Cadeia RAG para inferência
Este artigo descreve o processo que ocorre quando o usuário envia uma solicitação para o aplicativo RAG em uma configuração online. Uma vez que os dados tenham sido processados pelo pipeline de dados, eles são adequados para uso no aplicativo RAG. A série, ou cadeia de etapas que são invocadas no momento da inferência, é comumente referida como a cadeia RAG.
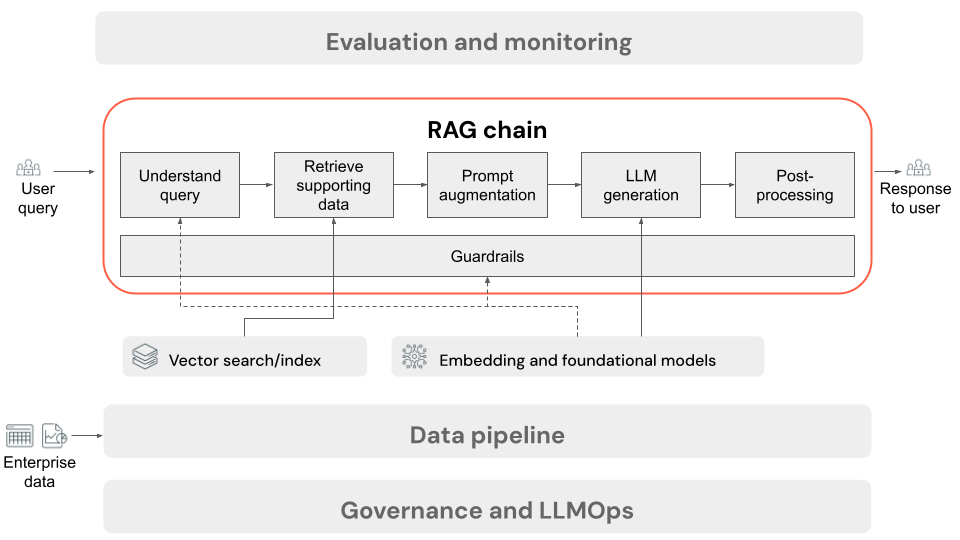
- (Opcional) Pré-processamento de consulta do usuário: em alguns casos, a consulta do usuário é pré-processada para torná-la mais adequada para consultar o banco de dados vetorial. Isso pode envolver a formatação da consulta dentro de um modelo, o uso de outro modelo para reescrever a solicitação ou a extração de palavras-chave para ajudar na recuperação. A saída desta etapa é uma consulta de recuperação que será usada na etapa de recuperação subsequente.
- Recuperação: Para recuperar informações de suporte do banco de dados vetorial, a consulta de recuperação é convertida em uma incorporação usando o mesmo modelo de incorporação que foi usado para incorporar os blocos de documento durante a preparação de dados. Essas incorporações permitem a comparação da semelhança semântica entre a consulta de recuperação e os blocos de texto não estruturados, usando medidas como semelhança cosseno. Em seguida, os blocos são recuperados do banco de dados vetorial e classificados com base em quão semelhantes são à solicitação incorporada. Os melhores resultados (mais semelhantes) são retornados.
- Aumento de prompt: O prompt que será enviado para o LLM é formado pelo aumento da consulta do usuário com o contexto recuperado, em um modelo que instrui o modelo como usar cada componente, geralmente com instruções adicionais para controlar o formato de resposta. O processo de iteração no modelo de prompt certo a ser usado é conhecido como engenharia de prompt.
- Geração LLM: O LLM usa o prompt aumentado, que inclui a consulta do usuário e os dados de suporte recuperados, como entrada. Em seguida, gera uma resposta que se baseia no contexto adicional.
- (Opcional) Pós-processamento: A resposta do LLM pode ser processada posteriormente para aplicar lógica de negócios adicional, adicionar citações ou refinar o texto gerado com base em regras ou restrições predefinidas.
Tal como acontece com o pipeline de dados da aplicação RAG, existem muitas decisões de engenharia consequentes que podem afetar a qualidade da cadeia RAG. Por exemplo, determinar quantos blocos recuperar na etapa 2 e como combiná-los com a consulta do usuário na etapa 3 pode afetar significativamente a capacidade do modelo de gerar respostas de qualidade.
Ao longo da cadeia, vários guarda-corpos podem ser aplicados para garantir a conformidade com as políticas empresariais. Isso pode envolver a filtragem de solicitações apropriadas, a verificação das permissões do usuário antes de acessar fontes de dados e a aplicação de técnicas de moderação de conteúdo às respostas geradas.