Como criar e consultar um índice de pesquisa vetorial
Este artigo descreve como criar e consultar um índice de pesquisa vetorial usando Mosaic AI Vetor Search.
Você pode criar e gerenciar componentes de pesquisa vetorial, como um ponto de extremidade de pesquisa vetorial e índices de pesquisa vetorial, usando a interface do usuário, o Python SDKou o REST API.
Requerimentos
- Espaço de trabalho com Unity Catalog.
- Computação sem servidor habilitada. Para obter instruções, consulte Conectar-se à computação sem servidor.
- A tabela de origem deve ter o Change Data Feed habilitado. Para obter instruções, consulte Usar o feed de dados de alteração do Delta Lake no Azure Databricks.
- Para criar um índice de pesquisa vetorial, você deve ter privilégios de CREATE TABLE no esquema de catálogo onde o índice será criado.
- Para consultar um índice que pertence a outro usuário, você deve ter privilégios adicionais. Consulte Consultar um ponto de extremidade de pesquisa vetorial.
A permissão para criar e gerenciar pontos de extremidade de pesquisa vetorial é configurada usando listas de controle de acesso. Consulte ACLs de ponto de extremidade de pesquisa vetorial.
Instalação
Para usar o SDK de pesquisa vetorial, você deve instalá-lo em seu bloco de anotações. Use o seguinte código para instalar o pacote:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
Em seguida, use o seguinte comando para importar VectorSearchClient:
from databricks.vector_search.client import VectorSearchClient
Autenticação
Consulte Proteção de dados e autenticação.
Criar um endereço de pesquisa vetorial
Você pode criar um endpoint de pesquisa vetorial usando a interface do utilizador do Databricks, o SDK do Python ou a API.
Criar um endpoint de pesquisa vetorial usando a interface gráfica do utilizador
Siga estas etapas para criar um endpoint de pesquisa vetorial usando a interface de utilizador.
Na barra lateral esquerda, clique em Compute.
Clique no separador Pesquisa vetorial e clique em Criar .

O formulário Criar ponto de extremidade é aberto. Insira um nome para este ponto de extremidade.
Clique Confirm.
Criar um ponto de extremidade de pesquisa vetorial usando o Python SDK
O exemplo a seguir usa a função create_endpoint() SDK para criar um ponto de extremidade de pesquisa vetorial.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearchClient(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
Criar um endpoint de pesquisa vetorial usando a API REST
Consulte a documentação de referência da API REST: POST /api/2.0/vector-search/endpoints.
(Opcional) Criar e configurar um endpoint para servir o modelo de embed
Se você optar por fazer com que o Databricks calcule as incorporações, poderá usar um ponto de extremidade de APIs de Modelo de Base pré-configurado ou criar um ponto de extremidade de serviço de modelo para atender ao modelo de incorporação de sua escolha. Consulte APIs do modelo de base de pagamento por token ou Criar modelo de base servindo pontos de extremidade para obter instruções. Para exemplos de notebooks, consulte Exemplos de notebooks para chamar um modelo de incorporação.
Quando configuras um ponto de extremidade de integração, a Databricks recomenda que removas a seleção predefinida de Escala para zero. O serviço de pontos de extremidade pode levar alguns minutos para aquecer, e a consulta inicial em um índice com um ponto de extremidade reduzido pode atingir o tempo limite.
Observação
A inicialização do índice de pesquisa vetorial pode atingir o tempo limite se o endpoint de integração não estiver configurado adequadamente para o conjunto de dados. Você só deve usar terminais de CPU para pequenos conjuntos de dados e testes. Para conjuntos de dados maiores, use um endpoint GPU para obter o desempenho ideal.
Criar um índice de pesquisa vetorial
Você pode criar um índice de pesquisa vetorial usando a interface do usuário, o SDK do Python ou a API REST. A interface do usuário é a abordagem mais simples.
Existem dois tipos de índices:
- do Índice de Sincronização Delta sincroniza automaticamente com uma Tabela Delta de origem, atualizando automática e incrementalmente o índice à medida que os dados subjacentes na Tabela Delta mudam.
