Desenvolver e depurar pipelines DLT em notebooks
Importante
A experiência do notebook para desenvolvimento de DLT está em Public Preview.
Este artigo descreve os recursos nos blocos de anotações do Azure Databricks que ajudam no desenvolvimento e depuração do código DLT.
Visão geral dos recursos
Quando você trabalha em um bloco de anotações Python ou SQL configurado como código-fonte para um pipeline DLT existente, você pode conectar o bloco de anotações diretamente ao pipeline. Quando o notebook está conectado ao pipeline, os seguintes recursos estão disponíveis:
- Inicie e valide o pipeline a partir do notebook.
- Veja o gráfico de fluxo de dados e o log de eventos do pipeline para obter a atualização mais recente no notebook.
- Visualize o diagnóstico de pipeline no editor de bloco de anotações.
- Exiba o status do cluster do pipeline no bloco de anotações.
- Aceda à IU DLT a partir do notebook.
Pré-requisitos
- Você deve ter um pipeline DLT existente com um bloco de anotações Python ou SQL configurado como código-fonte.
- Você deve ser o proprietário do pipeline ou ter o privilégio
CAN_MANAGE.
Limitações
- Os recursos abordados neste artigo só estão disponíveis em blocos de anotações do Azure Databricks. Não há suporte para arquivos de espaço de trabalho.
- O terminal web não está disponível quando conectado a um pipeline. Como resultado, ele não é visível como uma guia no painel inferior.
Conectar um portátil a um pipeline DLT
Dentro do caderno, clique no menu suspenso usado para selecionar o recurso de computação. O menu suspenso mostra todos os seus pipelines de DLT com este bloco de anotações como código-fonte. Para ligar o notebook a um pipeline, selecione-o na lista.
Ver o estado do cluster do pipeline
Para entender facilmente o estado do cluster do pipeline, seu status é mostrado no menu suspenso de computação com uma cor verde para indicar que o cluster está em execução.
Validar código de pipeline
Você pode validar o pipeline para verificar erros de sintaxe no seu código-fonte sem processar quaisquer dados.
Para validar um pipeline, siga um destes procedimentos:
- No canto superior direito do bloco de notas, clique em Validar.
- Pressione
Shift+Enterem qualquer célula do bloco de anotações. - No menu suspenso de uma célula, clique em Validar pipeline.
Observação
Se você tentar validar seu pipeline enquanto uma atualização existente já estiver em execução, uma caixa de diálogo será exibida perguntando se você deseja encerrar a atualização existente. Se clicar em Sim, a atualização existente será interrompida e uma atualização de validação será iniciada automaticamente.
Iniciar uma atualização de pipeline
Para iniciar uma atualização do seu pipeline, clique no botão Iniciar no canto superior direito do notebook. Consulte Realizar uma atualização num pipeline de DLT.
Exibir o status de uma atualização
O painel superior do bloco de anotações exibe se uma atualização de pipeline é:
- Início
- Validação
- Parar
Ver erros e diagnósticos
Depois de iniciar uma atualização ou validação de pipeline, todos os erros são mostrados em linha com um sublinhado vermelho. Passe o cursor sobre um erro para ver mais informações.
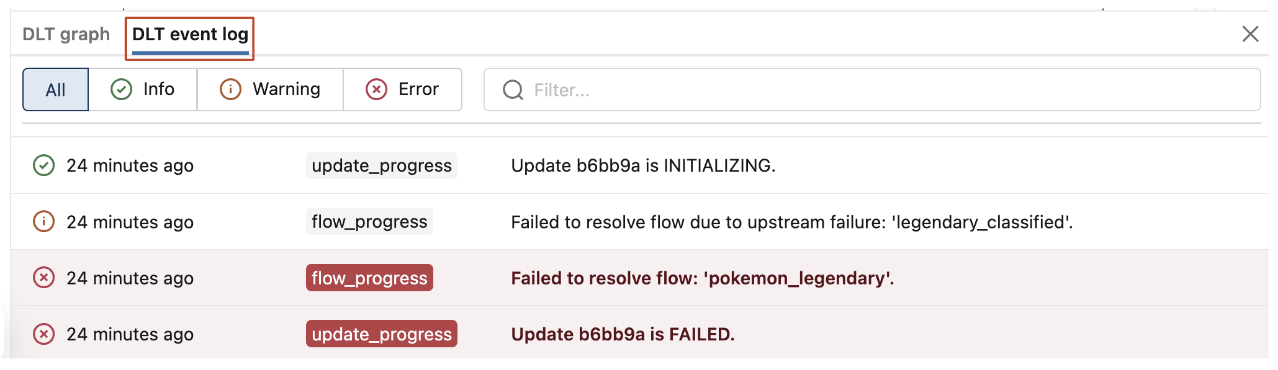
Visualizar eventos de pipeline
Quando anexado a um pipeline, há uma aba de log de eventos DLT na parte inferior do notebook.
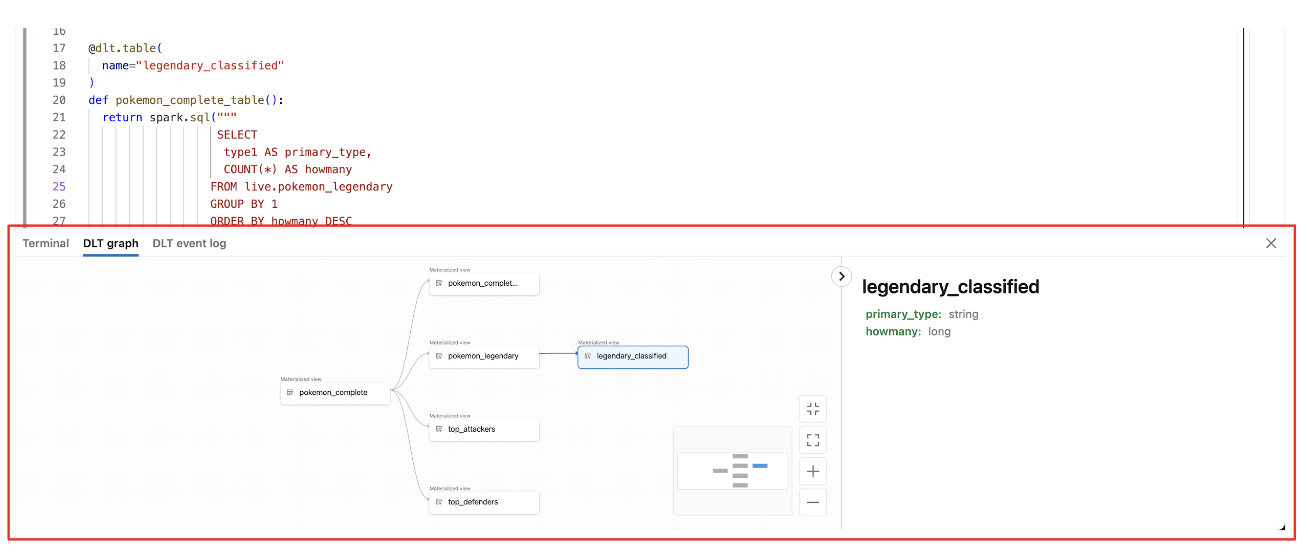
Exibir o gráfico de fluxo de dados do pipeline
Para exibir o gráfico de fluxo de dados de um pipeline, use a guia Gráfico DLT na parte inferior do bloco de anotações. A seleção de um nó no gráfico exibe o esquema no painel direito.
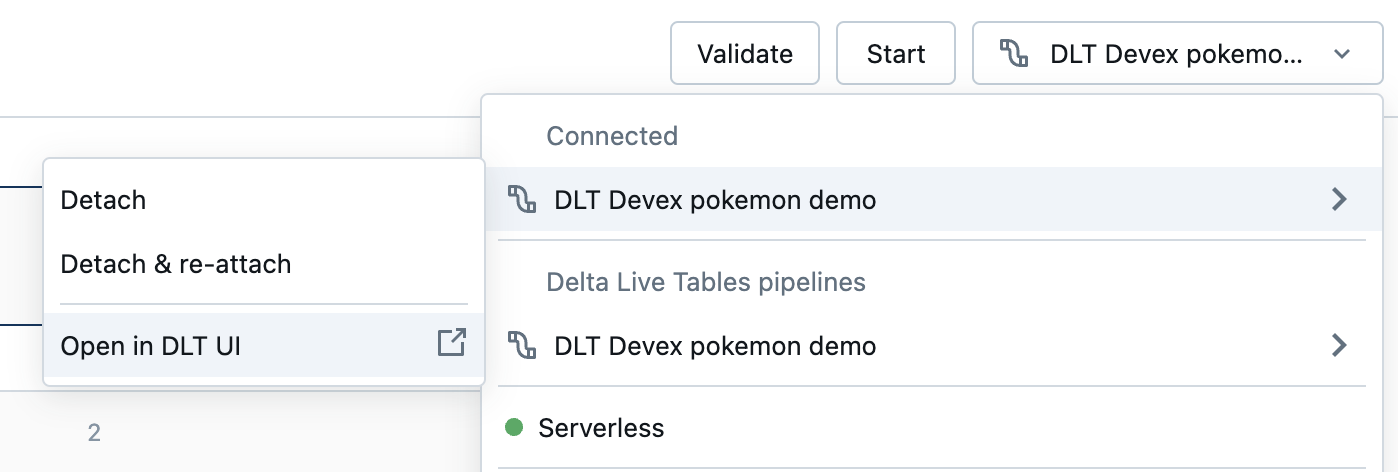
Como aceder à interface DLT a partir do bloco de notas
Para saltar facilmente para a IU DLT, utilize o menu no canto superior direito do bloco de notas.
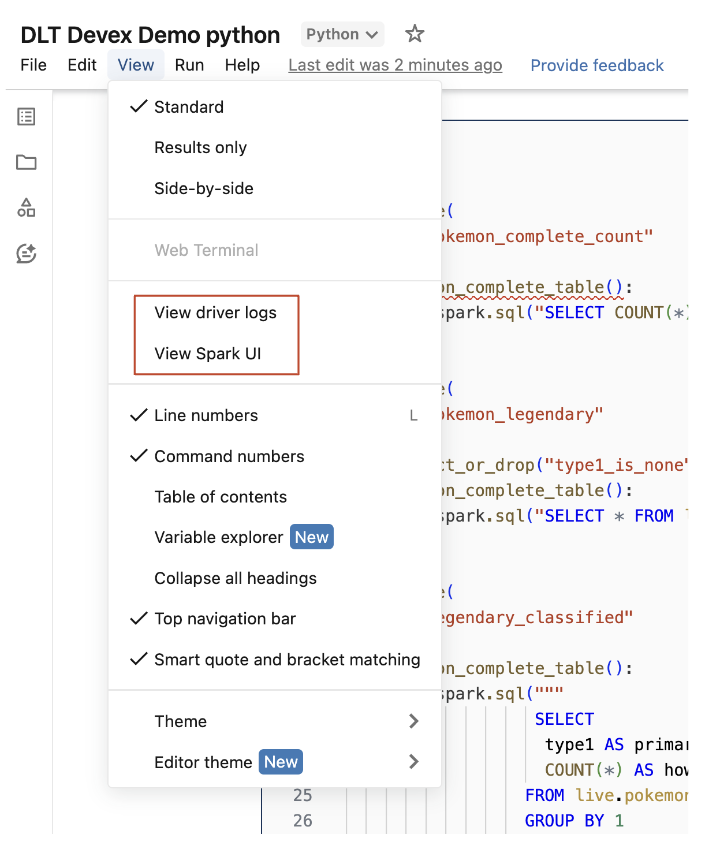
Aceder aos registos do driver e à interface do utilizador do Spark no notebook.
Os registos do driver e a interface de utilizador do Spark associados ao pipeline que está a ser desenvolvido podem ser facilmente acedidos no menu View do notebook.
 da interface do utilizador do Spark
da interface do utilizador do Spark