Modele aplicativos SaaS multilocatários no Azure Cosmos DB para PostgreSQL
APLICA-SE A: ![]() Azure Cosmos DB para PostgreSQL (alimentado pela extensão de banco de dados Citus para PostgreSQL)
Azure Cosmos DB para PostgreSQL (alimentado pela extensão de banco de dados Citus para PostgreSQL)
ID do locatário como a chave de estilhaço
O ID do locatário é a coluna na raiz da carga de trabalho ou a parte superior da hierarquia em seu modelo de dados. Por exemplo, neste esquema de comércio eletrônico SaaS, seria o ID da loja:
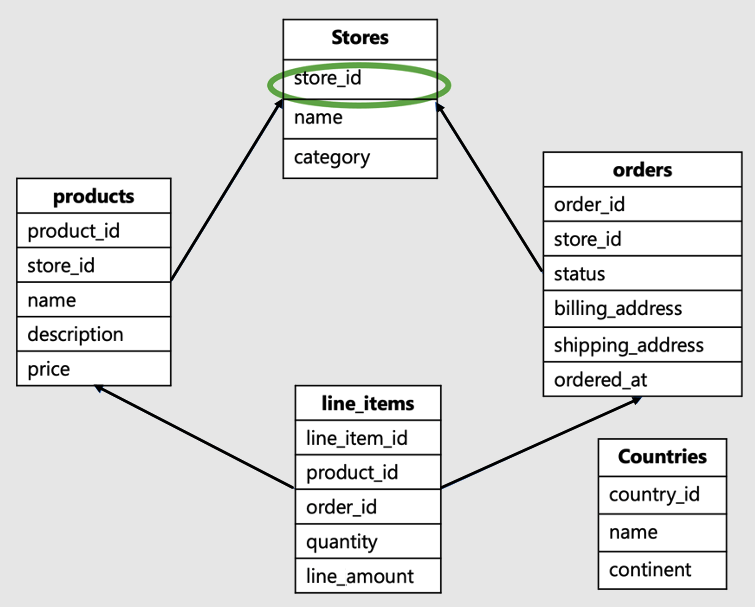
Esse modelo de dados seria típico de uma empresa como a Shopify. Ele hospeda sites para várias lojas online, onde cada loja interage com seus próprios dados.
- Este modelo de dados tem um monte de tabelas: lojas, produtos, pedidos, itens de linha e países.
- A tabela de lojas está no topo da hierarquia. Produtos, pedidos e itens de linha estão todos associados às lojas, portanto, mais abaixo na hierarquia.
- A tabela de países não está relacionada a lojas individuais, está entre todas as lojas.
Neste exemplo, store_id, que está no topo da hierarquia, é o identificador do locatário. É a chave de estilhaço certa. A seleção store_id como a chave de estilhaço permite a colocação de dados em todas as tabelas para um único armazenamento em um único trabalhador.
A colocação de mesas por loja tem vantagens:
- Fornece cobertura SQL, como chaves estrangeiras, JOINs. As transações para um único locatário são localizadas em um único nó de trabalho onde cada locatário existe.
- Alcança um desempenho de milissegundos de um dígito. As consultas para um único locatário são roteadas para um único nó em vez de serem paralelizadas, o que ajuda a otimizar os saltos de rede e ainda dimensionar computação/memória.
- Ele escala. À medida que o número de locatários cresce, você pode adicionar nós e reequilibrar os locatários para novos nós ou até mesmo isolar grandes locatários para seus próprios nós. O isolamento do locatário permite que você forneça recursos dedicados.
Modelo de dados ideal para aplicativos multilocatários
Neste exemplo, devemos distribuir as tabelas específicas da loja por ID da loja e criar countries uma tabela de referência.
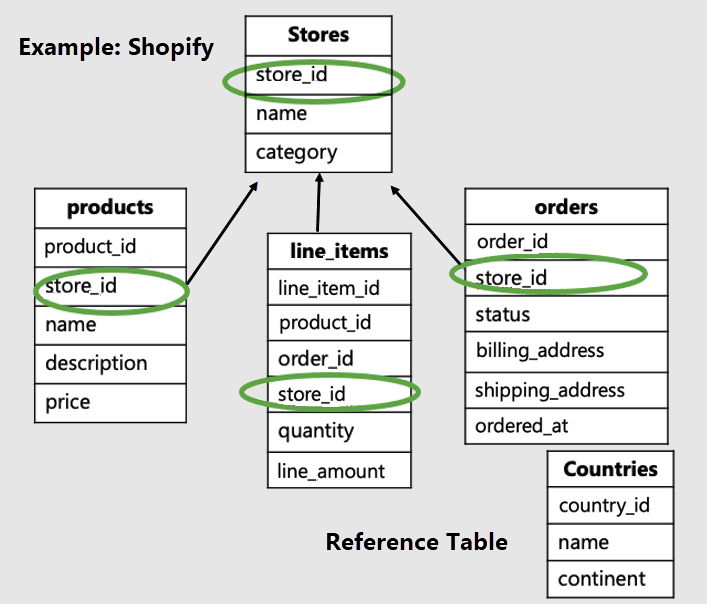
Observe que as tabelas específicas do locatário têm a ID do locatário e são distribuídas. No nosso exemplo, são distribuídas lojas, produtos e line_items. O resto das tabelas são tabelas de referência. No nosso exemplo, a tabela de países é uma tabela de referência.
-- Distribute large tables by the tenant ID
SELECT create_distributed_table('stores', 'store_id');
SELECT create_distributed_table('products', 'store_id', colocate_with => 'stores');
-- etc for the rest of the tenant tables...
-- Then, make "countries" a reference table, with a synchronized copy of the
-- table maintained on every worker node
SELECT create_reference_table('countries');
Todas as tabelas grandes devem ter o ID do inquilino.
- Se você estiver migrando um aplicativo multilocatário existente para o Azure Cosmos DB para PostgreSQL, talvez seja necessário desnormalizar um pouco e adicionar a coluna ID do locatário a tabelas grandes, se estiver faltando, e preencher os valores ausentes da coluna.
- Para novos aplicativos no Azure Cosmos DB para PostgreSQL, verifique se a ID do locatário está presente em todas as tabelas específicas do locatário.
Certifique-se de incluir o ID do locatário em restrições de chave primária, exclusiva e estrangeira em tabelas distribuídas na forma de uma chave composta. Por exemplo, se uma tabela tiver uma chave primária de id, transforme-a na chave (tenant_id,id)composta.
Não há necessidade de alterar as teclas das tabelas de referência.
Considerações de consulta para melhor desempenho
As consultas distribuídas que filtram o ID do locatário são executadas de forma mais eficiente em aplicativos multilocatário. Certifique-se de que suas consultas tenham sempre o escopo de um único locatário.
SELECT *
FROM orders
WHERE order_id = 123
AND store_id = 42; -- ← tenant ID filter
É necessário adicionar o filtro de ID do locatário mesmo que as condições de filtro originais identifiquem inequivocamente as linhas desejadas. O filtro de ID do locatário, embora aparentemente redundante, informa ao Azure Cosmos DB para PostgreSQL como rotear a consulta para um único nó de trabalho.
Da mesma forma, quando você estiver unindo duas tabelas distribuídas, certifique-se de que ambas as tabelas tenham escopo para um único locatário. O escopo pode ser feito garantindo que as condições de associação incluam o ID do locatário.
SELECT sum(l.quantity)
FROM line_items l
INNER JOIN products p
ON l.product_id = p.product_id
AND l.store_id = p.store_id -- ← tenant ID in join
WHERE p.name='Awesome Wool Pants'
AND l.store_id='8c69aa0d-3f13-4440-86ca-443566c1fc75';
-- ↑ tenant ID filter
Existem bibliotecas auxiliares para várias estruturas de aplicativos populares que facilitam a inclusão de um ID de locatário em consultas. Aqui estão as instruções:
Próximos passos
Agora terminamos de explorar a modelagem de dados para aplicativos escaláveis. O próximo passo é conectar e consultar o banco de dados com a linguagem de programação de sua escolha.