Técnicas de CI/CD com pastas Git e Databricks Git (Repos)
Aprenda técnicas para usar pastas Databricks Git em fluxos de trabalho de CI/CD. Ao configurar pastas Databricks Git no espaço de trabalho, você pode usar o controle de origem para arquivos de projeto em repositórios Git e pode integrá-los em seus pipelines de engenharia de dados.
A figura a seguir mostra uma visão geral das técnicas e do fluxo de trabalho.
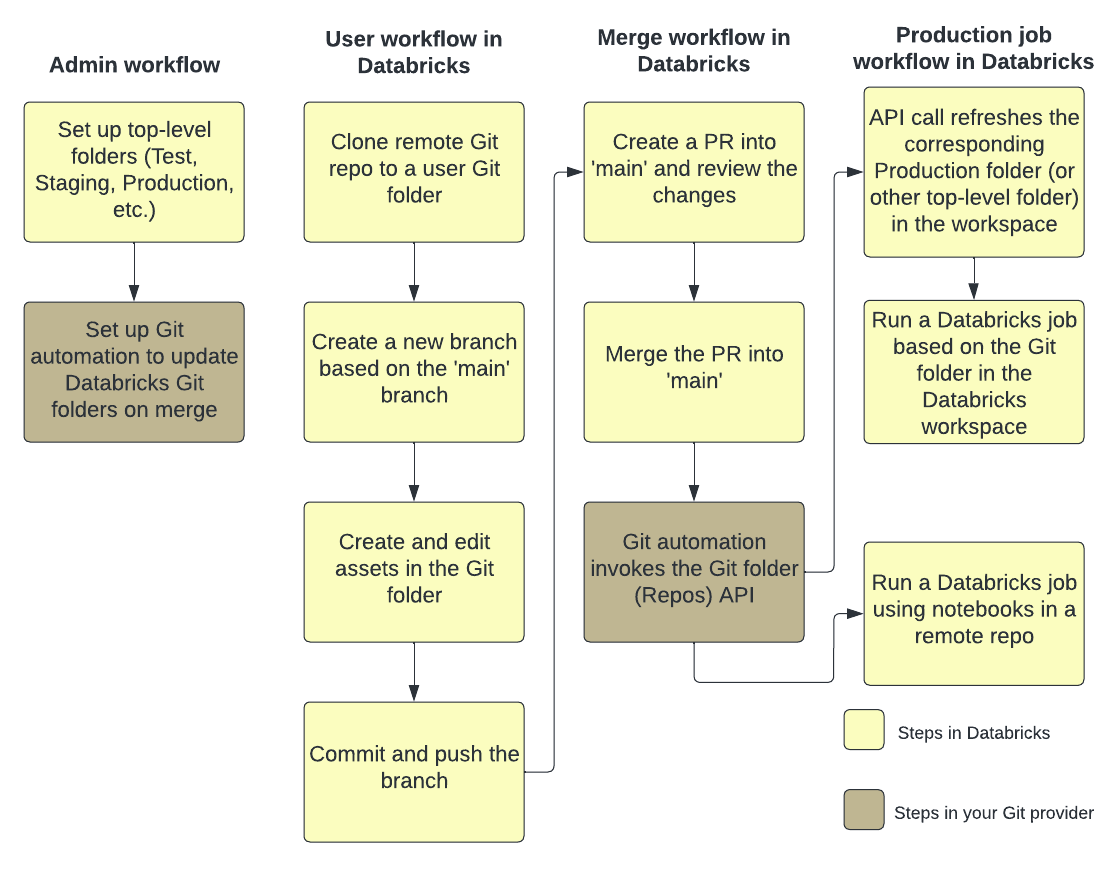
Para obter uma visão geral do CI/CD com o Azure Databricks, consulte O que é CI/CD no Azure Databricks?.
Fluxo de desenvolvimento
As pastas Databricks Git têm pastas de nível de usuário. As pastas de nível de usuário são criadas automaticamente quando os usuários clonam pela primeira vez um repositório remoto. Pode pensar nas pastas Git do Databricks dentro de pastas de utilizador como "checkouts locais", que são individuais para cada utilizador e onde os utilizadores fazem alterações no seu código.
