Implantar uma carga de trabalho do IoT Edge usando o compartilhamento de GPU em seu Azure Stack Edge Pro
Este artigo descreve como cargas de trabalho em contêineres podem compartilhar as GPUs em seu dispositivo de GPU do Azure Stack Edge Pro. A abordagem envolve habilitar o MPS (Multi-Process Service) e, em seguida, especificar as cargas de trabalho da GPU por meio de uma implantação do IoT Edge.
Pré-requisitos
Antes de começar, certifique-se de que:
Você tem acesso a um dispositivo de GPU do Azure Stack Edge Pro que está ativado e tem computação configurada. Você tem o ponto de extremidade da API do Kubernetes e adicionou esse ponto de extremidade ao
hostsarquivo no seu cliente que acessará o dispositivo.Você tem acesso a um sistema cliente com um sistema operacional suportado. Se estiver usando um cliente Windows, o sistema deverá executar o PowerShell 5.0 ou posterior para acessar o dispositivo.
Salve a seguinte implantação
jsonem seu sistema local. Você usará as informações desse arquivo para executar a implantação do IoT Edge. Essa implantação é baseada em contêineres CUDA simples que estão disponíveis publicamente na NVIDIA.{ "modulesContent": { "$edgeAgent": { "properties.desired": { "modules": { "cuda-sample1": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" }, "cuda-sample2": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" } }, "runtime": { "settings": { "minDockerVersion": "v1.25" }, "type": "docker" }, "schemaVersion": "1.1", "systemModules": { "edgeAgent": { "settings": { "image": "mcr.microsoft.com/azureiotedge-agent:1.0", "createOptions": "" }, "type": "docker" }, "edgeHub": { "settings": { "image": "mcr.microsoft.com/azureiotedge-hub:1.0", "createOptions": "{\"HostConfig\":{\"PortBindings\":{\"443/tcp\":[{\"HostPort\":\"443\"}],\"5671/tcp\":[{\"HostPort\":\"5671\"}],\"8883/tcp\":[{\"HostPort\":\"8883\"}]}}}" }, "type": "docker", "status": "running", "restartPolicy": "always" } } } }, "$edgeHub": { "properties.desired": { "routes": { "route": "FROM /messages/* INTO $upstream" }, "schemaVersion": "1.1", "storeAndForwardConfiguration": { "timeToLiveSecs": 7200 } } }, "cuda-sample1": { "properties.desired": {} }, "cuda-sample2": { "properties.desired": {} } } }
Verifique o driver da GPU, versão CUDA
O primeiro passo é verificar se o dispositivo está executando o driver de GPU necessário e as versões CUDA.
Execute o seguinte comando:
Get-HcsGpuNvidiaSmiNa saída NVIDIA smi, anote a versão da GPU e a versão CUDA no seu dispositivo. Se você estiver executando o software Azure Stack Edge 2102, esta versão corresponderá às seguintes versões de driver:
- Versão do driver GPU: 460.32.03
- CUDA versão: 11.2
Aqui está um exemplo de saída:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Tue Feb 23 10:34:01 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 0000041F:00:00.0 Off | 0 | | N/A 40C P8 15W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Mantenha esta sessão aberta, pois você a usará para visualizar a saída NVIDIA smi ao longo do artigo.
Implantar sem compartilhamento de contexto
Agora você pode implantar um aplicativo em seu dispositivo quando o Multi-Process Service não estiver em execução e não houver compartilhamento de contexto. A implantação é feita por meio do portal do Azure no iotedge namespace que existe no seu dispositivo.
Criar usuário no namespace IoT Edge
Primeiro, você criará um usuário que se conectará ao iotedge namespace. Os módulos IoT Edge são implantados no namespace iotedge. Para obter mais informações, consulte Namespaces do Kubernetes em seu dispositivo.
Siga estas etapas para criar um usuário e conceder ao usuário o acesso ao iotedge namespace.
Crie um novo usuário no
iotedgenamespace. Execute o seguinte comando:New-HcsKubernetesUser -UserName <user name>Aqui está um exemplo de saída:
[10.100.10.10]: PS>New-HcsKubernetesUser -UserName iotedgeuser apiVersion: v1 clusters: - cluster: certificate-authority-data: ===========================//snipped //======================// snipped //============================= server: https://compute.myasegpudev.wdshcsso.com:6443 name: kubernetes contexts: - context: cluster: kubernetes user: iotedgeuser name: iotedgeuser@kubernetes current-context: iotedgeuser@kubernetes kind: Config preferences: {} users: - name: iotedgeuser user: client-certificate-data: ===========================//snipped //======================// snipped //============================= client-key-data: ===========================//snipped //======================// snipped ============================ PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=Copie a saída exibida em texto sem formatação. Salve a saída como um arquivo de configuração (sem extensão) na
.kubepasta do seu perfil de usuário em sua máquina local, por exemplo,C:\Users\<username>\.kube.Conceda ao usuário que você criou, acesso ao
iotedgenamespace. Execute o seguinte comando:Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName <user name>Aqui está um exemplo de saída:
[10.100.10.10]: PS>Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName iotedgeuser [10.100.10.10]: PS>
Para obter instruções detalhadas, consulte Conectar-se e gerenciar um cluster Kubernetes via kubectl em seu dispositivo GPU Azure Stack Edge Pro.
Implantar módulos via portal
Implante módulos do IoT Edge por meio do portal do Azure. Você implantará módulos de exemplo NVIDIA CUDA disponíveis publicamente que executam a simulação de n corpos.
Certifique-se de que o serviço IoT Edge está em execução no seu dispositivo.
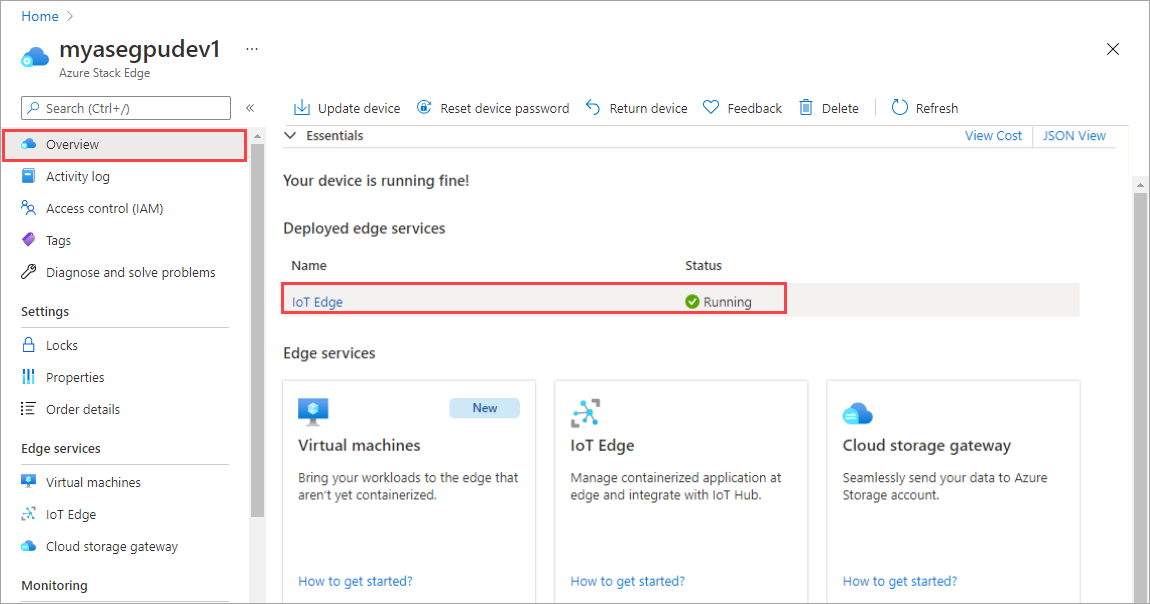
Selecione o bloco IoT Edge no painel direito. Vá para Propriedades do IoT Edge>. No painel direito, selecione o recurso do Hub IoT associado ao seu dispositivo.
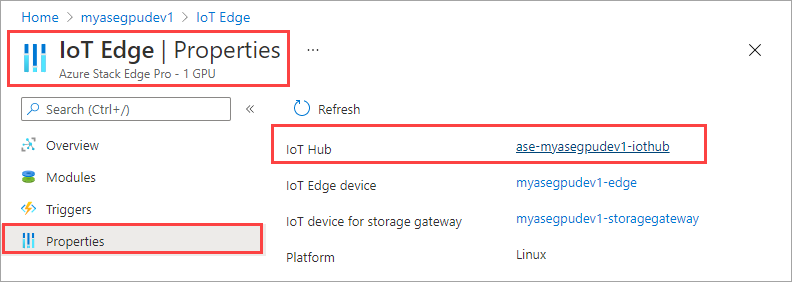
No recurso Hub IoT, vá para Gerenciamento Automático de > Dispositivos IoT Edge. No painel direito, selecione o dispositivo IoT Edge associado ao seu dispositivo.
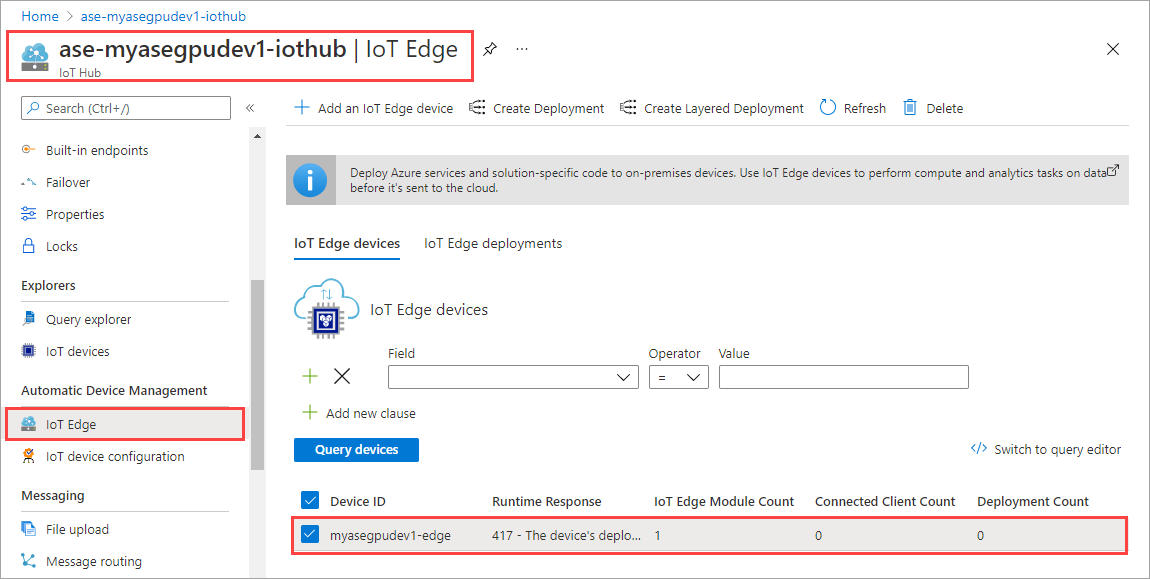
Selecione Definir módulos.
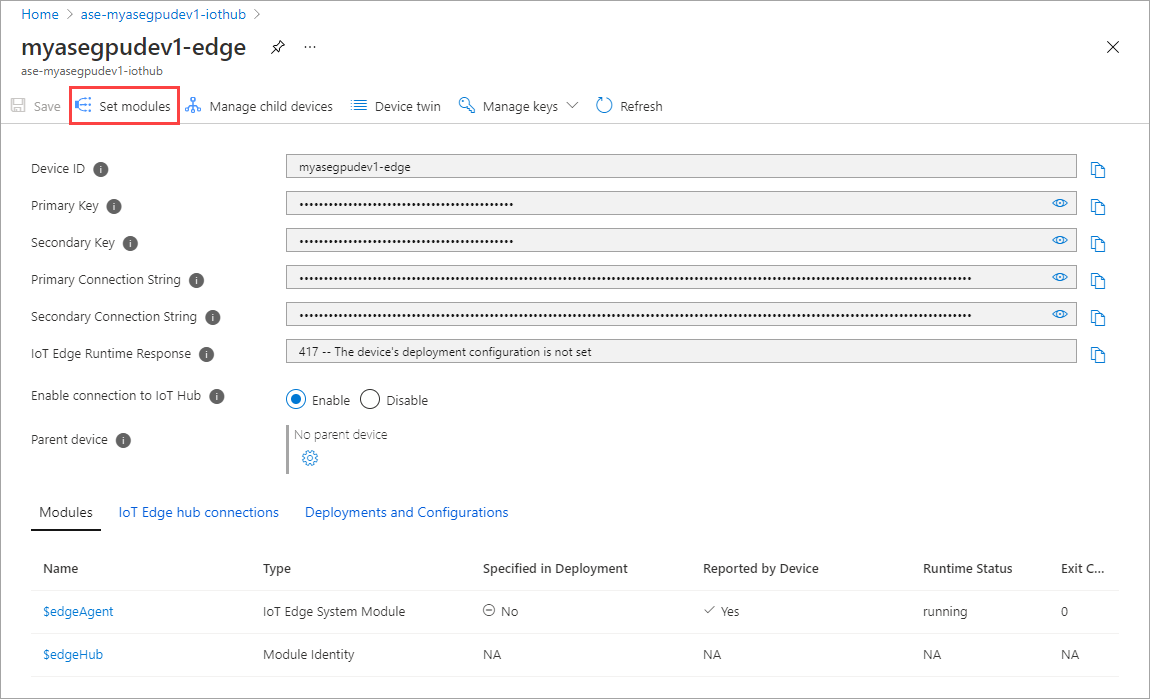
Selecione + Adicionar + módulo >IoT Edge.
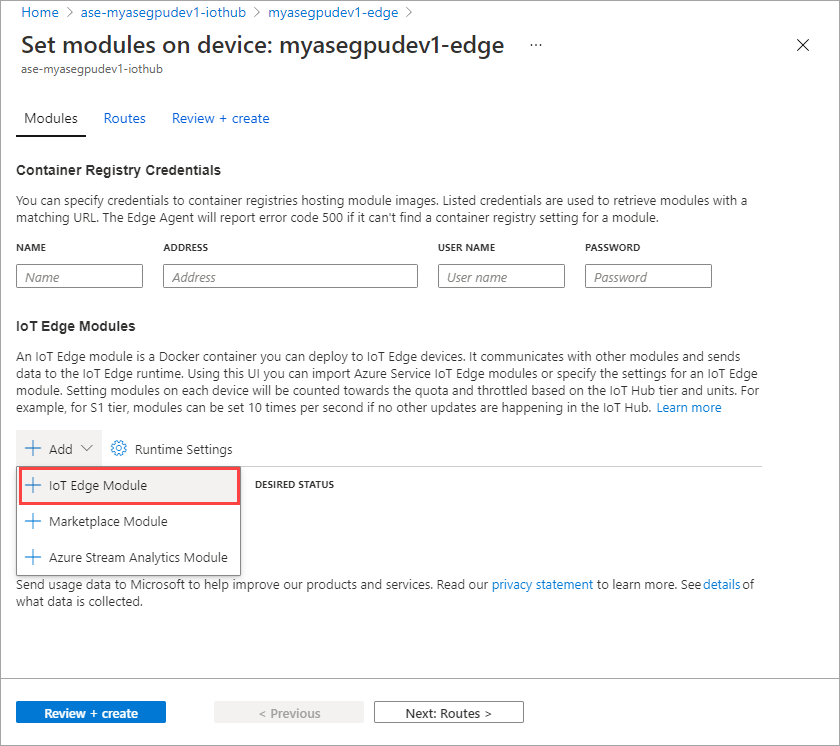
Na guia Configurações do módulo, forneça o nome do módulo IoT Edge e o URI da imagem. Defina a política de pull de imagem como Ao criar.
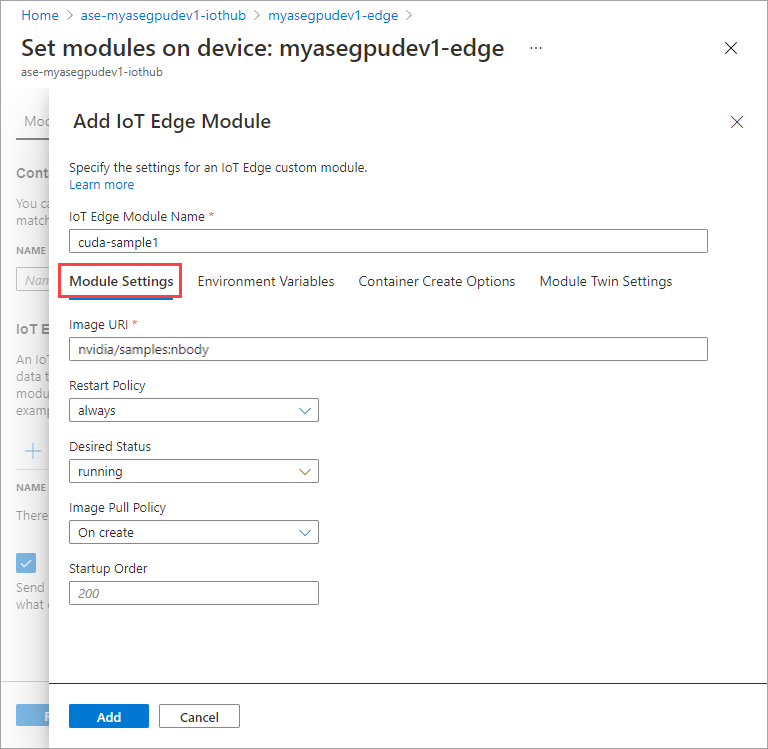
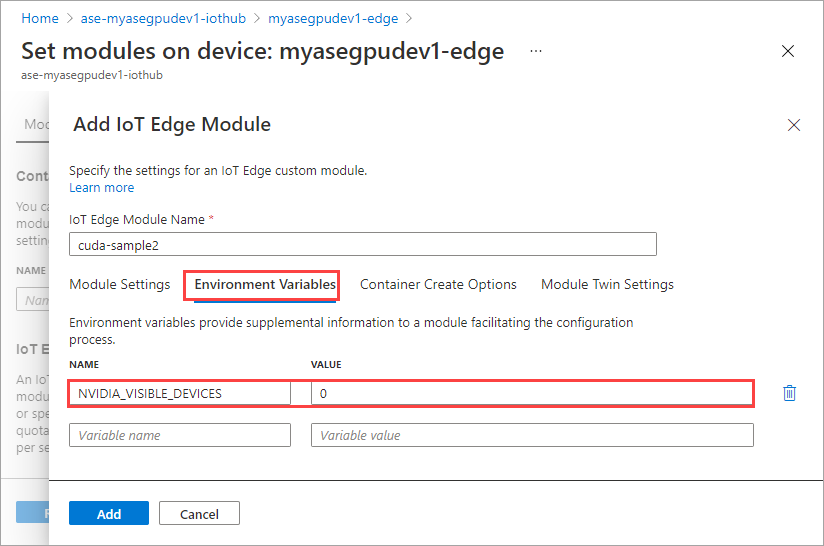
Na guia Variáveis de Ambiente, especifique NVIDIA_VISIBLE_DEVICES como 0.
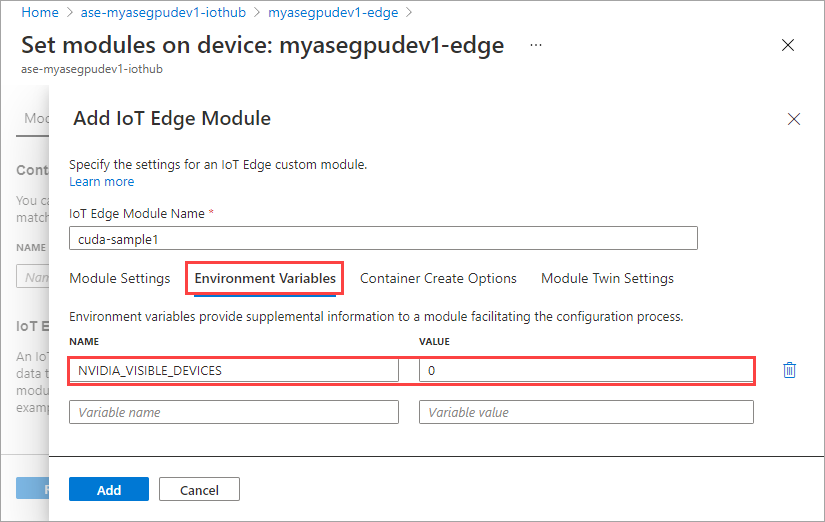
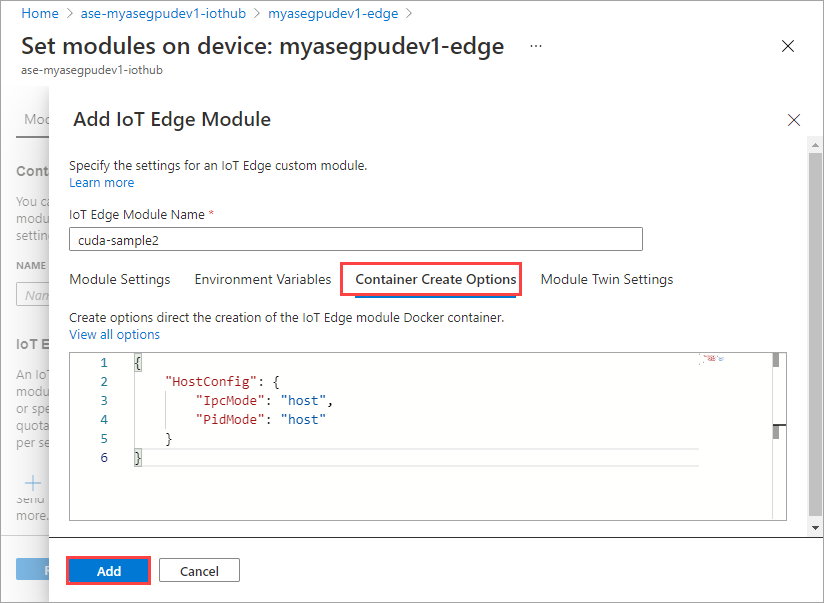
Na guia Opções de Criação de Contêiner, forneça as seguintes opções:
{ "Entrypoint": [ "/bin/sh" ], "Cmd": [ "-c", "/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done" ], "HostConfig": { "IpcMode": "host", "PidMode": "host" } }As opções são exibidas da seguinte forma:
Selecione Adicionar.
O módulo que você adicionou deve mostrar como Em execução.
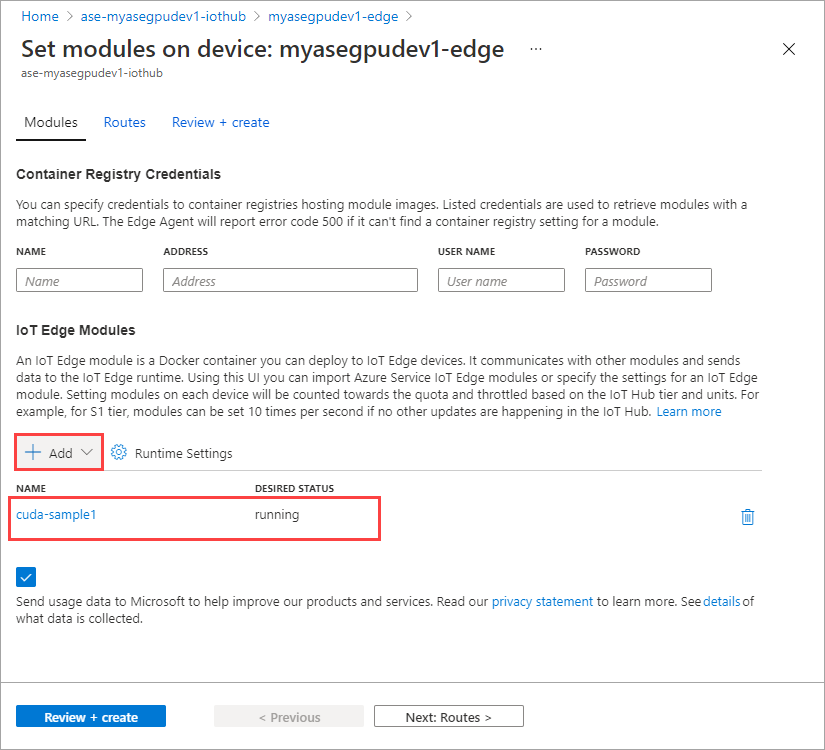
Repita todas as etapas para adicionar um módulo que você seguiu ao adicionar o primeiro módulo. Neste exemplo, forneça o nome do módulo como
cuda-sample2.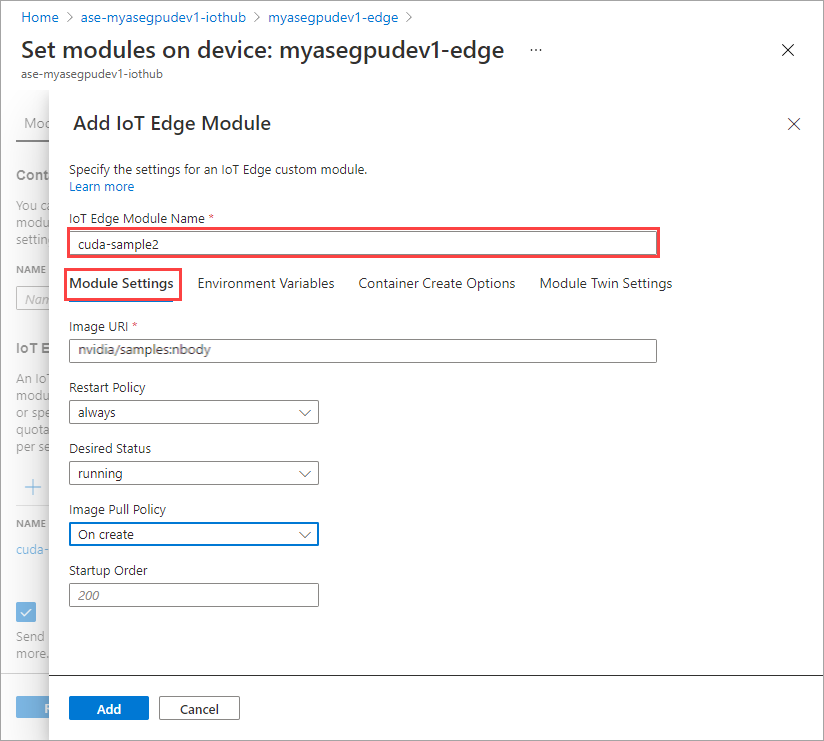
Use a mesma variável de ambiente, pois ambos os módulos compartilharão a mesma GPU.
Use as mesmas opções de criação de contêiner que você forneceu para o primeiro módulo e selecione Adicionar.
Na página Definir módulos, selecione Rever + Criar e, em seguida, selecione Criar.
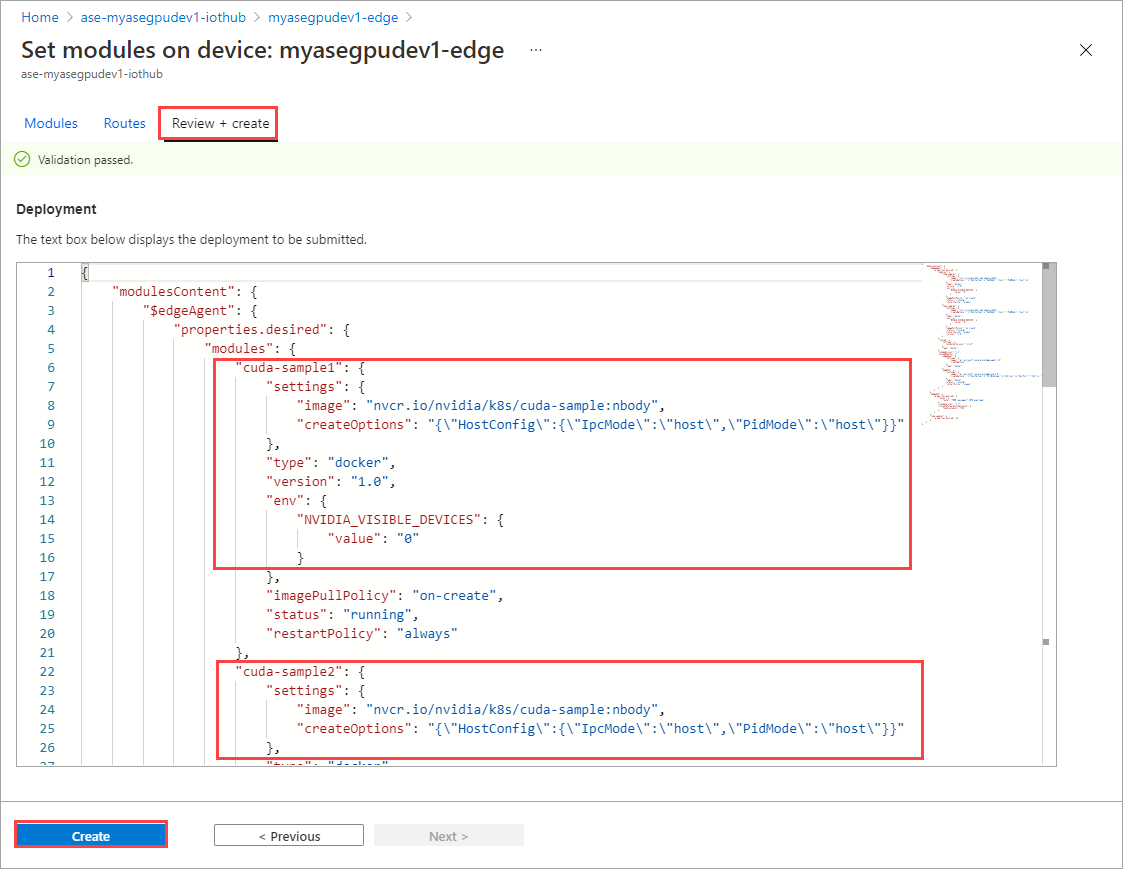
O status de tempo de execução de ambos os módulos agora deve ser mostrado como em execução.
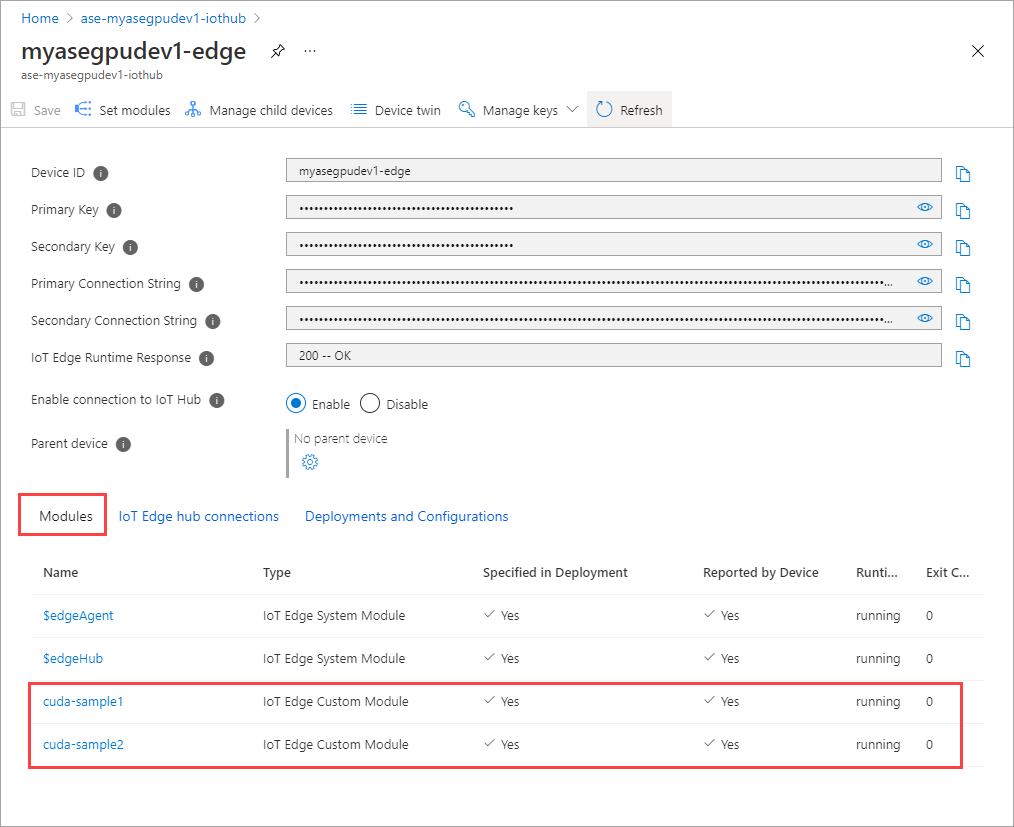
Monitorar a implantação da carga de trabalho
Abra uma nova sessão do PowerShell.
Liste os pods em execução no
iotedgenamespace. Execute o seguinte comando:kubectl get pods -n iotedgeAqui está um exemplo de saída:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-ssng8 2/2 Running 0 5s cuda-sample2-6db6d98689-d74kb 2/2 Running 0 4s edgeagent-79f988968b-7p2tv 2/2 Running 0 6d21h edgehub-d6c764847-l8v4m 2/2 Running 0 24h iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 6d21h PS C:\WINDOWS\system32>Existem dois pods
cuda-sample1-97c494d7f-lnmnsecuda-sample2-d9f6c4688-2rld9em execução no seu dispositivo.Enquanto ambos os contêineres estão executando a simulação de n corpos, veja a utilização da GPU a partir da saída smi da NVIDIA. Vá para a interface do PowerShell do dispositivo e execute
Get-HcsGpuNvidiaSmi.Aqui está um exemplo de saída quando ambos os contêineres estão executando a simulação de n corpos:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:31:16 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 52C P0 69W / 70W | 221MiB / 15109MiB | 100% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 188342 C /tmp/nbody 109MiB | | 0 N/A N/A 188413 C /tmp/nbody 109MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Como você pode ver, há dois contêineres rodando com simulação de n corpos na GPU 0. Você também pode visualizar o uso de memória correspondente.
Uma vez concluída a simulação, a saída smi NVIDIA mostrará que não há processos em execução no dispositivo.
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:54:48 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Após a conclusão da simulação de n corpos, visualize os logs para entender os detalhes da implantação e o tempo necessário para a conclusão da simulação.
Aqui está um exemplo de saída do primeiro contêiner:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample1-869989578c-ssng8 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170171.531 ms = 98.590 billion interactions per second = 1971.801 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Aqui está um exemplo de saída do segundo contêiner:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-d74kb cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170054.969 ms = 98.658 billion interactions per second = 1973.152 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Pare a implantação do módulo. No recurso do Hub IoT para o seu dispositivo:
Vá para Implantação Automática de Dispositivos > IoT Edge. Selecione o dispositivo IoT Edge correspondente ao seu dispositivo.
Vá para Definir módulos e selecione um módulo.
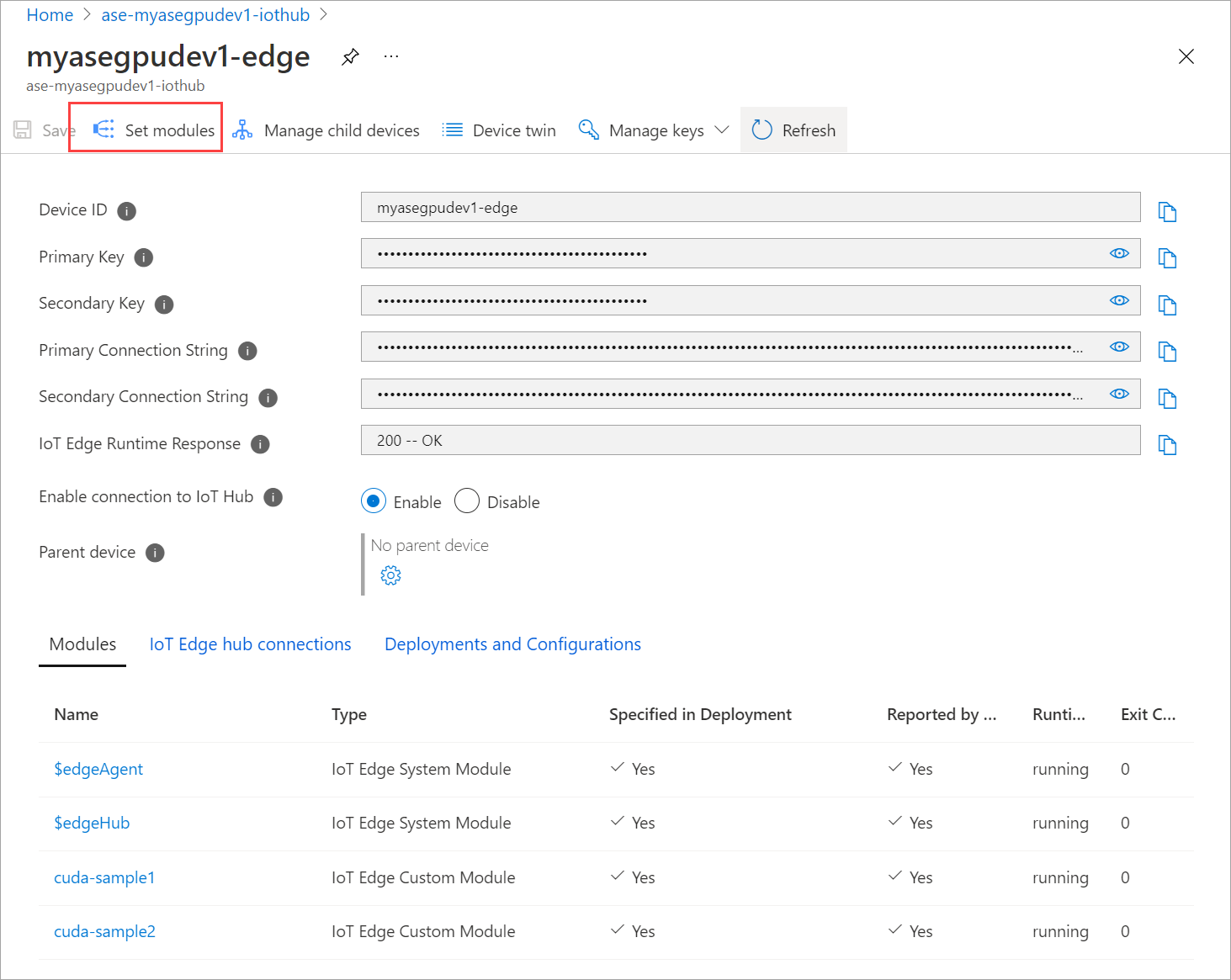
Na guia Módulos, selecione um módulo.
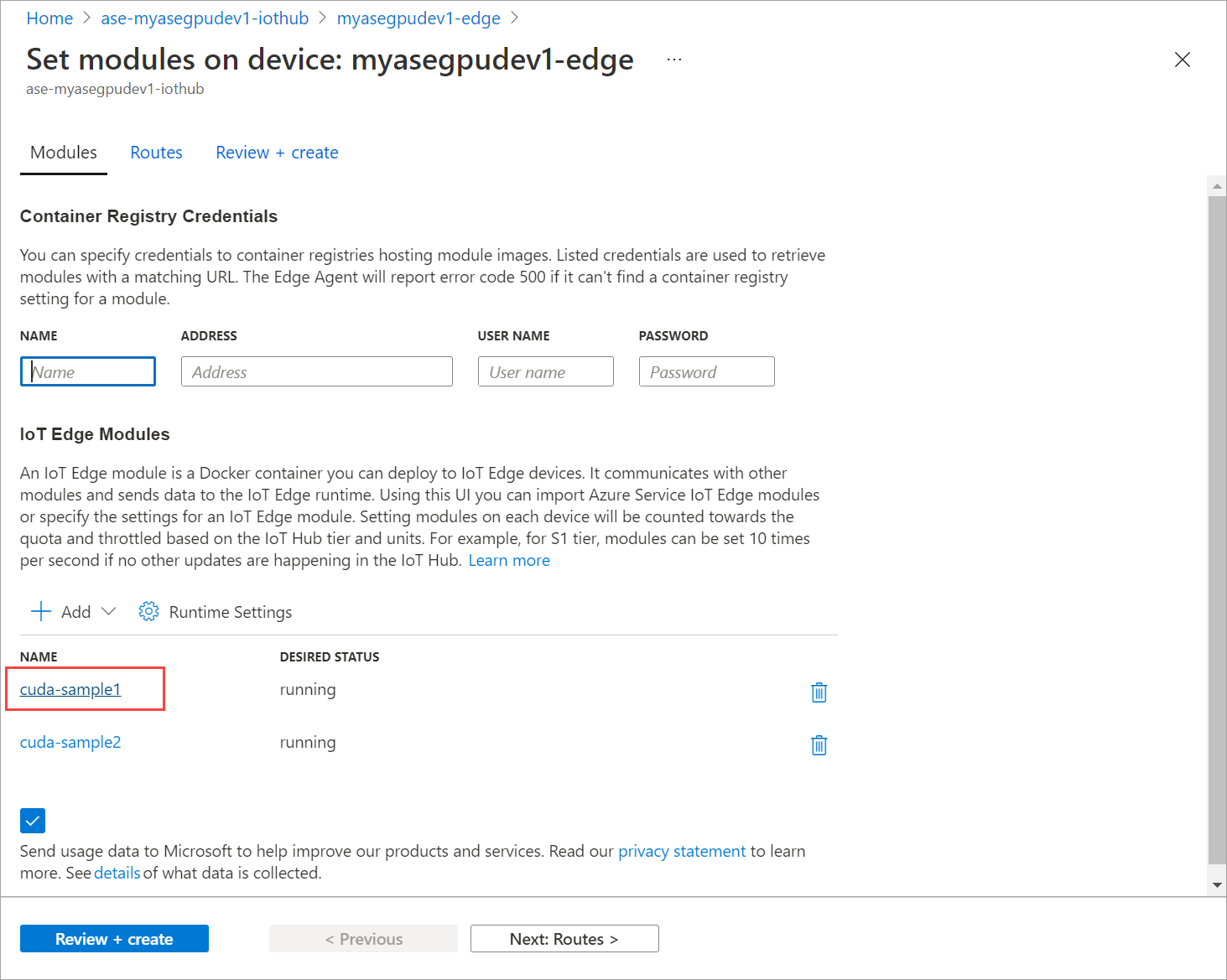
Na guia Configurações do módulo , defina Status desejado como interrompido. Selecione Atualizar.
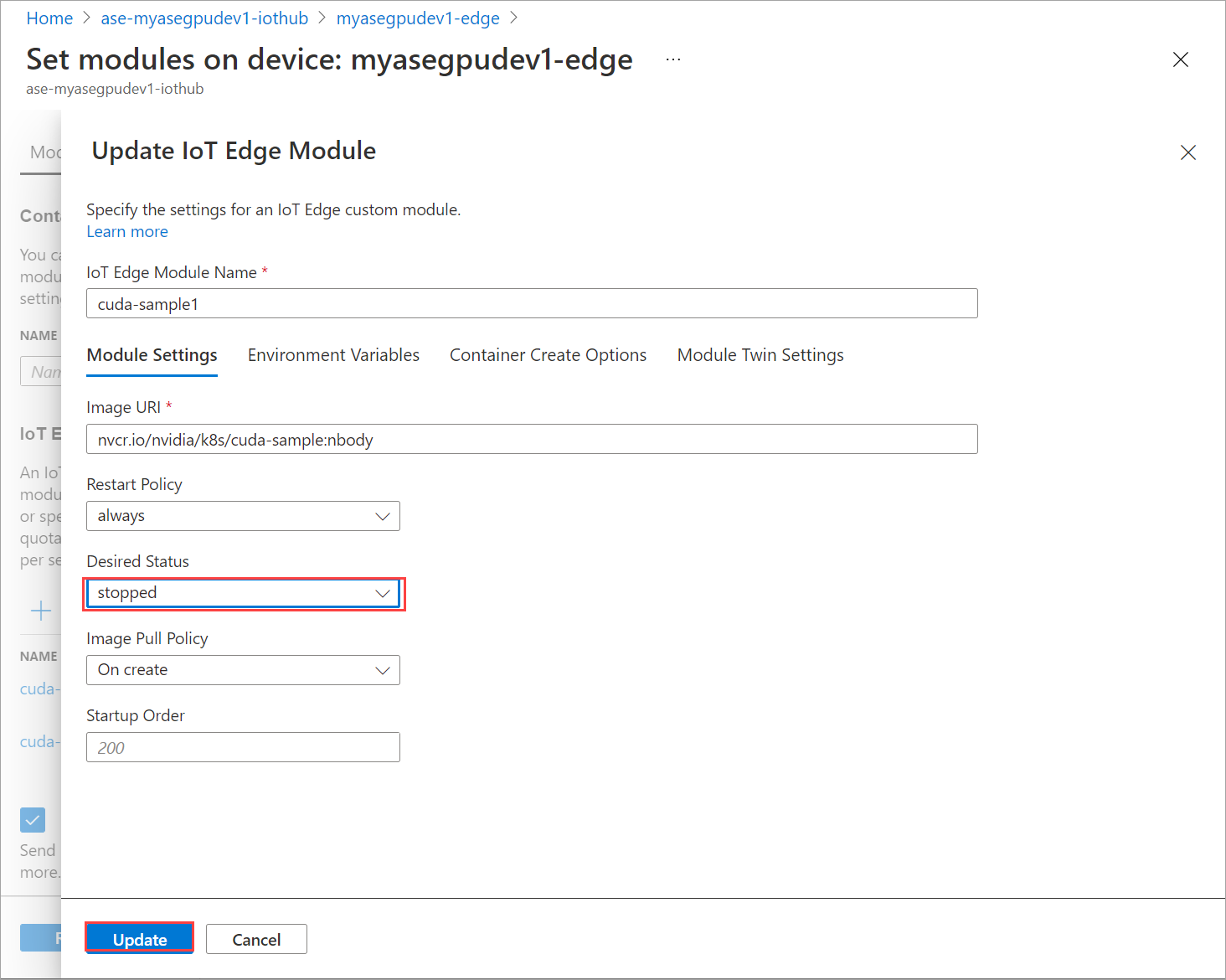
Repita as etapas para parar o segundo módulo implantado no dispositivo. Selecione Rever + criar e, em seguida, selecione Criar. Isso deve atualizar a implantação.
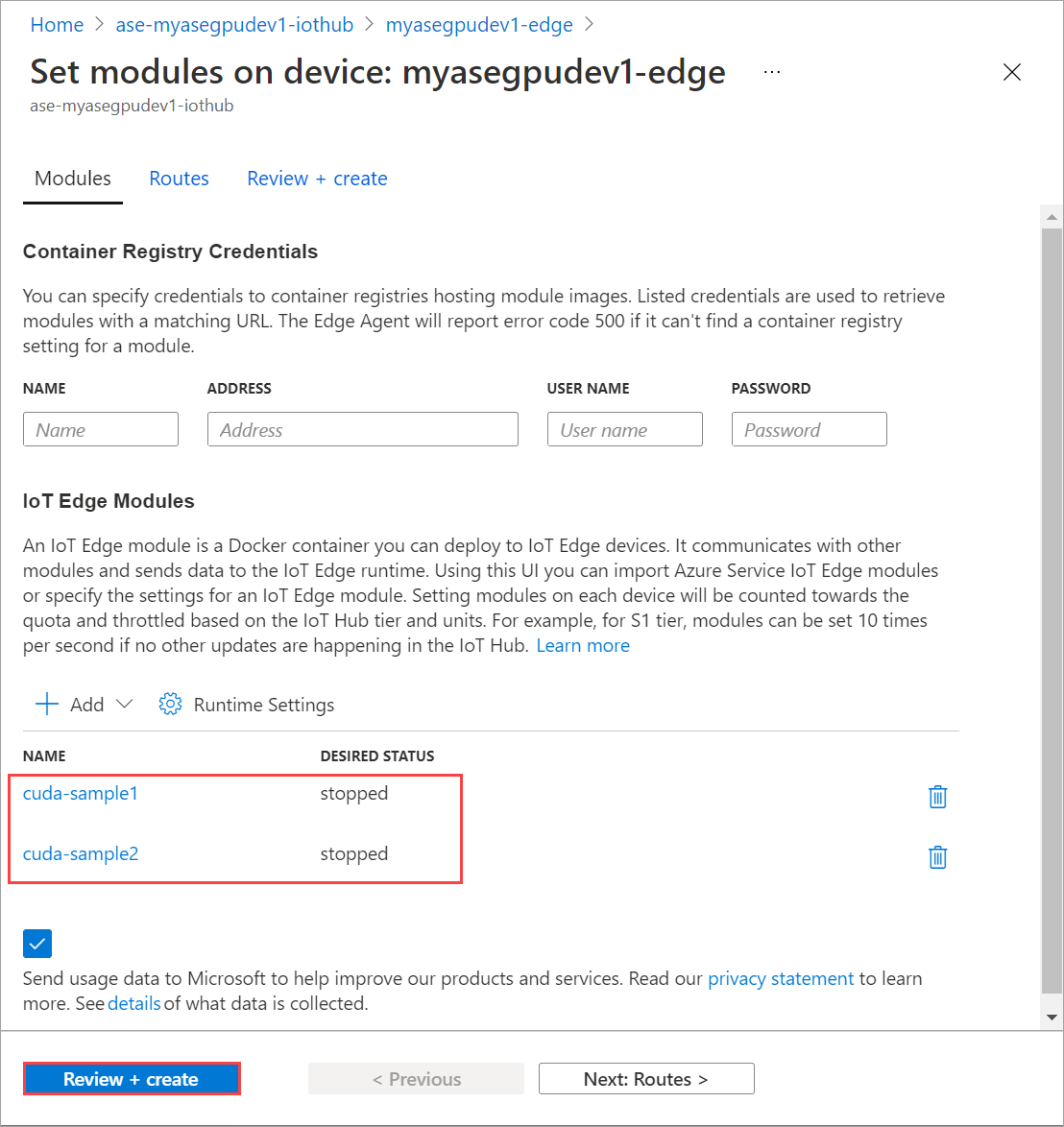
Atualizar página Definir módulos várias vezes. até que o status do módulo Runtime apareça como Parado.
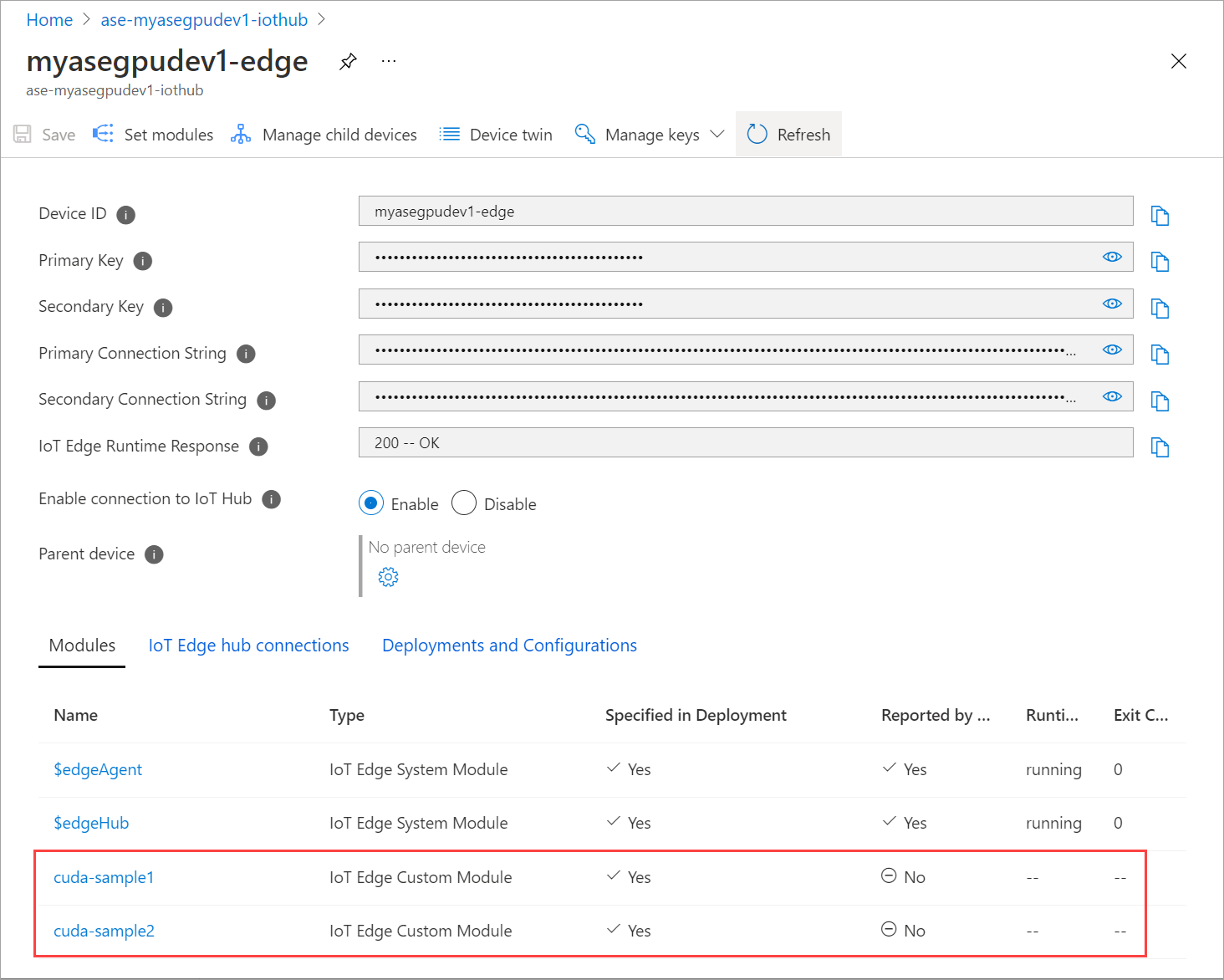
Implantar com compartilhamento de contexto
Agora você pode implantar a simulação de n corpos em dois contêineres CUDA quando o MPS estiver em execução no seu dispositivo. Primeiro, você ativará o MPS no dispositivo.
Para ativar o MPS no seu dispositivo, execute o
Start-HcsGpuMPScomando.[10.100.10.10]: PS>Start-HcsGpuMPS K8S-1HXQG13CL-1HXQG13: Set compute mode to EXCLUSIVE_PROCESS for GPU 0000191E:00:00.0. All done. Created nvidia-mps.service [10.100.10.10]: PS>Obtenha a saída NVIDIA smi da interface PowerShell do dispositivo. Você pode ver o
nvidia-cuda-mps-serverprocesso ou o serviço MPS está em execução no dispositivo.Aqui está um exemplo de saída:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:37:39 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 36C P8 9W / 70W | 28MiB / 15109MiB | 0% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmiImplante os módulos que você parou anteriormente. Defina o status desejado para ser executado através dos módulos set.
Aqui está o exemplo de saída:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-2zxh6 2/2 Running 0 44s cuda-sample2-6db6d98689-fn7mx 2/2 Running 0 44s edgeagent-79f988968b-7p2tv 2/2 Running 0 5d20h edgehub-d6c764847-l8v4m 2/2 Running 0 27m iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 5d20h PS C:\WINDOWS\system32>Você pode ver que os módulos estão implantados e em execução no seu dispositivo.
Quando os módulos são implantados, a simulação de n corpos também começa a ser executada em ambos os contêineres. Aqui está o exemplo de saída quando a simulação foi concluída no primeiro contêiner:
PS C:\WINDOWS\system32> kubectl -n iotedge logs cuda-sample1-869989578c-2zxh6 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155256.062 ms = 108.062 billion interactions per second = 2161.232 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Aqui está o exemplo de saída quando a simulação foi concluída no segundo contêiner:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-fn7mx cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155366.359 ms = 107.985 billion interactions per second = 2159.697 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Obtenha a saída smi NVIDIA da interface PowerShell do dispositivo quando ambos os contêineres estiverem executando a simulação de n corpos. Aqui está um exemplo de saída. Existem três processos, o
nvidia-cuda-mps-serverprocesso (tipo C) corresponde ao serviço MPS e os/tmp/nbodyprocessos (tipo M + C) correspondem às cargas de trabalho de n corpos implantadas pelos módulos.[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:59:44 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 54C P0 69W / 70W | 242MiB / 15109MiB | 100% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 56832 M+C /tmp/nbody 107MiB | | 0 N/A N/A 56900 M+C /tmp/nbody 107MiB | | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmi