Guia de início rápido: reconhecer e converter fala em texto
Importante
Os itens marcados (visualização) neste artigo estão atualmente em visualização pública. Essa visualização é fornecida sem um contrato de nível de serviço e não a recomendamos para cargas de trabalho de produção. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas. Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
Neste início rápido, você tenta falar em texto em tempo real no Azure AI Foundry.
Pré-requisitos
- Subscrição do Azure - Crie uma gratuitamente.
- Alguns recursos de serviços de IA do Azure são gratuitos para experimentar no portal do Azure AI Foundry. Para ter acesso a todos os recursos descritos neste artigo, você precisa conectar serviços de IA no Azure AI Foundry.
Experimente a conversão de voz em texto em tempo real
Vá para o seu projeto do Azure AI Foundry. Se você precisar criar um projeto, consulte Criar um projeto do Azure AI Foundry.
Selecione Playgrounds no painel esquerdo e, em seguida, selecione um playground para usar. Neste exemplo, selecione Experimentar o espaço de interação de fala.

Opcionalmente, você pode selecionar uma conexão diferente para usar no playground. No playground de Fala, você pode se conectar aos recursos multisserviço dos Serviços de IA do Azure ou aos recursos do serviço de Fala.
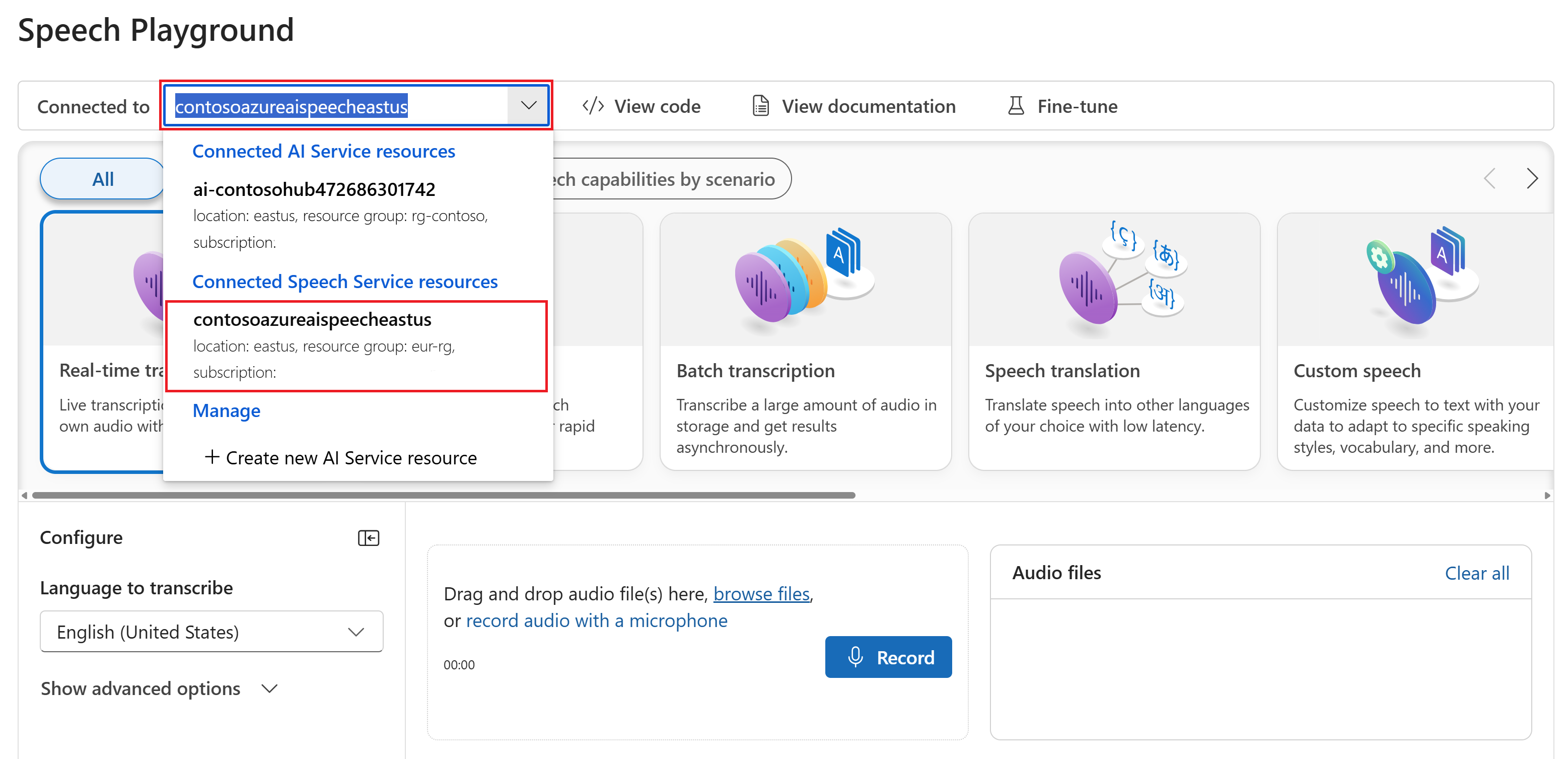
Selecione Transcrição em tempo real.
Selecione Mostrar opções avançadas para configurar as opções de fala para texto, como:
- Identificação de idioma: usada para identificar idiomas falados em áudio quando comparados com uma lista de idiomas suportados. Para obter mais informações sobre opções de identificação de idioma, como reconhecimento inicial e contínuo, consulte Identificação de idioma.
- Diarização de alto-falantes: Usado para identificar e separar alto-falantes em áudio. A diarização distingue entre os diferentes oradores que participam na conversa. O serviço de Fala fornece informações sobre qual orador estava falando uma parte específica da fala transcrita. Para obter mais informações sobre a diarização do orador, consulte o guia de início rápido de fala em texto em tempo real com diarização do alto-falante.
- Ponto de extremidade personalizado: use um modelo implantado de fala personalizada para melhorar a precisão do reconhecimento. Para usar o modelo de linha de base da Microsoft, deixe este conjunto como Nenhum. Para obter mais informações sobre fala personalizada, consulte Fala personalizada.
- Formato de saída: Escolha entre formatos de saída simples e detalhados. A saída simples inclui formato de exibição e carimbos de data/hora. A saída detalhada inclui mais formatos (como display, lexical, ITN e mascarado ITN), carimbos de data/hora e listas N-best.
- Lista de frases: melhore a precisão da transcrição fornecendo uma lista de frases conhecidas, como nomes de pessoas ou locais específicos. Use vírgulas ou ponto-e-vírgula para separar cada valor na lista de frases. Para obter mais informações sobre listas de frases, consulte Listas de frases.
Selecione um arquivo de áudio para carregar ou grave áudio em tempo real. Neste exemplo, usamos o
Call1_separated_16k_health_insurance.wavarquivo disponível no repositório do Speech SDK no GitHub. Você pode baixar o arquivo ou usar seu próprio arquivo de áudio.
Você pode visualizar a transcrição em tempo real na parte inferior da página.

Você pode selecionar a guia JSON para ver a saída JSON da transcrição. As propriedades incluem
Offset,Duration,RecognitionStatus,Display,Lexical,ITNe muito mais.





Pacote de documentação | de referência (NuGet) | Exemplos adicionais no GitHub
Neste início rápido, você cria e executa um aplicativo para reconhecer e transcrever fala para texto em tempo real.
Para transcrever arquivos de áudio de forma assíncrona, consulte O que é transcrição em lote. Se você não tiver certeza de qual solução de fala para texto é ideal para você, consulte O que é fala para texto?
Pré-requisitos
- Uma subscrição do Azure. Você pode criar um gratuitamente.
- Crie um recurso de Fala no portal do Azure.
- Obtenha a chave de recurso de Fala e a região. Depois que o recurso de Fala for implantado, selecione Ir para o recurso para exibir e gerenciar chaves.
Configurar o ambiente
O SDK de fala está disponível como um pacote NuGet e implementa o .NET Standard 2.0. Você instala o SDK de fala mais adiante neste guia. Para quaisquer outros requisitos, consulte Instalar o SDK de fala.
Definir variáveis de ambiente
Você precisa autenticar seu aplicativo para acessar os serviços de IA do Azure. Este artigo mostra como usar variáveis de ambiente para armazenar suas credenciais. Em seguida, você pode acessar as variáveis de ambiente do seu código para autenticar seu aplicativo. Para produção, use uma maneira mais segura de armazenar e acessar suas credenciais.
Importante
Recomendamos a autenticação do Microsoft Entra ID com identidades gerenciadas para recursos do Azure para evitar o armazenamento de credenciais com seus aplicativos executados na nuvem.
Se você usar uma chave de API, armazene-a com segurança em outro lugar, como no Cofre de Chaves do Azure. Não inclua a chave da API diretamente no seu código e nunca a publique publicamente.
Para obter mais informações sobre segurança de serviços de IA, consulte Autenticar solicitações para serviços de IA do Azure.
Para definir as variáveis de ambiente para sua chave de recurso de fala e região, abra uma janela de console e siga as instruções para seu sistema operacional e ambiente de desenvolvimento.
- Para definir a variável de ambiente, substitua
SPEECH_KEYsua chave por uma das chaves do seu recurso. - Para definir a variável de ambiente, substitua
SPEECH_REGIONsua região por uma das regiões do seu recurso.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota
Se você só precisar acessar as variáveis de ambiente no console atual, poderá definir a variável de ambiente com set em vez de setx.
Depois de adicionar as variáveis de ambiente, talvez seja necessário reiniciar todos os programas que precisam ler as variáveis de ambiente, incluindo a janela do console. Por exemplo, se você estiver usando o Visual Studio como editor, reinicie o Visual Studio antes de executar o exemplo.
Reconhecer voz a partir de um microfone
Gorjeta
Experimente o Kit de Ferramentas de Fala da IA do Azure para criar e executar facilmente exemplos no Visual Studio Code.
Siga estas etapas para criar um aplicativo de console e instalar o SDK de fala.
Abra uma janela de prompt de comando na pasta onde você deseja o novo projeto. Execute este comando para criar um aplicativo de console com a CLI do .NET.
dotnet new consoleEste comando cria o arquivo Program.cs no diretório do projeto.
Instale o SDK de fala em seu novo projeto com a CLI do .NET.
dotnet add package Microsoft.CognitiveServices.SpeechSubstitua o conteúdo do ficheiro Program.cs pelo seguinte código:
using System; using System.IO; using System.Threading.Tasks; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; class Program { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); static void OutputSpeechRecognitionResult(SpeechRecognitionResult speechRecognitionResult) { switch (speechRecognitionResult.Reason) { case ResultReason.RecognizedSpeech: Console.WriteLine($"RECOGNIZED: Text={speechRecognitionResult.Text}"); break; case ResultReason.NoMatch: Console.WriteLine($"NOMATCH: Speech could not be recognized."); break; case ResultReason.Canceled: var cancellation = CancellationDetails.FromResult(speechRecognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?"); } break; } } async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); using var speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); Console.WriteLine("Speak into your microphone."); var speechRecognitionResult = await speechRecognizer.RecognizeOnceAsync(); OutputSpeechRecognitionResult(speechRecognitionResult); } }Para alterar o idioma de reconhecimento de fala, substitua
en-USpor outro idioma suportado. Por exemplo, usees-ESpara espanhol (Espanha). Se você não especificar um idioma, o padrão seráen-US. Para obter detalhes sobre como identificar um dos vários idiomas que podem ser falados, consulte Identificação de idioma.Execute seu novo aplicativo de console para iniciar o reconhecimento de fala a partir de um microfone:
dotnet runImportante
Certifique-se de definir as
SPEECH_KEYvariáveis eSPEECH_REGIONde ambiente. Se você não definir essas variáveis, o exemplo falhará com uma mensagem de erro.Fale ao microfone quando solicitado. O que você fala deve aparecer como texto:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Observações
Aqui estão algumas outras considerações:
Este exemplo usa a operação para transcrever enunciados de até 30 segundos ou até que o
RecognizeOnceAsyncsilêncio seja detetado. Para obter informações sobre o reconhecimento contínuo de áudio mais longo, incluindo conversas multilingues, consulte Como reconhecer voz.Para reconhecer a fala de um arquivo de áudio, use
FromWavFileInputem vez deFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav");Para arquivos de áudio compactado, como MP4, instale o GStreamer e use
PullAudioInputStreamouPushAudioInputStream. Para obter mais informações, consulte Como usar áudio de entrada compactada.
Clean up resources (Limpar recursos)
Você pode usar o portal do Azure ou a CLI (Interface de Linha de Comando) do Azure para remover o recurso de Fala criado.
Pacote de documentação | de referência (NuGet) | Exemplos adicionais no GitHub
Neste início rápido, você cria e executa um aplicativo para reconhecer e transcrever fala para texto em tempo real.
Para transcrever arquivos de áudio de forma assíncrona, consulte O que é transcrição em lote. Se você não tiver certeza de qual solução de fala para texto é ideal para você, consulte O que é fala para texto?
Pré-requisitos
- Uma subscrição do Azure. Você pode criar um gratuitamente.
- Crie um recurso de Fala no portal do Azure.
- Obtenha a chave de recurso de Fala e a região. Depois que o recurso de Fala for implantado, selecione Ir para o recurso para exibir e gerenciar chaves.
Configurar o ambiente
O SDK de fala está disponível como um pacote NuGet e implementa o .NET Standard 2.0. Você instala o SDK de fala mais adiante neste guia. Para outros requisitos, consulte Instalar o SDK de fala.
Definir variáveis de ambiente
Você precisa autenticar seu aplicativo para acessar os serviços de IA do Azure. Este artigo mostra como usar variáveis de ambiente para armazenar suas credenciais. Em seguida, você pode acessar as variáveis de ambiente do seu código para autenticar seu aplicativo. Para produção, use uma maneira mais segura de armazenar e acessar suas credenciais.
