Acelere a análise de big data em tempo real usando o conector Spark
Aplica-se a:![]() Banco de Dados SQL do Azure Instância Gerenciada SQL
Banco de Dados SQL do Azure Instância Gerenciada SQL![]() do Azure
do Azure
Nota
A partir de setembro de 2020, esse conector não é mantido ativamente. No entanto, o Apache Spark Connector para SQL Server e Azure SQL agora está disponível, com suporte para ligações Python e R, uma interface mais fácil de usar para inserir dados em massa e muitas outras melhorias. Recomendamos vivamente que avalie e utilize o novo conector em vez deste. As informações sobre o conector antigo (esta página) são retidas apenas para fins de arquivo.
O conector Spark permite que os bancos de dados no Banco de Dados SQL do Azure, na Instância Gerenciada do SQL do Azure e no SQL Server atuem como fonte de dados de entrada ou coletor de dados de saída para trabalhos do Spark. Ele permite que você utilize dados transacionais em tempo real na análise de big data e persista os resultados para consultas ou relatórios ad hoc. Em comparação com o conector JDBC integrado, esse conector oferece a capacidade de inserir dados em massa em seu banco de dados. Ele pode superar a inserção linha a linha com desempenho 10x a 20x mais rápido. O conector Spark dá suporte à autenticação com a ID do Microsoft Entra (anteriormente Azure Ative Directory) para se conectar ao Banco de Dados SQL do Azure e à Instância Gerenciada SQL do Azure, permitindo que você conecte seu banco de dados do Azure Databricks usando sua conta do Microsoft Entra. Ele fornece interfaces semelhantes com o conector JDBC integrado. É fácil migrar seus trabalhos existentes do Spark para usar esse novo conector.
Nota
Microsoft Entra ID é o novo nome para o Azure Ative Directory (Azure AD). Estamos atualizando a documentação neste momento.
Baixe e construa um conector Spark
O repositório GitHub para o conector antigo vinculado anteriormente a partir desta página não é mantido ativamente. Em vez disso, recomendamos fortemente que você avalie e use o novo conector.
Versões oficiais suportadas
| Componente | Versão |
|---|---|
| Apache Spark | 2.0.2 ou posterior |
| Scala | 2.10 ou posterior |
| Controlador Microsoft JDBC para SQL Server | 6.2 ou posterior |
| Microsoft SQL Server | SQL Server 2008 ou posterior |
| Base de Dados SQL do Azure | Suportado |
| Instância Gerida do Azure SQL | Suportado |
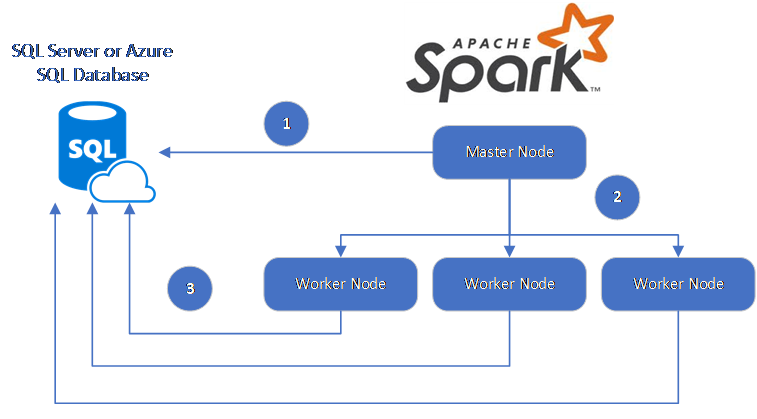
O conector Spark utiliza o Microsoft JDBC Driver for SQL Server para mover dados entre nós de trabalho do Spark e bancos de dados:
O fluxo de dados é o seguinte:
- O nó mestre do Spark se conecta a bancos de dados no Banco de dados SQL ou no SQL Server e carrega dados de uma tabela específica ou usando uma consulta SQL específica.
- O nó mestre do Spark distribui dados para nós de trabalho para transformação.
- O nó Trabalhador se conecta a bancos de dados que se conectam ao Banco de dados SQL e ao SQL Server e grava dados no banco de dados. O usuário pode optar por usar a inserção linha a linha ou a inserção em massa.
O diagrama a seguir ilustra o fluxo de dados.
Construa o conector Spark
Atualmente, o projeto de conector usa maven. Para criar o conector sem dependências, você pode executar:
- mvn pacote limpo
- Faça o download das versões mais recentes do JAR a partir da pasta de lançamento
- Incluir o JAR do SQL Database Spark
Conectar e ler dados usando o conector Spark
Você pode se conectar a bancos de dados no Banco de dados SQL e no SQL Server a partir de um trabalho do Spark para ler ou gravar dados. Você também pode executar uma consulta DML ou DDL em bancos de dados no Banco de dados SQL e no SQL Server.
Ler dados do SQL do Azure e do SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Ler dados do SQL do Azure e do SQL Server com consulta SQL especificada
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
Gravar dados no SQL do Azure e no SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Aquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
Executar consulta DML ou DDL no Azure SQL e SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
Conectar-se a partir do Spark usando a autenticação do Microsoft Entra
Você pode se conectar ao Banco de Dados SQL e à Instância Gerenciada do SQL usando a autenticação do Microsoft Entra. Use a autenticação do Microsoft Entra para gerenciar centralmente identidades de usuários de banco de dados e como uma alternativa à autenticação SQL.
Conectando-se usando o Modo de Autenticação ActiveDirectoryPassword
Requisito de configuração
Se você estiver usando o modo de autenticação ActiveDirectoryPassword, precisará fazer o download da microsoft-authentication-library-for-java e suas dependências e incluí-las no caminho de construção Java.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Conectando-se usando um token de acesso
Requisito de configuração
Se você estiver usando o modo de autenticação baseada em token de acesso, precisará fazer o download da microsoft-authentication-library-for-java e suas dependências e incluí-las no caminho de construção Java.
Consulte Usar a autenticação do Microsoft Entra para saber como obter um token de acesso ao seu banco de dados no Banco de Dados SQL do Azure ou na Instância Gerenciada SQL do Azure.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Escrever dados com a inserção em massa
O conector jdbc tradicional grava dados em seu banco de dados usando a inserção linha por linha. Você pode usar o conector Spark para gravar dados no SQL do Azure e no SQL Server usando a inserção em massa. Ele melhora significativamente o desempenho de gravação ao carregar grandes conjuntos de dados ou carregar dados em tabelas onde um índice de armazenamento de coluna é usado.
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
Próximos passos
Se ainda não o fez, baixe o conector Spark do repositório GitHub azure-sqldb-spark e explore os recursos adicionais no repositório :
Você também pode querer revisar o Apache Spark SQL, DataFrames e Datasets Guide e a documentação do Azure Databricks.