Descrição geral da continuidade de negócio e recuperação após desastre
A continuidade de negócio e a recuperação após desastre no Azure Data Explorer permitem que a sua empresa continue a operar perante uma interrupção. Este artigo aborda a disponibilidade (intra-região) e a recuperação após desastre. Detalha as capacidades nativas e as considerações de arquitetura para uma implementação resiliente do Azure Data Explorer. Detalha a recuperação de erros humanos, elevada disponibilidade, seguida de várias configurações de recuperação após desastre. Estas configurações dependem de requisitos de resiliência, como Objetivo de Ponto de Recuperação (RPO) e Objetivo de Tempo de Recuperação (RTO), esforço e custo necessários.
Mitigar eventos disruptivos
- Erro humano
- Elevada disponibilidade do Azure Data Explorer
- Indisponibilidade de uma zona de disponibilidade do Azure
- Indisponibilidade de um datacenter do Azure
- Indisponibilidade de uma região do Azure
Erro humano
Os erros humanos são inevitáveis. Os utilizadores podem remover acidentalmente um cluster, uma base de dados ou uma tabela.
Eliminação acidental do cluster ou da base de dados
A eliminação acidental de clusters ou bases de dados é uma ação irrecuperável. Enquanto proprietário do recurso do Azure Data Explorer, pode evitar a perda de dados ao ativar a capacidade de bloqueio de eliminação, disponível ao nível do recurso do Azure.
Eliminação acidental da tabela
Os utilizadores com permissões de administrador de tabelas ou superiores podem remover tabelas. Se um desses utilizadores deixar cair acidentalmente uma tabela, pode recuperá-la com o .undo drop table comando . Para que este comando seja bem-sucedido, primeiro tem de ativar a propriedade de recuperação na política de retenção.
Eliminação acidental de tabela externa
As tabelas externas são entidades de esquema de consulta Kusto que referenciam dados armazenados fora da base de dados. A eliminação de uma tabela externa elimina apenas os metadados da tabela. Pode recuperá-lo ao executar novamente o comando de criação da tabela. Utilize a capacidade de eliminação recuperável para proteger contra eliminação acidental ou substituição de um ficheiro/blob durante um período de tempo configurado pelo utilizador.
Elevada disponibilidade do Azure Data Explorer
A elevada disponibilidade refere-se à tolerância a falhas do Azure Data Explorer, aos respetivos componentes e às dependências subjacentes numa região do Azure. Esta tolerância a falhas evita pontos únicos de falha (SPOF) na implementação. No Azure Data Explorer, a elevada disponibilidade inclui a camada de persistência, a camada de computação e uma configuração de seguimento de líder.
Camada de persistência
O Azure Data Explorer tira partido do Armazenamento do Azure como camada de persistência durável. O Armazenamento do Azure fornece automaticamente tolerância a falhas, com a predefinição que oferece Armazenamento Localmente Redundante (LRS) num datacenter. Três réplicas são persistentes. Se uma réplica for perdida durante a utilização, outra é implementada sem interrupções. É possível obter mais resiliência com o Armazenamento Com Redundância entre Zonas (ZRS) que coloca as réplicas de forma inteligente nas zonas de disponibilidade regional do Azure para tolerância a falhas máxima a um custo adicional. O armazenamento preparado para ZRS é configurado automaticamente quando o cluster do Data Explorer do Azure é implementado no Zonas de Disponibilidade.
Camada de computação
O Azure Data Explorer é uma plataforma de computação distribuída e pode ter dois a muitos nós, dependendo do tipo de função de dimensionamento e nó. No momento do aprovisionamento, selecione zonas de disponibilidade para distribuir a implementação do nó, entre zonas para uma resiliência máxima intra-região. Uma falha na zona de disponibilidade não resultará numa indisponibilidade completa, mas sim na degradação do desempenho até à recuperação da zona.