Na sua pasta de usuário nas pastas Git do Databricks, clone seu repositório remoto. Uma prática recomendada é criar uma nova ramificação de recurso ou selecionar uma ramificação criada anteriormente para seu trabalho, em vez de confirmar e enviar diretamente as alterações para a ramificação principal. Você pode fazer alterações, confirmar e enviar alterações por push nessa ramificação. Quando estiver pronto para mesclar seu código, você poderá fazê-lo na interface do usuário de pastas do Git.
Requisitos
Esse fluxo de trabalho requer que você já tenha configurado seude integração do Git.
Nota
A Databricks recomenda que cada desenvolvedor trabalhe em sua própria ramificação de recursos. Para obter informações sobre como resolver conflitos de mesclagem, consulte Resolver conflitos de mesclagem.
Colaborar em pastas Git
O fluxo de trabalho a seguir usa uma ramificação chamada feature-b baseada na ramificação principal.
- Clone seu repositório Git existente em seu espaço de trabalho Databricks.
- Use a interface do usuário de pastas do Git para criar uma ramificação de recurso a partir da ramificação principal. Este exemplo usa uma única ramificação
feature-bde recurso para simplificar. Você pode criar e usar várias ramificações de recursos para fazer seu trabalho. - Faça suas modificações em blocos de anotações do Azure Databricks e outros arquivos no repositório.
- Confirme e envie suas alterações para seu provedor Git.
- Os colaboradores agora podem clonar o repositório Git em sua própria pasta de usuário.
- Trabalhando em uma nova ramificação, um colega de trabalho faz alterações nos blocos de anotações e outros arquivos na pasta Git.
- O colaborador confirma e envia suas alterações para o provedor Git.
- Para mesclar alterações de outras ramificações ou rebasear a ramificação feature-b no Databricks, na interface do usuário das pastas Git use um dos seguintes fluxos de trabalho:
-
Mesclar ramificações. Se não houver conflito, a mesclagem será enviada por push para o repositório Git remoto usando
git pusho . - Rebaseie em outro ramo.
-
Mesclar ramificações. Se não houver conflito, a mesclagem será enviada por push para o repositório Git remoto usando
- Quando estiver pronto para mesclar seu trabalho com o repositório Git remoto e
mainramificação, use a interface do usuário de pastas Git para mesclar as alterações do recurso-b. Se preferir, você pode mesclar as alterações diretamente no repositório Git que apoia sua pasta Git.
Fluxo de trabalho de trabalho de produção
As pastas Databricks Git fornecem duas opções para executar seus trabalhos de produção:
-
Opção 1: Forneça uma referência Git remota na definição de trabalho. Por exemplo, execute um bloco de anotações específico na
mainramificação de um repositório Git. - Opção 2: Configure um repositório Git de produção e chame APIs do Repos para atualizá-lo programaticamente. Execute trabalhos na pasta Databricks Git que clona esse repositório remoto. A chamada à API do Repos deve ser a primeira tarefa no trabalho.
Opção 1: Executar trabalhos usando blocos de anotações em um repositório remoto
Simplifique o processo de definição de trabalho e mantenha uma única fonte de verdade executando um trabalho do Azure Databricks usando blocos de anotações localizados em um repositório Git remoto. Essa referência do Git pode ser uma confirmação, tag ou ramificação do Git e é fornecida por você na definição do trabalho.
Isso ajuda a evitar alterações não intencionais em seu trabalho de produção, como quando um usuário faz edições locais em um repositório de produção ou alterna ramificações. Ele também automatiza a etapa do CD, pois você não precisa criar uma pasta Git de produção separada no Databricks, gerenciar permissões para ela e mantê-la atualizada.
Consulte Usar o Git com trabalhos.
Opção 2: Configurar um diretório Git de produção e a automação Git
Nesta opção, configuras uma pasta Git de produção e a automação para atualizar a pasta Git quando ocorre a fusão.
Etapa 1: configurar pastas de nível superior
O administrador cria pastas de nível superior que não são de usuário. O caso de uso mais comum para essas pastas de nível superior é criar pastas de desenvolvimento, preparo e produção que contenham pastas Databricks Git para as versões ou ramificações apropriadas para desenvolvimento, preparação e produção. Por exemplo, se sua empresa usa a main ramificação para produção, a pasta Git "produção" deve ter o main check-out da ramificação nela.
Normalmente, as permissões nessas pastas de nível superior são somente leitura para todos os usuários não administradores dentro do espaço de trabalho. Para essas pastas de nível superior, recomendamos que você forneça apenas entidades de serviço com permissões CAN EDIT e CAN MANAGE para evitar edições acidentais no código de produção por usuários do espaço de trabalho.
Etapa 2: Configurar atualizações automatizadas para pastas Git do Databricks com a API de pastas Git
Para manter uma pasta Git no Databricks na versão mais recente, pode-se configurar a automação do Git para efetuar uma chamada à API Repos. No seu fornecedor Git, configure a automatização que, após cada mesclagem bem-sucedida de um PR no ramo principal, chame o endpoint da API Repos na pasta Git apropriada para atualizá-la para a versão mais recente.
Por exemplo, no GitHub, isso pode ser alcançado com as Ações do GitHub. Para obter mais informações, consulte a API do Repos.
Usar um principal de serviço para automação com pastas do Databricks Git
Pode utilizar o console de conta do Azure Databricks ou a CLI do Databricks para criar um principal de serviço autorizado a aceder às pastas Git do seu espaço de trabalho.
Para criar uma nova entidade de serviço, consulte Gerenciar entidades de serviço. Quando tiver um principal de serviço no seu espaço de trabalho, pode associar-lhe as suas credenciais do Git para que possa aceder às pastas do Git do seu espaço de trabalho como parte do processo de automação.
Autorizar uma entidade de serviço a aceder a diretórios Git
Para fornecer acesso autorizado às suas pastas Git a um principal de serviço usando o console da conta do Azure Databricks:
Faça logon no seu espaço de trabalho do Azure Databricks. Você deve ter privilégios de administrador em seu espaço de trabalho para concluir essas etapas. Se você não tiver privilégios de administrador para seu espaço de trabalho, solicite-os ou entre em contato com o administrador da conta.
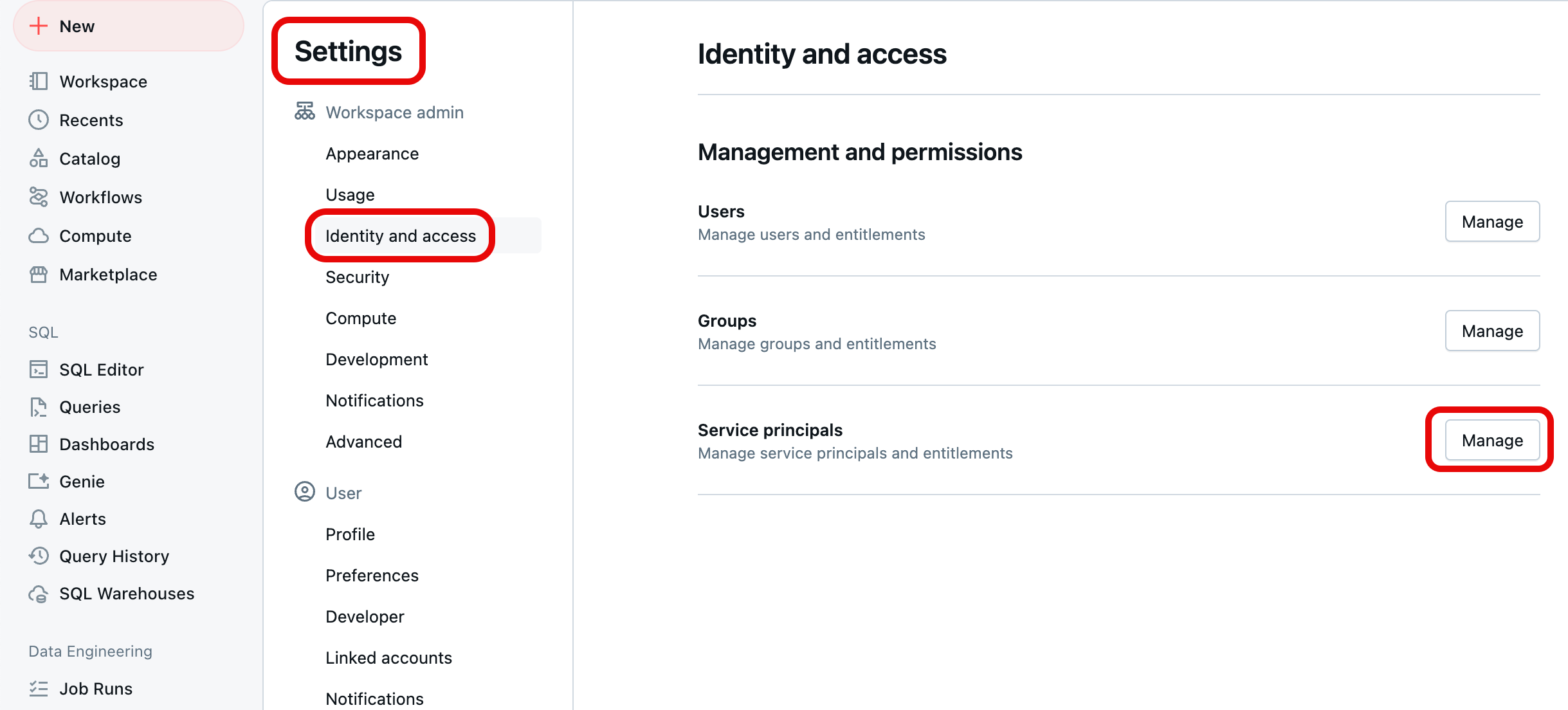
No canto superior direito de qualquer página, clique no seu nome de utilizador e, em seguida, selecione Definições.
Selecione Identidade e Acesso em Administração do Espaço de Trabalho na barra de navegação à esquerda e, em seguida, selecione o botão Gerir para Entidades de Serviço.
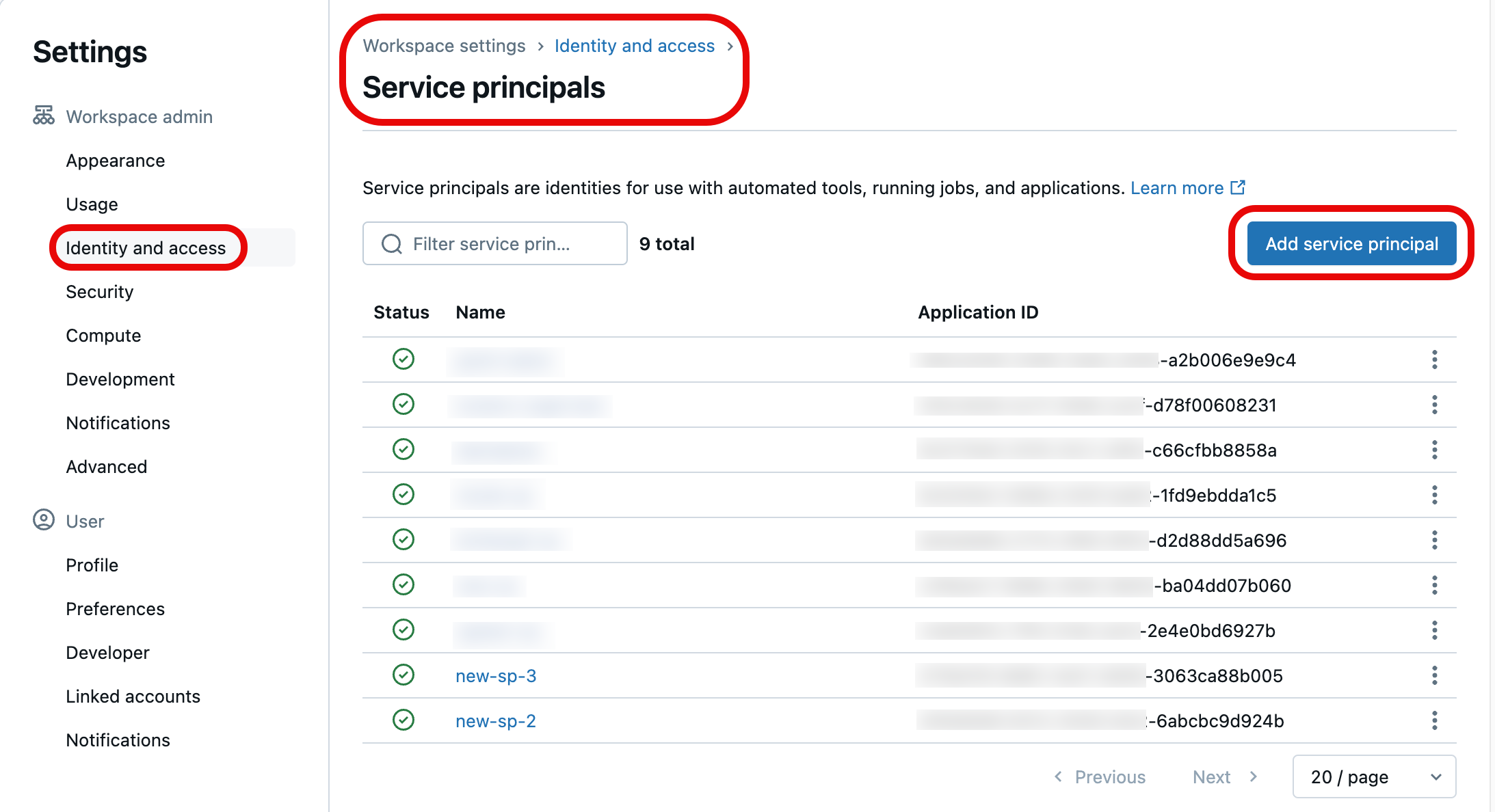
Na lista de entidades de serviço, selecione a que você deseja atualizar com as credenciais do Git. Você também pode criar uma nova entidade de serviço selecionando Adicionar entidade de serviço.
Selecione a guia de integração do Git. (Se você não criou a entidade de serviço ou não recebeu o privilégio de gerente da entidade de serviço nela, ela ficará esmaecida.) Nele, escolha o provedor Git para as credenciais (como o GitHub), selecione de conta do Link Git e, em seguida, selecione Link.
Você também pode usar um token de acesso pessoal (PAT) do Git se não quiser vincular suas próprias credenciais do Git. Para utilizar um token de acesso pessoal (PAT), selecione Token de acesso pessoal e forneça as informações do token para que a conta do Git as use ao autenticar o acesso da entidade de serviço. Para obter mais detalhes sobre como adquirir uma PAT de um provedor Git, consulte Configurar credenciais do Git & conectar um repositório remoto ao Azure Databricks.
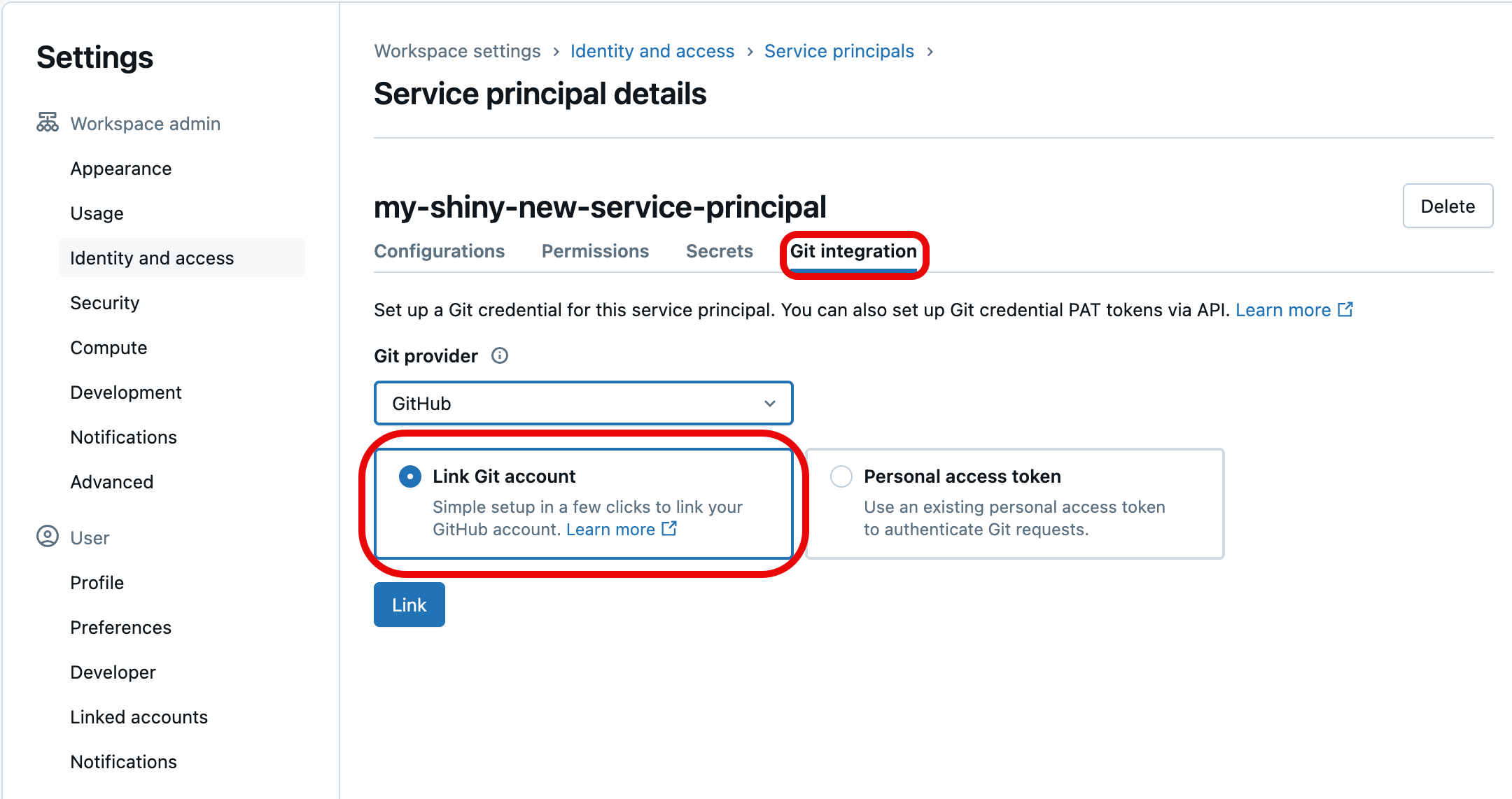
Você será solicitado a selecionar a conta de usuário do Git a ser vinculada. Escolha a conta de utilizador do Git que a entidade de serviço utilizará para acesso e selecione Continuar. (Se não vir a conta de utilizador que pretende utilizar, selecione Usar uma conta diferente.)
Na caixa de diálogo seguinte, selecione Autorizar Databricks. Você verá brevemente a mensagem "Vinculando conta..." e, em seguida, os detalhes atualizados da entidade de serviço.
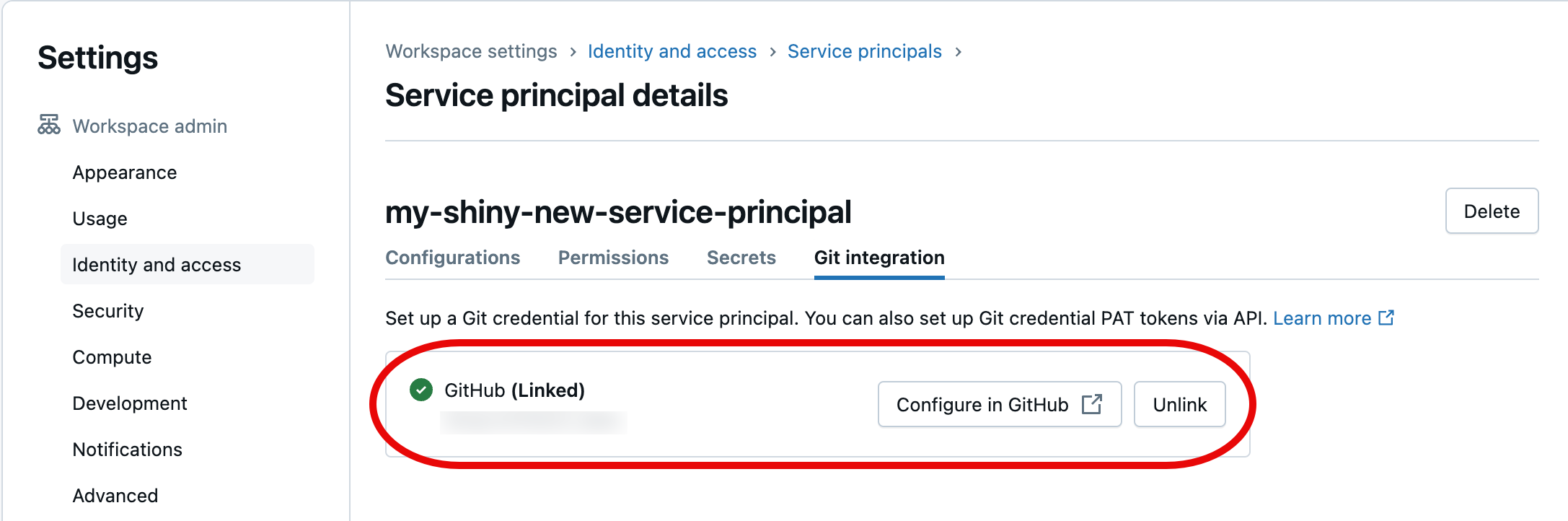
O principal de serviço escolhido irá agora aplicar as credenciais Git vinculadas ao aceder aos recursos da pasta Git do seu espaço de trabalho Azure Databricks como parte da sua automatização.
Integração Terraform
Você também pode gerenciar pastas Databricks Git em uma configuração totalmente automatizada usando Terraform e databricks_repo:
resource "databricks_repo" "this" {
url = "https://github.com/user/demo.git"
}
Para adicionar credenciais Git a uma entidade de serviço usando o Terraform, adicione a seguinte configuração:
provider "databricks" {
# Configuration options
}
provider "databricks" {
alias = "sp"
host = "https://....cloud.databricks.com"
token = databricks_obo_token.this.token_value
}
resource "databricks_service_principal" "sp" {
display_name = "service_principal_name_here"
}
resource "databricks_obo_token" "this" {
application_id = databricks_service_principal.sp.application_id
comment = "PAT on behalf of ${databricks_service_principal.sp.display_name}"
lifetime_seconds = 3600
}
resource "databricks_git_credential" "sp" {
provider = databricks.sp
depends_on = [databricks_obo_token.this]
git_username = "myuser"
git_provider = "azureDevOpsServices"
personal_access_token = "sometoken"
}
Configurar um pipeline de CI/CD automatizado com pastas Git Databricks
Aqui está uma automação simples que pode ser executada como uma ação do GitHub.
Requisitos
- Você criou uma pasta Git em um espaço de trabalho Databricks que está rastreando a ramificação base que está sendo mesclada.
- Você tem um pacote Python que cria os artefatos para colocar em um local DBFS. O seu código deve:
- Atualize o repositório associado à sua ramificação preferida (como
development) para conter as versões mais recentes dos seus blocos de notas. - Crie quaisquer artefatos e copie-os para o caminho da biblioteca.
- Substitua as últimas versões dos artefatos de compilação para evitar ter que atualizar manualmente as versões de artefatos na sua tarefa.
- Atualize o repositório associado à sua ramificação preferida (como
Criar um fluxo de trabalho automatizado de CI/CD
Configure segredos para que seu código possa acessar o espaço de trabalho Databricks. Adicione os seguintes segredos ao repositório Github:
-
DEPLOYMENT_TARGET_URL: Defina este como o URL do seu espaço de trabalho. Não inclua a
/?osubstring. - DEPLOYMENT_TARGET_TOKEN: Defina isso como um Databricks Personal Access Token (PAT). Você pode gerar um token de acesso pessoal (PAT) do Databricks seguindo as instruções em autenticação do token de acesso pessoal do Azure Databricks.
-
DEPLOYMENT_TARGET_URL: Defina este como o URL do seu espaço de trabalho. Não inclua a
Navegue até a guia Ações do repositório Git e clique no botão Novo fluxo de trabalho . Na parte superior da página, selecione Configure o fluxo de trabalho por si mesmo e cole o seguinte script:

# This is a basic automation workflow to help you get started with GitHub Actions. name: CI # Controls when the workflow will run on: # Triggers the workflow on push for main and dev branch push: paths-ignore: - .github branches: # Set your base branch name here - your-base-branch-name # A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: # This workflow contains a single job called "deploy" deploy: # The type of runner that the job will run on runs-on: ubuntu-latest environment: development env: DATABRICKS_HOST: ${{ secrets.DEPLOYMENT_TARGET_URL }} DATABRICKS_TOKEN: ${{ secrets.DEPLOYMENT_TARGET_TOKEN }} REPO_PATH: /Workspace/Users/someone@example.com/workspace-builder DBFS_LIB_PATH: dbfs:/path/to/libraries/ LATEST_WHEEL_NAME: latest_wheel_name.whl # Steps represent a sequence of tasks that will be executed as part of the job steps: # Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it - uses: actions/checkout@v3 - name: Setup Python uses: actions/setup-python@v3 with: # Version range or exact version of a Python version to use, using SemVer's version range syntax. python-version: 3.8 # Download the Databricks CLI. See https://github.com/databricks/setup-cli - uses: databricks/setup-cli@main - name: Install mods run: | pip install pytest setuptools wheel - name: Extract branch name shell: bash run: echo "##[set-output name=branch;]$(echo ${GITHUB_REF#refs/heads/})" id: extract_branch - name: Update Databricks Git folder run: | databricks repos update ${{env.REPO_PATH}} --branch "${{ steps.extract_branch.outputs.branch }}" - name: Build Wheel and send to Databricks DBFS workspace location run: | cd $GITHUB_WORKSPACE python setup.py bdist_wheel dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}} # there is only one wheel file; this line copies it with the original version number in file name and overwrites if that version of wheel exists; it does not affect the other files in the path dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}}${{env.LATEST_WHEEL_NAME}} # this line copies the wheel file and overwrites the latest version with itAtualize os seguintes valores de variáveis de ambiente com os seus:
-
DBFS_LIB_PATH: O caminho no DBFS para as bibliotecas (rodas) que você usará nesta automação, que começa com
dbfs:. Por exemplo,dbfs:/mnt/myproject/libraries. - REPO_PATH: O caminho em seu espaço de trabalho Databricks para a pasta Git onde os blocos de anotações serão atualizados.
-
LATEST_WHEEL_NAME: O nome do último arquivo de roda Python compilado (
.whl). Isso é usado para evitar a atualização manual de versões de roda em seus trabalhos do Databricks. Por exemplo,your_wheel-latest-py3-none-any.whl.
-
DBFS_LIB_PATH: O caminho no DBFS para as bibliotecas (rodas) que você usará nesta automação, que começa com
Selecione Confirmar alterações... para confirmar o script como um fluxo de trabalho de Ações do GitHub. Depois que a solicitação pull para este fluxo de trabalho for mesclada, vá para a guia Ações do repositório Git e confirme se as ações foram bem-sucedidas.