Conector Data Explorer do Azure para Apache Spark
Importante
Este conector pode ser utilizado na Análise em Tempo Real no Microsoft Fabric. Utilize as instruções neste artigo com as seguintes exceções:
- Se necessário, crie bases de dados com as instruções em Criar uma base de dados KQL.
- Se necessário, crie tabelas com as instruções em Criar uma tabela vazia.
- Obtenha URIs de consulta ou ingestão com as instruções em Copiar URI.
- Execute consultas num conjunto de consultas KQL.
O Apache Spark é um motor de análise unificado para processamento de dados em larga escala. O Azure Data Explorer é um serviço de análise de dados rápido e totalmente gerido que permite realizar análises em tempo real em grandes volumes de dados.
O conector do Azure Data Explorer para o Spark é um projeto open source que pode ser executado em qualquer cluster do Spark. Implementa a origem de dados e o sink de dados para mover dados em clusters do Azure Data Explorer e do Spark. Com o Azure Data Explorer e o Apache Spark, pode criar aplicações rápidas e dimensionáveis direcionadas para cenários orientados por dados. Por exemplo, machine learning (ML), Extract-Transform-Load (ETL) e Log Analytics. Com o conector, o Azure Data Explorer torna-se um arquivo de dados válido para operações padrão de origem e sink do Spark, como escrita, leitura e writeStream.
Pode escrever no Azure Data Explorer através da ingestão em fila ou da ingestão de transmissão em fluxo. A leitura do Azure Data Explorer suporta a eliminação de colunas e o pushdown predicado, que filtra os dados no Azure Data Explorer, reduzindo o volume de dados transferidos.
Nota
Para obter informações sobre como trabalhar com o conector do Synapse Spark para o Azure Data Explorer, consulte Ligar ao Azure Data Explorer com o Apache Spark para Azure Synapse Analytics.
Este tópico descreve como instalar e configurar o conector do Azure Data Explorer Spark e mover dados entre clusters do Azure Data Explorer e do Apache Spark.
Nota
Embora alguns dos exemplos abaixo se refira a um cluster do Azure Databricks Spark, o conector do Azure Data Explorer Spark não assume dependências diretas no Databricks ou em qualquer outra distribuição do Spark.
Pré-requisitos
- Uma subscrição do Azure. Crie uma conta gratuita do Azure.
- Um cluster e uma base de dados do Azure Data Explorer. Criar um cluster e uma base de dados.
- Um cluster do Spark
- Instalar a biblioteca de conectores do Azure Data Explorer:
- Bibliotecas pré-criadas para o Spark 2.4+Scala 2.11 ou Spark 3+scala 2.12
- Repositório maven
- Maven 3.x instalado
Dica
As versões do Spark 2.3.x também são suportadas, mas podem exigir algumas alterações nas dependências pom.xml.
Como criar o conector spark
A partir da versão 2.3.0, introduzimos novos IDs de artefactos que substituem spark-kusto-connector: kusto-spark_3.0_2.12 destinados ao Spark 3.x e Scala 2.12 e kusto-spark_2.4_2.11 destinados ao Spark 2.4.x e scala 2.11.
Nota
As versões anteriores à versão 2.5.1 já não funcionam para ingerir numa tabela existente. Atualize para uma versão posterior. Este passo é opcional. Se estiver a utilizar bibliotecas pré-criadas, por exemplo, o Maven, veja Configuração do cluster do Spark.
Criar pré-requisitos
Se não estiver a utilizar bibliotecas pré-criadas, terá de instalar as bibliotecas listadas em dependências , incluindo as seguintes bibliotecas do SDK Java kusto . Para encontrar a versão certa para instalar, procure o pom da versão relevante:
Veja esta origem para criar o Conector spark.
Para aplicações Scala/Java com definições de projeto do Maven, ligue a sua aplicação ao seguinte artefacto (a versão mais recente pode ser diferente):
<dependency> <groupId>com.microsoft.azure</groupId> <artifactId>kusto-spark_3.0_2.12</artifactId> <version>2.5.1</version> </dependency>
Criar comandos
Para criar o jar e executar todos os testes:
mvn clean package
Para criar o jar, execute todos os testes e instale o jar no repositório maven local:
mvn clean install
Para obter mais informações, veja Utilização do conector.
Configuração do cluster do Spark
Nota
Recomenda-se que utilize a versão mais recente do conector do Azure Data Explorer Spark ao executar os seguintes passos.
Configure as seguintes definições de cluster do Spark, com base no cluster do Azure Databricks com o Spark 2.4.4 e o Scala 2.11 ou Spark 3.0.1 e Scala 2.12:
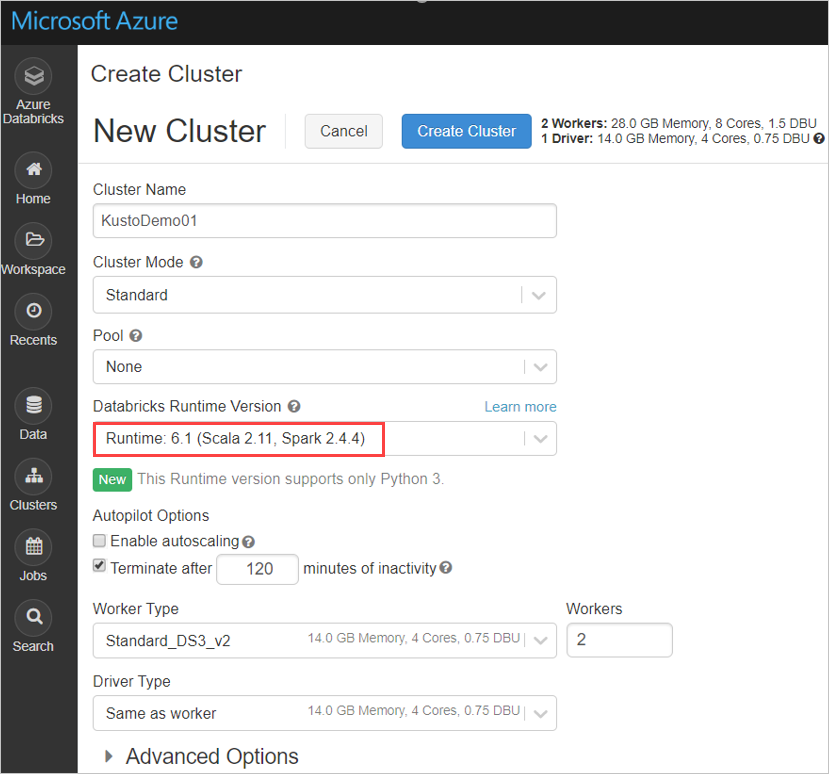
Instale a biblioteca spark-kusto-connector mais recente a partir do Maven:
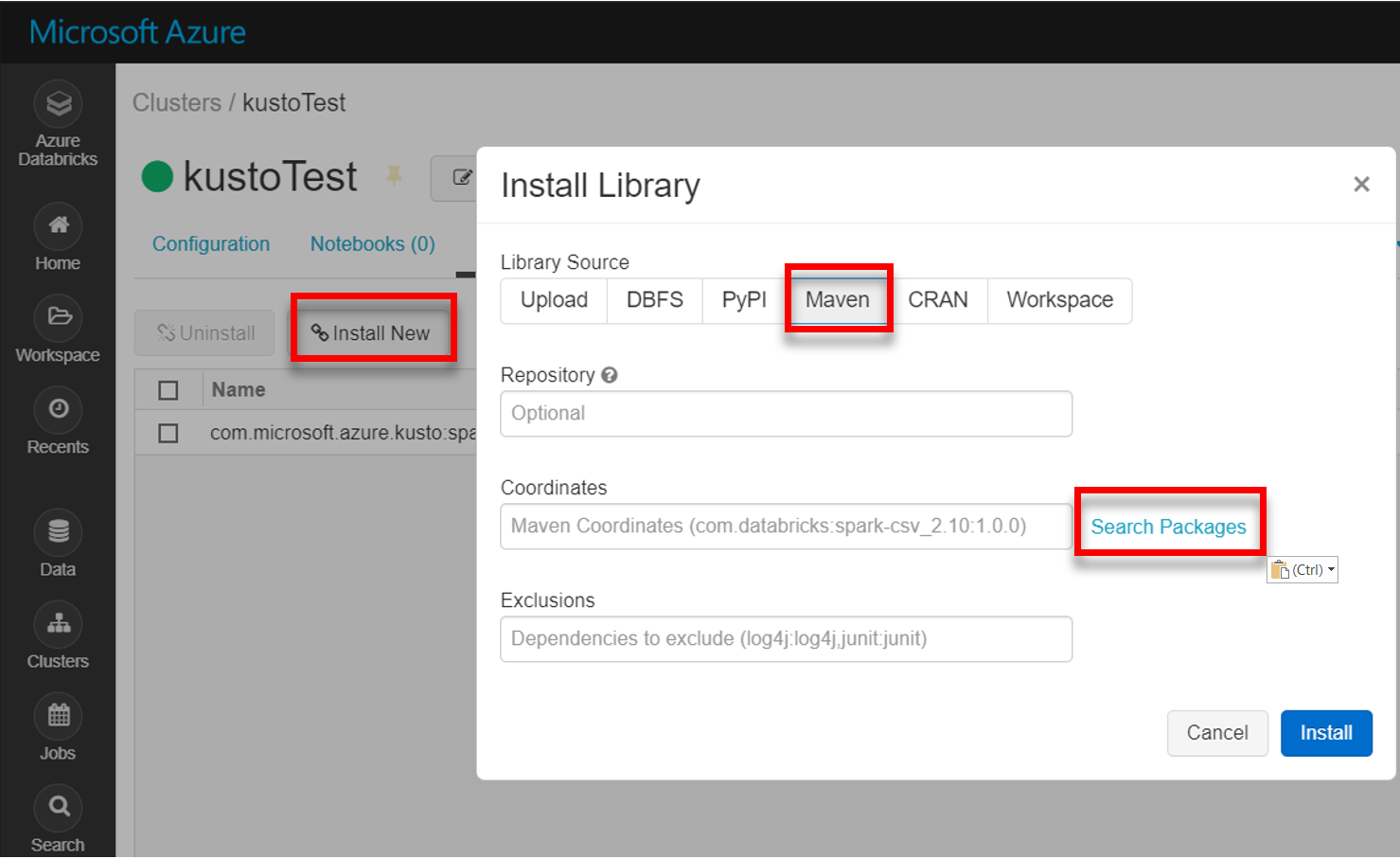
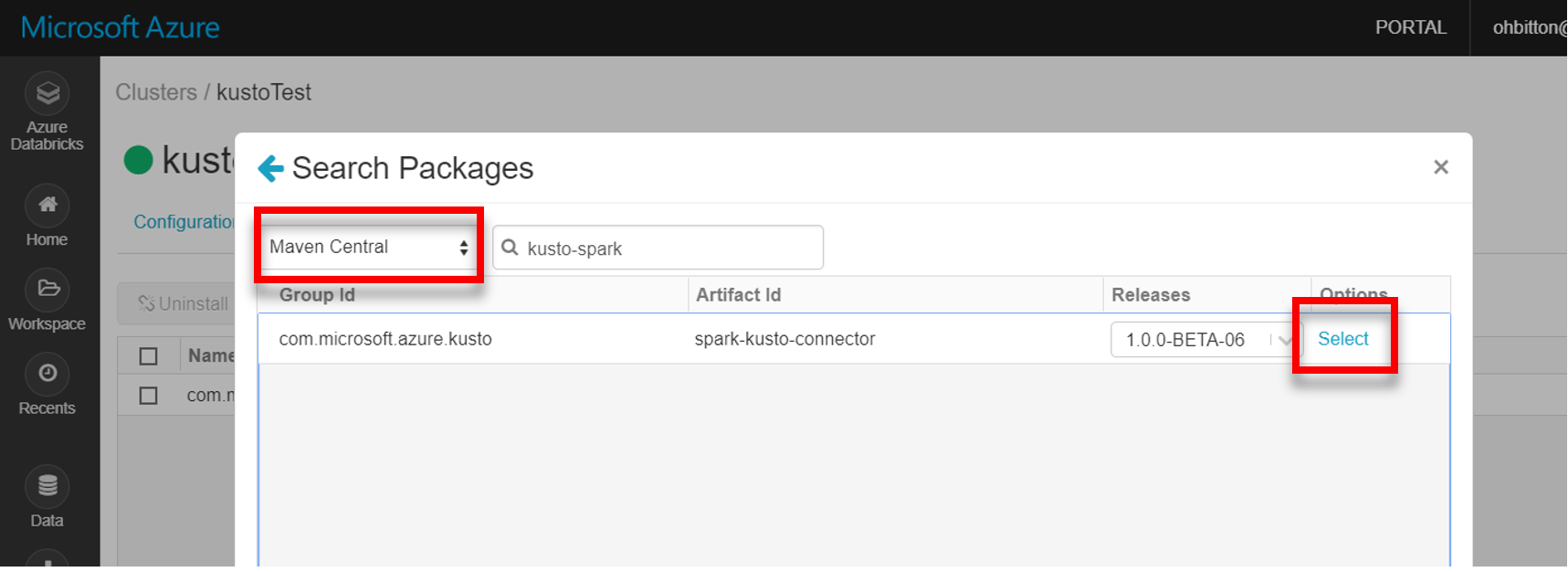
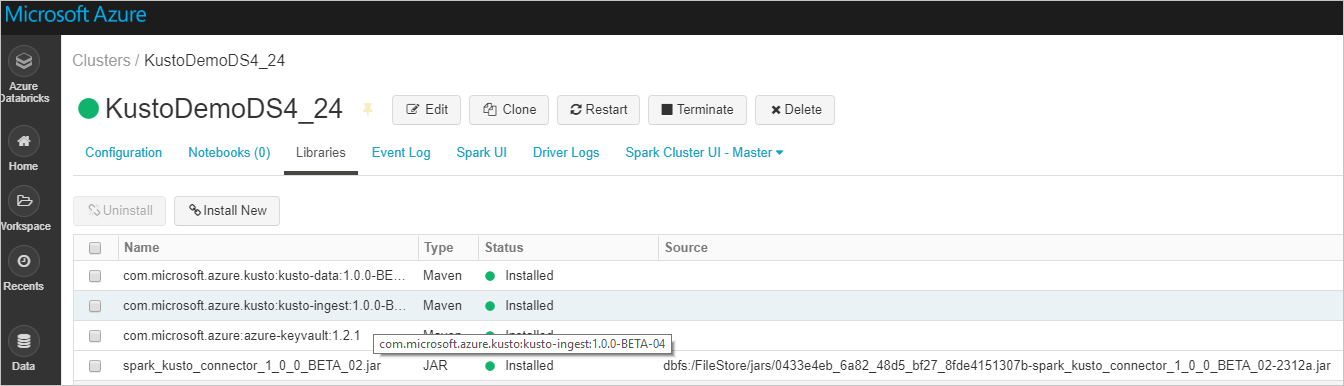
Verifique se todas as bibliotecas necessárias estão instaladas:
Para instalação com um ficheiro JAR, verifique se foram instaladas dependências adicionais:
Autenticação
O conector do Azure Data Explorer Spark permite-lhe autenticar com Microsoft Entra ID com um dos seguintes métodos:
- Uma aplicação Microsoft Entra
- Um token de acesso Microsoft Entra
- Autenticação de dispositivos (para cenários de não produção)
- Um Key Vault do Azure Para aceder ao recurso Key Vault, instale o pacote azure-keyvault e forneça credenciais de aplicação.
autenticação de aplicações Microsoft Entra
Microsoft Entra autenticação de aplicações é o método de autenticação mais simples e comum e é recomendado para o conector do Azure Data Explorer Spark.
| Propriedades | Cadeia de Opções | Description |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Microsoft Entra identificador da aplicação (cliente). |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Microsoft Entra autoridade de autenticação. Microsoft Entra ID do Diretório (inquilino). Opcional – predefinição para microsoft.com. Para obter mais informações, veja Microsoft Entra autoridade. |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | Microsoft Entra chave da aplicação para o cliente. |
Nota
As versões da API mais antigas (menos de 2.0.0) têm a seguinte nomenclatura: "kustoAADClientID", "kustoClientAADClientPassword", "kustoAADAuthorityID"
Privilégios de Data Explorer do Azure
Conceda os seguintes privilégios num cluster do Azure Data Explorer:
- Para leitura (origem de dados), a identidade Microsoft Entra tem de ter privilégios de visualizador na base de dados de destino ou privilégios de administrador na tabela de destino.
- Para escrever (sink de dados), a identidade Microsoft Entra tem de ter privilégios de ingestor na base de dados de destino. Também tem de ter privilégios de utilizador na base de dados de destino para criar novas tabelas. Se a tabela de destino já existir, tem de configurar privilégios de administrador na tabela de destino.
Para obter mais informações sobre as funções principais do Azure Data Explorer, veja Controlo de acesso baseado em funções. Para gerir funções de segurança, veja Gestão de funções de segurança.
Sink do Spark: escrever no Azure Data Explorer
Configurar parâmetros de sink:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Escreva DataFrame do Spark no cluster do Azure Data Explorer como lote:
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()Em alternativa, utilize a sintaxe simplificada:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)Escrever dados de transmissão em fluxo:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Origem do Spark: leitura a partir do Azure Data Explorer
Ao ler pequenas quantidades de dados, defina a consulta de dados:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)Opcional: se fornecer o armazenamento transitório de blobs (e não o Azure Data Explorer), os blobs são criados sob a responsabilidade do autor da chamada. Isto inclui o aprovisionamento do armazenamento, a rotação de chaves de acesso e a eliminação de artefactos transitórios. O módulo KustoBlobStorageUtils contém funções auxiliares para eliminar blobs com base em coordenadas de conta e contentor e credenciais de conta ou num URL de SAS completo com permissões de escrita, leitura e lista. Quando o RDD correspondente já não for necessário, cada transação armazena artefactos de blobs transitórios num diretório separado. Este diretório é capturado como parte de registos de informações de transação de leitura comunicados no nó Do Controlador do Spark.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")No exemplo acima, o Key Vault não é acedido através da interface do conector; é utilizado um método mais simples de utilização dos segredos do Databricks.
Leia a partir do Azure Data Explorer.
Se fornecer o armazenamento de blobs transitório, leia a partir do Azure Data Explorer da seguinte forma:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Se o Azure Data Explorer fornecer o armazenamento transitório de blobs, leia a partir do Azure Data Explorer da seguinte forma:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)