- Direct Vetor Access Index suporta leitura e gravação diretas de vetores e metadados. O usuário é responsável por atualizar esta tabela usando a API REST ou o Python SDK. Esse tipo de índice não pode ser criado usando a interface do usuário. Você deve usar a API REST ou o SDK.
Criar índice usando a interface do usuário
Na barra lateral esquerda, clique em Catálogo para abrir a interface de utilizador do Catalog Explorer.
Navegue até a tabela Delta que você deseja usar.
Clique no botão Criar no canto superior direito e selecione índice de pesquisa vetorial no menu suspenso.
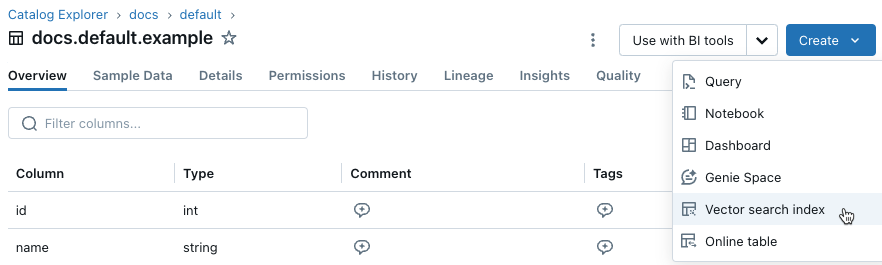
Use os seletores na caixa de diálogo para configurar o índice.
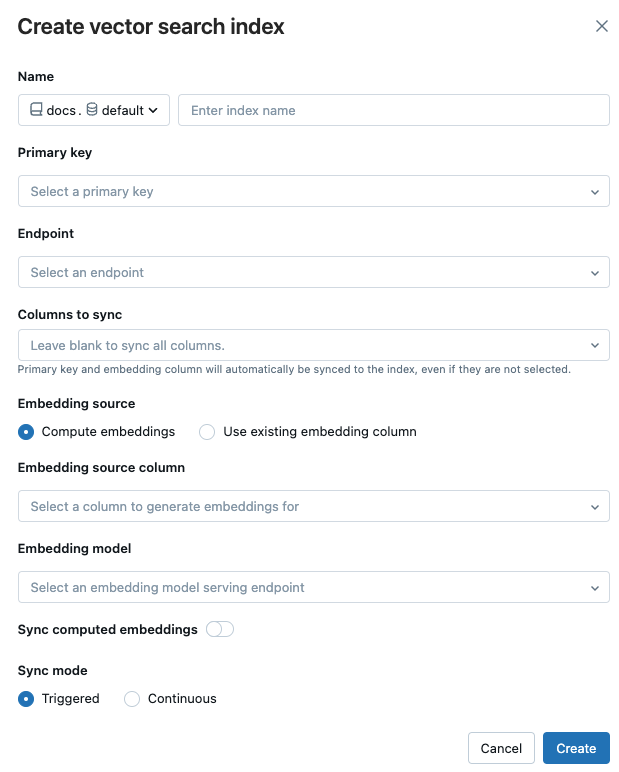
Nome: Nome a utilizar para a tabela em linha no Catálogo Unity. O nome requer um namespace de três níveis,
<catalog>.<schema>.<name>. Apenas caracteres alfanuméricos e sublinhados são permitidos.Chave primária: Coluna a ser usada como chave primária.
Endpoint: Selecione o endpoint de pesquisa vetorial que pretende utilizar.
Colunas para sincronizar: Selecione as colunas a serem sincronizadas com o índice vetorial. Se você deixar esse campo em branco, todas as colunas da tabela de origem serão sincronizadas com o índice. A coluna de chave primária e a coluna de origem de incorporação ou a coluna de vetor de incorporação são sempre sincronizadas.
Incorporação de fontes: Indique se deseja que o Databricks calcule incorporações para uma coluna de texto na tabela Delta (Compute embeddings), ou se sua tabela Delta contém incorporações pré-computadas (Use a coluna de incorporação existente).
- Se você selecionou Incorporações de computação, selecione a coluna para a qual deseja que as incorporações sejam computadas e o ponto de extremidade que está servindo ao modelo de incorporação. Apenas colunas de texto são suportadas.
- Se você selecionou Usar coluna de incorporação existente, selecione a coluna que contém as incorporações pré-calculadas e a dimensão de incorporação. O formato da coluna de incorporação pré-calculada deve ser
array[float].
Sincronizar incorporações computadas: alterne essa configuração para salvar as incorporações geradas em uma tabela do Catálogo Unity. Para obter mais informações, consulte Salvar tabela de incorporação gerada.
modo de sincronização: Contínuo mantém o índice sincronizado com latência de segundos. No entanto, ele tem um custo mais alto associado a ele, uma vez que um cluster de computação é provisionado para executar o pipeline de streaming de sincronização contínua. Para Contínuo e Acionado, a atualização é incremental — apenas os dados que foram alterados desde a última sincronização são processados.
Com modo de sincronização Trigger, você usa o SDK do Python ou a API REST para iniciar a sincronização. Consulte Atualizar um índice de sincronização delta.
Quando terminar de configurar o índice, clique em Criar.
Criar índice usando o SDK do Python
O exemplo a seguir cria um índice Delta Sync com incorporações computadas por Databricks.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
O exemplo a seguir cria um índice de sincronização delta com incorporações autogerenciadas. Este exemplo também mostra o uso do parâmetro opcional columns_to_sync selecionar apenas um subconjunto de colunas para usar no índice.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
Por padrão, todas as colunas da tabela de origem são sincronizadas com o índice. Para sincronizar apenas um subconjunto de colunas, use columns_to_sync. A chave primária e as colunas de incorporação são sempre incluídas no índice.
Para sincronizar apenas a chave primária e a coluna de incorporação, você deve especificá-las em columns_to_sync conforme mostrado:
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Para sincronizar colunas adicionais, especifique-as conforme mostrado. Não é necessário incluir a chave primária e a coluna de incorporação, pois elas estão sempre sincronizadas.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
O exemplo a seguir cria um Direct Vetor Access Index.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name="{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Criar índice usando a API REST
Consulte a documentação de referência da API REST: POST /api/2.0/vector-search/indexes.
Salvar tabela de incorporação gerada
Se o Databricks gerar as incorporações, você poderá salvar as incorporações geradas em uma tabela no Unity Catalog. Esta tabela é criada no mesmo esquema que o índice vetorial e é vinculada a partir da página de índice vetorial.
O nome da tabela é o nome do índice de pesquisa vetorial, anexado por _writeback_table. O nome não é editável.
Você pode acessar e consultar a tabela como qualquer outra tabela no Unity Catalog. No entanto, você não deve soltar ou modificar a tabela, pois ela não se destina a ser atualizada manualmente. A tabela é excluída automaticamente se o índice for excluído.
Atualizar um índice de pesquisa vetorial
Atualizar um Índice Delta Sync
Os índices criados com modo de sincronização de contínua são atualizados automaticamente quando a tabela Delta de origem é alterada. Se você estiver usando modo de sincronização de acionado, use o SDK do Python ou a API REST para iniciar a sincronização.
Python SDK
index.sync()
REST API
Consulte a documentação de referência da API REST: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Atualizar um índice de acesso vetorial direto
Você pode usar o SDK do Python ou a API REST para inserir, atualizar ou excluir dados de um Direct Vetor Access Index.
Python SDK
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
REST API
Consulte a documentação de referência da API REST: POST /api/2.0/vector-search/indexes.
O exemplo de código a seguir ilustra como atualizar um índice usando um token de acesso pessoal (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
O exemplo de código a seguir ilustra como atualizar um índice usando um principal de serviço.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
Consultar um endpoint de pesquisa vetorial
Você pode consultar o endpoint de pesquisa vetorial apenas usando o SDK do Python, a API REST ou a função SQL vector_search() AI.
Observação
Se o usuário que está consultando o ponto de extremidade não for o proprietário do índice de pesquisa vetorial, o usuário deverá ter os seguintes privilégios de UC:
- USE CATALOG no catálogo que contém o índice de pesquisa vetorial.
- USE SCHEMA no esquema que contém o índice de pesquisa vetorial.
- SELECT no índice de pesquisa vetorial.
Para executar uma pesquisa híbrida de semelhança de palavras-chave, defina o parâmetro query_type como hybrid. O valor padrão é ann (vizinho mais próximo aproximado).
Python SDK
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
REST API
Consulte a documentação de referência da API REST: POST /api/2.0/vector-search/indexes/{index_name}/query.
O exemplo de código a seguir ilustra como consultar um índice usando um token de acesso pessoal (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Query Vector Search index with `query_vector`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index with `query_text`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
O exemplo de código a seguir ilustra como consultar um índice usando um principal de serviço.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "ReadVectorIndex"}'
# If you are using an route_optimized embedding model endpoint (TODO: link), then you need to have additional authorization details to invoke the serving endpoint
# export EMBEDDING_MODEL_SERVING_ENDPOINT_ID=...
# export AUTHORIZATION_DETAILS="$AUTHORIZATION_DETAILS"',{"type":"workspace_permission","object_type":"serving-endpoints","object_path":"/serving-endpoints/'"$EMBEDDING_MODEL_SERVING_ENDPOINT_ID"'","actions": ["query_inference_endpoint"]}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
SQL
Para usar esse função de IA, consulte vetor_search função.
Usar filtros em consultas
Uma consulta pode definir filtros com base em qualquer coluna na tabela Delta.
similarity_search retorna apenas linhas que correspondem aos filtros especificados. Os seguintes filtros são suportados:
| Operador de filtro | Comportamento | Exemplos |
|---|---|---|
NOT |
Nega o filtro. A chave deve terminar com "NÃO". Por exemplo, "color NOT" com o valor "red" corresponde a documentos em que a cor não é vermelha. |
{"id NOT": 2}
{“color NOT”: “red”}
|
< |
Verifica se o valor do campo é menor que o valor do filtro. A chave deve terminar com " <". Por exemplo, "preço <" com valor 200 corresponde a documentos em que o preço é inferior a 200. | {"id <": 200} |
<= |
Verifica se o valor do campo é menor ou igual ao valor do filtro. A chave deve terminar com " <=". Por exemplo, "preço <=" com valor 200 corresponde a documentos em que o preço é menor ou igual a 200. | {"id <=": 200} |
> |
Verifica se o valor do campo é maior do que o valor do filtro. A chave deve terminar com " >". Por exemplo, "preço >" com valor 200 corresponde a documentos em que o preço é superior a 200. | {"id >": 200} |
>= |
Verifica se o valor do campo é maior ou igual ao valor do filtro. A chave deve terminar com " >=". Por exemplo, "preço >=" com valor 200 corresponde a documentos em que o preço é maior ou igual a 200. | {"id >=": 200} |
OR |
Verifica se o valor do campo corresponde a algum dos valores de filtro. A chave deve conter OR para separar várias subchaves. Por exemplo, color1 OR color2 com valor ["red", "blue"] corresponde a documentos em que color1 é red ou color2 é blue. |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
Corresponde a cadeias de caracteres parciais. | {"column LIKE": "hello"} |
| Nenhum operador de filtro especificado | O filtro verifica se há uma correspondência exata. Se vários valores forem especificados, ele corresponderá a qualquer um dos valores. |
{"id": 200}
{"id": [200, 300]}
|
Consulte os seguintes exemplos de código:
Python SDK
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
REST API
Consulte POST /api/2.0/vector-search/indexes/{index_name}/query.
Exemplos de blocos de notas
Os exemplos nesta seção demonstram o uso do SDK Python de pesquisa vetorial.
Exemplos de LangChain
Consulte Como usar LangChain com Mosaic AI Vetor Search para usar o Mosaic AI Vetor Search como em integração com pacotes LangChain.
O bloco de anotações a seguir mostra como converter seus resultados de pesquisa de semelhança em documentos LangChain.
Pesquisa vetorial com o caderno do Python SDK
Exemplos de blocos de notas para chamar um modelo de incorporação
Os blocos de anotações a seguir demonstram como configurar um ponto de extremidade Mosaic AI Model Serving para geração de incorporações.