Visão geral dos grupos de failover - práticas recomendadas & - Instância Gerenciada SQL do Azure
Aplica-se a:![]() Instância Gerida do SQL do Azure
Instância Gerida do SQL do Azure
- Base de Dados SQL do Azure
- da Instância Gerenciada SQL do Azure
O recurso de grupos de failover permite gerenciar a replicação e o failover de todos os bancos de dados de usuários em uma instância gerenciada para outra região do Azure. Este artigo fornece uma visão geral do recurso de grupo de failover com práticas recomendadas e recomendações para usá-lo com a Instância Gerenciada SQL do Azure.
Para começar a usar o recurso, revise Configurar um grupo de failover para a Instância Gerenciada SQL do Azure.
Visão geral
O recurso de grupos de failover permite gerenciar a replicação e o failover de bancos de dados de usuários em uma instância gerenciada para uma instância gerenciada em outra região do Azure. Os grupos de failover são projetados para simplificar a implantação e o gerenciamento de bancos de dados replicados geograficamente em escala.
Para mais informações, consulte Alta disponibilidade para a Instância Gerida do Azure SQL. Para o RPO e RTO com falha de substituição geográfica, consulte a visão geral de continuidade de negócios.
Redirecionamento de ponto final
Os grupos de failover fornecem pontos finais de escuta de leitura e escrita e somente leitura, que permanecem inalterados durante os failovers geográficos. Não é necessário alterar a cadeia de conexão do seu aplicativo após um failover geográfico, porque as conexões são automaticamente roteadas para a primária atual. Um failover geográfico alterna todos os bancos de dados secundários do grupo para a função principal. Após a conclusão do failover geográfico, o registo DNS é atualizado automaticamente para redirecionar os endpoints para a nova região.
Descarregar tarefas de apenas leitura
Para reduzir o tráfego para os seus bancos de dados primários, pode também usar os bancos de dados secundários em um grupo de alternância para transferir cargas de trabalho somente de leitura. Utilize o listener de leitura apenas para direcionar o tráfego de leitura apenas para uma base de dados secundária legível.
Recuperando um aplicativo
Para alcançar a continuidade total dos negócios, adicionar redundância de banco de dados regional é apenas parte da solução. A recuperação de um aplicativo (serviço) de ponta a ponta após uma falha catastrófica requer a recuperação de todos os componentes que constituem o serviço e quaisquer serviços dependentes. Exemplos desses componentes incluem o software cliente (por exemplo, um navegador com um JavaScript personalizado), front-ends da Web, armazenamento e DNS. É fundamental que todos os componentes sejam resilientes às mesmas falhas e fiquem disponíveis dentro do RTO (Recovery Time Objetive, objetivo de tempo de recuperação) do seu aplicativo. Portanto, você precisa identificar todos os serviços dependentes e entender as garantias e capacidades que eles fornecem. Deve-se tomar as medidas adequadas para garantir que o serviço funcione durante o failover dos serviços dos quais depende.
Política de alternância em caso de falha
Os grupos de failover suportam duas políticas de failover:
-
Gerido pelo cliente (recomendado) - Os clientes podem executar um failover de um grupo quando perceberem uma interrupção inesperada a afetar um ou mais bancos de dados no grupo de failover. Ao usar ferramentas de linha de comando, como o PowerShell, a CLI do Azure ou a API REST, o valor da política de failover para o gerido pelo cliente é
manual. -
gerenciado pela Microsoft - No caso de uma interrupção generalizada que afete uma região primária, a Microsoft inicia o failover de todos os grupos de failover afetados que têm sua política de failover configurada para ser gerenciada pela Microsoft. O failover sob gestão da Microsoft não será iniciado em grupos individuais de failover ou num subconjunto de grupos de failover numa região. Ao usar ferramentas de linha de comando, como o PowerShell, a CLI do Azure ou a API Rest, o valor da política de failover para gerenciado pela Microsoft é
automatic.
Cada política de failover tem um conjunto exclusivo de casos de uso e expectativas correspondentes sobre o escopo de failover e a perda de dados, como resume a tabela a seguir:
| Política de failover | Escopo de failover | Caso de uso | Perda potencial de dados |
|---|---|---|---|
| Gerenciado pelo cliente (Recomendado) |
Grupo(s) de failover | Um ou mais bancos de dados em um grupo de failover são afetados por uma interrupção e ficam indisponíveis. Você pode optar por fazer failover. | Sim |
| Gerenciado pela Microsoft | Todos os grupos de failover na região | Uma interrupção generalizada em um datacenter, zona de disponibilidade ou região causa indisponibilidade de bancos de dados e a equipe de serviço SQL do Microsoft Azure decide acionar um failover forçado. Use essa opção somente quando quiser delegar a responsabilidade de recuperação de desastres à Microsoft e o aplicativo for tolerante ao RTO (tempo de inatividade) de pelo menos uma hora ou mais. |
Sim |
Gerenciado pelo cliente
Em raras ocasiões, a disponibilidade de integrada ou a de alta disponibilidade não é suficiente para mitigar uma interrupção, e os seus bancos de dados num grupo de failover podem estar indisponíveis por um período que não seja aceitável para o contrato de nível de serviço (SLA) das aplicações que usam os bancos de dados. Os bancos de dados podem estar indisponíveis devido a um problema localizado que afeta apenas alguns bancos de dados, ou podem estar no datacenter, na zona de disponibilidade ou no nível da região. Em qualquer um desses casos, para restaurar a continuidade dos negócios, você pode iniciar um failover forçado.
Definir sua política de failover como gerenciada pelo cliente é altamente recomendável, pois mantém você no controle de quando iniciar um failover e restaurar a continuidade dos negócios. Você pode iniciar um failover quando notar uma interrupção inesperada afetando um ou mais bancos de dados no grupo de failover.
Gerenciado pela Microsoft
Com uma política de failover gerenciada pela Microsoft, a responsabilidade pela recuperação de desastres é delegada ao serviço SQL do Azure. Para que o serviço SQL do Azure inicie um failover forçado, as seguintes condições devem ser atendidas:
- Datacenter, zona de disponibilidade ou interrupção no nível da região causada por um evento de desastre natural, alterações de configuração, bugs de software ou falhas de componentes de hardware e muitos bancos de dados na região são afetados.
- O período de carência expirou. Como a verificação da escala e a mitigação da interrupção dependem de ações humanas, o período de carência não pode ser definido abaixo de uma hora.
Quando essas condições são atendidas, o serviço SQL do Azure inicia failovers forçados para todos os grupos de failover na região que têm a política de failover definida como gerenciada pela Microsoft.
Importante
Use a política de failover gerenciada pelo cliente para testar e implementar seu plano de recuperação de desastres. Não confie no failover gerenciado pela Microsoft, que só pode ser executado pela Microsoft em circunstâncias extremas. Um failover gerenciado pela Microsoft seria iniciado para todos os grupos de failover na região que têm a política de failover definida como gerenciada pela Microsoft. Não pode ser iniciado para grupo de failover individual. Se você precisar da capacidade de fazer failover seletivamente em seu grupo de failover, use a política de failover gerenciada pelo cliente.
Defina a política de failover para ser gerida pela Microsoft apenas quando:
- Você deseja delegar a responsabilidade de recuperação de desastres ao serviço SQL do Azure.
- O aplicativo é tolerante a que seu banco de dados fique indisponível por pelo menos uma hora ou mais.
- É aceitável acionar failovers forçados algum tempo após o período de carência expirar, pois o tempo efetivo de um failover forçado pode variar significativamente.
- É aceitável que todos os bancos de dados dentro do grupo de failover façam failover, independentemente da configuração de redundância de zona ou do status de disponibilidade. Embora os bancos de dados configurados para redundância de zona sejam resilientes a falhas zonais e possam não ser afetados por uma interrupção, eles ainda serão submetidos a failover se fizerem parte de um grupo de failover com uma política de failover gerenciada pela Microsoft.
- É aceitável realizar failovers forçados de bases de dados no grupo de failover sem ter em conta a dependência da aplicação de outros serviços ou componentes do Azure utilizados pela aplicação, o que pode causar uma degradação do desempenho ou indisponibilidade da aplicação.
- É aceitável incorrer em uma quantidade desconhecida de perda de dados, pois o tempo exato do failover forçado não pode ser controlado e ignora o status de sincronização dos bancos de dados secundários.
- Todos os bancos de dados primários e secundários no grupo de failover e quaisquer relações de replicação geográfica possuem a mesma camada de serviço e camada de computação (provisionada ou serverless) com tamanho de computação & (DTUs ou vCores). Se os SLOs (objetivos de nível de serviço) de todos os bancos de dados não coincidirem, a política de failover será alterada mais tarde de gerido pela Microsoft para gerido pelo cliente por meio do Azure SQL.
Quando um failover é acionado pela Microsoft, uma entrada para o nome da operação failover do grupo de failover do Azure SQL é adicionada ao log de atividades do Azure Monitor. A entrada inclui o nome do grupo de failover sob Recurso, e Evento iniciado por exibe um único hífen (-) para indicar que o failover foi iniciado pela Microsoft. Essas informações também podem ser encontradas na página Log de atividades do novo servidor primário ou instância no portal do Azure.
Terminologia e capacidades
Grupo de tolerância a falhas (FOG)
Um grupo de failover permite que todos os bancos de dados de usuários em uma instância gerenciada façam failover como uma unidade para outra região do Azure caso a instância gerenciada primária fique indisponível devido a uma interrupção da região primária. Como os grupos de failover para Instância Gerenciada SQL contêm todos os bancos de dados de usuário dentro da instância, apenas um grupo de failover pode ser configurado em uma instância.
Importante
O nome do grupo de failover deve ser único a nível global dentro do domínio
.database.windows.net.Primária
A instância gerida que aloja os bancos de dados primários no grupo de recuperação.
Secundária
A instância gerenciada que hospeda os bancos de dados secundários no grupo de failover. O secundário não pode estar na mesma região do Azure que o principal.
Importante
Se um banco de dados contiver objetos OLTP na memória, a instância de réplica geográfica primária e secundária deverá ter camadas de serviço correspondentes, pois os objetos OLTP na memória residem na memória. Uma camada de serviço mais baixa na instância de réplica geográfica pode resultar em problemas de falta de memória. Se isso ocorrer, a réplica secundária pode não conseguir recuperar o banco de dados, causando a indisponibilidade do banco de dados secundário juntamente com os objetos OLTP na memória no geo-secundário. Isso, por sua vez, pode fazer com que o failover também não seja bem-sucedido. Para evitar isso, verifique se a camada de serviço da instância geosecundária corresponde à do banco de dados primário. As atualizações da camada de serviço podem ser operações que exigem o processamento de grandes volumes de dados e podem demorar algum tempo a finalizar.
Failover (sem perda de dados)
O failover executa a sincronização completa de dados entre bancos de dados primários e secundários antes que o secundário alterne para a função principal. Isso garante que não haja perda de dados. O failover só é possível quando o primário está acessível. O mecanismo de failover é usado nos seguintes cenários:
- Execute exercícios de recuperação de desastres (DR) na produção quando a perda de dados não for aceitável
- Realocar a carga de trabalho para uma região diferente
- Retornar a carga de trabalho para a região primária após a interrupção ter sido atenuada (failback)
Failover forçado (perda potencial de dados)
O failover forçado alterna imediatamente o secundário para a função principal sem esperar que as alterações recentes se propaguem a partir da principal. Esta operação pode resultar em perda potencial de dados. O failover forçado é usado como um método de recuperação durante interrupções quando o principal não está acessível. Quando a interrupção for atenuada, o primário antigo se reconectará automaticamente e se tornará um novo secundário. Um failover pode ser executado para failback, retornando as réplicas para suas funções primárias e secundárias originais.
Período de carência com perda de dados
Como os dados são replicados para o secundário usando replicação assíncrona, o failover forçado de grupos com políticas de failover gerenciadas pela Microsoft pode resultar em perda de dados. Você pode personalizar a política de failover para refletir a tolerância do seu aplicativo à perda de dados. Ao configurar
GracePeriodWithDataLossHours, você pode controlar quanto tempo o serviço SQL do Azure aguarda antes de iniciar um failover forçado, o que pode resultar em perda de dados.
zona DNS
Uma ID exclusiva que é gerada automaticamente quando uma nova Instância Gerenciada SQL é criada. Um certificado de vários domínios (SAN) para esta instância é provisionado para autenticar as conexões de cliente para qualquer instância na mesma zona DNS. As duas instâncias gerenciadas no mesmo grupo de failover devem compartilhar a zona DNS.
Ouvinte de leitura/gravação do grupo de failover
Um registro DNS CNAME que aponta para o primário atual. Ele é criado automaticamente quando o grupo de failover é criado e permite que as cargas de trabalho de leitura e gravação se reconectem de forma transparente ao primário quando este for alterado após o failover. Quando o grupo de failover é criado numa Instância Gerida SQL, o registo CNAME DNS para a URL do ouvinte é formado como
<fog-name>.<zone_id>.database.windows.net.Ouvinte somente leitura do grupo de failover
Um registro DNS CNAME que aponta para o secundário atual. Criado automaticamente quando o grupo de failover é criado, permite que a carga de trabalho SQL só de leitura se conecte de forma transparente ao secundário quando este é alterado após o failover. Quando o grupo de failover é criado em uma Instância Gerenciada SQL, o registro CNAME DNS para a URL do ouvinte é formado como
<fog-name>.secondary.<zone_id>.database.windows.net. Por padrão, o failover do ouvinte somente leitura é desabilitado, pois garante que o desempenho do primário não seja afetado quando o secundário estiver offline. No entanto, isso também significa que as sessões somente leitura não poderão se conectar até que o secundário seja recuperado. Se não conseguires tolerar o tempo de inatividade das sessões somente leitura e puderes usar a instância primária para tráfego somente leitura e leitura-escrita à custa de uma potencial degradação do desempenho da primária, podes ativar a comutação por erro para o listener somente leitura ao configurar a propriedadeAllowReadOnlyFailoverToPrimary. Nesse caso, o tráfego de leitura apenas é automaticamente redirecionado para o primário se o secundário não estiver disponível.Observação
A propriedade
AllowReadOnlyFailoverToPrimarysó terá efeito se a política de failover gerenciada pela Microsoft estiver habilitada e um failover forçado tiver sido acionado. Nesse caso, se a propriedade estiver definida como True, a nova instância primária servirá tanto sessões de leitura-gravação quanto somente leitura.
Arquitetura de grupo de failover
O grupo de failover deve ser configurado na instância primária e o conectará à instância secundária em uma região diferente do Azure. Todos os bancos de dados de usuários na instância serão replicados para a instância secundária. Os bancos de dados do sistema, como master e msdb, não serão replicados.
O diagrama a seguir ilustra uma configuração típica de um aplicativo de nuvem com redundância geográfica usando instância gerenciada e grupo de failover:
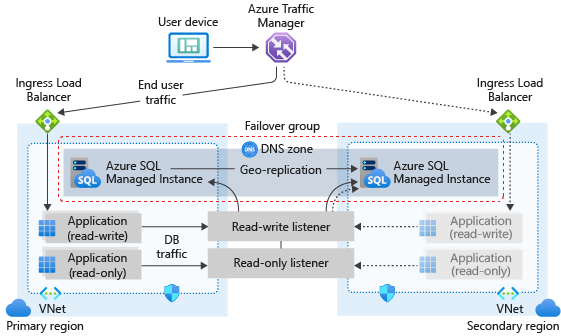
Se seu aplicativo usa a Instância Gerenciada SQL como a camada de dados, siga as diretrizes gerais e as práticas recomendadas descritas neste artigo ao projetar para continuidade de negócios.
Criar a instância geosecundária
Para garantir a conectividade ininterrupta com a Instância Gerenciada SQL primária após o failover, as instâncias primária e secundária devem estar na mesma zona DNS. Ele garante que o mesmo certificado de vários domínios (SAN) possa ser usado para autenticar conexões de cliente para qualquer uma das duas instâncias no grupo de failover. Quando seu aplicativo estiver pronto para implantação de produção, crie uma Instância Gerenciada SQL secundária em uma região diferente e verifique se ela compartilha a zona DNS com a Instância Gerenciada SQL primária. Você pode fazer isso especificando um parâmetro opcional durante a criação. Se você estiver usando o PowerShell ou a API REST, o nome do parâmetro opcional será DNSZonePartner. O nome do campo opcional correspondente no portal do Azure é Instância Gerenciada Primária.
Importante
A primeira instância gerenciada criada na sub-rede determina a zona DNS para todas as instâncias subsequentes na mesma sub-rede. Isso significa que duas instâncias da mesma sub-rede não podem pertencer a zonas DNS diferentes.
Para obter mais informações sobre como criar a Instância Gerenciada SQL secundária na mesma zona DNS que a instância primária, consulte Configurar um grupo de failover para a Instância Gerenciada SQL do Azure.
Usar regiões emparelhadas
Implante ambas as instâncias geridas nas regiões emparelhadas de por motivos de desempenho. Os grupos de failover da Instância Gerenciada SQL em regiões emparelhadas apresentam um desempenho superior em relação às não emparelhadas.
A Instância Gerenciada SQL do Azure segue uma prática de implantação segura na qual as regiões emparelhadas do Azure geralmente não são implantadas ao mesmo tempo. No entanto, não é possível prever qual região será atualizada primeiro, portanto, a ordem de implantação não é garantida. Às vezes, sua instância primária é atualizada primeiro e, às vezes, a instância secundária é atualizada primeiro.
Em situações em que a Instância Gerida do Azure SQL faz parte de um grupo de failover de e as instâncias no grupo não estão em regiões emparelhadas do Azure, selecione diferentes agendamentos de janela de manutenção para o seu banco de dados primário e secundário. Por exemplo, selecione uma janela de manutenção dias úteis para o seu banco de dados geosecundário e uma janela de manutenção de fim de semana para o seu banco de dados geoprimário.
Habilite e otimize o fluxo de tráfego de replicação geográfica entre as instâncias
A conectividade entre as sub-redes de rede virtual que hospedam a instância primária e secundária deve ser estabelecida e mantida para um fluxo de tráfego de replicação geográfica ininterrupto. Há várias maneiras de fornecer conectividade entre as instâncias que você pode escolher com base em sua topologia de rede e políticas:
de emparelhamento de rede virtual global (emparelhamento de VNet) é a maneira recomendada de estabelecer conectividade entre duas instâncias em um grupo de failover. Ele fornece uma conexão privada de baixa latência e alta largura de banda entre as redes virtuais emparelhadas usando a infraestrutura de backbone da Microsoft. Nenhuma Internet pública, gateways ou criptografia adicional é necessária na comunicação entre as redes virtuais emparelhadas.
Semeadura inicial
Ao estabelecer um grupo de failover entre instâncias gerenciadas, há uma fase inicial de propagação antes do início da replicação de dados. A fase inicial de semeadura é a parte mais longa e cara da operação. Quando a propagação inicial é concluída, os dados são sincronizados e apenas as alterações de dados subsequentes são replicadas. O tempo necessário para a conclusão da propagação inicial depende do tamanho dos dados, do número de bancos de dados replicados, da intensidade da carga de trabalho nos bancos de dados primários e da velocidade do vínculo entre as redes virtuais que hospedam a instância primária e secundária, que depende principalmente da maneira como a conectividade é estabelecida. Em circunstâncias normais, e quando a conectividade é estabelecida usando o emparelhamento de rede virtual global recomendado, a velocidade de propagação é de até 360 GB por hora para a Instância Gerenciada SQL. A semeadura é realizada para um lote de bancos de dados de usuários em paralelo - não necessariamente para todos os bancos de dados ao mesmo tempo. Vários lotes podem ser necessários se houver muitos bancos de dados hospedados na instância.
Se a velocidade da ligação entre as duas instâncias for mais lenta do que o necessário, é provável que o tempo de inicialização seja perceptivelmente afetado. Você pode usar a velocidade de propagação declarada, o número de bancos de dados, o tamanho total dos dados e a velocidade do link para estimar quanto tempo a fase inicial de propagação levará antes do início da replicação de dados. Por exemplo, para um único banco de dados de 100 GB, a fase inicial de propagação levaria cerca de 1,2 horas se o link for capaz de enviar 84 GB por hora e se não houver outros bancos de dados sendo semeados. Se o link só puder transferir 10 GB por hora, a propagação de um banco de dados de 100 GB pode levar cerca de 10 horas. Se houver vários bancos de dados para replicar, a propagação será executada em paralelo e, quando combinada com uma velocidade de link lenta, a fase inicial de propagação pode levar consideravelmente mais tempo, especialmente se a propagação paralela de dados de todos os bancos de dados exceder a largura de banda de link disponível.
Importante
No caso de um link extremamente lento ou ocupado fazer com que a fase inicial de propagação leve dias, a criação de um grupo de failover pode exceder o tempo limite. O processo de criação será automaticamente cancelado após 6 dias.
Gerenciar failover geográfico para uma instância geosecundária
O grupo de failover gerencia o failover geográfico de todos os bancos de dados na instância gerenciada primária. Quando um grupo é criado, cada banco de dados na instância será automaticamente replicado geograficamente para a instância geosecundária. Não é possível usar grupos de failover para iniciar um failover parcial de um subconjunto de bancos de dados.
Importante
Se um banco de dados for descartado na instância gerenciada primária, ele também será descartado automaticamente na instância gerenciada geosecundária.
Usar o ouvinte de leitura-gravação (MI primário)
Para cargas de trabalho de leitura-gravação, use <fog-name>.zone_id.database.windows.net como o nome do servidor. As conexões são direcionadas automaticamente para o servidor principal. Esse nome não é alterado após o failover. O failover geográfico envolve a atualização do registo DNS, para que as novas ligações de cliente sejam encaminhadas para o novo primário somente depois que o cache DNS do cliente for renovado. Como a instância secundária compartilha a zona DNS com a principal, o aplicativo cliente poderá se reconectar a ela usando o mesmo certificado SAN do lado do servidor. As conexões de cliente existentes precisam ser encerradas e, em seguida, recriadas para serem roteadas para a nova primária. O listener de leitura-gravação e o listener só de leitura não podem ser alcançados através do endpoint público para a instância gerida.
Usar o leitor de acesso apenas (MI secundário)
Se tiver cargas de trabalho somente de leitura logicamente isoladas que são tolerantes à latência de dados, pode executá-las no geo-secundário. Para conectar-se diretamente ao geo-secundário, use <fog-name>.secondary.<zone_id>.database.windows.net como o nome do servidor.
Na camada Business Critical, a Instância Gerenciada SQL oferece suporte ao uso de réplicas somente leitura para descarregar cargas de trabalho de consulta somente leitura, usando o parâmetro ApplicationIntent=ReadOnly na cadeia de conexão. Depois de configurar um secundário replicado geograficamente, você pode usar esse recurso para se conectar a uma réplica somente leitura no local primário ou no local replicado geograficamente:
- Para se conectar a uma réplica somente leitura no local principal, use
ApplicationIntent=ReadOnlye<fog-name>.<zone_id>.database.windows.net. - Para se conectar a uma réplica de leitura única na localização secundária, use
ApplicationIntent=ReadOnlye<fog-name>.secondary.<zone_id>.database.windows.net.
O ouvinte de gravação e leitura e o ouvinte somente de leitura não podem ser acessados através do ponto de extremidade público para a instância gerenciada.
Potencial degradação do desempenho após failover
Um aplicativo típico do Azure usa vários serviços do Azure e consiste em vários componentes. O failover geográfico do grupo é acionado com base apenas no estado dos componentes SQL do Azure. Outros serviços do Azure na região principal podem não ser afetados pela interrupção e seus componentes ainda podem estar disponíveis nessa região. Quando os bancos de dados primários alternam para a região secundária, a latência entre os componentes dependentes pode aumentar. Garanta a redundância de todos os componentes do aplicativo na região secundária e faça failover dos componentes do aplicativo junto com o banco de dados para que o desempenho do aplicativo não seja afetado pela maior latência entre regiões.
Perda potencial de dados após failover forçado
Se ocorrer uma interrupção na região primária, as transações recentes podem não ter sido replicadas para o geosecundário e pode haver perda de dados se um failover forçado for executado.
Atualização de DNS
A atualização do DNS do escutador de leitura e escrita acontecerá imediatamente após o processo de failover ser iniciado. Esta operação não resultará em perda de dados. No entanto, o processo de alternar funções de banco de dados pode levar até 5 minutos em condições normais. Até que algumas bases de dados na nova instância primária fiquem totalmente operacionais, ainda serão de leitura apenas. Se um failover for iniciado usando o PowerShell, a operação para alternar a função de réplica primária será síncrona. Se for iniciada usando o portal do Azure, a interface do usuário indica o status de conclusão. Se for iniciado usando a API REST, use o mecanismo de sondagem padrão do Azure Resource Manager para monitorar a conclusão.
Importante
Utilize o failover planeado manual para mover o principal de volta ao local original assim que for resolvida a interrupção que causou a falha geográfica.
Economize custos com uma réplica de DR livre de licença
Você pode economizar nos custos de licença do SQL Server configurando sua instância gerenciada secundária para ser usada apenas para recuperação de desastres (DR). Para configurar isto, consulte Configurar uma réplica de standby sem licença para Azure SQL Managed Instance.
Desde que a instância secundária não seja usada para tarefas de leitura, a Microsoft fornece uma quantidade de vCores sem custo para corresponder à instância primária. Você ainda é cobrado pela computação e armazenamento usados pela instância secundária. Os grupos de failover suportam apenas uma réplica - a réplica deve ser legível ou designada como uma réplica somente DR.
Habilitar cenários dependentes de objetos dos bancos de dados do sistema
Os bancos de dados do sistema não são replicados para a instância secundária em um grupo de failover. Para habilitar cenários que dependem de objetos dos bancos de dados do sistema, certifique-se de criar os mesmos objetos na instância secundária e mantê-los sincronizados com a instância primária.
Por exemplo, se você planeja usar os mesmos logons na instância secundária, certifique-se de criá-los com o SID idêntico.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Para saber mais, consulte Replicação de logins e tarefas de agente.
Sincronizar propriedades de instância e instâncias de políticas de retenção
As instâncias em um grupo de failover permanecem recursos separados do Azure e nenhuma alteração feita na configuração da instância primária será replicada automaticamente para a instância secundária. Certifique-se de executar todas as alterações relevantes no primário e na instância secundária. Por exemplo, se você alterar a redundância de armazenamento de backup ou a política de retenção de backup de longo prazo na instância principal, certifique-se de alterá-la também na instância secundária.
Dimensionar instâncias
Você pode aumentar ou reduzir a instância primária e secundária para um tamanho de computação diferente dentro da mesma camada de serviço ou para uma camada de serviço diferente. Ao aumentar a escala dentro da mesma camada de serviço, recomendamos que se aumente primeiro a escala do geosecundário e, em seguida, se aumente a escala do primário. Ao reduzir a escala dentro da mesma camada de serviço, inverta a ordem: reduza o primário primeiro e, em seguida, diminua o secundário. Quando você dimensiona a instância para uma camada de serviço diferente, essa recomendação é imposta. A sequência de operações é imposta ao dimensionar a camada de serviço e vCores, bem como o armazenamento.
A sequência é recomendada especificamente para evitar o problema em que o geo-secundário em um SKU mais baixo fica sobrecarregado e deve ser repropagado durante um processo de upgrade ou downgrade.
Importante
- Para instâncias dentro de um grupo de failover, não há suporte para alterar a camada de serviço para, ou de, a camada de Propósito Geral de Próxima geração. Você deve primeiro excluir o grupo de failover antes de modificar qualquer réplica e, em seguida, recriar o grupo de failover depois que a alteração entrar em vigor.
- Há um problema conhecido que pode afetar a acessibilidade da instância que está a ser escalada utilizando o ouvinte associado do grupo de failover.
Evitar a perda de dados críticos
Devido à alta latência das redes de longa distância, a replicação geográfica usa um mecanismo de replicação assíncrona. A replicação assíncrona torna inevitável a possibilidade de perda de dados se o primário falhar. Para proteger transações críticas contra perda de dados, um desenvolvedor de aplicativos pode chamar o procedimento armazenado sp_wait_for_database_copy_sync imediatamente após confirmar a transação. Chamar sp_wait_for_database_copy_sync bloqueia o encadeamento de chamada até que a última transação confirmada tenha sido transmitida e consolidada no log de transações do banco de dados secundário. No entanto, não espera pelas transações transmitidas serem reexecutadas no secundário.
sp_wait_for_database_copy_sync tem como escopo um link de replicação geográfica específico. Qualquer usuário com direitos de conexão com o banco de dados primário pode chamar este procedimento.
Para evitar a perda de dados durante o failover geográfico planeado iniciado pelo utilizador, a replicação muda automaticamente e temporariamente para replicação síncrona e, em seguida, executa um failover. Em seguida, a replicação retorna ao modo assíncrono após a conclusão do failover geográfico.
Observação
sp_wait_for_database_copy_sync evita a perda de dados após o failover geográfico para transações específicas, mas não garante a sincronização completa para acesso de leitura. O atraso causado por uma chamada de procedimento sp_wait_for_database_copy_sync pode ser significativo e depende do tamanho do log de transações que ainda não foi transmitido no sistema primário no momento da chamada.
Status do grupo de failover
O grupo de tolerância a falhas relata o seu estado, descrevendo o estado atual da replicação de dados.
- Semeadura - A de inicialização está ocorrendo após a criação do grupo de failover, até que todos os bancos de dados de utilizadores sejam inicializados na instância secundária. O processo de failover não pode ser iniciado enquanto o grupo de failover estiver no estado de Sincronização, pois os bancos de dados de utilizador ainda não foram copiados para a segunda instância.
- O estado usual do grupo de failover é a sincronização. Isso significa que as alterações de dados na instância primária estão sendo replicadas de forma assíncrona para a instância secundária. Esse status não garante que os dados estejam totalmente sincronizados a todo momento. Pode haver alterações de dados do primário que ainda precisam ser replicadas para o secundário devido à natureza assíncrona do processo de replicação entre instâncias no grupo de alternância. Os failovers automáticos e manuais podem ser iniciados enquanto o grupo de failover está no status Sincronização.
- Failover em andamento - esse status indica que o processo de failover iniciado automática ou manualmente está em andamento. Nenhuma alteração no grupo de failover ou atividades de failover adicionais podem ser iniciadas enquanto o grupo de failover estiver nesse estado.
Failback
Quando os grupos de failover são configurados com uma política de failover gerenciada pela Microsoft, o failover forçado para o servidor geosecundário é iniciado durante um cenário de desastre de acordo com o período de cortesia definido. O failback para o primário antigo deve ser iniciado manualmente.
Interoperabilidade de funcionalidades
Cópias de Segurança
Um backup completo é feito nos seguintes cenários:
- Antes do início da propagação inicial, quando você cria um grupo de failover.
- Após um failover (alternância de serviço).
Um backup completo é um tipo de operação de dados que não pode ser ignorado ou adiado e pode levar algum tempo para ser concluído. O tempo necessário para concluir depende do tamanho dos dados, do número de bancos de dados e da intensidade da carga de trabalho nos bancos de dados primários. Um backup completo pode atrasar visivelmente a propagação inicial e pode atrasar ou impedir uma operação de failover em uma nova instância logo após um failover.
Serviço de Log Replay
Os bancos de dados migrados para a Instância Gerida SQL do Azure usando o Log Replay Service (LRS) não podem ser adicionados a um grupo de failover até que a etapa de transferência seja executada. Um banco de dados migrado com o LRS está em um estado de restauração até a transferência, e os bancos de dados em um estado de restauração não podem ser adicionados a um grupo de failover. A tentativa de criar um grupo de failover com um banco de dados em um estado de restauração atrasa a criação do grupo de failover até que a restauração do banco de dados seja concluída.
Replicação transacional
Há suporte para o uso da replicação transacional com instâncias que estão em um grupo de failover. No entanto, se você configurar a replicação antes de adicionar sua instância gerenciada SQL a um grupo de failover, a replicação será pausada quando você começar a criar seu grupo de failover e o monitor de replicação mostrará um status de Replicated transactions are waiting for the next log backup or for mirroring partner to catch up. A replicação é recomeçada uma vez que o grupo de failover é criado com êxito.
Se um de editor de
Permissões e limitações
Analise uma lista de permissões e limitações antes de configurar um grupo de failover.
Gerencie grupos de failover programaticamente
Os grupos de failover também podem ser gerenciados programaticamente usando o Azure PowerShell, a CLI do Azure e a API REST. Consulte para configurar o grupo de contingência e saiba mais.
Exercícios de recuperação de desastres
A maneira recomendada de executar uma simulação de DR é usando o failover manual planejado, de acordo com o seguinte tutorial: Teste de failover.
Executar uma perfuração usando failover forçado não é recomendado, pois essa operação não fornece proteções contra a perda de dados. No entanto, é possível obter failover forçado sem perda de dados garantindo que as seguintes condições sejam atendidas antes de iniciar o failover forçado:
- A carga de trabalho é interrompida na instância gerenciada principal.
- Todas as transações de longa duração foram concluídas.
- Todas as conexões de cliente com a instância gerenciada primária foram desconectadas.
- O estado do grupo de failover está 'a sincronizar'.
Verifique se as duas instâncias gerenciadas trocaram de função e se o status do grupo de failover mudou de 'Failover em andamento' para 'Sincronização' antes de estabelecer conexões com a nova instância gerenciada primária e iniciar a carga de trabalho de leitura-gravação.
Para executar um failback sem perda de dados para as funções de instância gerenciadas originais, o uso de failover planejado manual em vez de failover forçado é altamente recomendado. Se for utilizado o failback forçado:
- Siga as mesmas etapas para o failover sem perda de dados.
- Espera-se um tempo de execução de failback mais longo se o failback forçado for executado logo após o failover forçado inicial ser concluído, pois terá de aguardar a conclusão das operações de backup automático pendentes na antiga instância gerida primária.
- Qualquer operação de backup automático pendente na instância gerenciada em transição da função principal para a secundária afetará a disponibilidade do banco de dados nessa instância.
- Use o status do grupo de failover para determinar se ambas as instâncias alteraram com êxito suas funções e estão prontas para aceitar conexões de cliente.
Conteúdo relacionado
- Configurar um grupo de failover
- Usar o PowerShell para adicionar uma instância gerenciada a um grupo de failover
- Configurar uma réplica em espera livre de licença para a Instância Gerida do Azure SQL
- Visão geral da continuidade de negócios com a Instância Gerenciada SQL do Azure
- Backups automatizados na Instância Gerenciada SQL do Azure
- Restaurar um banco de dados a partir de um backup no da Instância Gerenciada SQL do Azure