Capture e visualize linhagens de dados usando o Unity Catalog
Este artigo descreve como capturar e visualizar linhagem de dados usando o Catalog Explorer, as tabelas do sistema de linhagem de dados e a API REST.
Você pode usar o Unity Catalog para capturar linhagem de dados de tempo de execução em consultas executadas no Azure Databricks. A linhagem é suportada para todos os idiomas e é capturada até ao nível da coluna. Os dados de linhagem incluem blocos de anotações, trabalhos e painéis relacionados à consulta. A linhagem pode ser visualizada no Catalog Explorer quase em tempo real e recuperada programaticamente usando as tabelas do sistema de linhagem e a API REST do Databricks.
A linhagem é agregada em todos os espaços de trabalho anexados ao metastore do Unity Catalog. Isso significa que a linhagem capturada em um espaço de trabalho é visível em qualquer outro espaço de trabalho que compartilhe esse metastore. Especificamente, tabelas e outros objetos de dados registrados no metastore são visíveis para usuários que têm pelo menos BROWSE permissões nesses objetos, em todos os espaços de trabalho anexados ao metastore. No entanto, informações detalhadas sobre objetos no nível do espaço de trabalho, como blocos de anotações e painéis em outros espaços de trabalho, são mascaradas (consulte Limitações e Permissões de linhagem).
Os dados de linhagem são retidos por um ano.
A imagem a seguir é um gráfico de linhagem de exemplo. Exemplos e funcionalidades específicas de linhagem de dados são abordados mais adiante neste artigo.
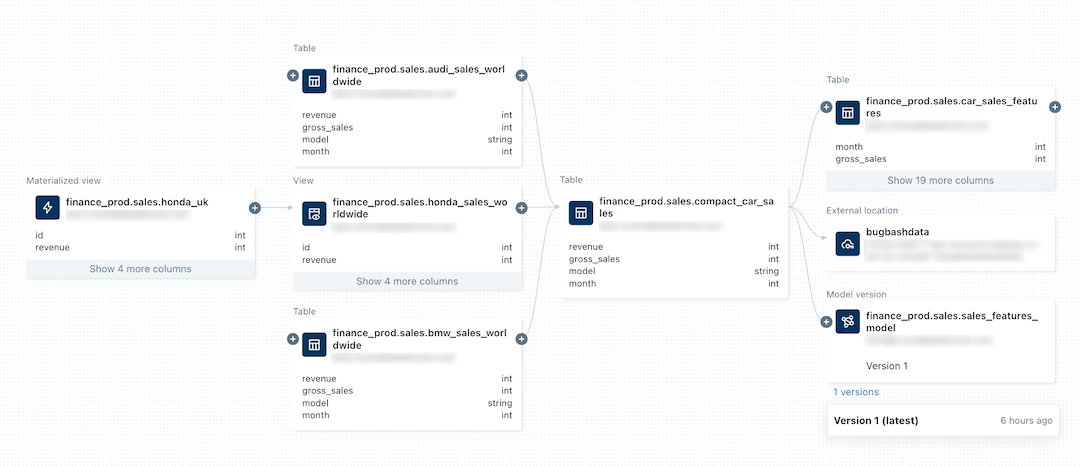
Para obter informações sobre como controlar a linhagem de um modelo de aprendizado de máquina, consulte Controlar a linhagem de dados de um modelo no Unity Catalog.
Requisitos
O seguinte é necessário para capturar linhagem de dados usando o Unity Catalog:
O espaço de trabalho deve ter o Unity Catalog ativado.
As tabelas devem ser registradas em um metastore do Catálogo Unity.
As consultas têm de utilizar o Spark DataFrame (por exemplo, funções do Spark SQL que devolvem um DataFrame) ou interfaces SQL do Databricks. Para obter exemplos de consultas Databricks SQL e PySpark, consulte Exemplos.
Para exibir a linhagem de uma tabela ou exibição, os usuários devem ter pelo menos o privilégio
BROWSEno catálogo pai da tabela ou exibição. O catálogo pai também deve estar acessível a partir do espaço de trabalho. Consulte Limitar o acesso do catálogo a espaços de trabalho específicos.Para exibir informações de linhagem para blocos de anotações, trabalhos ou painéis, os usuários devem ter permissões nesses objetos, conforme definido pelas configurações de controle de acesso no espaço de trabalho. Consulte Permissões de linhagem.
Para exibir a linhagem de um pipeline habilitado para Unity Catalog, você deve ter permissões de
CAN_VIEWno pipeline.O rastreamento de linhagem de streaming entre tabelas Delta requer o Databricks Runtime 11.3 LTS ou superior.
O rastreamento de linhagem de colunas para cargas de trabalho do Delta Live Tables requer o Databricks Runtime 13.3 LTS ou uma versão superior.
Poderá ser necessário atualizar as suas regras de firewall de saída para permitir a conectividade com o ponto final dos Hubs de Eventos no plano de controlo do Azure Databricks. Normalmente, isso se aplica se seu espaço de trabalho do Azure Databricks for implantado em sua própria VNet (também conhecida como injeção de VNet). Para obter o ponto de extremidade dos Hubs de Eventos para a sua região de espaço de trabalho, consulte Metastore, armazenamento de objetos Blob de artefatos, armazenamento de objetos Blob para tabelas do sistema, armazenamento de objetos Blob para logs e endereços IP de pontos de extremidade dos Hubs de Eventos. Para obter informações sobre como configurar rotas definidas pelo utilizador (UDR) para o Azure Databricks, veja Definições de rota definidas pelo utilizador para o Azure Databricks.
Exemplos
Nota
Os exemplos a seguir usam o nome do catálogo
lineage_datae o nome do esquemalineagedemo. Para usar um catálogo e esquema diferentes, altere os nomes usados nos exemplos.Para concluir este exemplo, você deve ter privilégios de
CREATEeUSE SCHEMAem um esquema. Um administrador de metastore, proprietário de catálogo, proprietário de esquema ou usuário com o privilégio deMANAGEno esquema pode conceder esses privilégios. Por exemplo, para dar a todos os usuários do grupo 'data_engineers' permissão para criar tabelas no esquemalineagedemono catálogolineage_data, um usuário com um dos privilégios ou funções acima pode executar as seguintes consultas:CREATE SCHEMA lineage_data.lineagedemo; GRANT USE SCHEMA, CREATE on SCHEMA lineage_data.lineagedemo to `data_engineers`;
Capture e explore a linhagem
Para capturar dados de linhagem:
Vá para a página inicial do Azure Databricks, clique no ícone
 Novo na barra lateral e selecione Bloco de Anotações no menu.
Novo na barra lateral e selecione Bloco de Anotações no menu.Insira um nome para o bloco de anotações e selecione SQL em Idioma Padrão.
Em Cluster, selecione um cluster com acesso ao Catálogo Unity.
Clique em Criar.
Na primeira célula do bloco de notas, introduza as seguintes consultas:
CREATE TABLE IF NOT EXISTS lineage_data.lineagedemo.menu ( recipe_id INT, app string, main string, dessert string ); INSERT INTO lineage_data.lineagedemo.menu (recipe_id, app, main, dessert) VALUES (1,"Ceviche", "Tacos", "Flan"), (2,"Tomato Soup", "Souffle", "Creme Brulee"), (3,"Chips","Grilled Cheese","Cheesecake"); CREATE TABLE lineage_data.lineagedemo.dinner AS SELECT recipe_id, concat(app," + ", main," + ",dessert) AS full_menu FROM lineage_data.lineagedemo.menuPara executar as consultas, clique na célula e pressione shift+enter ou clique em
 Executar Menu e selecione Executar célula.
Executar Menu e selecione Executar célula.
Para usar o Catalog Explorer para exibir a linhagem gerada por essas consultas:
Na caixa de pesquisa Pesquisa na barra superior do espaço de trabalho do Azure Databricks, procure pela tabela
lineage_data.lineagedemo.dinnere selecione-a.Selecione a guia Linhagem. O painel de linhagem aparece e exibe tabelas relacionadas (para este exemplo, é a tabela
menu).Para exibir um gráfico interativo da linhagem de dados, clique em Ver gráfico de linhagem. Por padrão, um nível é exibido no gráfico. Clique no ícone
 num nó para revelar mais conexões, se estiverem disponíveis.
num nó para revelar mais conexões, se estiverem disponíveis.Clique em uma seta que conecta nós no gráfico de linhagem para abrir o painel de conexão Linhagem. O painel de conexão Lineage mostra detalhes sobre a conexão, incluindo tabelas de origem e destino, notebooks e trabalhos.
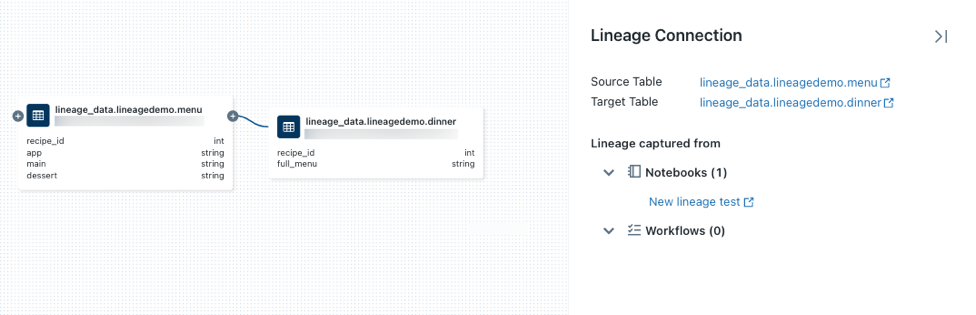
Para mostrar o caderno associado à tabela
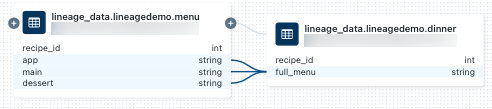
dinner, selecione o caderno no painel de conexão Lineage ou feche o gráfico de linhagem e clique em em Notebooks. Para abrir o bloco de notas num novo separador, clique no nome do bloco de notas.Para exibir a linhagem em nível de coluna, clique em uma coluna no gráfico para mostrar links para colunas relacionadas. Por exemplo, clicar na coluna «full_menu» mostra as colunas a montante das quais a coluna foi derivada:
Para visualizar a linhagem usando uma linguagem diferente, por exemplo, Python:
Abra o bloco de notas que criou anteriormente, crie uma nova célula e introduza o seguinte código Python:
%python from pyspark.sql.functions import rand, round df = spark.range(3).withColumn("price", round(10*rand(seed=42),2)).withColumnRenamed("id","recipe_id") df.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.price") dinner = spark.read.table("lineage_data.lineagedemo.dinner") price = spark.read.table("lineage_data.lineagedemo.price") dinner_price = dinner.join(price, on="recipe_id") dinner_price.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.dinner_price")Execute a célula clicando na célula e pressionando shift+enter ou clicando
e selecionando Executar célula.Na caixa Pesquisa na barra superior do espaço de trabalho do Azure Databricks, procure a tabela
lineage_data.lineagedemo.pricee selecione-a.Vá para a guia Linhagem e clique em Ver gráfico de linhagem. Clique nos
ícones para explorar a linhagem de dados gerada pelas consultas.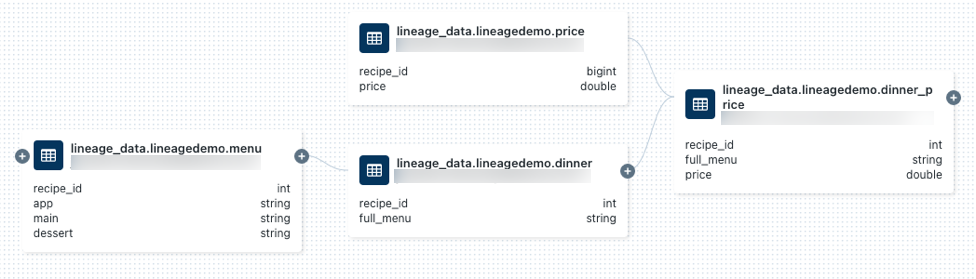
Clique em uma seta que conecta nós no gráfico de linhagem para abrir o painel de conexão Linhagem. O painel de conexão do Lineage
mostra detalhes sobre a conexão, incluindo tabelas de origem e destino, notebooks e trabalhos.
Capturar e visualizar linhagem de fluxo de trabalho
O Lineage também é capturado para qualquer fluxo de trabalho que leia ou grave no Unity Catalog. Para exibir a linhagem de um fluxo de trabalho do Azure Databricks:
Clique
Novo na barra lateral e selecione Notebook no menu.Insira um nome para o bloco de anotações e selecione SQL em de idioma padrão .
