Realize a sua própria avaliação de desempenho dos endpoints LLM
Este artigo fornece um exemplo de notebook recomendado pelo Databricks para o benchmarking de um endpoint LLM. Ele também inclui uma breve introdução sobre como o Databricks executa a inferência LLM e calcula a latência e a taxa de transferência como métricas de desempenho de endpoint.
A inferência LLM no Databricks mede tokens por segundo para o modo de taxa de transferência provisionada para APIs do Modelo de Base. Consulte O que significam os intervalos de tokens por segundo na largura de banda provisionada?.
Bloco de notas de exemplo de avaliação comparativa
Você pode importar o seguinte bloco de anotações para seu ambiente Databricks e especificar o nome do seu ponto de extremidade LLM para executar um teste de carga.
Avaliação de desempenho de um endpoint LLM
Introdução à inferência LLM
Os LLMs realizam inferência em um processo de duas etapas:
- Pré-preenchimento, onde os tokens no prompt de entrada são processados em paralelo.
- Decodificação, onde o texto é gerado um token de cada vez de forma autorregressiva. Cada token gerado é anexado à entrada e alimentado de volta no modelo para gerar o próximo token. A geração para quando o LLM produz um token de parada especial ou quando uma condição definida pelo usuário é atendida.
A maioria dos aplicativos de produção tem um orçamento de latência, e o Databricks recomenda que você maximize a taxa de transferência, dado esse orçamento de latência.
- O número de tokens de entrada tem um impacto substancial na memória necessária para processar solicitações.
- O número de tokens de saída domina a latência geral de resposta.
O Databricks divide a inferência LLM nas seguintes submétricas:
- Time to first token (TTFT): é a rapidez com que os utilizadores começam a ver a saída do modelo depois de inserir a sua consulta. Tempos de espera baixos para uma resposta são essenciais em interações em tempo real, mas menos importantes em cargas de trabalho offline. Essa métrica é impulsionada pelo tempo necessário para processar o prompt e, em seguida, gerar o primeiro token de saída.
- Time per output token (TPOT): Tempo para gerar um token de saída para cada usuário que está consultando o sistema. Esta métrica corresponde à forma como cada utilizador percebe a "velocidade" do modelo. Por exemplo, um TPOT de 100 milissegundos por token seria de 10 tokens por segundo, ou aproximadamente 450 palavras por minuto, o que é mais rápido do que uma pessoa normal consegue ler.
Com base nessas métricas, a latência total e a taxa de transferência podem ser definidas da seguinte forma:
- Latência = TTFT + (TPOT) * (o número de tokens a gerar)
- Taxa de transferência = número de tokens de saída por segundo em todas as solicitações de simultaneidade
No Databricks, os endpoints de serviço LLM são capazes de ser dimensionados para suportar a carga enviada pelos clientes com vários pedidos simultâneos. Há um equilíbrio entre latência e taxa de transferência. Isso ocorre porque, nos endpoints de serviço LLM, solicitações simultâneas podem ser processadas ao mesmo tempo. Em baixas cargas de solicitação simultâneas, a latência é a menor possível. No entanto, se você aumentar a carga de solicitação, a latência pode aumentar, mas a taxa de transferência provavelmente também aumenta. Isso ocorre porque duas solicitações no valor de tokens por segundo podem ser processadas em menos do dobro do tempo.
Portanto, controlar o número de solicitações paralelas em seu sistema é essencial para equilibrar a latência com a taxa de transferência. Se você tiver um caso de uso de baixa latência, deseja enviar menos solicitações simultâneas para o ponto de extremidade para manter a latência baixa. Se tiveres um caso de utilização com alta taxa de transferência, deves saturar o endpoint com muitas solicitações simultâneas, já que uma taxa de transferência mais alta compensa mesmo que afete a latência.
- Os casos de uso de alta taxa de transferência podem incluir inferências em lote e outras tarefas não voltadas para o usuário.
- Os casos de uso de baixa latência podem incluir aplicativos em tempo real que exigem respostas imediatas.
Ferramenta de benchmarking Databricks
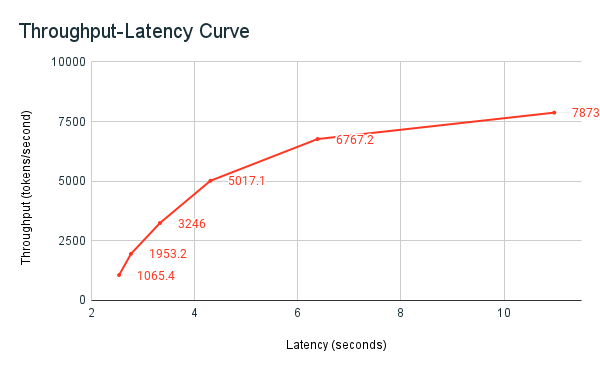
O exemplo de caderno de benchmarking de compartilhado anteriormente,, é a ferramenta de benchmarking do Databricks. O bloco de anotações exibe a latência total em todas as solicitações e métricas de taxa de transferência, e traça a curva de taxa de transferência em função da latência para diferentes números de solicitações paralelas. A estratégia de dimensionamento automático do ponto de extremidade Databricks equilibra entre latência e taxa de transferência. No caderno, observa-se que a latência e a taxa de transferência aumentam à medida que mais utilizadores simultâneos consultam o endpoint.
No entanto, você também começa a ver que, à medida que o número de solicitações paralelas aumenta, a taxa de transferência começa a estabilizar, atingindo um limite de cerca de 8000 tokens por segundo. Este platô ocorre devido ao fato de que a taxa de transferência provisionada para o endpoint limita o número de trabalhadores e solicitações paralelas que podem ser feitas. À medida que mais solicitações são feitas além do que o ponto de extremidade pode lidar simultaneamente, a latência total continua a aumentar à medida que solicitações adicionais aguardam na fila.
Mais detalhes sobre a filosofia da Databricks no que diz respeito ao benchmarking de desempenho dos LLM são descritos no blogue LLM Inference Performance Engineering: Best Practices.