Pré-requisito: Reunir requisitos
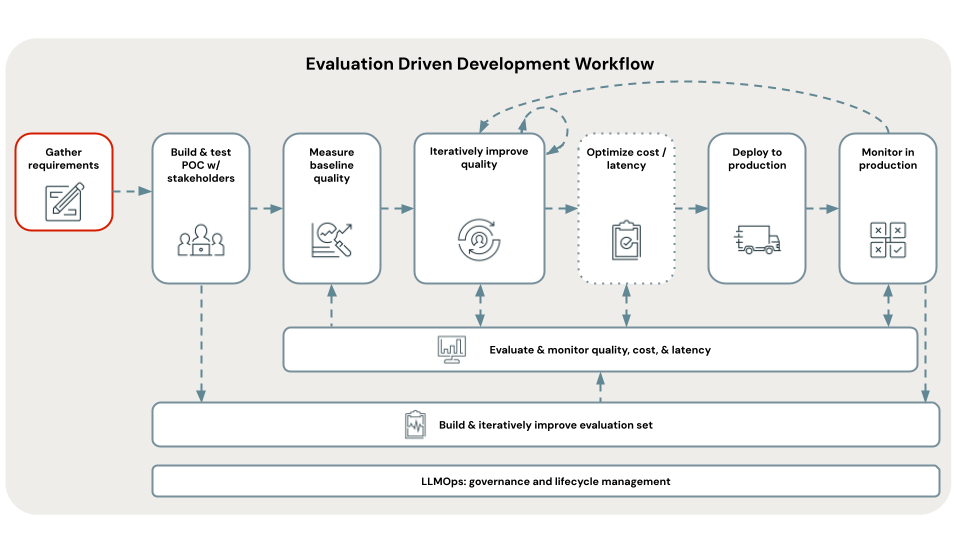
Definir requisitos de casos de uso claros e abrangentes é um primeiro passo crítico no desenvolvimento de um aplicativo RAG bem-sucedido. Estes requisitos servem dois objetivos principais. Em primeiro lugar, ajudam a determinar se a RAG é a abordagem mais adequada para o caso de uso dado. Se o RAG for realmente um bom ajuste, esses requisitos orientam o projeto, a implementação e as decisões de avaliação da solução. Investir tempo no início de um projeto para reunir requisitos detalhados pode evitar desafios e contratempos significativos mais tarde no processo de desenvolvimento e garante que a solução resultante atenda às necessidades dos usuários finais e partes interessadas. Requisitos bem definidos fornecem a base para os estágios subsequentes do ciclo de vida de desenvolvimento que iremos percorrer.
Consulte o repositório GitHub para obter o código de exemplo nesta seção. Você também pode usar o código do repositório como um modelo para criar seus próprios aplicativos de IA.
O caso de uso é adequado para RAG?
A primeira coisa que você precisa estabelecer é se o RAG é mesmo a abordagem certa para o seu caso de uso. Dado o hype em torno do RAG, é tentador vê-lo como uma possível solução para qualquer problema. No entanto, existem nuances sobre quando a RAG é adequada ou não.
O RAG é um bom ajuste quando:
- Raciocínio sobre informações recuperadas (não estruturadas e estruturadas) que não se encaixam inteiramente na janela de contexto do LLM
- Sintetizar informações de várias fontes (por exemplo, gerar um resumo de pontos-chave de diferentes artigos sobre um tópico)
- A recuperação dinâmica com base em uma consulta de usuário é necessária (por exemplo, dada uma consulta de usuário, determine de qual fonte de dados recuperar)
- O caso de uso requer a geração de conteúdo novo com base em informações recuperadas (por exemplo, responder a perguntas, fornecer explicações, oferecer recomendações)
A RAG pode não ser a melhor opção quando:
- A tarefa não requer recuperação específica da consulta. Por exemplo, gerar resumos de transcrição de chamadas; mesmo que transcrições individuais sejam fornecidas como contexto no prompt LLM, as informações recuperadas permanecem as mesmas para cada resumo.
- Todo o conjunto de informações a serem recuperadas pode caber na janela de contexto do LLM
- São necessárias respostas de latência extremamente baixa (por exemplo, quando as respostas são necessárias em milissegundos)
- Respostas simples baseadas em regras ou modeladas são suficientes (por exemplo, um chatbot de suporte ao cliente que fornece respostas predefinidas com base em palavras-chave)
Requisitos para descobrir
Depois de estabelecer que o RAG é adequado para o seu caso de uso, considere as seguintes perguntas para capturar requisitos concretos. Os requisitos são priorizados da seguinte forma:
🟢 P0: Deve definir este requisito antes de iniciar o seu POC.
🟡 P1: Deve definir antes de ir para a produção, mas pode refinar iterativamente durante o POC.
⚪ P2: Bom ter exigência.
Não se trata de uma lista exaustiva de perguntas. No entanto, ele deve fornecer uma base sólida para capturar os principais requisitos para sua solução RAG.
Experiência de utilizador
Definir como os usuários irão interagir com o sistema RAG e que tipo de respostas são esperadas
🟢 [P0] Como será um pedido típico para a cadeia RAG? Peça às partes interessadas exemplos de consultas de potenciais utilizadores.
🟢 [P0] Que tipo de respostas os usuários esperam (respostas curtas, explicações longas, uma combinação ou qualquer outra coisa)?
🟡 [P1] Como os usuários irão interagir com o sistema? Através de uma interface de chat, barra de pesquisa, ou alguma outra modalidade?
🟡 [P1] tom ou estilo de chapéu deve gerar respostas tomar? (formal, conversacional, técnico?)
🟡 [P1] Como o aplicativo deve lidar com consultas ambíguas, incompletas ou irrelevantes? Nesses casos, deve ser fornecida alguma forma de feedback ou orientação?
⚪ [P2] Existem requisitos específicos de formatação ou apresentação para a saída gerada? A saída deve incluir metadados além da resposta da cadeia?
Dados
Determine a natureza, fonte(s) e qualidade dos dados que serão usados na solução RAG.
🟢 [P0] Quais são as fontes disponíveis para usar?
Para cada fonte de dados:
- 🟢 [P0] Os dados são estruturados ou não estruturados?
- 🟢 [P0] Qual é o formato de origem dos dados de recuperação (por exemplo, PDFs, documentação com imagens/tabelas, respostas estruturadas da API)?
- 🟢 [P0] Onde residem esses dados?
- 🟢 [P0] Quantos dados estão disponíveis?
- 🟡 [P1] Com que frequência os dados são atualizados? Como essas atualizações devem ser tratadas?
- 🟡 [P1] Existem problemas conhecidos de qualidade de dados ou inconsistências para cada fonte de dados?
Considere a criação de uma tabela de inventário para consolidar essas informações, por exemplo:
| Data source | Origem | Tipo(s) de ficheiro(s) | Tamanho | Frequência de atualização |
|---|---|---|---|---|
| Fonte de dados 1 | Volume do catálogo Unity | JSON | 10GB | Diário |
| Fonte de dados 2 | API pública | XML | NA (API) | Em Tempo Real |
| Fonte de dados 3 | SharePoint | PDF, .docx | 500MB | Mensalmente |
Restrições de desempenho
Capture os requisitos de desempenho e recursos para o aplicativo RAG.
🟡 [P1] Qual é a latência máxima aceitável para gerar as respostas?
🟡 [P1] Qual é o tempo máximo aceitável para o primeiro token?
🟡 [P1] Se a saída estiver sendo transmitida, é aceitável uma latência total mais alta?
🟡 [P1] Existem limitações de custo nos recursos de computação disponíveis para inferência?
🟡 [P1] Quais são os padrões de utilização esperados e as cargas de pico?
🟡 [P1] Quantos usuários ou solicitações simultâneas o sistema deve ser capaz de lidar? O Databricks lida nativamente com esses requisitos de escalabilidade, através da capacidade de escalar automaticamente com o Model Serving.
Avaliação
Estabeleça como a solução RAG será avaliada e melhorada ao longo do tempo.
🟢 [P0] Qual é o objetivo / KPI do negócio que você quer impactar? Qual é o valor de base e qual é o objetivo?
🟢 [P0] Que utilizadores ou partes interessadas fornecerão feedback inicial e contínuo?
🟢 [P0] Que métricas devem ser usadas para avaliar a qualidade das respostas geradas? O Mosaic AI Agent Evaluation fornece um conjunto recomendado de métricas a serem usadas.
🟡 [P1] Qual é o conjunto de perguntas em que o aplicativo RAG deve ser bom para entrar em produção?
🟡 [P1] Existe um [conjunto de avaliação]? É possível obter um conjunto de avaliações de consultas dos utilizadores, juntamente com respostas fundamentadas e (opcionalmente) os documentos comprovativos corretos que devem ser recuperados?
🟡 [P1] Como será recolhido e incorporado o feedback dos utilizadores no sistema?
Segurança
Identificar quaisquer considerações de segurança e privacidade.
🟢 [P0] Existem dados sensíveis/confidenciais que precisam ser tratados com cuidado?
🟡 [P1] Os controles de acesso precisam ser implementados na solução (por exemplo, um determinado usuário só pode recuperar de um conjunto restrito de documentos)?
Implementação
Compreender como a solução RAG será integrada, implantada e mantida.
🟡 Como deve a solução RAG integrar-se com os sistemas e fluxos de trabalho existentes?
🟡 Como o modelo deve ser implantado, dimensionado e versionado? Este tutorial aborda como o ciclo de vida de ponta a ponta pode ser tratado no Databricks usando MLflow, Unity Catalog, Agent SDK e Model Serving.
Exemplo
Como exemplo, considere como essas perguntas se aplicam a este exemplo de aplicativo RAG usado por uma equipe de suporte ao cliente Databricks:
| Área | Considerações | Requisitos |
|---|---|---|
| Experiência de utilizador | - Modalidade de interação. - Exemplos típicos de consulta de usuário. - Formato e estilo de resposta esperados. - Tratamento de consultas ambíguas ou irrelevantes. |
- Interface de chat integrada com Slack. - Exemplos de consultas: "Como faço para reduzir o tempo de inicialização do cluster?" "Que tipo de plano de apoio tenho?" - Respostas técnicas claras, com trechos de código e links para documentação relevante, quando apropriado. - Fornecer sugestões contextuais e escalar para apoiar os engenheiros quando necessário. |
| Dados | - Número e tipo de fontes de dados. - Formato e localização dos dados. - Tamanho dos dados e frequência de atualização. - Qualidade e consistência dos dados. |
- Três fontes de dados. - Documentação da empresa (HTML, PDF). - Tickets de suporte resolvidos (JSON). - Publicações no fórum da comunidade (tabela Delta). - Dados armazenados no Catálogo Unity e atualizados semanalmente. - Tamanho total dos dados: 5GB. - Estrutura de dados consistente e qualidade mantida por docs dedicados e equipes de suporte. |
| Desempenho | - Latência máxima aceitável. - Restrições de custos. - Uso esperado e simultaneidade. |
- Requisito de latência máxima. - Restrições de custos. - Pico de carga esperado. |
| Avaliação | - Disponibilidade do conjunto de dados de avaliação. - Métricas de qualidade. - Recolha de feedback dos utilizadores. |
- Especialistas no assunto de cada área de produto ajudam a rever os resultados e ajustar as respostas incorretas para criar o conjunto de dados de avaliação. - KPIs de negócio. - Aumento da taxa de resolução de tickets de suporte. - Diminuição do tempo gasto pelo usuário por ticket de suporte. - Métricas de qualidade. - Correção e relevância das respostas julgadas pelo LLM. - LLM julga precisão de recuperação. - Votação ascendente ou negativa do usuário. - Recolha de feedback. - Slack será instrumentado para fornecer um polegar para cima / para baixo. |
| Segurança | - Tratamento de dados sensíveis. - Requisitos de controlo de acessos. |
- Nenhum dado sensível do cliente deve estar na fonte de recuperação. - Autenticação de usuários através do Databricks Community SSO. |
| Implementação | - Integração com sistemas existentes. - Implantação e versionamento. |
- Integração com sistema de tickets de suporte. - Cadeia implantada como um endpoint Databricks Model Servindo. |
Próximo passo
Comece com a Etapa 1. Clone repositório de código e crie computação.