Clique em Criar.
Na primeira célula do bloco de notas, introduza a seguinte consulta:
SELECT * FROM lineage_data.lineagedemo.menuClique em Agendar na barra superior. Na caixa de diálogo de agendamento, selecione Manual, selecione um cluster com acesso ao Unity Catalog e clique em Criar.
Clique em Executar agora.
Na caixa Pesquisa
na barra superior do espaço de trabalho do Azure Databricks, procure a tabela e selecione-a. Na guia Linhagem, clique em Fluxos de Trabalho , e selecione a guia Downstream . O nome do trabalho aparece sob Nome do Trabalho como um consumidor da tabela
menu.
Capture e visualize a linhagem do painel
Para criar um painel e exibir sua linhagem de dados:
Vá para a página inicial do Azure Databricks e abra o Explorador de Catálogo clicando em Catálogo na barra lateral.
Clique no nome do catálogo, clique lineagedemoe selecione a tabela
menu. Também pode utilizar a caixa Pesquisa na barra superior para procurar a tabelamenu.Clique em Abrir em um painel.
Selecione as colunas que deseja adicionar ao painel e clique Criar.
Publique o painel.
Somente os painéis publicados são rastreados na linhagem de dados.
Na caixa Pesquisa na barra superior, procure a tabela
lineage_data.lineagedemo.menue selecione-a.Na guia Linhagem, clique em Painéis. O painel aparece sob Nome do Painel como um utilizador da tabela do menu.
Permissões de linhagem
Os gráficos de linhagem partilham o mesmo modelo de permissão que o Unity Catalog. As tabelas e outros objetos de dados registrados no metastore do Unity Catalog são visíveis apenas para usuários que têm pelo menos BROWSE permissões nesses objetos. Se um usuário não tiver o privilégio de BROWSE ou SELECT em uma tabela, ele não poderá explorar sua linhagem. Os gráficos de linhagem exibem objetos do Unity Catalog em todos os espaços de trabalho anexados ao metastore, desde que o usuário tenha permissões de objeto adequadas.
Por exemplo, execute os seguintes comandos para userA:
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
Quando userA visualiza o gráfico de linhagem para a tabela lineage_data.lineagedemo.menu, eles verão a tabela menu. Eles não poderão ver informações sobre tabelas associadas, como a tabela lineage_data.lineagedemo.dinner a jusante. A tabela dinner é exibida como um nó masked na exibição para userA, e userA não podem expandir o gráfico para revelar tabelas descendentes a partir de tabelas às quais não têm permissão de acesso.
Se você executar o seguinte comando para conceder permissão ao BROWSE para userB, esse usuário poderá exibir o gráfico de linhagem de qualquer tabela no esquema lineage_data.:
GRANT BROWSE on lineage_data to `userB@company.com`;
Da mesma forma, os usuários de linhagem devem ter permissões específicas para exibir objetos de espaço de trabalho, como blocos de anotações, trabalhos e painéis. Além disso, eles só podem ver informações detalhadas sobre objetos de espaço de trabalho quando estiverem conectados ao espaço de trabalho no qual esses objetos foram criados. Informações detalhadas sobre objetos no nível do espaço de trabalho em outros espaços de trabalho são mascaradas no gráfico de linhagem.
Para obter mais informações sobre como gerenciar o acesso a objetos protegíveis no Unity Catalog, consulte Manage privileges in Unity Catalog. Para obter mais informações sobre como gerenciar o acesso a objetos de espaço de trabalho, como blocos de anotações, trabalhos e painéis, consulte Listas de controle de acesso.
Excluir dados de linhagem
Aviso
As instruções a seguir excluem todos os objetos armazenados no Catálogo Unity. Utilize estas instruções apenas se necessário. Por exemplo, para atender aos requisitos de conformidade.
Para excluir dados de linhagem, você deve excluir o metastore que gerencia os objetos do Unity Catalog. Para obter mais informações sobre como excluir o metastore, consulte Excluir um metastore. Os dados serão eliminados no prazo de 90 dias.
Consultar dados de linhagem usando tabelas do sistema
Você pode usar as tabelas do sistema de linhagem para consultar programaticamente dados de linhagem. Para obter instruções detalhadas, consulte Monitorizar a atividade da conta com as tabelas do sistema e as tabelas do sistema de referência Lineage .
