Junho de 2018
Esses recursos e melhorias na plataforma Databricks foram lançados em junho de 2018.
Integração do RStudio
19 de junho de 2018: Versão 2.74
O Azure Databricks agora se integra ao RStudio Server, o IDE popular para R. Com esta nova e poderosa integração, você pode:
- Inicie a interface do usuário do RStudio diretamente do Azure Databricks.
- Importe pacotes SparkR e sparklyr dentro do IDE RStudio.
- Acesse, explore e transforme grandes conjuntos de dados do RStudio IDE usando o Apache Spark.
- Execute e monitore trabalhos do Spark em um cluster do Azure Databricks.
- Gerencie seu código usando o controle de versão.
- Use as edições Open Source ou Pro do RStudio Server no Azure Databricks.
A integração com o RStudio requer o plano Premium. Você deve instalar a integração em um cluster de alta simultaneidade. Para obter detalhes, consulte RStudio no Azure Databricks.
Remoção de registos de clusters
19 de junho de 2018: Versão 2.74
Por padrão, os logs de cluster são retidos por 30 dias. Agora você pode excluí-los permanente e imediatamente acessando a guia Armazenamento do espaço de trabalho no Admin Console. Consulte Limpar armazenamento do espaço de trabalho.
Novas regiões
Junho 7, 2018
O Azure Databricks agora está disponível nas seguintes regiões:
- Austrália Oriental
- Sudeste da Austrália
- Sul do Reino Unido
- Oeste do Reino Unido
Pasta de lixo
7 de junho de 2018: Versão 2.73
Uma nova ![]() pasta Lixo contém todos os blocos de anotações, bibliotecas e pastas que você excluiu. A pasta Lixo é automaticamente limpa após 30 dias. Você pode restore um objeto excluído arrastando-o da pasta Lixo para outra pasta.
pasta Lixo contém todos os blocos de anotações, bibliotecas e pastas que você excluiu. A pasta Lixo é automaticamente limpa após 30 dias. Você pode restore um objeto excluído arrastando-o da pasta Lixo para outra pasta.
Para obter detalhes, consulte Excluir um objeto.
Período de retenção de registos reduzido
7 de junho de 2018: Versão 2.73
Os logs de cluster agora são retidos por 30 dias. Eles costumavam ser mantidos indefinidamente.
Respostas à API no formato GZIP
7 de junho de 2018: Versão 2.73
As solicitações enviadas com o Accept-Encoding: gzip cabeçalho retornam respostas compactadas.
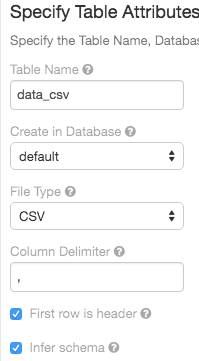
Table importar UI
7 de junho de 2018: Versão 2.73
O criar table interface do usuário agora oferece suporte a uma opção para inferir o schema de arquivos CSV: