Como criar pipelines de dados simples, eficientes e de baixa latência
As empresas orientadas por dados de hoje produzem dados continuamente, o que requer pipelines de dados de engenharia que ingerem e transformam continuamente esses dados. Esses pipelines devem ser capazes de processar e entregar dados exatamente uma vez, produzir resultados com latências inferiores a 200 milissegundos e sempre tentar minimizar custos.
Este artigo descreve as abordagens de processamento de fluxo em lote e incremental para pipelines de dados de engenharia, por que o processamento de fluxo incremental é a melhor opção e as próximas etapas para começar a usar as ofertas de processamento de fluxo incremental do Databricks, o Streaming no Azure Databricks e o que é Delta Live Tables?. Esses recursos permitem que você escreva e execute rapidamente pipelines que garantem semântica de entrega, latência, custo e muito mais.
As armadilhas de trabalhos repetidos em lote
Ao configurar seu pipeline de dados, você pode, em primeiro lugar, escrever trabalhos em lote repetidos para ingerir seus dados. Por exemplo, a cada hora você pode executar um trabalho do Spark que lê a partir de sua fonte e grava dados em um coletor como o Delta Lake. O desafio com essa abordagem é processar incrementalmente sua fonte, porque o trabalho do Spark que é executado a cada hora precisa começar onde o último terminou. Você pode registrar o carimbo de data/hora mais recente dos dados processados e, em seguida, selecionar todas as linhas com carimbos de data/hora mais recentes do que esse carimbo de data/hora, mas há armadilhas:
Para executar um pipeline de dados contínuo, você pode tentar agendar um trabalho em lote por hora que leia incrementalmente a partir de sua origem, faça transformações e grave o resultado em um coletor, como o Delta Lake. Esta abordagem pode ter armadilhas:
- Um trabalho do Spark que consulta todos os novos dados após um carimbo de data/hora perderá dados atrasados.
- Um trabalho do Spark que falha pode levar à quebra de garantias exatas uma vez, se não for tratado com cuidado.
- Um trabalho do Spark que lista o conteúdo de locais de armazenamento em nuvem para encontrar novos arquivos se tornará caro.
Em seguida, você ainda precisa transformar repetidamente esses dados. Você pode escrever trabalhos em lote repetidos que, em seguida, agregam seus dados ou aplicam outras operações, o que complica e reduz ainda mais a eficiência do pipeline.
Um exemplo de lote
Para entender completamente as armadilhas da ingestão e transformação em lote para seu pipeline, considere os exemplos a seguir.
Dados perdidos
Dado um tópico Kafka com dados de uso que determinam quanto cobrar de seus clientes e seu pipeline está ingerindo em lotes, a sequência de eventos pode ter esta aparência:
- Seu primeiro lote tem dois registros às 8h e 8h30.
- Você atualiza o carimbo de data/hora mais recente para 8h30.
- Você obtém outro recorde às 8h15.
- Seu segundo lote consulta tudo depois das 8h30, então você perde o registro às 8h15.
Além disso, você não quer cobrar demais ou subestimar seus usuários, então você deve garantir que está ingerindo todos os registros exatamente uma vez.
Processamento redundante
Em seguida, suponha que seus dados contenham linhas de compras de usuários e você queira agregar as vendas por hora para saber os horários mais populares em sua loja. Se as compras para a mesma hora chegarem em lotes diferentes, você terá vários lotes que produzem saídas para a mesma hora:
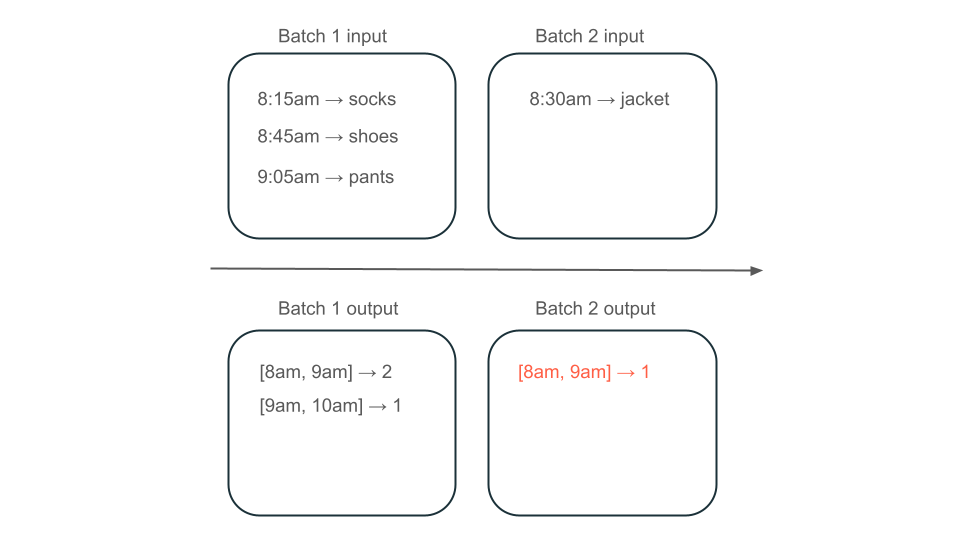
A janela das 8h às 9h tem dois elementos (a saída do lote 1), um elemento (a saída do lote 2) ou três (a saída de nenhum dos lotes)? Os dados necessários para produzir uma determinada janela de tempo aparecem em vários lotes de transformação. Para resolver isso, você pode particionar seus dados por dia e reprocessar toda a partição quando precisar calcular um resultado. Em seguida, você pode substituir os resultados em sua pia:
