você deve sincronizar a manutenção dos bancos de dados para evitar erros de sincronização. |
| VirtualManagerDB | O banco de dados de administração do SCVMM contém as informações exibidas no Console do Administrador do SCVMM, como máquinas virtuais, hosts de máquinas virtuais, servidores de biblioteca de máquinas virtuais e suas propriedades. Observação: se o SCVMM estiver instalado em um servidor separado do Azure DevOps Server, esse banco de dados poderá não estar presente no servidor da camada de dados para Azure DevOps Server. Nesse caso, você deve configurá-lo, fazer backup e restaurá-lo separadamente de Azure DevOps Server. No entanto, você deve usar transações marcadas e sincronizar a manutenção dos bancos de dados para evitar erros de sincronização. |