Importante
Recomendamos a autenticação do Microsoft Entra ID com identidades gerenciadas para recursos do Azure para evitar o armazenamento de credenciais com seus aplicativos executados na nuvem.
Se você usar uma chave de API, armazene-a com segurança em outro lugar, como no Cofre de Chaves do Azure. Não inclua a chave da API diretamente no seu código e nunca a publique publicamente.
Para obter mais informações sobre segurança de serviços de IA, consulte Autenticar solicitações para serviços de IA do Azure.
Para definir as variáveis de ambiente para sua chave de recurso de fala e região, abra uma janela de console e siga as instruções para seu sistema operacional e ambiente de desenvolvimento.
- Para definir a variável de ambiente, substitua
SPEECH_KEYsua chave por uma das chaves do seu recurso. - Para definir a variável de ambiente, substitua
SPEECH_REGIONsua região por uma das regiões do seu recurso.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota
Se você só precisar acessar as variáveis de ambiente no console atual, poderá definir a variável de ambiente com set em vez de setx.
Depois de adicionar as variáveis de ambiente, talvez seja necessário reiniciar todos os programas que precisam ler as variáveis de ambiente, incluindo a janela do console. Por exemplo, se você estiver usando o Visual Studio como editor, reinicie o Visual Studio antes de executar o exemplo.
Reconhecer voz a partir de um microfone
Gorjeta
Experimente o Kit de Ferramentas de Fala da IA do Azure para criar e executar facilmente exemplos no Visual Studio Code.
Siga estas etapas para criar um aplicativo de console e instalar o SDK de fala.
Crie um novo projeto de console C++ na Comunidade do Visual Studio chamado
SpeechRecognition.Selecione Ferramentas>Nuget Package Manager Package Manager Console (Ferramentas Nuget Package Manager>PackageManager Console). No Console do Gerenciador de Pacotes, execute este comando:
Install-Package Microsoft.CognitiveServices.SpeechSubstitua o conteúdo do
SpeechRecognition.cpppelo seguinte código:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); if ((size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set both SPEECH_KEY and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto speechRecognizer = SpeechRecognizer::FromConfig(speechConfig, audioConfig); std::cout << "Speak into your microphone.\n"; auto result = speechRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }Para alterar o idioma de reconhecimento de fala, substitua
en-USpor outro idioma suportado. Por exemplo, usees-ESpara espanhol (Espanha). Se você não especificar um idioma, o padrão seráen-US. Para obter detalhes sobre como identificar um dos vários idiomas que podem ser falados, consulte Identificação de idioma.Crie e execute seu novo aplicativo de console para iniciar o reconhecimento de fala a partir de um microfone.
Importante
Certifique-se de definir as
SPEECH_KEYvariáveis eSPEECH_REGIONde ambiente. Se você não definir essas variáveis, o exemplo falhará com uma mensagem de erro.Fale ao microfone quando solicitado. O que você fala deve aparecer como texto:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Observações
Aqui estão algumas outras considerações:
Este exemplo usa a operação para transcrever enunciados de até 30 segundos ou até que o
RecognizeOnceAsyncsilêncio seja detetado. Para obter informações sobre o reconhecimento contínuo de áudio mais longo, incluindo conversas multilingues, consulte Como reconhecer voz.Para reconhecer a fala de um arquivo de áudio, use
FromWavFileInputem vez deFromDefaultMicrophoneInput:auto audioConfig = AudioConfig::FromWavFileInput("YourAudioFile.wav");Para arquivos de áudio compactado, como MP4, instale o GStreamer e use
PullAudioInputStreamouPushAudioInputStream. Para obter mais informações, consulte Como usar áudio de entrada compactada.
Clean up resources (Limpar recursos)
Você pode usar o portal do Azure ou a CLI (Interface de Linha de Comando) do Azure para remover o recurso de Fala criado.
Pacote de documentação | de referência (Go) | Amostras adicionais no GitHub
Neste início rápido, você cria e executa um aplicativo para reconhecer e transcrever fala para texto em tempo real.
Para transcrever arquivos de áudio de forma assíncrona, consulte O que é transcrição em lote. Se você não tiver certeza de qual solução de fala para texto é ideal para você, consulte O que é fala para texto?
Pré-requisitos
- Uma subscrição do Azure. Você pode criar um gratuitamente.
- Crie um recurso de Fala no portal do Azure.
- Obtenha a chave de recurso de Fala e a região. Depois que o recurso de Fala for implantado, selecione Ir para o recurso para exibir e gerenciar chaves.
Configurar o ambiente
Instale o SDK de Fala para Go. Para obter requisitos e instruções, consulte Instalar o SDK de fala.
Definir variáveis de ambiente
Você precisa autenticar seu aplicativo para acessar os serviços de IA do Azure. Este artigo mostra como usar variáveis de ambiente para armazenar suas credenciais. Em seguida, você pode acessar as variáveis de ambiente do seu código para autenticar seu aplicativo. Para produção, use uma maneira mais segura de armazenar e acessar suas credenciais.
Importante
Recomendamos a autenticação do Microsoft Entra ID com identidades gerenciadas para recursos do Azure para evitar o armazenamento de credenciais com seus aplicativos executados na nuvem.
Se você usar uma chave de API, armazene-a com segurança em outro lugar, como no Cofre de Chaves do Azure. Não inclua a chave da API diretamente no seu código e nunca a publique publicamente.
Para obter mais informações sobre segurança de serviços de IA, consulte Autenticar solicitações para serviços de IA do Azure.
Para definir as variáveis de ambiente para sua chave de recurso de fala e região, abra uma janela de console e siga as instruções para seu sistema operacional e ambiente de desenvolvimento.
- Para definir a variável de ambiente, substitua
SPEECH_KEYsua chave por uma das chaves do seu recurso. - Para definir a variável de ambiente, substitua
SPEECH_REGIONsua região por uma das regiões do seu recurso.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota
Se você só precisar acessar as variáveis de ambiente no console atual, poderá definir a variável de ambiente com set em vez de setx.
Depois de adicionar as variáveis de ambiente, talvez seja necessário reiniciar todos os programas que precisam ler as variáveis de ambiente, incluindo a janela do console. Por exemplo, se você estiver usando o Visual Studio como editor, reinicie o Visual Studio antes de executar o exemplo.
Reconhecer voz a partir de um microfone
Siga estas etapas para criar um módulo GO.
Abra uma janela de prompt de comando na pasta onde você deseja o novo projeto. Crie um novo arquivo chamado speech-recognition.go.
Copie o seguinte código para speech-recognition.go:
package main import ( "bufio" "fmt" "os" "github.com/Microsoft/cognitive-services-speech-sdk-go/audio" "github.com/Microsoft/cognitive-services-speech-sdk-go/speech" ) func sessionStartedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Started (ID=", event.SessionID, ")") } func sessionStoppedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Stopped (ID=", event.SessionID, ")") } func recognizingHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognizing:", event.Result.Text) } func recognizedHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognized:", event.Result.Text) } func cancelledHandler(event speech.SpeechRecognitionCanceledEventArgs) { defer event.Close() fmt.Println("Received a cancellation: ", event.ErrorDetails) fmt.Println("Did you set the speech resource key and region values?") } func main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speechKey := os.Getenv("SPEECH_KEY") speechRegion := os.Getenv("SPEECH_REGION") audioConfig, err := audio.NewAudioConfigFromDefaultMicrophoneInput() if err != nil { fmt.Println("Got an error: ", err) return } defer audioConfig.Close() speechConfig, err := speech.NewSpeechConfigFromSubscription(speechKey, speechRegion) if err != nil { fmt.Println("Got an error: ", err) return } defer speechConfig.Close() speechRecognizer, err := speech.NewSpeechRecognizerFromConfig(speechConfig, audioConfig) if err != nil { fmt.Println("Got an error: ", err) return } defer speechRecognizer.Close() speechRecognizer.SessionStarted(sessionStartedHandler) speechRecognizer.SessionStopped(sessionStoppedHandler) speechRecognizer.Recognizing(recognizingHandler) speechRecognizer.Recognized(recognizedHandler) speechRecognizer.Canceled(cancelledHandler) speechRecognizer.StartContinuousRecognitionAsync() defer speechRecognizer.StopContinuousRecognitionAsync() bufio.NewReader(os.Stdin).ReadBytes('\n') }Execute os seguintes comandos para criar um arquivo go.mod vinculado a componentes hospedados no GitHub:
go mod init speech-recognition go get github.com/Microsoft/cognitive-services-speech-sdk-goImportante
Certifique-se de definir as
SPEECH_KEYvariáveis eSPEECH_REGIONde ambiente. Se você não definir essas variáveis, o exemplo falhará com uma mensagem de erro.Compile e execute o código:
go build go run speech-recognition
Clean up resources (Limpar recursos)
Você pode usar o portal do Azure ou a CLI (Interface de Linha de Comando) do Azure para remover o recurso de Fala criado.
Documentação | de referência Exemplos adicionais no GitHub
Neste início rápido, você cria e executa um aplicativo para reconhecer e transcrever fala para texto em tempo real.
Para transcrever arquivos de áudio de forma assíncrona, consulte O que é transcrição em lote. Se você não tiver certeza de qual solução de fala para texto é ideal para você, consulte O que é fala para texto?
Pré-requisitos
- Uma subscrição do Azure. Você pode criar um gratuitamente.
- Crie um recurso de Fala no portal do Azure.
- Obtenha a chave de recurso de Fala e a região. Depois que o recurso de Fala for implantado, selecione Ir para o recurso para exibir e gerenciar chaves.
Configurar o ambiente
Para configurar seu ambiente, instale o SDK de fala. O exemplo neste início rápido funciona com o Java Runtime.
Instale o Apache Maven. Em seguida, execute
mvn -vpara confirmar a instalação bem-sucedida.Crie um novo
pom.xmlarquivo na raiz do seu projeto e copie o seguinte código para ele:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.42.0</version> </dependency> </dependencies> </project>Instale o SDK de fala e as dependências.
mvn clean dependency:copy-dependencies
Definir variáveis de ambiente
Você precisa autenticar seu aplicativo para acessar os serviços de IA do Azure. Este artigo mostra como usar variáveis de ambiente para armazenar suas credenciais. Em seguida, você pode acessar as variáveis de ambiente do seu código para autenticar seu aplicativo. Para produção, use uma maneira mais segura de armazenar e acessar suas credenciais.
Importante
Recomendamos a autenticação do Microsoft Entra ID com identidades gerenciadas para recursos do Azure para evitar o armazenamento de credenciais com seus aplicativos executados na nuvem.
Se você usar uma chave de API, armazene-a com segurança em outro lugar, como no Cofre de Chaves do Azure. Não inclua a chave da API diretamente no seu código e nunca a publique publicamente.
Para obter mais informações sobre segurança de serviços de IA, consulte Autenticar solicitações para serviços de IA do Azure.
Para definir as variáveis de ambiente para sua chave de recurso de fala e região, abra uma janela de console e siga as instruções para seu sistema operacional e ambiente de desenvolvimento.
- Para definir a variável de ambiente, substitua
SPEECH_KEYsua chave por uma das chaves do seu recurso. - Para definir a variável de ambiente, substitua
SPEECH_REGIONsua região por uma das regiões do seu recurso.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota
Se você só precisar acessar as variáveis de ambiente no console atual, poderá definir a variável de ambiente com set em vez de setx.
Depois de adicionar as variáveis de ambiente, talvez seja necessário reiniciar todos os programas que precisam ler as variáveis de ambiente, incluindo a janela do console. Por exemplo, se você estiver usando o Visual Studio como editor, reinicie o Visual Studio antes de executar o exemplo.
Reconhecer voz a partir de um microfone
Siga estas etapas para criar um aplicativo de console para reconhecimento de fala.
Crie um novo arquivo chamado SpeechRecognition.java no mesmo diretório raiz do projeto.
Copie o seguinte código para SpeechRecognition.java:
import com.microsoft.cognitiveservices.speech.*; import com.microsoft.cognitiveservices.speech.audio.AudioConfig; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; public class SpeechRecognition { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" private static String speechKey = System.getenv("SPEECH_KEY"); private static String speechRegion = System.getenv("SPEECH_REGION"); public static void main(String[] args) throws InterruptedException, ExecutionException { SpeechConfig speechConfig = SpeechConfig.fromSubscription(speechKey, speechRegion); speechConfig.setSpeechRecognitionLanguage("en-US"); recognizeFromMicrophone(speechConfig); } public static void recognizeFromMicrophone(SpeechConfig speechConfig) throws InterruptedException, ExecutionException { AudioConfig audioConfig = AudioConfig.fromDefaultMicrophoneInput(); SpeechRecognizer speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); System.out.println("Speak into your microphone."); Future<SpeechRecognitionResult> task = speechRecognizer.recognizeOnceAsync(); SpeechRecognitionResult speechRecognitionResult = task.get(); if (speechRecognitionResult.getReason() == ResultReason.RecognizedSpeech) { System.out.println("RECOGNIZED: Text=" + speechRecognitionResult.getText()); } else if (speechRecognitionResult.getReason() == ResultReason.NoMatch) { System.out.println("NOMATCH: Speech could not be recognized."); } else if (speechRecognitionResult.getReason() == ResultReason.Canceled) { CancellationDetails cancellation = CancellationDetails.fromResult(speechRecognitionResult); System.out.println("CANCELED: Reason=" + cancellation.getReason()); if (cancellation.getReason() == CancellationReason.Error) { System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode()); System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails()); System.out.println("CANCELED: Did you set the speech resource key and region values?"); } } System.exit(0); } }Para alterar o idioma de reconhecimento de fala, substitua
en-USpor outro idioma suportado. Por exemplo, usees-ESpara espanhol (Espanha). Se você não especificar um idioma, o padrão seráen-US. Para obter detalhes sobre como identificar um dos vários idiomas que podem ser falados, consulte Identificação de idioma.Execute seu novo aplicativo de console para iniciar o reconhecimento de fala a partir de um microfone:
javac SpeechRecognition.java -cp ".;target\dependency\*" java -cp ".;target\dependency\*" SpeechRecognitionImportante
Certifique-se de definir as
SPEECH_KEYvariáveis eSPEECH_REGIONde ambiente. Se você não definir essas variáveis, o exemplo falhará com uma mensagem de erro.Fale ao microfone quando solicitado. O que você fala deve aparecer como texto:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Observações
Aqui estão algumas outras considerações:
Este exemplo usa a operação para transcrever enunciados de até 30 segundos ou até que o
RecognizeOnceAsyncsilêncio seja detetado. Para obter informações sobre o reconhecimento contínuo de áudio mais longo, incluindo conversas multilingues, consulte Como reconhecer voz.Para reconhecer a fala de um arquivo de áudio, use
fromWavFileInputem vez defromDefaultMicrophoneInput:AudioConfig audioConfig = AudioConfig.fromWavFileInput("YourAudioFile.wav");Para arquivos de áudio compactado, como MP4, instale o GStreamer e use
PullAudioInputStreamouPushAudioInputStream. Para obter mais informações, consulte Como usar áudio de entrada compactada.
Clean up resources (Limpar recursos)
Você pode usar o portal do Azure ou a CLI (Interface de Linha de Comando) do Azure para remover o recurso de Fala criado.
Pacote de documentação | de referência (npm) | Exemplos adicionais no código-fonte da Biblioteca GitHub |
Neste início rápido, você cria e executa um aplicativo para reconhecer e transcrever fala para texto em tempo real.
Para transcrever arquivos de áudio de forma assíncrona, consulte O que é transcrição em lote. Se você não tiver certeza de qual solução de fala para texto é ideal para você, consulte O que é fala para texto?
Pré-requisitos
- Uma subscrição do Azure. Você pode criar um gratuitamente.
- Crie um recurso de Fala no portal do Azure.
- Obtenha a chave de recurso de Fala e a região. Depois que o recurso de Fala for implantado, selecione Ir para o recurso para exibir e gerenciar chaves.
Você também precisa de um arquivo de áudio .wav em sua máquina local. Você pode usar seu próprio arquivo .wav (até 30 segundos) ou baixar o arquivo de https://crbn.us/whatstheweatherlike.wav exemplo.
Configurar o ambiente
Para configurar seu ambiente, instale o SDK de fala para JavaScript. Execute este comando: npm install microsoft-cognitiveservices-speech-sdk. Para obter instruções de instalação guiadas, consulte Instalar o SDK de fala.
Definir variáveis de ambiente
Você precisa autenticar seu aplicativo para acessar os serviços de IA do Azure. Este artigo mostra como usar variáveis de ambiente para armazenar suas credenciais. Em seguida, você pode acessar as variáveis de ambiente do seu código para autenticar seu aplicativo. Para produção, use uma maneira mais segura de armazenar e acessar suas credenciais.
Importante
Recomendamos a autenticação do Microsoft Entra ID com identidades gerenciadas para recursos do Azure para evitar o armazenamento de credenciais com seus aplicativos executados na nuvem.
Se você usar uma chave de API, armazene-a com segurança em outro lugar, como no Cofre de Chaves do Azure. Não inclua a chave da API diretamente no seu código e nunca a publique publicamente.
Para obter mais informações sobre segurança de serviços de IA, consulte Autenticar solicitações para serviços de IA do Azure.
Para definir as variáveis de ambiente para sua chave de recurso de fala e região, abra uma janela de console e siga as instruções para seu sistema operacional e ambiente de desenvolvimento.
- Para definir a variável de ambiente, substitua
SPEECH_KEYsua chave por uma das chaves do seu recurso. - Para definir a variável de ambiente, substitua
SPEECH_REGIONsua região por uma das regiões do seu recurso.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota
Se você só precisar acessar as variáveis de ambiente no console atual, poderá definir a variável de ambiente com set em vez de setx.
Depois de adicionar as variáveis de ambiente, talvez seja necessário reiniciar todos os programas que precisam ler as variáveis de ambiente, incluindo a janela do console. Por exemplo, se você estiver usando o Visual Studio como editor, reinicie o Visual Studio antes de executar o exemplo.
Reconhecer a voz a partir de um ficheiro
Gorjeta
Experimente o Kit de Ferramentas de Fala da IA do Azure para criar e executar facilmente exemplos no Visual Studio Code.
Siga estas etapas para criar um aplicativo de console Node.js para reconhecimento de fala.
Abra uma janela de prompt de comando onde você deseja o novo projeto e crie um novo arquivo chamado SpeechRecognition.js.
Instale o SDK de fala para JavaScript:
npm install microsoft-cognitiveservices-speech-sdkCopie o seguinte código para SpeechRecognition.js:
const fs = require("fs"); const sdk = require("microsoft-cognitiveservices-speech-sdk"); // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" const speechConfig = sdk.SpeechConfig.fromSubscription(process.env.SPEECH_KEY, process.env.SPEECH_REGION); speechConfig.speechRecognitionLanguage = "en-US"; function fromFile() { let audioConfig = sdk.AudioConfig.fromWavFileInput(fs.readFileSync("YourAudioFile.wav")); let speechRecognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig); speechRecognizer.recognizeOnceAsync(result => { switch (result.reason) { case sdk.ResultReason.RecognizedSpeech: console.log(`RECOGNIZED: Text=${result.text}`); break; case sdk.ResultReason.NoMatch: console.log("NOMATCH: Speech could not be recognized."); break; case sdk.ResultReason.Canceled: const cancellation = sdk.CancellationDetails.fromResult(result); console.log(`CANCELED: Reason=${cancellation.reason}`); if (cancellation.reason == sdk.CancellationReason.Error) { console.log(`CANCELED: ErrorCode=${cancellation.ErrorCode}`); console.log(`CANCELED: ErrorDetails=${cancellation.errorDetails}`); console.log("CANCELED: Did you set the speech resource key and region values?"); } break; } speechRecognizer.close(); }); } fromFile();Em SpeechRecognition.js, substitua-YourAudioFile.wav pelo seu próprio ficheiro .wav. Este exemplo só reconhece a fala de um arquivo .wav . Para obter informações sobre outros formatos de áudio, consulte Como usar áudio de entrada compactada. Este exemplo suporta até 30 segundos de áudio.
Para alterar o idioma de reconhecimento de fala, substitua
en-USpor outro idioma suportado. Por exemplo, usees-ESpara espanhol (Espanha). Se você não especificar um idioma, o padrão seráen-US. Para obter detalhes sobre como identificar um dos vários idiomas que podem ser falados, consulte Identificação de idioma.Execute seu novo aplicativo de console para iniciar o reconhecimento de fala a partir de um arquivo:
node.exe SpeechRecognition.jsImportante
Certifique-se de definir as
SPEECH_KEYvariáveis eSPEECH_REGIONde ambiente. Se você não definir essas variáveis, o exemplo falhará com uma mensagem de erro.A fala do arquivo de áudio deve ser saída como texto:
RECOGNIZED: Text=I'm excited to try speech to text.
Observações
Este exemplo usa a operação para transcrever enunciados de até 30 segundos ou até que o recognizeOnceAsync silêncio seja detetado. Para obter informações sobre o reconhecimento contínuo de áudio mais longo, incluindo conversas multilingues, consulte Como reconhecer voz.
Nota
Não há suporte para reconhecer a fala de um microfone no Node.js. É suportado apenas em um ambiente JavaScript baseado em navegador. Para obter mais informações, consulte o exemplo React e a implementação de fala em texto a partir de um microfone no GitHub.
O exemplo React mostra padrões de design para a troca e o gerenciamento de tokens de autenticação. Ele também mostra a captura de áudio de um microfone ou arquivo para conversão de fala em texto.
Clean up resources (Limpar recursos)
Você pode usar o portal do Azure ou a CLI (Interface de Linha de Comando) do Azure para remover o recurso de Fala criado.
Pacote de documentação | de referência (PyPi) | Amostras adicionais no GitHub
Neste início rápido, você cria e executa um aplicativo para reconhecer e transcrever fala para texto em tempo real.
Para transcrever arquivos de áudio de forma assíncrona, consulte O que é transcrição em lote. Se você não tiver certeza de qual solução de fala para texto é ideal para você, consulte O que é fala para texto?
Pré-requisitos
- Uma subscrição do Azure. Você pode criar um gratuitamente.
- Crie um recurso de Fala no portal do Azure.
- Obtenha a chave de recurso de Fala e a região. Depois que o recurso de Fala for implantado, selecione Ir para o recurso para exibir e gerenciar chaves.
Configurar o ambiente
O Speech SDK for Python está disponível como um módulo Python Package Index (PyPI). O Speech SDK for Python é compatível com Windows, Linux e macOS.
- Para Windows, instale o Microsoft Visual C++ Redistributable for Visual Studio 2015, 2017, 2019 e 2022 para sua plataforma. A instalação deste pacote pela primeira vez pode exigir uma reinicialização.
- No Linux, você deve usar a arquitetura de destino x64.
Instale uma versão do Python a partir da versão 3.7 ou posterior. Para outros requisitos, consulte Instalar o SDK de fala.
Definir variáveis de ambiente
Você precisa autenticar seu aplicativo para acessar os serviços de IA do Azure. Este artigo mostra como usar variáveis de ambiente para armazenar suas credenciais. Em seguida, você pode acessar as variáveis de ambiente do seu código para autenticar seu aplicativo. Para produção, use uma maneira mais segura de armazenar e acessar suas credenciais.
Importante
Recomendamos a autenticação do Microsoft Entra ID com identidades gerenciadas para recursos do Azure para evitar o armazenamento de credenciais com seus aplicativos executados na nuvem.
Se você usar uma chave de API, armazene-a com segurança em outro lugar, como no Cofre de Chaves do Azure. Não inclua a chave da API diretamente no seu código e nunca a publique publicamente.
Para obter mais informações sobre segurança de serviços de IA, consulte Autenticar solicitações para serviços de IA do Azure.
Para definir as variáveis de ambiente para sua chave de recurso de fala e região, abra uma janela de console e siga as instruções para seu sistema operacional e ambiente de desenvolvimento.
- Para definir a variável de ambiente, substitua
SPEECH_KEYsua chave por uma das chaves do seu recurso. - Para definir a variável de ambiente, substitua
SPEECH_REGIONsua região por uma das regiões do seu recurso.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota
Se você só precisar acessar as variáveis de ambiente no console atual, poderá definir a variável de ambiente com set em vez de setx.
Depois de adicionar as variáveis de ambiente, talvez seja necessário reiniciar todos os programas que precisam ler as variáveis de ambiente, incluindo a janela do console. Por exemplo, se você estiver usando o Visual Studio como editor, reinicie o Visual Studio antes de executar o exemplo.
Reconhecer voz a partir de um microfone
Gorjeta
Experimente o Kit de Ferramentas de Fala da IA do Azure para criar e executar facilmente exemplos no Visual Studio Code.
Siga estas etapas para criar um aplicativo de console.
Abra uma janela de prompt de comando na pasta onde você deseja o novo projeto. Crie um novo arquivo chamado speech_recognition.py.
Execute este comando para instalar o SDK de fala:
pip install azure-cognitiveservices-speechCopie o seguinte código para speech_recognition.py:
import os import azure.cognitiveservices.speech as speechsdk def recognize_from_microphone(): # This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('SPEECH_KEY'), region=os.environ.get('SPEECH_REGION')) speech_config.speech_recognition_language="en-US" audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True) speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) print("Speak into your microphone.") speech_recognition_result = speech_recognizer.recognize_once_async().get() if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(speech_recognition_result.text)) elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(speech_recognition_result.no_match_details)) elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled: cancellation_details = speech_recognition_result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) print("Did you set the speech resource key and region values?") recognize_from_microphone()Para alterar o idioma de reconhecimento de fala, substitua
en-USpor outro idioma suportado. Por exemplo, usees-ESpara espanhol (Espanha). Se você não especificar um idioma, o padrão seráen-US. Para obter detalhes sobre como identificar um dos vários idiomas que podem ser falados, consulte Identificação do idioma.Execute seu novo aplicativo de console para iniciar o reconhecimento de fala a partir de um microfone:
python speech_recognition.pyImportante
Certifique-se de definir as
SPEECH_KEYvariáveis eSPEECH_REGIONde ambiente. Se você não definir essas variáveis, o exemplo falhará com uma mensagem de erro.Fale ao microfone quando solicitado. O que você fala deve aparecer como texto:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Observações
Aqui estão algumas outras considerações:
Este exemplo usa a operação para transcrever enunciados de até 30 segundos ou até que o
recognize_once_asyncsilêncio seja detetado. Para obter informações sobre o reconhecimento contínuo de áudio mais longo, incluindo conversas multilingues, consulte Como reconhecer voz.Para reconhecer a fala de um arquivo de áudio, use
filenameem vez deuse_default_microphone:audio_config = speechsdk.audio.AudioConfig(filename="YourAudioFile.wav")Para arquivos de áudio compactado, como MP4, instale o GStreamer e use
PullAudioInputStreamouPushAudioInputStream. Para obter mais informações, consulte Como usar áudio de entrada compactada.
Clean up resources (Limpar recursos)
Você pode usar o portal do Azure ou a CLI (Interface de Linha de Comando) do Azure para remover o recurso de Fala criado.
Pacote de documentação | de referência (download) | Exemplos adicionais no GitHub
Neste início rápido, você cria e executa um aplicativo para reconhecer e transcrever fala para texto em tempo real.
Para transcrever arquivos de áudio de forma assíncrona, consulte O que é transcrição em lote. Se você não tiver certeza de qual solução de fala para texto é ideal para você, consulte O que é fala para texto?
Pré-requisitos
- Uma subscrição do Azure. Você pode criar um gratuitamente.
- Crie um recurso de Fala no portal do Azure.
- Obtenha a chave de recurso de Fala e a região. Depois que o recurso de Fala for implantado, selecione Ir para o recurso para exibir e gerenciar chaves.
Configurar o ambiente
O Speech SDK for Swift é distribuído como um pacote de estrutura. A estrutura suporta Objective-C e Swift no iOS e macOS.
O Speech SDK pode ser usado em projetos Xcode como um CocoaPod, ou baixado diretamente e vinculado manualmente. Este guia usa um CocoaPod. Instale o gerenciador de dependência do CocoaPod conforme descrito em suas instruções de instalação.
Definir variáveis de ambiente
Você precisa autenticar seu aplicativo para acessar os serviços de IA do Azure. Este artigo mostra como usar variáveis de ambiente para armazenar suas credenciais. Em seguida, você pode acessar as variáveis de ambiente do seu código para autenticar seu aplicativo. Para produção, use uma maneira mais segura de armazenar e acessar suas credenciais.
Importante
Recomendamos a autenticação do Microsoft Entra ID com identidades gerenciadas para recursos do Azure para evitar o armazenamento de credenciais com seus aplicativos executados na nuvem.
Se você usar uma chave de API, armazene-a com segurança em outro lugar, como no Cofre de Chaves do Azure. Não inclua a chave da API diretamente no seu código e nunca a publique publicamente.
Para obter mais informações sobre segurança de serviços de IA, consulte Autenticar solicitações para serviços de IA do Azure.
Para definir as variáveis de ambiente para sua chave de recurso de fala e região, abra uma janela de console e siga as instruções para seu sistema operacional e ambiente de desenvolvimento.
- Para definir a variável de ambiente, substitua
SPEECH_KEYsua chave por uma das chaves do seu recurso. - Para definir a variável de ambiente, substitua
SPEECH_REGIONsua região por uma das regiões do seu recurso.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota
Se você só precisar acessar as variáveis de ambiente no console atual, poderá definir a variável de ambiente com set em vez de setx.
Depois de adicionar as variáveis de ambiente, talvez seja necessário reiniciar todos os programas que precisam ler as variáveis de ambiente, incluindo a janela do console. Por exemplo, se você estiver usando o Visual Studio como editor, reinicie o Visual Studio antes de executar o exemplo.
Reconhecer voz a partir de um microfone
Siga estas etapas para reconhecer a fala em um aplicativo macOS.
Clone o repositório Azure-Samples/cognitive-services-speech-sdk para obter o projeto de exemplo Reconhecer fala de um microfone no Swift no macOS . O repositório também tem amostras do iOS.
Navegue até o diretório do aplicativo de exemplo baixado (
helloworld) em um terminal.Execute o comando
pod install. Este comando gera um espaço dehelloworld.xcworkspacetrabalho Xcode contendo o aplicativo de exemplo e o SDK de fala como uma dependência.Abra o
helloworld.xcworkspaceespaço de trabalho no Xcode.Abra o arquivo chamado AppDelegate.swift e localize os
applicationDidFinishLaunchingmétodos erecognizeFromMicconforme mostrado aqui.import Cocoa @NSApplicationMain class AppDelegate: NSObject, NSApplicationDelegate { var label: NSTextField! var fromMicButton: NSButton! var sub: String! var region: String! @IBOutlet weak var window: NSWindow! func applicationDidFinishLaunching(_ aNotification: Notification) { print("loading") // load subscription information sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"] label = NSTextField(frame: NSRect(x: 100, y: 50, width: 200, height: 200)) label.textColor = NSColor.black label.lineBreakMode = .byWordWrapping label.stringValue = "Recognition Result" label.isEditable = false self.window.contentView?.addSubview(label) fromMicButton = NSButton(frame: NSRect(x: 100, y: 300, width: 200, height: 30)) fromMicButton.title = "Recognize" fromMicButton.target = self fromMicButton.action = #selector(fromMicButtonClicked) self.window.contentView?.addSubview(fromMicButton) } @objc func fromMicButtonClicked() { DispatchQueue.global(qos: .userInitiated).async { self.recognizeFromMic() } } func recognizeFromMic() { var speechConfig: SPXSpeechConfiguration? do { try speechConfig = SPXSpeechConfiguration(subscription: sub, region: region) } catch { print("error \(error) happened") speechConfig = nil } speechConfig?.speechRecognitionLanguage = "en-US" let audioConfig = SPXAudioConfiguration() let reco = try! SPXSpeechRecognizer(speechConfiguration: speechConfig!, audioConfiguration: audioConfig) reco.addRecognizingEventHandler() {reco, evt in print("intermediate recognition result: \(evt.result.text ?? "(no result)")") self.updateLabel(text: evt.result.text, color: .gray) } updateLabel(text: "Listening ...", color: .gray) print("Listening...") let result = try! reco.recognizeOnce() print("recognition result: \(result.text ?? "(no result)"), reason: \(result.reason.rawValue)") updateLabel(text: result.text, color: .black) if result.reason != SPXResultReason.recognizedSpeech { let cancellationDetails = try! SPXCancellationDetails(fromCanceledRecognitionResult: result) print("cancelled: \(result.reason), \(cancellationDetails.errorDetails)") print("Did you set the speech resource key and region values?") updateLabel(text: "Error: \(cancellationDetails.errorDetails)", color: .red) } } func updateLabel(text: String?, color: NSColor) { DispatchQueue.main.async { self.label.stringValue = text! self.label.textColor = color } } }No AppDelegate.m, use as variáveis de ambiente que você definiu anteriormente para sua chave de recurso de fala e região.
sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"]Para alterar o idioma de reconhecimento de fala, substitua
en-USpor outro idioma suportado. Por exemplo, usees-ESpara espanhol (Espanha). Se você não especificar um idioma, o padrão seráen-US. Para obter detalhes sobre como identificar um dos vários idiomas que podem ser falados, consulte Identificação de idioma.Para tornar visível a saída de depuração, selecione View>Debug Area>Activate Console.
Crie e execute o código de exemplo selecionando Executar produto>no menu ou selecionando o botão Reproduzir.
Importante
Certifique-se de definir as
SPEECH_KEYvariáveis eSPEECH_REGIONde ambiente. Se você não definir essas variáveis, o exemplo falhará com uma mensagem de erro.
Depois de selecionar o botão no aplicativo e dizer algumas palavras, você verá o texto que você falou na parte inferior da tela. Quando você executa o aplicativo pela primeira vez, ele solicita que você dê ao aplicativo acesso ao microfone do seu computador.
Observações
Este exemplo usa a operação para transcrever enunciados de até 30 segundos ou até que o recognizeOnce silêncio seja detetado. Para obter informações sobre o reconhecimento contínuo de áudio mais longo, incluindo conversas multilingues, consulte Como reconhecer voz.
Objective-C
O SDK de Fala para Objective-C compartilha bibliotecas de cliente e documentação de referência com o SDK de Fala para Swift. Para obter exemplos de código Objective-C, consulte o projeto de exemplo reconhecer fala de um microfone em Objective-C no macOS no GitHub.
Clean up resources (Limpar recursos)
Você pode usar o portal do Azure ou a CLI (Interface de Linha de Comando) do Azure para remover o recurso de Fala criado.
Referência | da API REST de fala para texto API REST de fala para texto para referência | de áudio curta Exemplos adicionais no GitHub
Neste início rápido, você cria e executa um aplicativo para reconhecer e transcrever fala para texto em tempo real.
Para transcrever arquivos de áudio de forma assíncrona, consulte O que é transcrição em lote. Se você não tiver certeza de qual solução de fala para texto é ideal para você, consulte O que é fala para texto?
Pré-requisitos
- Uma subscrição do Azure. Você pode criar um gratuitamente.
- Crie um recurso de Fala no portal do Azure.
- Obtenha a chave de recurso de Fala e a região. Depois que o recurso de Fala for implantado, selecione Ir para o recurso para exibir e gerenciar chaves.
Você também precisa de um arquivo de áudio .wav em sua máquina local. Você pode usar seu próprio arquivo .wav até 60 segundos ou baixar o arquivo de https://crbn.us/whatstheweatherlike.wav exemplo.
Definir variáveis de ambiente
Você precisa autenticar seu aplicativo para acessar os serviços de IA do Azure. Este artigo mostra como usar variáveis de ambiente para armazenar suas credenciais. Em seguida, você pode acessar as variáveis de ambiente do seu código para autenticar seu aplicativo. Para produção, use uma maneira mais segura de armazenar e acessar suas credenciais.
Importante
Recomendamos a autenticação do Microsoft Entra ID com identidades gerenciadas para recursos do Azure para evitar o armazenamento de credenciais com seus aplicativos executados na nuvem.
Se você usar uma chave de API, armazene-a com segurança em outro lugar, como no Cofre de Chaves do Azure. Não inclua a chave da API diretamente no seu código e nunca a publique publicamente.
Para obter mais informações sobre segurança de serviços de IA, consulte Autenticar solicitações para serviços de IA do Azure.
Para definir as variáveis de ambiente para sua chave de recurso de fala e região, abra uma janela de console e siga as instruções para seu sistema operacional e ambiente de desenvolvimento.
- Para definir a variável de ambiente, substitua
SPEECH_KEYsua chave por uma das chaves do seu recurso. - Para definir a variável de ambiente, substitua
SPEECH_REGIONsua região por uma das regiões do seu recurso.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Nota
Se você só precisar acessar as variáveis de ambiente no console atual, poderá definir a variável de ambiente com set em vez de setx.
Depois de adicionar as variáveis de ambiente, talvez seja necessário reiniciar todos os programas que precisam ler as variáveis de ambiente, incluindo a janela do console. Por exemplo, se você estiver usando o Visual Studio como editor, reinicie o Visual Studio antes de executar o exemplo.
Reconhecer a voz a partir de um ficheiro
Abra uma janela do console e execute o seguinte comando cURL. Substitua YourAudioFile.wav pelo caminho e nome do arquivo de áudio.
curl --location --request POST "https://%SPEECH_REGION%.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed" ^
--header "Ocp-Apim-Subscription-Key: %SPEECH_KEY%" ^
--header "Content-Type: audio/wav" ^
--data-binary "@YourAudioFile.wav"
Importante
Certifique-se de definir as SPEECH_KEY variáveis e SPEECH_REGION de ambiente. Se você não definir essas variáveis, o exemplo falhará com uma mensagem de erro.
Você deve receber uma resposta semelhante à que é mostrada aqui. O DisplayText deve ser o texto que foi reconhecido a partir do seu arquivo de áudio. O comando reconhece até 60 segundos de áudio e converte-o em texto.
{
"RecognitionStatus": "Success",
"DisplayText": "My voice is my passport, verify me.",
"Offset": 6600000,
"Duration": 32100000
}
Para obter mais informações, consulte API REST de fala para texto para áudio curto.
Clean up resources (Limpar recursos)
Você pode usar o portal do Azure ou a CLI (Interface de Linha de Comando) do Azure para remover o recurso de Fala criado.
Neste início rápido, você cria e executa um aplicativo para reconhecer e transcrever fala para texto em tempo real.
Para transcrever arquivos de áudio de forma assíncrona, consulte O que é transcrição em lote. Se você não tiver certeza de qual solução de fala para texto é ideal para você, consulte O que é fala para texto?
Pré-requisitos
- Uma subscrição do Azure. Você pode criar um gratuitamente.
- Crie um recurso de Fala no portal do Azure.
- Obtenha a chave de recurso de Fala e a região. Depois que o recurso de Fala for implantado, selecione Ir para o recurso para exibir e gerenciar chaves.
Configurar o ambiente
Siga estas etapas e consulte o início rápido da CLI de fala para obter outros requisitos para sua plataforma.
Execute o seguinte comando da CLI do .NET para instalar a CLI de fala:
dotnet tool install --global Microsoft.CognitiveServices.Speech.CLIExecute os comandos a seguir para configurar sua chave de recurso de fala e região. Substitua
SUBSCRIPTION-KEYpela chave de recurso de Fala e substituaREGIONpela região de recurso de Fala.spx config @key --set SUBSCRIPTION-KEY spx config @region --set REGION
Reconhecer voz a partir de um microfone
Execute o seguinte comando para iniciar o reconhecimento de fala a partir de um microfone:
spx recognize --microphone --source en-USFale no microfone e verá a transcrição das suas palavras em texto em tempo real. A CLI de fala para após um período de silêncio, 30 segundos, ou quando você seleciona Ctrl+C.
Connection CONNECTED... RECOGNIZED: I'm excited to try speech to text.
Observações
Aqui estão algumas outras considerações:
Para reconhecer a fala de um arquivo de áudio, use
--fileem vez de--microphone. Para arquivos de áudio compactado, como MP4, instale o GStreamer e use--formato . Para obter mais informações, consulte Como usar áudio de entrada compactada.spx recognize --file YourAudioFile.wav spx recognize --file YourAudioFile.mp4 --format anyPara melhorar a precisão de reconhecimento de palavras ou enunciados específicos, use uma lista de frases. Você inclui uma lista de frases em linha ou com um arquivo de texto junto com o
recognizecomando:spx recognize --microphone --phrases "Contoso;Jessie;Rehaan;" spx recognize --microphone --phrases @phrases.txtPara alterar o idioma de reconhecimento de fala, substitua
en-USpor outro idioma suportado. Por exemplo, usees-ESpara espanhol (Espanha). Se você não especificar um idioma, o padrão seráen-US.spx recognize --microphone --source es-ESPara reconhecimento contínuo de áudio superior a 30 segundos, anexe
--continuous:spx recognize --microphone --source es-ES --continuousExecute este comando para obter informações sobre mais opções de reconhecimento de fala, como entrada e saída de arquivo:
spx help recognize
Clean up resources (Limpar recursos)
Você pode usar o portal do Azure ou a CLI (Interface de Linha de Comando) do Azure para remover o recurso de Fala criado.