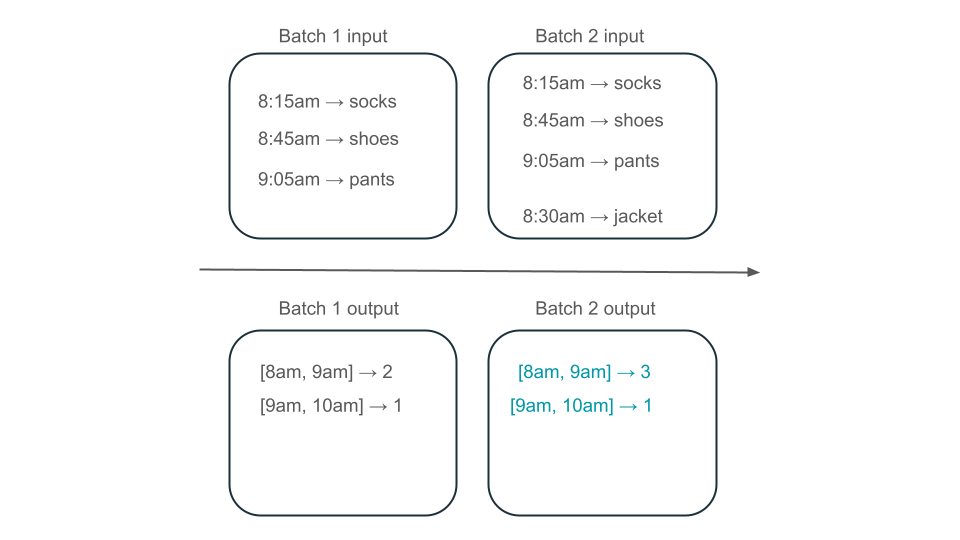
No entanto, isso ocorre às custas da latência e do custo, porque o segundo lote precisa fazer o trabalho desnecessário de processamento de dados que pode já ter processado.
Sem armadilhas com o processamento incremental de fluxo
O processamento de fluxo incremental torna mais fácil evitar todas as armadilhas de trabalhos em lote repetidos para ingerir e transformar dados. O Databricks Structured Streaming e o Delta Live Tables gerenciam as complexidades de implementação do streaming para permitir que você se concentre apenas na sua lógica de negócios. Você só precisa especificar a qual fonte se conectar, quais transformações devem ser feitas nos dados e onde gravar o resultado.
Ingestão incremental
A ingestão incremental no Databricks é alimentada pelo Apache Spark Structured Streaming, que pode consumir incrementalmente uma fonte de dados e gravá-la em um coletor. O mecanismo de Streaming Estruturado pode consumir dados exatamente uma vez e o mecanismo pode lidar com dados fora de ordem. O mecanismo pode ser executado em notebooks ou usando tabelas de streaming no Delta Live Tables.
O mecanismo de streaming estruturado no Databricks fornece fontes de streaming proprietárias, como o AutoLoader, que pode processar arquivos na nuvem de forma incremental. O Databricks também fornece conectores para outros barramentos de mensagens populares como Apache Kafka, Amazon Kinesis, Apache Pulsar e Google Pub/Sub.
Transformação incremental
A transformação incremental em Databricks com Streaming Estruturado permite especificar transformações para DataFrames com a mesma API de uma consulta em lote, mas rastreia dados entre lotes e valores agregados ao longo do tempo para que você não precise fazê-lo. Ele nunca precisa reprocessar dados, por isso é mais rápido e econômico do que trabalhos em lote repetidos. O Streaming Estruturado produz um fluxo de dados que pode ser anexado ao seu coletor, como Delta Lake, Kafka ou qualquer outro conector suportado.
Materialized Views in Delta Live Tables é alimentado pelo motor Enzyme. O Enzyme ainda processa incrementalmente sua fonte, mas em vez de produzir um fluxo, ele cria uma exibição materializada, que é uma tabela pré-computada que armazena os resultados de uma consulta que você lhe dá. O Enzyme é capaz de determinar eficientemente como os novos dados afetam os resultados da sua consulta e mantém a tabela pré-computada atualizada.
As Visualizações Materializadas criam uma visão sobre o seu agregado que está sempre se atualizando de forma eficiente para que, por exemplo, no cenário descrito acima, você saiba que a janela das 8h às 9h tem três elementos.
Streaming estruturado ou tabelas Delta Live?
A diferença significativa entre Structured Streaming e Delta Live Tables é a maneira como você operacionaliza suas consultas de streaming. No Streaming Estruturado, você especifica manualmente muitas configurações e precisa costurar manualmente as consultas. Você deve iniciar explicitamente as consultas, esperar que elas sejam encerradas, cancelá-las em caso de falha e outras ações. No Delta Live Tables, você declarativamente dá ao Delta Live Tables seus pipelines para serem executados e ele os mantém em execução.
O Delta Live Tables também possui recursos como Visualizações Materializadas, que pré-computam de forma eficiente e incremental as transformações de seus dados.
Para obter mais informações sobre esses recursos, consulte Streaming no Azure Databricks e O que é Delta Live Tables?.
Próximos passos
- Crie seu primeiro pipeline com Delta Live Tables. Consulte o Tutorial : Execute o seu primeiro pipeline Delta Live Tables.
- Execute suas primeiras consultas de Streaming Estruturado no Databricks. Consulte Executar sua primeira carga de trabalho de streaming estruturado.
- Use uma visão materializada. Veja Utilizar vistas materializadas no Databricks SQL.