Introdução ao RAG no desenvolvimento de IA
Este artigo é uma introdução à geração aumentada de recuperação (RAG): o que é, como funciona e conceitos-chave.
O que é geração aumentada por recuperação?
RAG é uma técnica que permite que um modelo de linguagem grande (LLM) gere respostas enriquecidas aumentando o prompt de um usuário com dados de suporte recuperados de uma fonte de informação externa. Ao incorporar essas informações recuperadas, o RAG permite que o LLM gere respostas mais precisas e de maior qualidade em comparação com não aumentar o prompt com contexto adicional.
Por exemplo, suponha que você esteja criando um chatbot de perguntas e respostas para ajudar os funcionários a responder perguntas sobre os documentos proprietários da sua empresa. Um LLM independente não será capaz de responder com precisão a perguntas sobre o conteúdo desses documentos se não tiver sido especificamente treinado sobre eles. O LLM pode recusar-se a responder por falta de informação ou, pior ainda, pode gerar uma resposta incorreta.
O RAG resolve esse problema primeiro recuperando informações relevantes dos documentos da empresa com base na consulta de um usuário e, em seguida, fornecendo as informações recuperadas ao LLM como contexto adicional. Isso permite que o LLM gere uma resposta mais precisa, desenhando a partir dos detalhes específicos encontrados nos documentos relevantes. Em essência, o RAG permite que o LLM "consulte" as informações recuperadas para formular sua resposta.
Componentes principais de um aplicativo RAG
Um aplicativo RAG é um exemplo de um sistema de IA composto: ele expande as capacidades de linguagem do modelo sozinho, combinando-o com outras ferramentas e procedimentos.
Ao usar um LLM autônomo, um usuário envia uma solicitação, como uma pergunta, ao LLM, e o LLM responde com uma resposta baseada exclusivamente em seus dados de treinamento.
Em sua forma mais básica, as seguintes etapas acontecem em um aplicativo RAG:
- Recuperação: A solicitação do usuário é usada para consultar alguma fonte externa de informação. Isso pode significar consultar um repositório vetorial, realizar uma pesquisa de palavra-chave sobre algum texto ou consultar um banco de dados SQL. O objetivo da etapa de recuperação é obter dados de suporte que ajudem o LLM a fornecer uma resposta útil.
- Aumento: Os dados de suporte da etapa de recuperação são combinados com a solicitação do usuário, geralmente usando um modelo com formatação e instruções adicionais para o LLM, para criar um prompt.
- Geração: O prompt resultante é passado para o LLM, e o LLM gera uma resposta à solicitação do usuário.
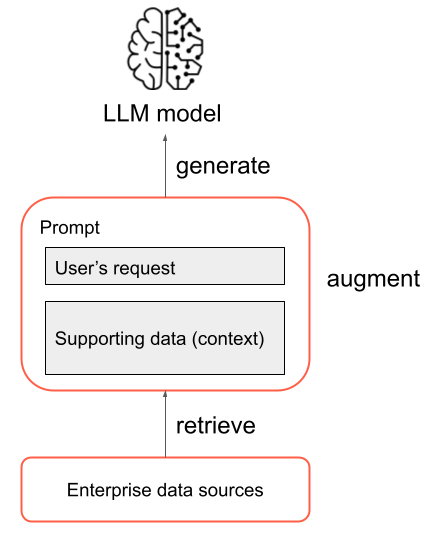
Esta é uma visão geral simplificada do processo RAG, mas é importante notar que a implementação de um aplicativo RAG envolve muitas tarefas complexas. O pré-processamento de dados de origem para torná-los adequados para uso em RAG, a recuperação eficaz de dados, a formatação do prompt aumentado e a avaliação das respostas geradas exigem consideração e esforço cuidadosos. Estes tópicos serão abordados mais pormenorizadamente nas secções posteriores deste guia.
Porquê usar o RAG?
A tabela a seguir descreve os benefícios do uso do RAG em comparação com um LLM autônomo:
| Com um LLM sozinho | Usando LLMs com RAG |
|---|---|
| Nenhum conhecimento proprietário: os LLMs geralmente são treinados em dados disponíveis publicamente, portanto, não podem responder com precisão a perguntas sobre os dados internos ou proprietários de uma empresa. | Os aplicativos RAG podem incorporar dados proprietários: um aplicativo RAG pode fornecer documentos proprietários, como memorandos, e-mails e documentos de design para um LLM, permitindo que ele responda a perguntas sobre esses documentos. |
| O conhecimento não é atualizado em tempo real: os LLMs não têm acesso a informações sobre eventos que ocorreram depois de serem treinados. Por exemplo, um LLM independente não pode dizer nada sobre os movimentos de ações hoje. | Os aplicativos RAG podem acessar dados em tempo real: um aplicativo RAG pode fornecer ao LLM informações oportunas de uma fonte de dados atualizada, permitindo que ele forneça respostas úteis sobre eventos após sua data de corte de treinamento. |
| Falta de citações: LLMs não podem citar fontes específicas de informação ao responder, deixando o usuário incapaz de verificar se a resposta é factualmente correta ou uma alucinação. | RAG pode citar fontes: Quando usado como parte de uma aplicação RAG, um LLM pode ser solicitado a citar suas fontes. |
| Falta de controles de acesso a dados (ACLs): LLMs sozinhos não podem fornecer respostas diferentes para usuários diferentes com base em permissões de usuário específicas. | RAG permite segurança de dados/ACLs: A etapa de recuperação pode ser projetada para encontrar apenas as informações que o usuário tem credenciais para acessar, permitindo que um aplicativo RAG recupere seletivamente informações pessoais ou proprietárias. |
Tipos de RAG
A arquitetura RAG pode trabalhar com dois tipos de dados de suporte:
| Dados estruturados | Dados não estruturados | |
|---|---|---|
| Definição | Dados tabulares organizados em linhas e colunas com um esquema específico, por exemplo, tabelas em um banco de dados. | Dados sem uma estrutura ou organização específica, por exemplo, documentos que incluem texto e imagens ou conteúdo multimídia, como áudio ou vídeos. |
| Fontes de dados de exemplo | - Registos de clientes num sistema de BI ou data warehouse - Dados de transações de um banco de dados SQL - Dados de APIs de aplicativos (como SAP, Salesforce e assim por diante) |
- Registos de clientes num sistema de BI ou data warehouse - Dados de transações de um banco de dados SQL - Dados de APIs de aplicativos (como SAP, Salesforce e assim por diante) - PDFs - Documentos do Google ou Microsoft Office - Wikis - Imagens - Vídeos |
A sua escolha de dados para RAG depende do seu caso de uso. O restante do tutorial se concentra em RAG para dados não estruturados.