Estágio Slow Spark com pouca entrada/saída
Se tiver uma fase lenta com pouca E/S, isso pode ser causado por:
- Ler muitos ficheiros pequenos
- Escrever muitos ficheiros pequenos
- UDF(s) lento(s)
- Junção cartesiana
- Junção explosiva
Quase todos esses problemas podem ser identificados usando o SQL DAG.
Abra o SQL DAG
Para abrir o SQL DAG, deslize até à parte superior da página da tarefa e clique em Consulta SQL Associada:

Agora deverás ver o DAG. Se não, desloque-se um pouco para baixo e deve consegui-lo ver:
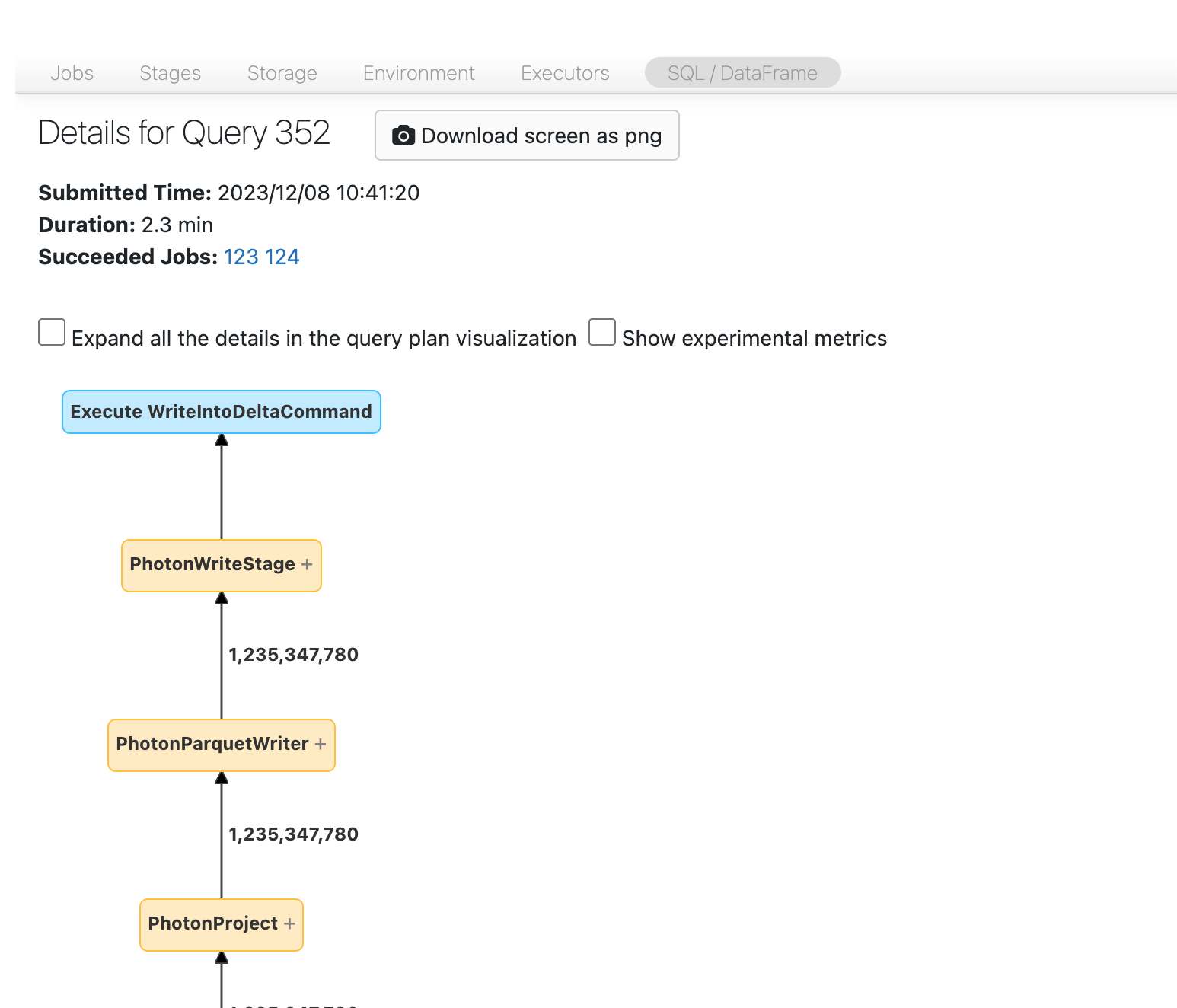
Antes de seguir em frente, familiarize-se com o DAG e onde o tempo está sendo gasto. Alguns nós no DAG contêm informações temporais úteis e outros não. Por exemplo, este bloco demorou 2,1 minutos e até fornece o ID da etapa:

Este nó requer que você o abra para ver que levou 1,4 minutos:
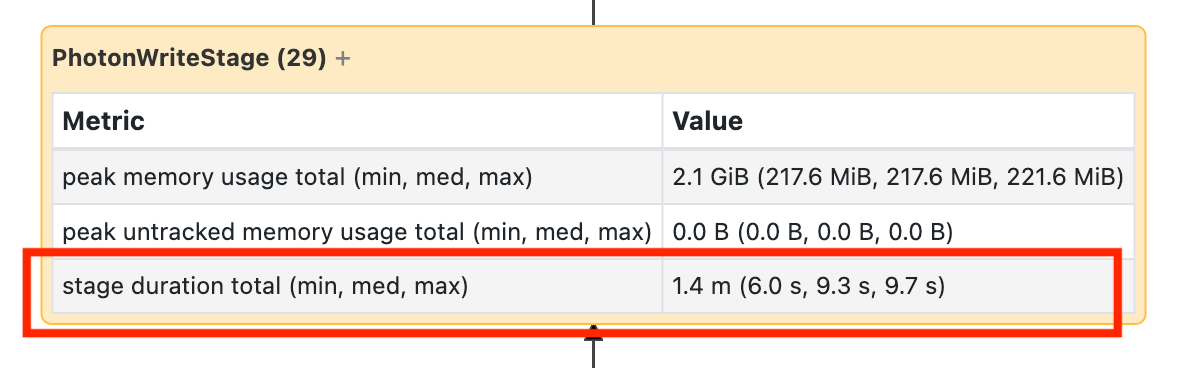
Esses tempos são cumulativos, então é o tempo total gasto em todas as tarefas, não o tempo do relógio. Mas ainda é muito útil, pois eles estão correlacionados com o tempo e o custo do relógio.
É útil familiarizar-se com onde no DAG o tempo está sendo gasto.
Ler muitos ficheiros pequenos
Se vir que um dos seus operadores de análise está a demorar muito tempo, abra-o e procure o número de ficheiros que lê:
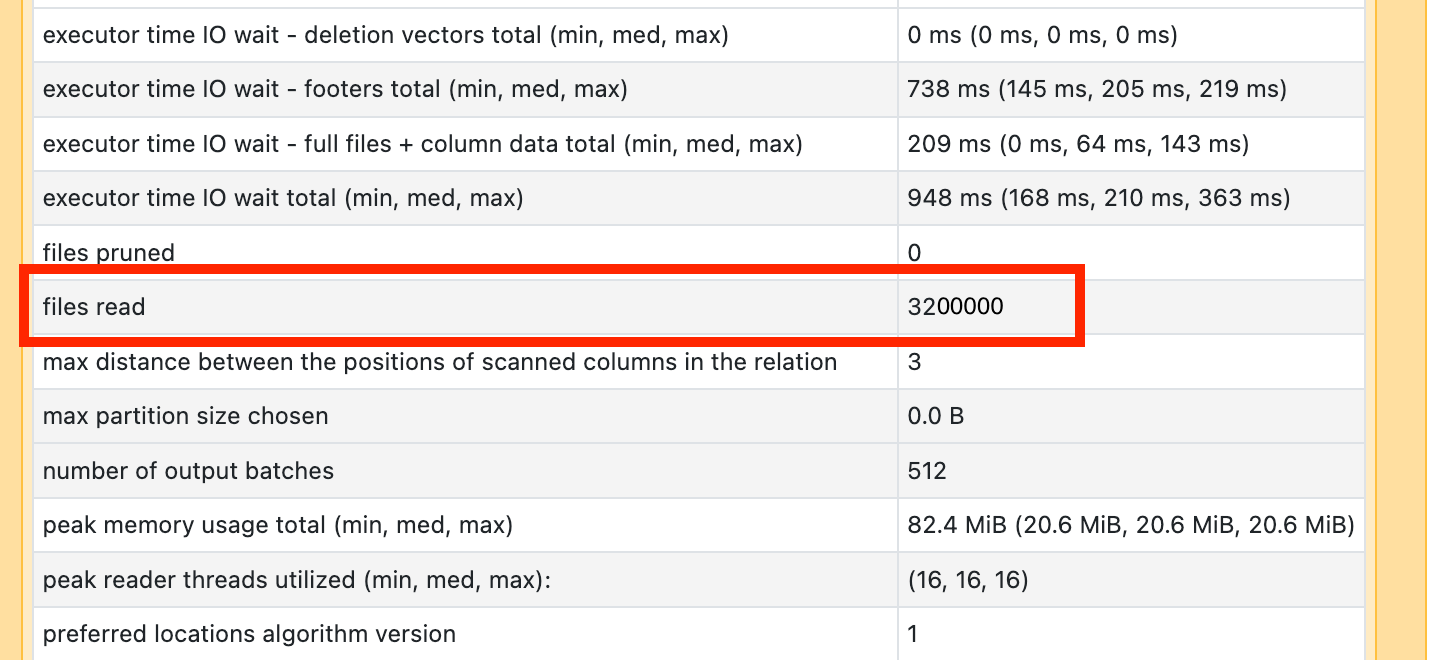
Se você estiver lendo dezenas de milhares de arquivos ou mais, você pode ter um pequeno problema de arquivo. Os seus ficheiros não devem ter menos de 8MB. O problema do arquivo pequeno é mais frequentemente causado pelo particionamento em muitas colunas ou uma coluna de alta cardinalidade.
Se tiveres sorte, podes apenas precisar de executar OPTIMIZE. Independentemente disso, você precisa reconsiderar seu layout de arquivo .
Escrever muitos ficheiros pequenos
Se vir que a sua escrita está a demorar muito tempo, abra-a e procure o número de ficheiros e a quantidade de dados que foram gravados:
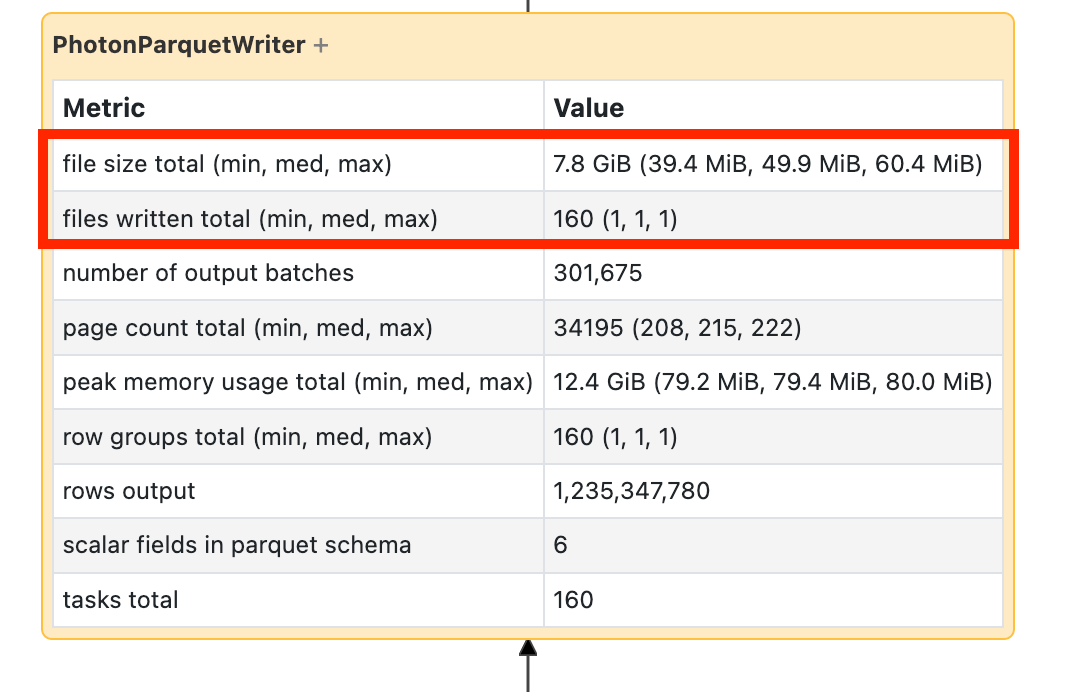
Se estiver a escrever dezenas de milhares de ficheiros ou mais, poderá ter um pequeno problema com ficheiros. Os seus ficheiros não devem ter menos de 8MB. O problema do arquivo pequeno é mais frequentemente causado pelo particionamento em muitas colunas ou uma coluna de alta cardinalidade. Você precisa reconsiderar a sua estrutura de ficheiro ou ativar as gravações otimizadas.
UDFs lentas
Se sabes que tens UDFs, ou vês algo assim no teu DAG, poderás estar a sofrer de UDFs lentos:

Se você acha que está sofrendo com esse problema, tente comentar seu UDF para ver como ele afeta a velocidade do seu pipeline. Se o UDF é de facto onde o tempo está a ser gasto, a sua melhor opção é reescrever o UDF usando funções nativas. Se isso não for possível, considere o número de tarefas no estágio que executa o seu UDF. Se for menor que o número de núcleos no seu cluster, manipule o seu dataframe repartition() antes de usar a função definida pelo utilizador (UDF):
(df
.repartition(num_cores)
.withColumn('new_col', udf(...))
)
UDFs também podem sofrer de problemas de memória. Considere que cada tarefa pode ter que carregar todos os dados em sua partição na memória. Se esses dados forem muito grandes, as coisas podem ficar muito lentas ou instáveis. A repartição também pode resolver esse problema, tornando cada tarefa menor.
Junção cartesiana
Se vires uma ligação cartesiana ou uma ligação de loop aninhada no teu DAG, deves saber que estas ligações são muito caras. Certifique-se de que é isso que você pretendia e veja se há outra maneira.
Junção por Explosão ou Explosão
Se vires algumas linhas a entrar num nó e muitas mais a sair, pode estar a sofrer de uma junção explosiva ou explode().

Leia mais sobre explosões no guia de otimização do Databricks.