Se seu espaço de trabalho estiver em uma região que não ofereça suporte a tabelas do sistema de linhagem, você poderá, alternativamente, usar a API REST de linhagem de dados para recuperar dados de linhagem programaticamente.
Recuperar linhagem usando a API REST de linhagem de dados
A API de linhagem de dados permite recuperar linhagens de tabelas e colunas. No entanto, se o espaço de trabalho estiver em uma região que ofereça suporte às tabelas do sistema de linhagem, você deverá usar consultas de tabela do sistema em vez da API REST. As tabelas do sistema são uma opção melhor para a recuperação programática de dados de linhagem. A maioria das regiões suporta as tabelas do sistema de linhagem.
Importante
Para aceder às APIs REST do Databricks, tem de se autenticar.
Recuperar linhagem de tabela
Este exemplo recupera dados de linhagem para a tabela dinner.
Pedir
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/table-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "include_entity_lineage": true}'
Substitua <workspace-instance>.
Este exemplo usa um arquivo .netrc .
Response
{
"upstreams": [
{
"tableInfo": {
"name": "menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
],
"downstreams": [
{
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
},
{
"tableInfo": {
"name": "dinner_price",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
]
}
Recuperar linhagem da coluna
Este exemplo recupera dados de coluna para a tabela dinner.
Pedir
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/column-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "column_name": "dessert"}'
Substitua <workspace-instance>.
Este exemplo usa um arquivo .netrc .
Response
{
"upstream_cols": [
{
"name": "dessert",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "main",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "app",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
}
],
"downstream_cols": [
{
"name": "full_menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "dinner_price",
"table_type": "TABLE"
}
]
}
Limitações
Embora a linhagem seja agregada para todos os espaços de trabalho anexados ao mesmo metastore do Unity Catalog, os detalhes dos objetos do espaço de trabalho, como blocos de anotações e painéis, são visíveis apenas no espaço de trabalho no qual foram criados.
Como a linhagem é calculada em uma janela de rolagem de um ano, a linhagem coletada há mais de um ano não é exibida. Por exemplo, se um trabalho ou consulta ler dados da tabela A e gravar na tabela B, o link entre a tabela A e a tabela B será exibido por apenas um ano. Você pode filtrar dados de linhagem por período de tempo dentro da janela de um ano.
Os trabalhos que usam a solicitação da API
runs submitde Trabalhos não estão disponíveis ao exibir a linhagem. A linhagem de nível de tabela e coluna ainda é capturada ao usar a solicitaçãoruns submit, mas o link para a execução não é capturado.Unity Catalog captura a linhagem ao nível da coluna sempre que possível. No entanto, há alguns casos em que a linhagem em nível de coluna não pode ser capturada.
A linhagem de coluna é suportada somente quando a origem e o destino são referenciados pelo nome da tabela (Exemplo:
select * from <catalog>.<schema>.<table>). A linhagem de coluna não pode ser capturada se a origem ou o destino estiverem identificados por caminho (Exemplo:select * from delta."s3://<bucket>/<path>").Se uma tabela ou exibição for renomeada, a linhagem não será capturada para a tabela ou exibição renomeada.
Se um esquema ou catálogo for renomeado, a linhagem não será capturada para tabelas e exibições no catálogo ou esquema renomeado.
Se usar o ponto de verificação do conjunto de dados Spark SQL, a linhagem não será capturada.
O Unity Catalog captura linhagem de pipelines Delta Live Tables na maioria dos casos. No entanto, em alguns casos, a cobertura completa de linhagem não pode ser garantida, como quando os pipelines usam a API APPLY CHANGES ou tabelas TEMPORARY.
Lineage não captura funções de pilha.
As visualizações globais de temperatura não são capturadas na linhagem.
Tabelas abaixo
system.information_schemanão são capturadas em linhagem.A linhagem completa em nível de coluna não é capturada por padrão para operações
MERGE.Você pode ativar a captura de linhagem para
MERGEoperações definindo a propriedadespark.databricks.dataLineage.mergeIntoV2EnabledSpark comotrue. Habilitar esse sinalizador pode diminuir o desempenho da consulta, especialmente em cargas de trabalho que envolvem tabelas muito amplas.