Provisionar a análise em escala na nuvem
Processo de implantação da zona de aterrissagem de gerenciamento de dados
A equipe de operações da plataforma de dados é responsável pela implantação de uma zona de aterrissagem de gerenciamento de dados. A zona de aterragem de gestão de dados deve ter o seu próprio repositório, mantido pela equipa de operações da plataforma de dados.
Atenção
Crie e implante uma zona de aterrissagem de gerenciamento de dados antes que qualquer zona de aterrissagem de dados seja implantada.
Processo de implantação da zona de aterrissagem de dados
As equipes podem usar modelos fornecidos pela equipe de operações da plataforma de dados para evitar começar do zero para cada ativo. Recomendamos um padrão de bifurcação para automatizar a implantação de uma nova zona de pouso.
Por exemplo, uma equipa de operações de zona de aterragem de dados solicita uma nova zona de aterragem de dados usando uma ferramenta de gestão de TI ou Power Apps. Após a aprovação da solicitação, inicie o seguinte fluxo de trabalho usando parâmetros da solicitação:
- Implante uma nova assinatura para a nova zona de aterrissagem de dados.
- Fork a ramificação principal do modelo de zona de aterrissagem de dados para criar um novo repositório.
- Crie uma conexão de serviço no novo repositório.
- Atualize os parâmetros no novo repositório com base nos parâmetros da solicitação.
- Crie um pipeline de implantação para implantar os serviços, acionado pelo check-in dos parâmetros atualizados.
- Notifique a equipe de operações da zona de pouso de dados de que a nova zona de pouso está disponível.
A equipe de operações da zona de aterrissagem de dados agora pode alterar ou adicionar modelos do Azure Resource Manager.
Esse fluxo de trabalho pode ser automatizado usando vários conjuntos de serviços na plataforma Azure. Manipule algumas das etapas, como renomear parâmetros em arquivos de parâmetros, usando pipelines de CI/CD. Outras etapas podem ser executadas usando outras ferramentas de orquestração de fluxo de trabalho, como Aplicativos Lógicos.
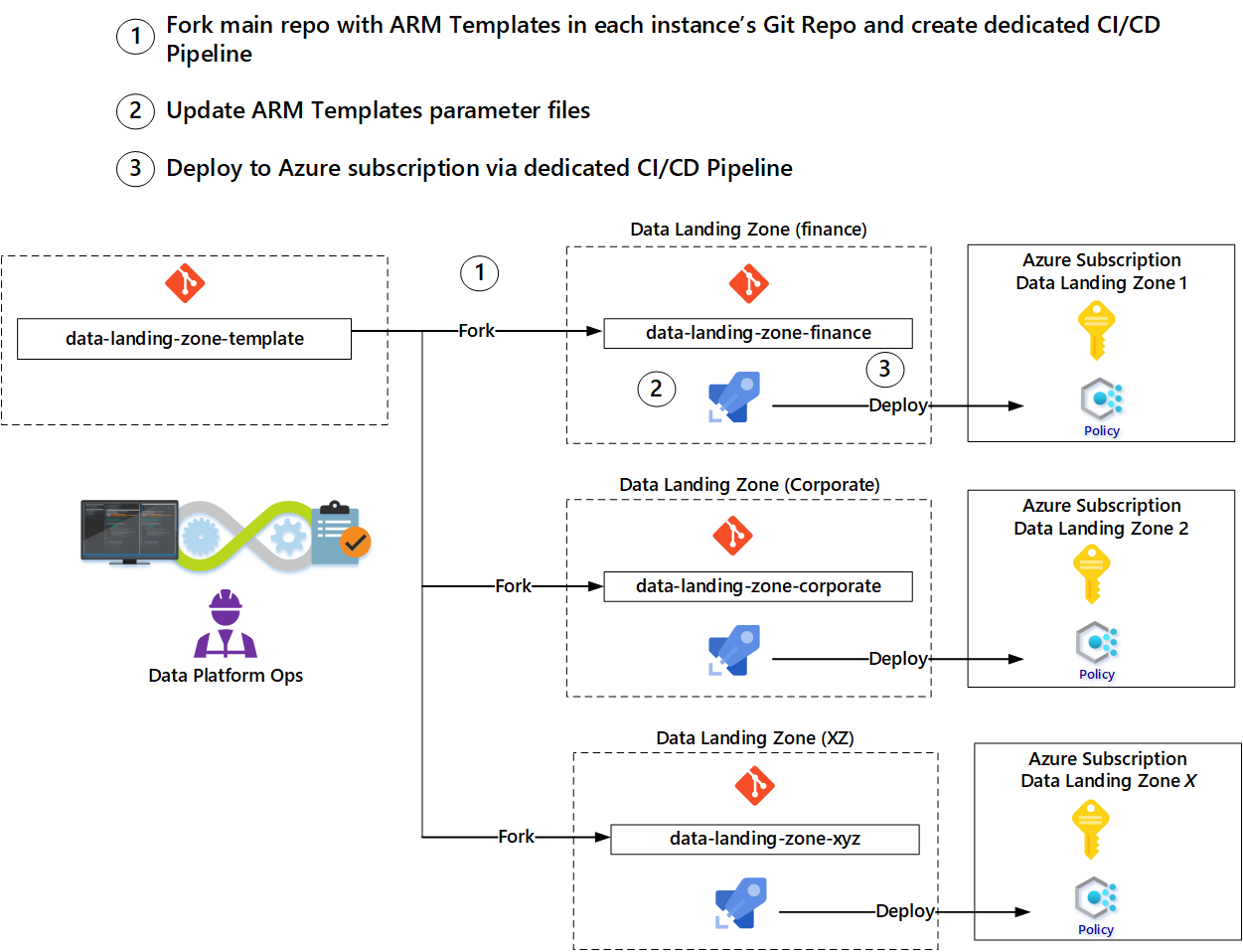
O padrão de bifurcação permite que as equipes atualizem seus modelos a partir dos modelos originais usados para bifurcá-los. Além disso, se melhorias ou novos recursos forem implementados nos repositórios de modelos, as equipas de operações poderão integrá-los no seu fork.
Adotar práticas recomendadas para repositórios, como:
- Proteja a filial principal.
- Utilize ramos para alterações, atualizações e melhorias.
- Defina os proprietários de código que aprovam solicitações pull antes de mesclar as alterações na ramificação principal.
- Valide ramificações por meio de testes automatizados.
- Limite o número de ações e pessoas na equipe, como quem pode acionar pipelines de compilação e lançamento.
Dica
Coordene atividades entre equipes para garantir que melhorias ou novos recursos nos modelos originais sejam replicados em todas as instâncias da zona de aterrissagem de dados. As equipes de operações podem puxar as alterações de modelo originais para a bifurcação.
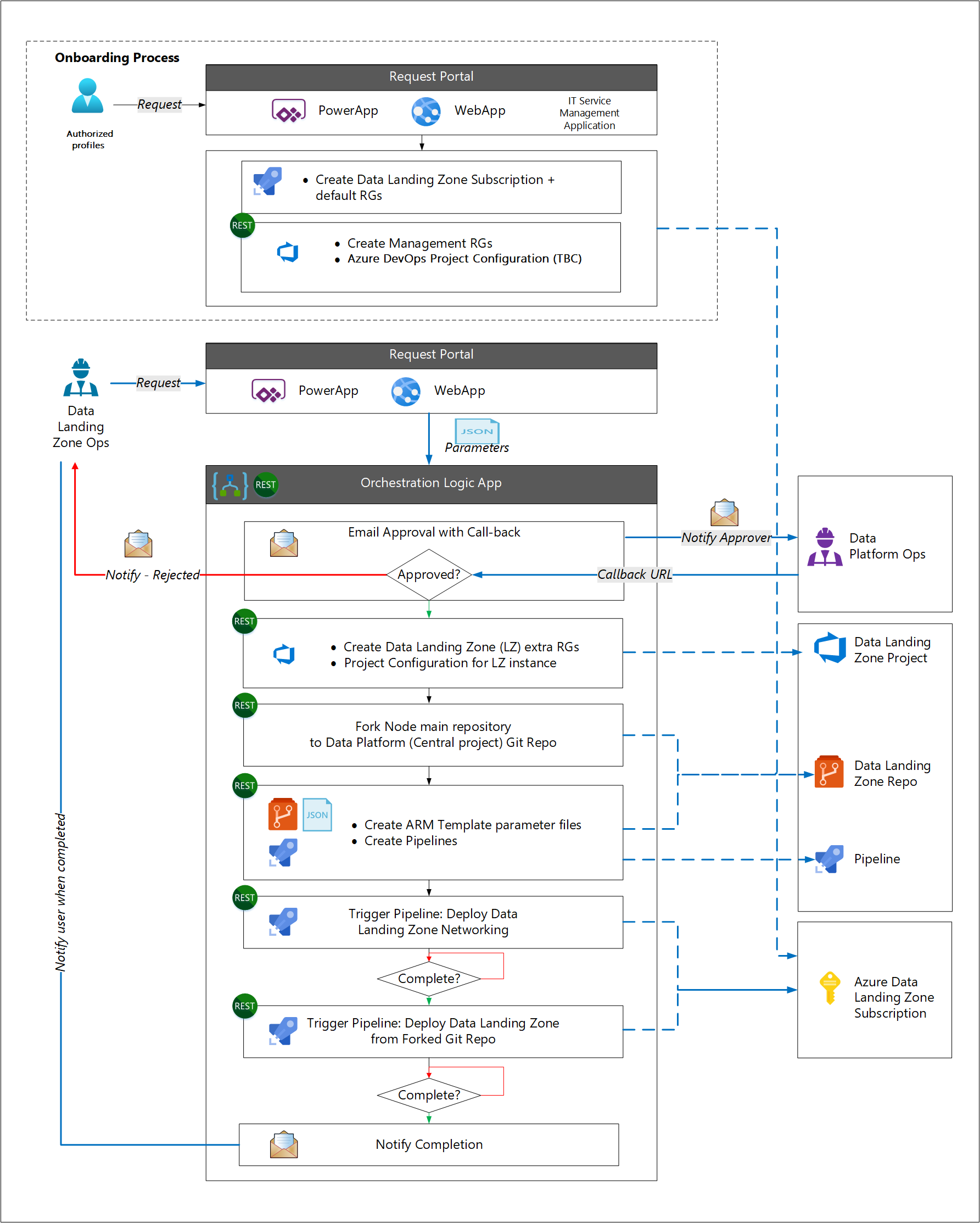
O processo de integração inicial é separado do processo de implementação da zona de aterrissagem de dados. Essa separação é baseada na suposição de que a maioria das organizações tem um processo de implantação de assinatura padrão do Azure como parte de seu modelo operacional de nuvem. O processo de integração implanta componentes corporativos padrão (como uma ferramenta de gerenciamento de serviços de TI de terceiros). Os componentes específicos da zona de aterrissagem de dados são implantados em seguida.
Não há APIs Git disponíveis para clonar/atualizar/confirmar/enviar na solução de automação proposta. Portanto, a nossa abordagem é usar uma conta do Azure Automation contendo runbooks do PowerShell que:
- Configurar uma zona de aterrissagem de dados
- Faça um fork do repositório principal para um repositório de plataforma de dados Git
- Configurar as configurações de sub-rede para a zona de aterrissagem de dados
- Configurar o Microsoft Entra ID
Os runbooks usam funções Git do módulo GitAutomation PowerShell para trabalhar com repositórios Git. Ao instalar este módulo dentro de uma conta de Automação do Azure, os usuários podem fazer operações de criação, clonagem, consulta, push, pull e commit em repositórios Git. A imagem a seguir mostra o módulo GitAutomation instalado dentro de uma conta de Automação do Azure:

Use a função Copy-GitRepository do módulo GitAutomation para clonar o repositório Git principal da URL especificada pelo URL para o caminho Git da plataforma de dados especificado pelo DestinationPath.
Essa abordagem para a implantação da zona de aterrissagem de dados é flexível, ao mesmo tempo em que garante que as ações estejam em conformidade com os requisitos organizacionais. O gerenciamento do ciclo de vida é habilitado pela aplicação de novos recursos ou otimizações dos modelos originais.
Processo de implantação de aplicativos de dados
Após a criação de uma zona de aterragem de dados, a integração pode ser iniciada para as equipas de aplicações de dados. As equipes de operações da plataforma de dados ou da zona de aterrissagem de dados concedem aprovação de implantação.
A implantação é feita diretamente usando ferramentas de DevOps ou chamada por meio de pipelines/fluxos de trabalho expostos como APIs. Semelhante à zona de aterrissagem de dados, a implantação começa com a bifurcação do repositório original do aplicativo de dados.
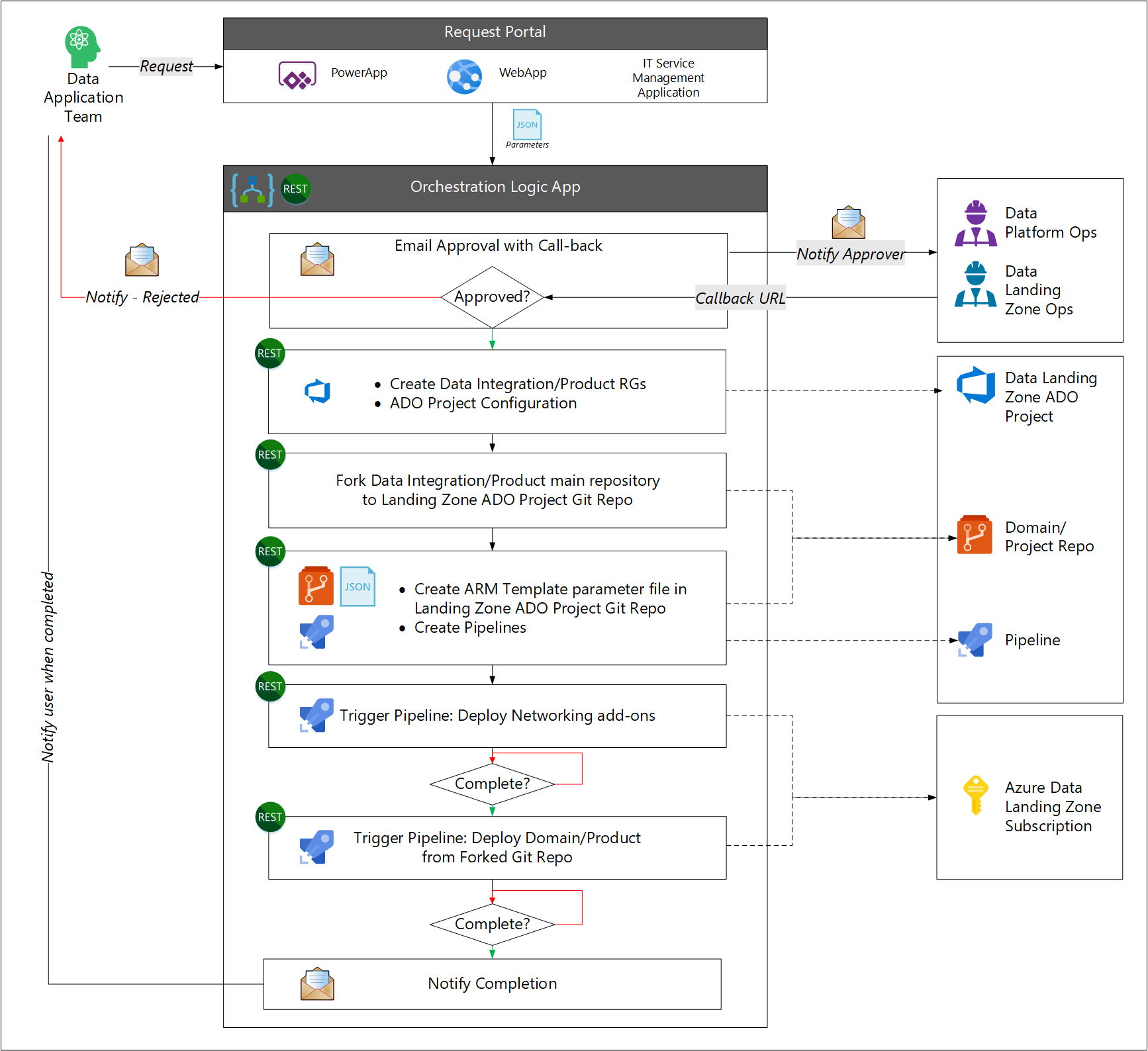
- O usuário faz uma solicitação para novos serviços de aplicativo de dados.
- O processo de fluxo de trabalho solicita aprovação da plataforma de dados ou da equipe de operações da zona de aterrissagem de dados.
- O fluxo de trabalho chama a API de gerenciamento de serviços de TI para criar os grupos de recursos necessários e a criação de uma conexão de serviço do Azure DevOps. O fluxo de trabalho atribui uma equipe ao projeto Azure DevOps.
- O fluxo de trabalho bifurca o repositório de aplicativos de dados original para criar o projeto de destino do Azure DevOps.
- O fluxo de trabalho cria um ficheiro de parâmetros do modelo do Azure Resource Manager e configura pipelines.
- Em seguida, o fluxo de trabalho inicia um pipeline do Azure para criar os requisitos de rede e outro pipeline do Azure para implantar os serviços de aplicativo de dados.
- O fluxo de trabalho notifica o utilizador após a conclusão.
Dica
Se você é novo no DataOps, revise o DataOps para o data warehouse moderno laboratório prático no Centro de Arquitetura do Azure. O cenário do laboratório descreve um escritório de planejamento urbano fictício que pode usar essa solução de implantação. A solução de implantação fornece um pipeline de dados de ponta a ponta que segue o padrão de arquitetura de data warehouse moderno, juntamente com os processos correspondentes de DevOps e DataOps, para avaliar o uso do estacionamento e tomar decisões de negócios informadas.
Resumo
Os padrões acima fornecem controle, agilidade, autosserviço e gerenciamento do ciclo de vida das políticas.
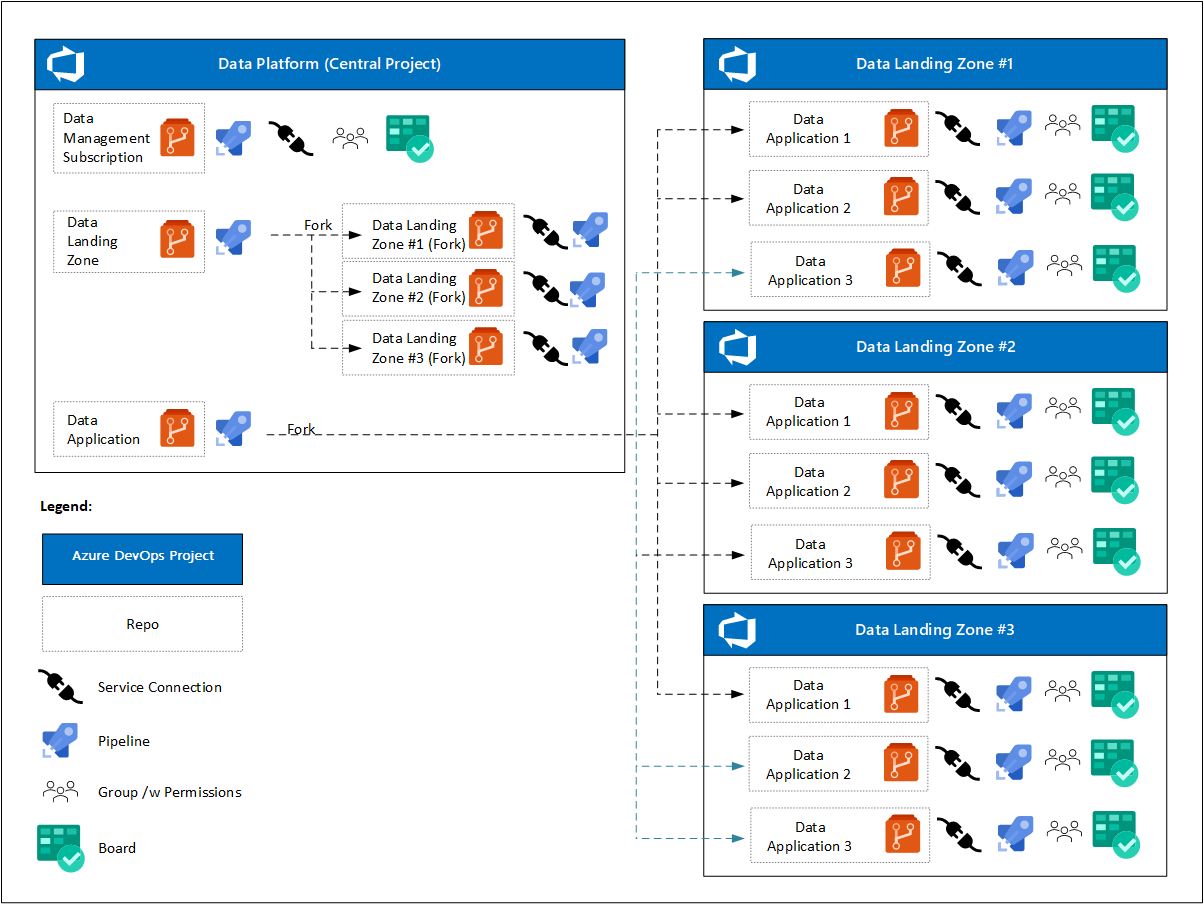
No início do projeto, a plataforma de dados tem um projeto de DevOps do Azure com um ou mais Painéis do Azure. As equipes individuais de DevOps se concentram em:
- Um repositório para a zona de aterrissagem de gerenciamento de dados, pipelines e uma conexão de serviço com o ambiente de nuvem.
- Um repositório de modelos para a zona de aterrissagem de dados, pipelines para implantar uma instância de zona de aterrissagem de dados e conexões de serviço para ambientes de nuvem.
- Um repositório de modelos para serviços de produtos de dados, pipelines para implantar uma instância de produto de dados e conexões de serviço para ambientes de nuvem. Essas conexões são bifurcadas da zona de receção de dados do Azure DevOps Projects.
Após a implantação das zonas de aterrissagem de dados, a análise em escala de nuvem prescreve que:
- Cada zona de aterrissagem de dados terá seu próprio projeto de DevOps do Azure com um ou mais Painéis do Azure.
- Para cada aplicativo de dados, sua zona de aterrissagem de dados Azure DevOps project fork é criada após a aprovação da solicitação.
- Cada aplicação de dados inclui:
- Uma conexão de serviço.
- Um pipeline registado.
- Uma equipe de DevOps com acesso ao quadro e repositório do Azure.
- Um conjunto diferente de políticas para o repositório bifurcado.
Para controlar a implantação de aplicativos de dados, siga estas práticas:
- A equipa de operações da zona de pouso de dados é responsável por e protege o ramo principal do repositório.
- Somente a ramificação principal é usada para implantar em ambientes de teste e produção.
- As ramificações de funcionalidades podem ser implantadas em ambientes de desenvolvimento.
- As ramificações de funcionalidade são de propriedade das equipas de DataOps. Eles são usados para testar recursos novos ou modificados.
- As equipas de DataOps podem mesclar ramos funcionais em outros ramos funcionais sem aprovação.
- As equipas de DataOps criam um pedido de pull para integrar as ramificações de funcionalidades na ramificação principal, e a equipa de operações da zona de entrada de dados fornece aprovação.
- Novos recursos ou melhorias para os modelos originais são integrados no repositório ramificado para mantê-los atualizados.