Configuração do cluster de seguimento de coordenadores
O Azure Data Explorer fornece uma capacidade de seguimento opcional para que um cluster de coordenador seja seguido por outros clusters de seguidores para acesso só de leitura aos dados e metadados do líder. As alterações no coordenador, como create, appende drop são sincronizadas automaticamente com o seguidor. Embora os líderes possam abranger as regiões do Azure, os clusters de seguidores devem ser alojados nas mesmas regiões que o coordenador. Se o cluster de classificação estiver inativo ou as bases de dados ou tabelas forem acidentalmente removidas, os clusters de seguidores perderão o acesso até que o acesso seja recuperado no coordenador.
Indisponibilidade de uma zona de disponibilidade do Azure
As zonas de disponibilidade do Azure são localizações físicas exclusivas na mesma região do Azure. Podem proteger a computação e os dados de um cluster do Azure Data Explorer contra falhas parciais na região. A falha de zona é um cenário de disponibilidade, uma vez que é intra-região.
Afixe um cluster de Data Explorer do Azure à mesma zona que outros recursos do Azure ligados. Para obter mais informações sobre como ativar zonas de disponibilidade, veja Criar um cluster.
Nota
A implementação em zonas de disponibilidade é possível ao criar um cluster ou pode ser migrada mais tarde.
Indisponibilidade de um datacenter do Azure
As zonas de disponibilidade do Azure têm um custo e alguns clientes optam por implementar sem redundância zonal. Com uma implementação do Azure Data Explorer, uma falha do datacenter do Azure resultará numa indisponibilidade do cluster. O processamento de uma indisponibilidade do datacenter do Azure é, portanto, idêntico ao de uma indisponibilidade da região do Azure.
Indisponibilidade de uma região do Azure
O Azure Data Explorer não fornece proteção automática contra a indisponibilidade de toda uma região do Azure. Para minimizar o impacto comercial se ocorrer uma falha deste tipo, vários clusters do Azure Data Explorer em regiões emparelhadas do Azure. Com base no objetivo de tempo de recuperação (RTO), no objetivo de ponto de recuperação (RPO), bem como nas considerações de esforço e custo, existem várias configurações de recuperação após desastre. As otimizações de custos e desempenho são possíveis com as recomendações do Assistente do Azure e a configuração do dimensionamento automático .
Configurações de recuperação após desastre
Esta secção detalha várias configurações de recuperação após desastre consoante os requisitos de resiliência (RPO e RTO), o esforço necessário e o custo.
O objetivo de tempo de recuperação (RTO) refere-se ao tempo para recuperar de uma interrupção. Por exemplo, RTO de 2 horas significa que a aplicação tem de estar operacional no prazo de duas horas após uma interrupção. O objetivo de ponto de recuperação (RPO) refere-se ao intervalo de tempo que pode passar durante uma interrupção antes de a quantidade de dados perdidos durante esse período ser superior ao limiar permitido. Por exemplo, se o RPO for de 24 horas e uma aplicação tiver dados que começam há 15 anos, ainda estão dentro dos parâmetros do RPO acordado.
Os processos de ingestão, processamento e curadoria precisam de um design diligente antecipadamente ao planear a recuperação após desastre. A ingestão refere-se a dados integrados no Azure Data Explorer de várias origens; o processamento refere-se a transformações e atividades semelhantes; a curadoria refere-se a vistas materializadas, exportações para o data lake, etc.
Seguem-se configurações populares de recuperação após desastre e cada uma delas é descrita em detalhe abaixo.
- Configuração Active-Active-Active (always-on)
- Configuração Active-Active
- Configuração de reserva Active-Hot
- Configuração do cluster de recuperação de dados a pedido
Configuração ativa-ativa-ativa
Esta configuração também é denominada "always-on". Para implementações de aplicações críticas sem tolerância a interrupções, deve utilizar vários clusters de Data Explorer do Azure em regiões emparelhadas do Azure. Configure a ingestão, o processamento e a curadoria em paralelo para todos os clusters. O SKU do cluster tem de ser o mesmo entre regiões. O Azure irá garantir que as atualizações são implementadas e escalonadas entre regiões emparelhadas do Azure. Uma falha na região do Azure não causará uma indisponibilidade da aplicação. Poderá deparar-se com alguma latência ou degradação do desempenho.
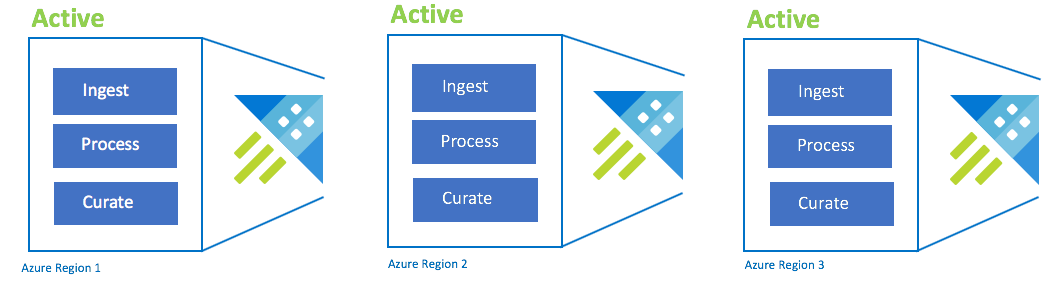
| Configuração | RPO | RTO | Esforço | Custo |
|---|---|---|---|---|
| Active-Active-Active-n | 0 horas | 0 horas | Mais baixo | Mais alto |
configuração do Active-Active
Esta configuração é idêntica à configuração active-active-active-active, mas envolve apenas duas regiões emparelhadas do Azure. Configure a ingestão dupla, o processamento e a curadoria. Os utilizadores são encaminhados para a região mais próxima. O SKU do cluster tem de ser o mesmo entre regiões.
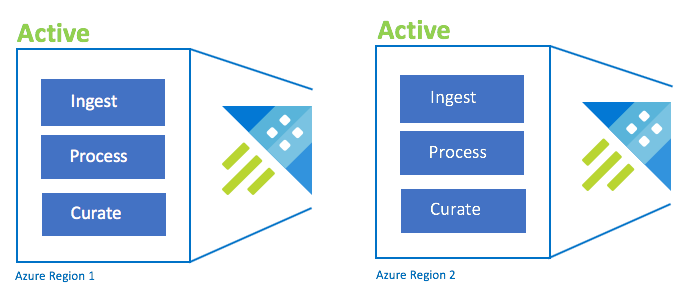
| Configuração | RPO | RTO | Esforço | Custo |
|---|---|---|---|---|
| Ativa-ativa | 0 horas | 0 horas | Mais baixo | Alto |
Active-Hot configuração de reserva
A configuração Active-Hot é semelhante à configuração Active-Active na ingestão , processamento e curação duplas. Embora o cluster de reserva esteja online para ingestão, processo e curadoria, não está disponível para consulta. O cluster de reserva não precisa de estar no mesmo SKU que o cluster primário. Pode ser de um SKU e dimensionamento mais pequenos, o que pode fazer com que seja menos eficaz. Num cenário de desastre, os utilizadores são redirecionados para o cluster de reserva, que opcionalmente pode ser aumentado verticalmente para aumentar o desempenho.
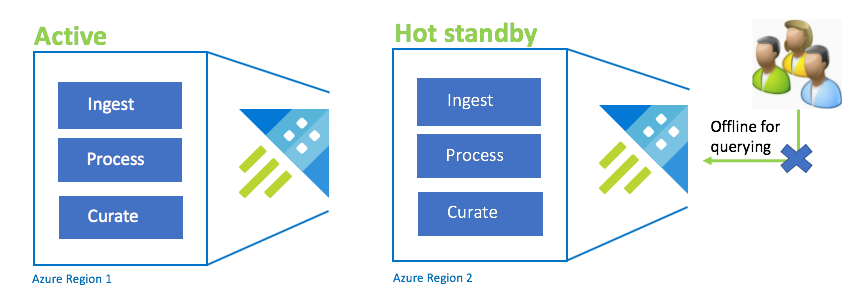
| Configuração | RPO | RTO | Esforço | Custo |
|---|---|---|---|---|
| Modo de Espera Ativo-Frequente | 0 horas | Baixo | Médio | Médio |
Configuração da recuperação de dados a pedido
Esta solução oferece a menor resiliência (RPO e RTO mais elevados), é a mais baixa em termos de custo e mais elevada em esforço. Nesta configuração, não existe nenhum cluster de recuperação de dados. Configure a exportação contínua de dados organizados (a menos que também sejam necessários dados não processados e intermédios) para uma conta de armazenamento que esteja configurada como GRS (Armazenamento Georredundante). Um cluster de recuperação de dados é configurado se existir um cenário de recuperação após desastre. Nessa altura, são aplicados DDLs, configuração, políticas e processos. Os dados são ingeridos a partir do armazenamento com a propriedade de ingestão kustoCreationTime para ultrapassar o tempo de ingestão predefinido para o tempo do sistema.
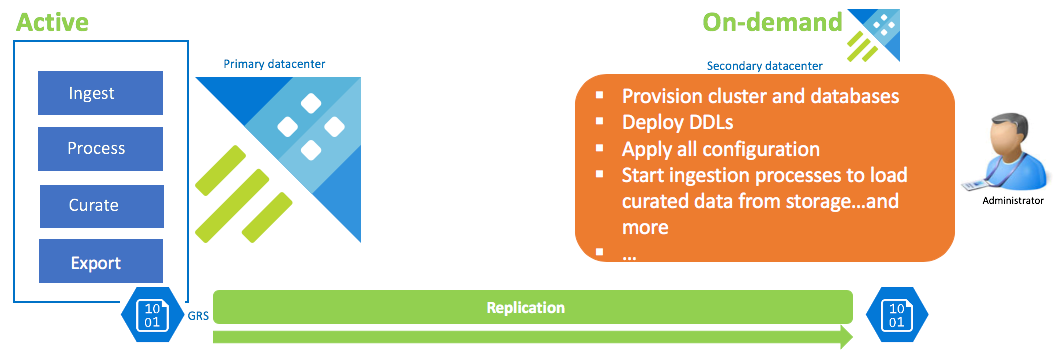
| Configuração | RPO | RTO | Esforço | Custo |
|---|---|---|---|---|
| Cluster de recuperação de dados a pedido | Mais alto | Mais alto | Mais alto | Menor |
Resumo das opções de configuração da recuperação após desastre
| Configuração | Resiliência | RPO | RTO | Esforço | Custo |
|---|---|---|---|---|---|
| Active-Active-Active-n | Mais alto | 0 horas | 0 horas | Mais baixo | Mais alto |
| Ativa-ativa | Alto | 0 horas | 0 horas | Mais baixo | Alto |
| Modo de Espera Ativo-Frequente | Médio | 0 horas | Baixo | Médio | Médio |
| Cluster de recuperação de dados a pedido | Menor | Mais alto | Mais alto | Mais alto | Menor |
Melhores práticas
Independentemente da configuração de recuperação após desastre escolhida, siga estas melhores práticas:
- Todos os objetos, políticas e configurações da base de dados devem ser mantidos no controlo de origem para que possam ser libertados para o cluster a partir da sua ferramenta de automatização de versões. Para obter mais informações, veja Suporte do Azure DevOps para o Azure Data Explorer.
- Crie, desenvolva e implemente rotinas de validação para garantir que todos os clusters estão sincronizados de uma perspetiva de dados. O Azure Data Explorer suporta associações entre clusters. Uma contagem simples ou linhas entre tabelas pode ajudar a validar.
- Os procedimentos de versão devem envolver verificações de governação e saldos que garantam o espelhamento dos clusters.
- Esteja totalmente consciente do que é preciso para criar um cluster do zero.
- Crie uma lista de verificação de unidades de implementação. A sua lista será exclusiva às suas necessidades, mas deve incluir: scripts de implementação, ligações de ingestão, ferramentas de BI e outras configurações importantes.