Janeiro de 2019
Esses recursos e aprimoramentos da plataforma Azure Databricks foram lançados em janeiro de 2019.
Nota
Os lançamentos são encenados. Sua conta do Azure Databricks pode não ser atualizada até uma semana após a data de lançamento inicial.
Próxima alteração: Python 3 para se tornar o padrão quando você cria clusters
Janeiro 29, 2019
Quando a plataforma Databricks versão 2.91 for lançada em meados de fevereiro, a versão padrão do Python para novos clusters mudará do Python 2 para o Python 3. Os clusters existentes não alterarão suas versões do Python, é claro. Mas se você tem o hábito de tomar o padrão Python 2 quando cria novos clusters, você precisará começar a prestar atenção à sua seleção de versão do Python.
Lançamento do Databricks Runtime 5.2 para Machine Learning (Beta)
Janeiro 24, 2019
O Databricks Runtime 5.2 ML é construído sobre o Databricks Runtime 5.2 (EoS). Ele contém muitas bibliotecas populares de aprendizado de máquina, incluindo TensorFlow, PyTorch, Keras e XGBoost, e fornece treinamento distribuído do TensorFlow usando Horovod. Além das atualizações da biblioteca desde o Databricks Runtime ML 5.1, o Databricks Runtime 5.2 ML inclui os seguintes novos recursos:
- O GraphFrames agora suporta a API Pregel (Python) com otimizações de desempenho do Databricks.
-
HorovodRunner acrescenta:
- Em um cluster de GPU, os processos de treinamento são mapeados para GPUs em vez de nós de trabalho para simplificar o suporte a tipos de instância de várias GPUs. Este suporte integrado permite-lhe distribuir para todas as GPUs numa máquina multi-GPU sem código personalizado.
-
HorovodRunner.run()agora retorna o valor de retorno do primeiro processo de treinamento.
Consulte as notas de versão completas do Databricks Runtime 5.2 ML. d
Lançamento do Databricks Runtime 5.2
Janeiro 24, 2019
O Databricks Runtime 5.2 já está disponível. O Databricks Runtime 5.2 inclui o Apache Spark 2.4.0, novos recursos e upgrades Delta Lake e Structured Streaming e bibliotecas Python, R, Java e Scala atualizadas. Para obter detalhes, consulte Databricks Runtime 5.2 (EoS).
Vista JSON da configuração de clusters
Janeiro 15-22, 2019
A página de configuração do cluster agora oferece suporte a uma exibição JSON:
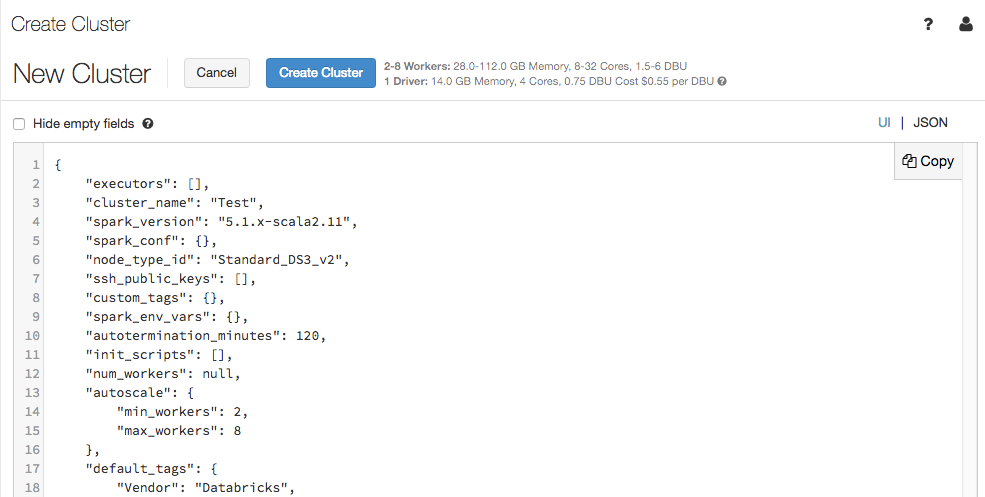
O modo de exibição JSON é somente leitura. No entanto, você pode copiar o JSON e usá-lo para criar e atualizar clusters com a API Clusters.
IU de Clusters
15 a 22 de janeiro de 2019: Versão 2.89
A página de criação de cluster foi limpa e reorganizada para facilitar o uso, incluindo uma nova alternância de Opções Avançadas.
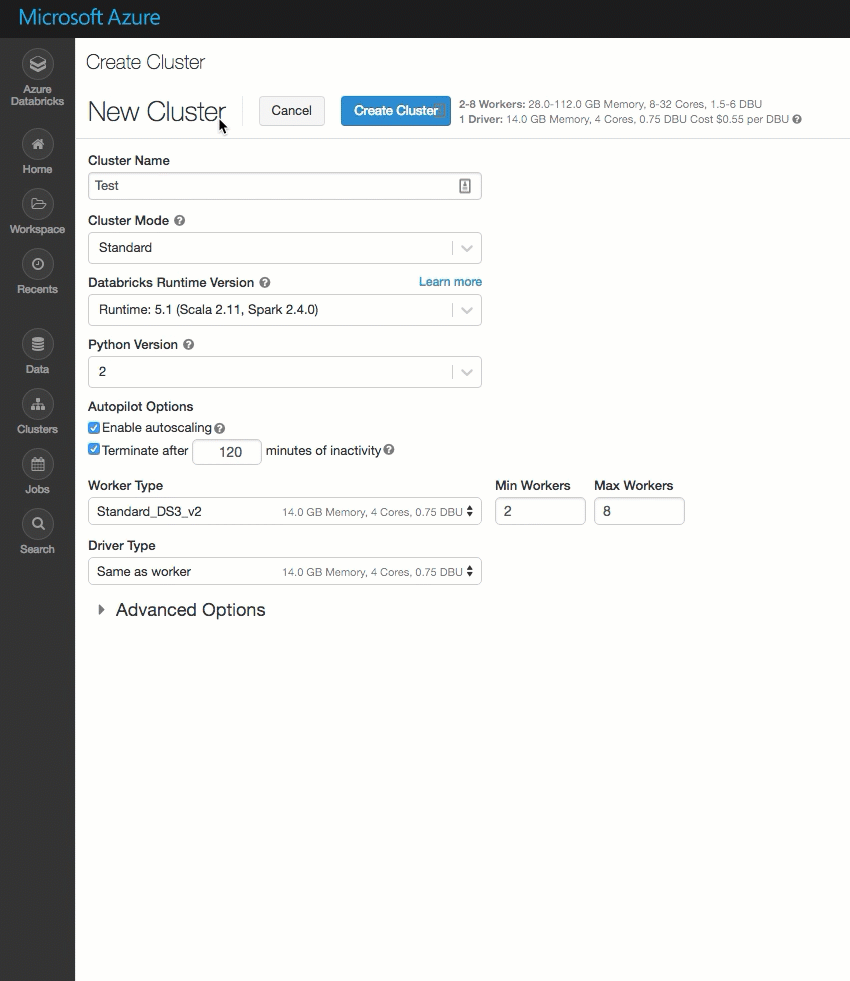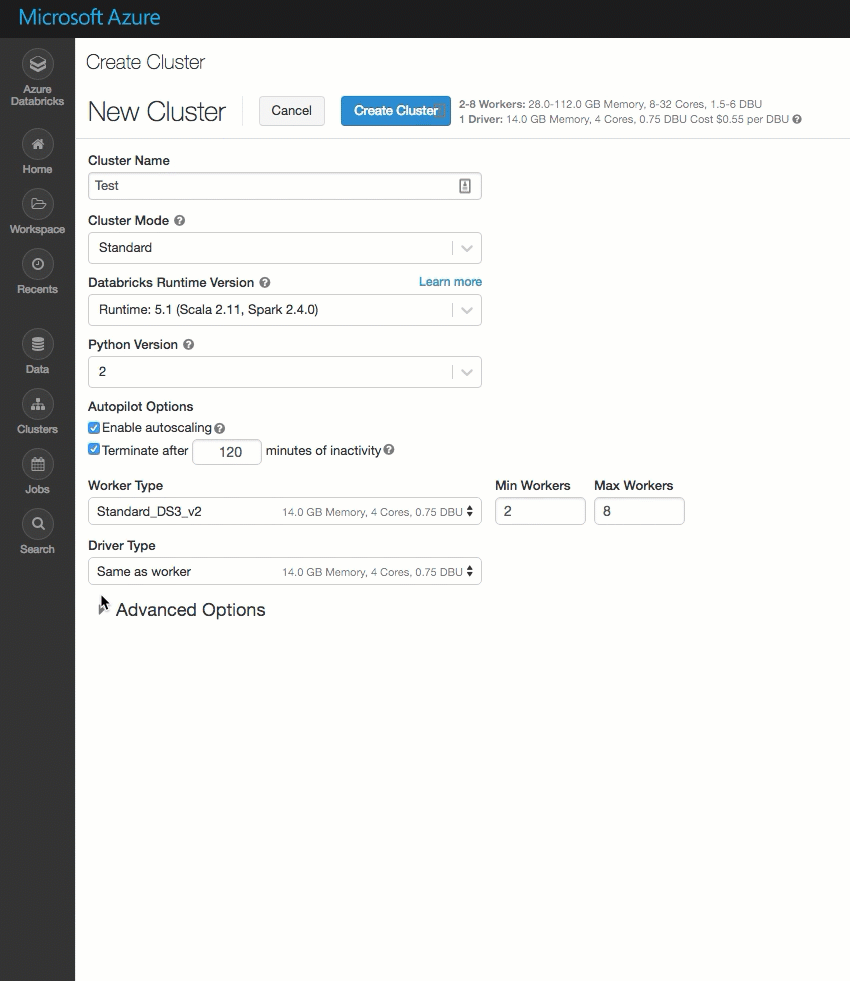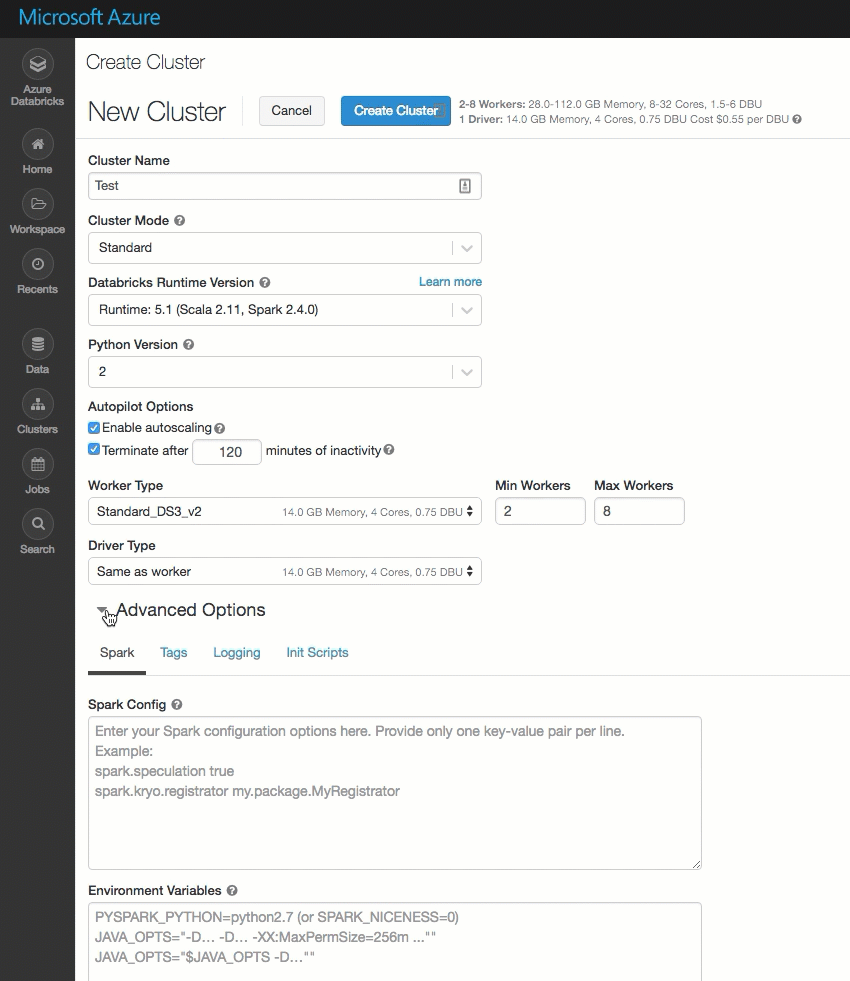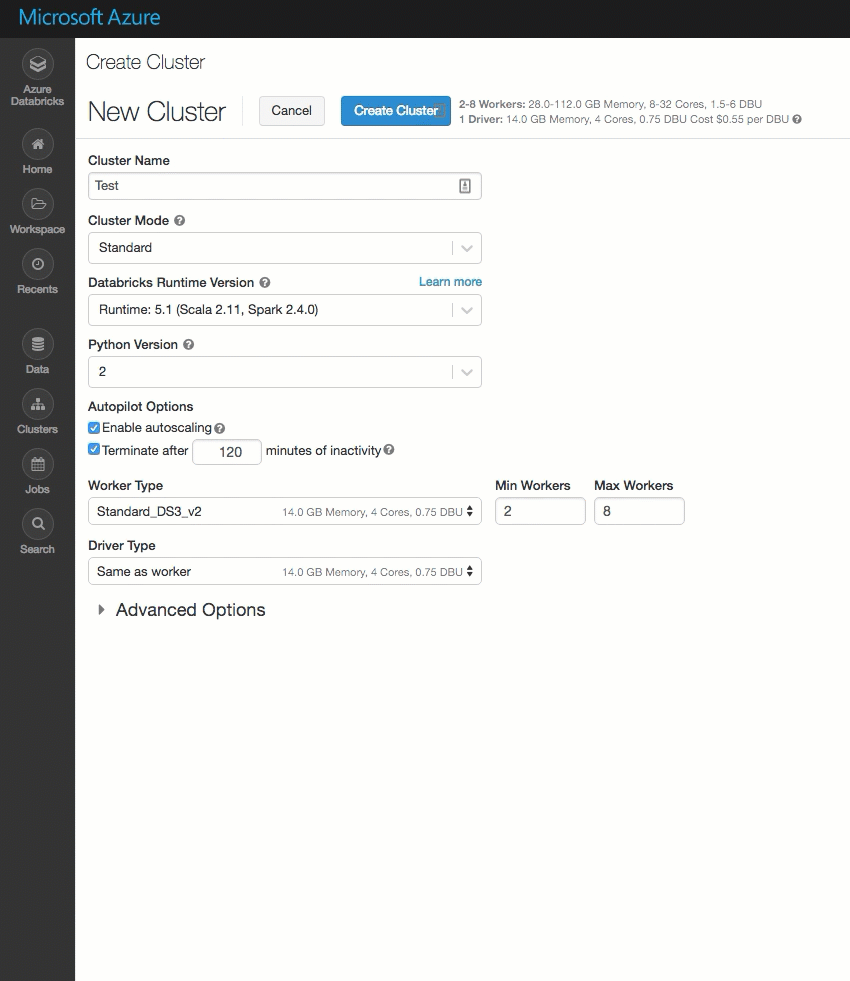
Implementar o Azure Databricks na sua própria rede virtual do Azure (injeção de VNet)
Janeiro 10, 2019
Importante
Esta funcionalidade está em Pré-visualização Pública.
A implantação padrão do Azure Databricks é um serviço totalmente gerenciado no Azure: todos os recursos do plano de computação, incluindo uma rede virtual (VNet) à qual todos os clusters serão associados, são implantados em um grupo de recursos bloqueado. No entanto, se você precisar de personalização de rede, agora pode implantar o Azure Databricks em sua própria rede virtual (às vezes chamada de injeção de VNet), permitindo:
- Conecte o Azure Databricks a outros serviços do Azure (como o Armazenamento do Azure) de maneira mais segura usando pontos de extremidade de serviço.
- Conecte-se a fontes de dados locais para uso com o Azure Databricks, aproveitando as rotas definidas pelo usuário.
- Conecte o Azure Databricks a um appliance virtual de rede para inspecionar todo o tráfego de saída e executar ações de acordo com as regras de permissão e negação.
- Configure o Azure Databricks para usar DNS personalizado.
- Configure regras de NSG (grupo de segurança de rede) para especificar restrições de tráfego de saída.
- Implante clusters do Azure Databricks em sua rede virtual existente.
A implantação do Azure Databricks em sua própria rede virtual também permite que você aproveite os intervalos CIDR flexíveis (em qualquer lugar entre /16-/24 para a rede virtual e entre /18-/26 para as sub-redes).
A configuração usando a interface do usuário do portal do Azure é rápida e fácil: ao criar um espaço de trabalho, basta selecionar Implantar o espaço de trabalho do Azure Databricks na sua Rede Virtual, selecionar a sua rede virtual e fornecer intervalos CIDR para duas sub-redes. O Azure Databricks atualiza a rede virtual com duas novas sub-redes e grupos de segurança de rede usando intervalos CIDR fornecidos por você, permite o acesso ao tráfego de sub-rede de entrada e saída e implanta o espaço de trabalho na rede virtual atualizada.
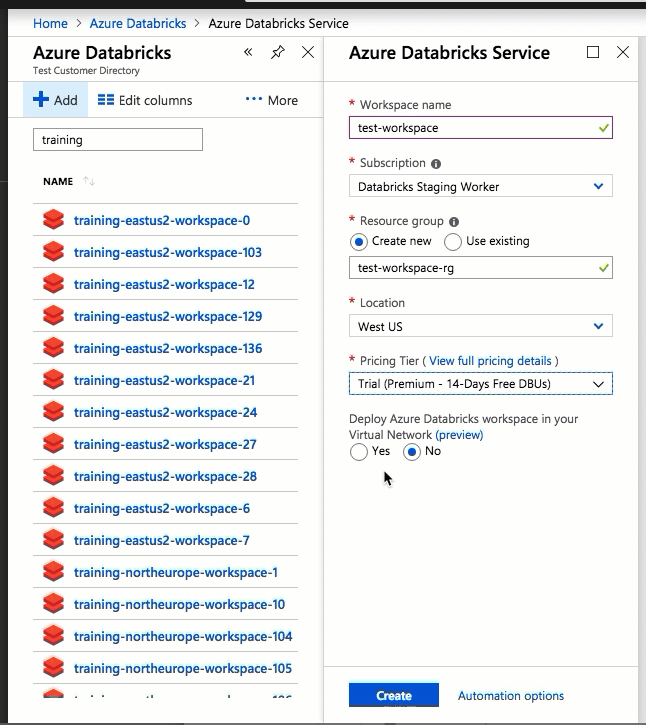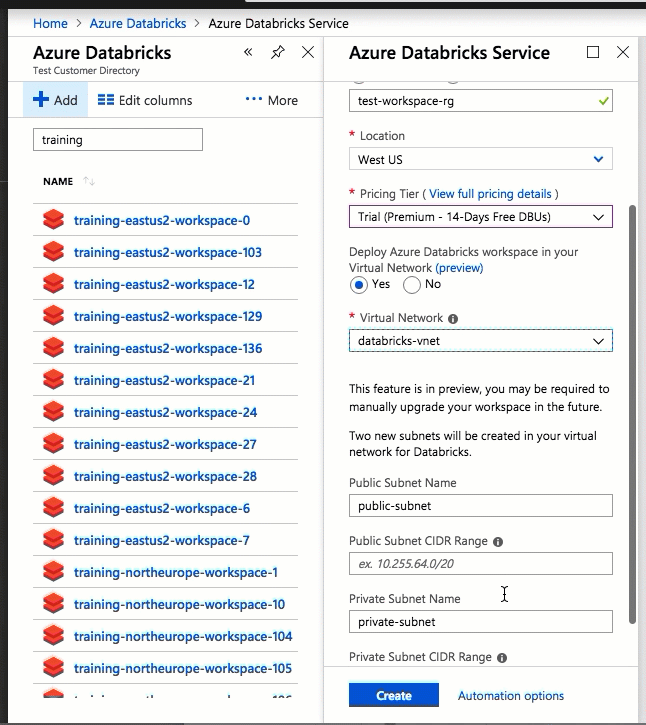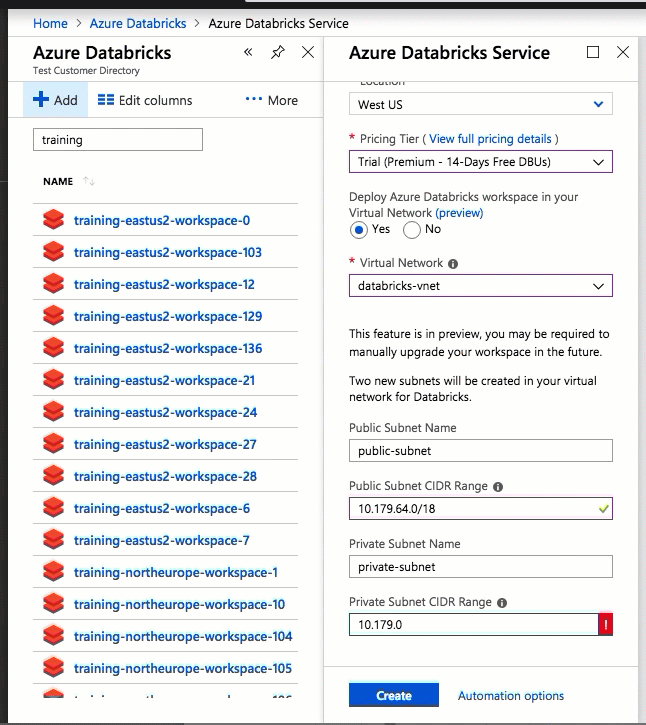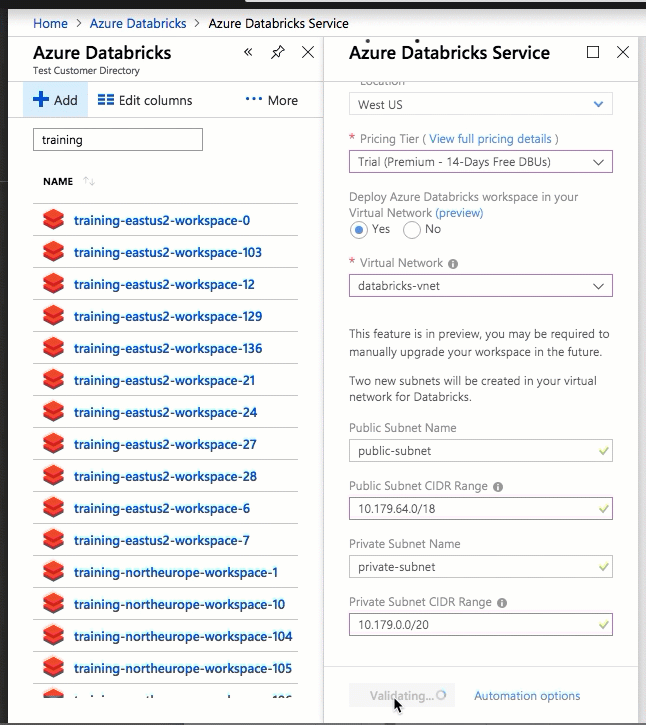
Se você preferir configurar a rede virtual para injeção de VNet por conta própria — por exemplo, quiser usar sub-redes existentes, usar grupos de segurança de rede existentes ou criar suas próprias regras de segurança — poderá usar modelos ARM fornecidos pelo Azure-Databricks em vez da interface do usuário do portal.
Nota
Anteriormente, esse recurso estava disponível apenas por inscrição. Ele permanece no Preview mas agora é totalmente self-service.
Para obter detalhes, consulte Implantar o Azure Databricks em sua rede virtual do Azure (injeção de VNet) e Conectar seu espaço de trabalho do Azure Databricks à sua rede local.
IU de Biblioteca
2 a 9 de janeiro de 2019: Versão 2.88
As melhorias na interface do usuário da biblioteca que foram originalmente lançadas em novembro de 2018 e revertidas pouco depois foram relançadas. Essas atualizações facilitam o carregamento, a instalação e o gerenciamento de bibliotecas para seus clusters do Azure Databricks.
A interface do usuário do Azure Databricks agora oferece suporte a bibliotecas de espaço de trabalho e bibliotecas instaladas em cluster. Existe uma biblioteca de espaço de trabalho no espaço de trabalho e pode ser instalada em um ou mais clusters. Uma biblioteca instalada em cluster é uma biblioteca que existe apenas no contexto do cluster em que está instalada. Além disso:
- Agora você pode criar uma biblioteca a partir de um arquivo carregado para o armazenamento de objetos.
- Agora você pode instalar e desinstalar bibliotecas na página de detalhes da biblioteca e na guia Bibliotecas do cluster.
- As bibliotecas instaladas usando a API agora são exibidas na guia Bibliotecas de um cluster.
Para obter detalhes, consulte Bibliotecas.
Eventos de Clusters
2 a 9 de janeiro de 2019: Versão 2.88
Novos eventos de cluster foram adicionados para refletir o status do driver Spark. Para obter detalhes, consulte API de clusters.
Controlo de Versões dos Blocos de Notas com o Azure DevOps Services
2 a 9 de janeiro de 2019: Versão 2.88
O Azure Databricks agora facilita o uso dos Serviços de DevOps do Azure (anteriormente VSTS) para controlar a versão de seus blocos de anotações. A autenticação é automática, a configuração é simples e você gerencia as revisões do seu notebook da mesma forma que faz com nossa integração com o GitHub.
Para obter detalhes, consulte Controle de versão do Git para blocos de anotações (legado).