Modelo de compra vCore - Banco de Dados SQL do Azure
Aplica-se a:![]() do Banco de Dados SQL do Azure
do Banco de Dados SQL do Azure
- Base de Dados SQL do Azure
- da Instância Gerenciada SQL do Azure
Este artigo analisa o modelo de compra vCore para Azure SQL Database.
Visão geral
Um núcleo virtual (vCore) representa uma CPU lógica e oferece a opção de escolher as características físicas do hardware (por exemplo, o número de núcleos, a memória e o tamanho do armazenamento). O modelo de compra baseado em vCore oferece flexibilidade, controle, transparência do consumo de recursos individuais e uma maneira direta de traduzir os requisitos de carga de trabalho local para a nuvem. Esse modelo otimiza o preço e permite que você escolha recursos de computação, memória e armazenamento com base em suas necessidades de carga de trabalho.
No modelo de compra baseado em vCore, seus custos dependem da escolha e do uso de:
- Nível de serviço
- Configuração de hardware
- Recursos de computação (o número de vCores e a quantidade de memória)
- Armazenamento reservado de banco de dados
- Armazenamento de backup atual
Importante
Recursos de computação, E/S e armazenamento de dados e logs são cobrados por banco de dados ou pool elástico. O armazenamento de backup é cobrado por cada banco de dados. Para obter detalhes de preços, consulte a página de preços da Base de Dados SQL do Azure.
Compare os modelos de compra vCore e DTU
O modelo de compra vCore usado pelo Banco de Dados SQL do Azure fornece vários benefícios em relação ao modelo de compra baseado em DTU :
- Maiores limites de computação, memória, E/S e armazenamento.
- Escolha de configuração de hardware para melhor corresponder aos requisitos de computação e memória da carga de trabalho.
- Descontos de preços para Benefício Híbrido do Azure (AHB).
- Maior transparência nos detalhes de hardware que alimentam a computação, o que facilita o planejamento de migrações de implantações locais.
- O preço da instância reservada só está disponível para o modelo de compra baseado em vCore.
- Maior granularidade de dimensionamento com vários tamanhos de computação disponíveis.
Para obter ajuda na escolha entre os modelos de compra vCore e DTU, consulte as diferenças entre os modelos de compra baseados em vCore e DTU.
Computação
O modelo de compra baseado em vCore tem uma camada de computação provisionada e uma camada de computação sem servidor
Resumindo:
- Enquanto a camada de computação provisionada fornece uma quantidade específica de recursos de computação que são continuamente provisionados independentemente da atividade de carga de trabalho, a camada de computação sem servidor dimensiona automaticamente os recursos de computação com base na atividade da carga de trabalho.
- Enquanto a camada de computação provisionada
fatura a quantidade de computação provisionada a um preço fixo por hora, a camada de computação sem servidorfatura a quantidade de computação usada, por segundo.
Independentemente da camada de computação, três réplicas secundárias adicionais de alta disponibilidade são alocadas automaticamente na camada de serviço Business Critical para fornecer alta resiliência a falhas e failovers rápidos. Essas réplicas adicionais tornam o custo aproximadamente 2,7 vezes maior do que na camada de serviço de uso geral. Da mesma forma, o maior custo de armazenamento por GB na camada de serviço Business Critical reflete os limites de E/S mais altos e a menor latência do armazenamento SSD local.
No Hyperscale, os clientes controlam o número de réplicas adicionais de alta disponibilidade de 0 a 4 para obter o nível de resiliência exigido por seus aplicativos e, ao mesmo tempo, controlar os custos.
Para obter mais informações sobre computação no Banco de Dados SQL do Azure, consulte Recursos de computação (CPU e memória).
Limites de recursos
Para os limites de recursos do vCore, analise as configurações de hardware disponíveis e depois reveja os limites de recursos para:
Armazenamento de dados e logs
Os fatores a seguir afetam a quantidade de armazenamento usada para dados e arquivos de log e se aplicam às camadas de uso geral e críticas para os negócios.
- Cada tamanho de computação suporta um tamanho máximo de dados configurável, com um padrão de 32 GB.
- Quando você configura o tamanho máximo de dados, um extra de 30% do armazenamento faturável é adicionado automaticamente para o arquivo de log.
- Na camada de serviço de uso geral,
tempdbusa armazenamento SSD local e esse custo de armazenamento está incluído no preço do vCore. - Na camada de serviço Business Critical, o
tempdbpartilha o armazenamento SSD local com os dados e os arquivos de log, e o custo de armazenamento detempdbestá incluído no preço do vCore. - Nos níveis de uso geral e crítico para os negócios, você é cobrado pelo tamanho máximo de armazenamento configurado para um banco de dados ou pool elástico.
- Para o Banco de dados SQL, você pode selecionar qualquer tamanho máximo de dados entre 1 GB e o tamanho máximo de armazenamento suportado, em incrementos de 1 GB.
As seguintes considerações de armazenamento se aplicam ao Hyperscale:
- O tamanho máximo de armazenamento de dados está definido como 128 TB e não é configurável.
- Você é cobrado apenas pelo armazenamento de dados alocado, não pelo armazenamento máximo de dados.
- Você não será cobrado pelo armazenamento de logs.
-
tempdbusa armazenamento SSD local e seu custo está incluído no preço do vCore. Para monitorizar o tamanho atual do armazenamento de dados alocado e usado no SQL Database, use as métricas allocated_data_storage e storage do Azure Monitor , respetivamente.
Para monitorizar o tamanho atual de armazenamento alocado e utilizado de ficheiros individuais de dados e de log numa base de dados usando T-SQL, use a visualização sys.database_files e a função FILEPROPERTY(... , 'SpaceUsed').
Dica
Em algumas circunstâncias, talvez seja necessário reduzir um banco de dados para recuperar espaço não utilizado. Para obter mais informações, consulte Gerenciar espaço de arquivo no Banco de Dados SQL do Azure.
Armazenamento de backup
O armazenamento para backups de banco de dados é alocado para dar suporte às capacidades de restauração point-in-time (PITR) e às capacidades de retenção de longo prazo (LTR) do Banco de Dados SQL. Esse armazenamento é separado do armazenamento de dados e arquivos de log e é cobrado separadamente.
- PITR: Nas camadas de uso geral e crítica para os negócios, os backups de banco de dados individuais são copiados para de armazenamento do Azure automaticamente. O tamanho do armazenamento aumenta dinamicamente à medida que novos backups são criados. O armazenamento é utilizado para backups completos, diferenciais e de log transacional. O consumo de armazenamento depende da taxa de alteração do banco de dados e do período de retenção configurado para backups. Você pode configurar um período de retenção separado para cada banco de dados entre 1 e 35 dias para o Banco de dados SQL. Uma quantidade de armazenamento de backup igual ao tamanho máximo de dados configurado é fornecida sem custo extra.
- LTR: Você também pode configurar a retenção de longo prazo de backups completos por até 10 anos. Se você configurar uma política LTR, esses backups serão armazenados no armazenamento de Blob do Azure automaticamente, mas você poderá controlar a frequência com que os backups serão copiados. Para atender a diferentes requisitos de conformidade, você pode selecionar diferentes períodos de retenção para backups semanais, mensais e/ou anuais. A configuração escolhida determina quanto armazenamento é usado para backups LTR. Para obter mais informações, consulte retenção de backup de longo prazo.
Para armazenamento de backup em Hyperscale, consulte Backups automatizados para bancos de dados Hyperscale.
Níveis de serviço
As opções da camada de serviço no modelo de compra vCore incluem Propósito Geral, Crítica para os Negócios e Hiperescala. A camada de serviço geralmente determina o tipo e o desempenho de armazenamento, as opções de alta disponibilidade e recuperação de desastres e a disponibilidade de determinados recursos, como In-Memory OLTP.
| Caso de uso | Uso Geral | Crítico para o Negócio | de hiperescala |
|---|---|---|---|
| Melhor para | A maioria das cargas de trabalho empresariais. Oferece opções de computação e armazenamento orientadas para o orçamento, equilibradas e escaláveis. | Oferece aos aplicativos de negócios a mais alta resiliência a falhas usando várias réplicas secundárias de alta disponibilidade e oferece o mais alto desempenho de E/S. | A maior variedade de cargas de trabalho, incluindo aquelas com requisitos de armazenamento e escala de leitura altamente escaláveis. Oferece maior resiliência a falhas, permitindo a configuração de mais de uma réplica secundária de alta disponibilidade. |
| Calcular tamanho | 2 a 128 vCores | 2 a 128 vCores | 2 a 128 vCores |
| Tipo de armazenamento | Armazenamento remoto premium (por instância) | Armazenamento local super-rápido em SSD (por instância) | Armazenamento desacoplado com cache de unidade de estado sólido local (por réplica de computação) |
| Tamanho de armazenamento | 1 GB – 4 TB | 1 GB – 4 TB | 10 GB – 128 TB |
| IOPS | 320 IOPS por vCore com 16.000 IOPS máximas | 4.000 IOPS por vCore com 327.680 IOPS máximas | 327.680 IOPS com SSD local máximo A hiperescala é uma arquitetura multicamadas com cache em vários níveis. IOPS eficazes dependem da carga de trabalho. |
| Memória/vCore | 5,1 GB | 5,1 GB | 5,1 GB ou 10,2 GB |
| Cópias de Segurança | Uma opção de armazenamento de backup com redundância geográfica, com redundância de zona ou com redundância local, retenção de 1 a 35 dias (padrão de 7 dias) Retenção de longo prazo disponível até 10 anos |
Uma opção de armazenamento de backup com redundância geográfica, com redundância de zona ou com redundância local, retenção de 1 a 35 dias (padrão de 7 dias) Retenção de longo prazo disponível até 10 anos |
Uma opção de armazenamento com redundância local (LRS), com redundância de zona (ZRS) ou com redundância geográfica (GRS) Retenção de 1 a 35 dias (7 dias por padrão), com até 10 anos de retenção de longo prazo disponíveis |
| Disponibilidade | Uma réplica, sem réplicas em escala de leitura, alta disponibilidade (HA) com redundância de zona |
Três réplicas, uma réplica para leitura em escala, alta disponibilidade (HA) com redundância de zona |
alta disponibilidade (HA) com redundância de zona |
| Preços/Faturação |
vCore, armazenamento reservado e armazenamento de backup são cobrados. As IOPS não são cobradas. |
vCore, armazenamento reservado e armazenamento de backup são cobrados. As IOPS não são cobradas. |
vCore para cada réplica e o armazenamento usado são cobrados. As IOPS não são cobradas. |
| Modelos de desconto |
Reservas do Azure Benefício Híbrido do Azure (não disponível em assinaturas de desenvolvimento/testes) Subscrições da oferta Enterprise e Pay-As- Dev/TestYou-Go |
Reservas do Azure Benefício Híbrido do Azure (não disponível em assinaturas de desenvolvimento/testes) Subscrições da oferta Enterprise e Pay-As- Dev/TestYou-Go |
Benefício Híbrido do Azure (não disponível em subscrições de desenvolvimento/teste) 1 Subscrições da oferta Enterprise e Pay-As- Dev/TestYou-Go |
| Tabelas OLTP na memória | Não | Sim | Não |
1 Preços simplificados para o SQL Database Hyperscale em breve. Revise o blog de preços do Hyperscale para obter detalhes.
Para obter mais detalhes, reveja os limites de recursos para o servidor lógico , bancos de dados únicos , e bancos de dados em pool .
Observação
Para obter mais informações sobre o Contrato de Nível de Serviço (SLA), consulte SLA para o Banco de Dados SQL do Azure
Finalidade Geral
O modelo de arquitetura para a camada de serviço de uso geral é baseado em uma separação de computação e armazenamento. Esse modelo de arquitetura depende da alta disponibilidade e confiabilidade do armazenamento de Blob do Azure que replica arquivos de banco de dados de forma transparente e garante que não haja perda de dados se ocorrer uma falha na infraestrutura subjacente.
A figura a seguir mostra quatro nós no modelo de arquitetura padrão com as camadas de computação e armazenamento separadas.
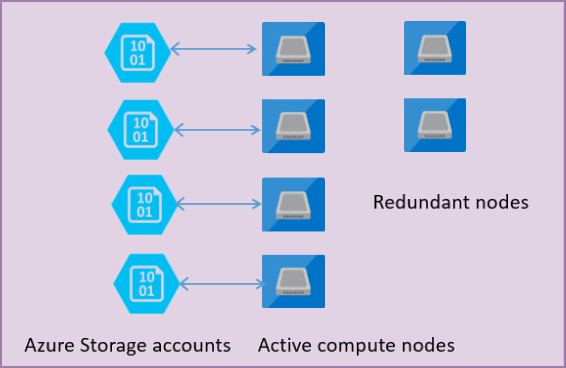
No modelo de arquitetura para a camada de serviço de uso geral, há duas camadas:
- Uma camada de computação sem estado que está a executar o processo
sqlservr.exee contém apenas dados transitórios e em cache (por exemplo, cache de plano, pool de buffers, pool de colunas). Esse nó sem estado é operado pelo Azure Service Fabric que inicializa o processo, controla a integridade do nó e realiza a transferência para outro local, se necessário. - Uma camada de dados com estado com arquivos de banco de dados (.mdf/.ldf) armazenados no armazenamento de Blob do Azure. O armazenamento de Blob do Azure garante que não haja perda de dados de nenhum registro colocado em qualquer arquivo de banco de dados. O Armazenamento do Azure tem disponibilidade/redundância de dados interna que garante que todos os registros no arquivo de log ou página no arquivo de dados sejam preservados, mesmo se o processo falhar.
Sempre que o mecanismo de banco de dados ou o sistema operacional é atualizado, alguma parte da infraestrutura subjacente falha ou, se algum problema crítico é detectado no processo de sqlservr.exe, o Azure Service Fabric move o processo sem estado para outro nó de computação sem estado. Há um conjunto de nós sobressalentes que está à espera de executar um novo serviço de cálculo se ocorrer uma falha do nó primário, para minimizar o tempo de recuperação. Os dados na camada de armazenamento do Azure não são afetados e os arquivos de dados/log são anexados ao processo recém-inicializado. Este processo garante 99,99% de disponibilidade por padrão e 99,995% de disponibilidade quando a redundância de zona está habilitada. Pode haver alguns impactos no desempenho de cargas de trabalho pesadas que estão em voo devido ao tempo de transição e ao fato de que o novo nó começa com cache frio.
Quando escolher esta camada de serviço
A camada de serviço de Propósito Geral é a camada de serviço padrão no Banco de Dados SQL do Azure projetada para a maioria das cargas de trabalho genéricas. Se você precisar de um mecanismo de banco de dados totalmente gerenciado com um SLA padrão e latência de armazenamento entre 5 ms e 10 ms, a camada de uso geral é a opção para você.
Negócios Críticos
O modelo de camada de serviço Crítica para os Negócios é baseado em um cluster de processos do mecanismo de banco de dados. Esse modelo de arquitetura depende de um quórum de nós do motor de base de dados para minimizar o impacto no desempenho da sua carga de trabalho, mesmo durante as atividades de manutenção. Atualizações e patches do sistema operacional subjacente, drivers e do mecanismo de banco de dados ocorrem de forma transparente, com tempo de inatividade mínimo para os usuários finais.
No modelo Business Critical, a computação e o armazenamento são integrados em cada nó. A replicação de dados entre processos do mecanismo de banco de dados em cada nó de um cluster de quatro nós garante alta disponibilidade, com cada nó usando SSD de estado sólido conectado localmente como armazenamento de dados. O diagrama a seguir mostra como o nível de serviço Business Critical organiza um cluster de nós do mecanismo de base de dados em réplicas de grupos de disponibilidade.

Tanto o processo do mecanismo de banco de dados quanto os arquivos .mdf/.ldf subjacentes são colocados no mesmo nó com armazenamento SSD conectado localmente, proporcionando baixa latência à sua carga de trabalho. A alta disponibilidade é implementada usando tecnologia semelhante aos grupos de disponibilidade do SQL Server Always On. Cada banco de dados é um cluster de nós de banco de dados com uma réplica primária acessível para cargas de trabalho de clientes e três réplicas secundárias contendo cópias de dados. A réplica primária envia constantemente alterações para as réplicas secundárias para garantir que os dados estejam disponíveis nas réplicas secundárias se a primária falhar por qualquer motivo. O failover é tratado pelo Service Fabric e pelo mecanismo de banco de dados – uma réplica secundária se torna a principal e uma nova réplica secundária é criada para garantir que haja nós suficientes no cluster. A carga de trabalho é redirecionada automaticamente para a nova réplica primária.
Além disso, o cluster Business Critical tem uma capacidade interna de expansão de leitura que fornece uma réplica somente leitura gratuita, usada para executar consultas de leitura (como relatórios) que não afetarão o desempenho do seu trabalho na réplica principal.
Quando escolher esta camada de serviço
A camada de serviço Business Critical foi projetada para aplicativos que exigem respostas de baixa latência do armazenamento SSD subjacente (1-2 ms em média), recuperação mais rápida se a infraestrutura subjacente falhar ou precisam descarregar relatórios, análises e consultas somente leitura para a réplica secundária legível gratuita do banco de dados primário.
Os principais motivos pelos quais você deve escolher a camada de serviço Crítica para os Negócios em vez da camada de Uso Geral são:
- Requisitos de baixa latência de E/S – cargas de trabalho que precisam de uma resposta consistentemente rápida da camada de armazenamento (1-2 milissegundos em média) devem usar a camada crítica de negócios.
- Carga de trabalho com relatórios e consultas analíticas, onde uma réplica secundária gratuita, apenas para leitura, é suficiente.
- Maior resiliência e recuperação mais rápida de falhas. Em caso de falha do sistema, o banco de dados na instância primária é desativado e uma das réplicas secundárias se torna imediatamente o novo banco de dados primário de leitura-gravação, pronto para processar consultas.
- Proteção avançada contra corrupção de dados. Como a camada Business Critical usa réplicas de bases de dados em segundo plano, o serviço usa a reparação automática de páginas disponível com espelhamento de e grupos de disponibilidade para ajudar a mitigar danos nos dados. Se uma réplica não puder ler uma página devido a um problema de integridade de dados, uma nova cópia da página será recuperada de outra réplica, substituindo a página ilegível sem perda de dados ou tempo de inatividade do cliente. Essa funcionalidade estará disponível na camada de uso geral se o banco de dados tiver réplica geosecundária.
- Maior disponibilidade - A camada Business Critical em uma configuração de zona de multidisponibilidade fornece resiliência a falhas zonais e um SLA de maior disponibilidade.
- de recuperação geográfica rápida - Quando de replicação geográfica ativa é configurada, a camada crítica de negócios tem um RPO (Recovery Point Objetive, objetivo de ponto de recuperação) garantido de 5 segundos e um RTO (Recovery Time Objetive, objetivo de tempo de recuperação) de 30 segundos por 100% de horas implantadas.
Hiperescala
A camada de serviço Hyperscale é adequada para todos os tipos de carga de trabalho. Sua arquitetura nativa da nuvem fornece computação e armazenamento escaláveis de forma independente para suportar a maior variedade de aplicativos tradicionais e modernos. Os recursos de computação e armazenamento em Hyperscale excedem substancialmente os recursos disponíveis nas camadas de uso geral e crítica para os negócios.
Para saber mais, consulte a camada de serviço Hiperescala para o Banco de Dados SQL do Azure .
Quando escolher esta camada de serviço
A camada de serviço Hyperscale remove muitos dos limites práticos tradicionalmente vistos em bancos de dados em nuvem. Onde a maioria dos outros bancos de dados é limitada pelos recursos disponíveis em um único nó, os bancos de dados na camada de serviço Hyperscale não têm esses limites. Com sua arquitetura de armazenamento flexível, um banco de dados Hyperscale cresce conforme necessário - e você é cobrado apenas pela capacidade de armazenamento usada.
Além de seus recursos avançados de dimensionamento, o Hyperscale é uma ótima opção para qualquer carga de trabalho, não apenas para grandes bancos de dados. Com o Hyperscale, você pode:
- Obtenha alta resiliência e rápida recuperação de falhas, controlando o custo e escolhendo o número de réplicas de alta disponibilidade de 0 a 4.
- Melhore a alta disponibilidade de habilitando a redundância de zona para computação e armazenamento.
- Obtenha baixa latência de E/S (1-2 milissegundos em média) para a parte acessada com frequência do seu banco de dados. Para bancos de dados menores, isso pode se aplicar a todo o banco de dados.
- Implemente uma grande variedade de cenários de expansão de leitura com réplicas nomeadas.
- Aproveite o escalamento rápido de , sem esperar que os dados sejam copiados para o armazenamento local em novos nós.
- Aproveite o backup contínuo de base de dados sem impacto e a restauração rápida .
- Suporte os requisitos de continuidade de negócios usando grupos de failover e replicação geográfica.
Configuração de hardware
As configurações de hardware comuns no modelo vCore incluem séries padrão (Gen5), séries Fsv2 e DC. O Hyperscale também oferece uma opção para hardware otimizado de série premium e para memória de série premium. A configuração de hardware define limites de computação e memória e outras características que afetam o desempenho da carga de trabalho.
Certas configurações de hardware, como a série padrão (Gen5), podem usar mais de um tipo de processador (CPU), conforme descrito em Recursos de computação (CPU e memória). Embora um determinado banco de dados ou pool elástico tenda a permanecer no hardware com o mesmo tipo de CPU por um longo tempo (geralmente por vários meses), há certos eventos que podem fazer com que um banco de dados ou pool seja movido para hardware que usa um tipo de CPU diferente.
Um banco de dados ou pool pode ser movido para uma variedade de cenários, incluindo, entre outros, quando:
- O objetivo do serviço é alterado
- A infraestrutura atual em um datacenter está se aproximando dos limites de capacidade
- O hardware usado atualmente está sendo desativado devido ao seu fim de vida útil
- A configuração com redundância de zona está ativada, sendo movida para um hardware diferente devido à capacidade disponível.
Para algumas cargas de trabalho, uma mudança para um tipo de CPU diferente pode alterar o desempenho. O Banco de dados SQL configura o hardware com o objetivo de fornecer desempenho previsível da carga de trabalho, mesmo se o tipo de CPU mudar, mantendo as alterações de desempenho dentro de uma banda estreita. No entanto, em todo o amplo espectro de cargas de trabalho de clientes no Banco de dados SQL, e à medida que novos tipos de CPUs se tornam disponíveis, ocasionalmente é possível ver alterações mais percetíveis no desempenho, se um banco de dados ou pool for movido para um tipo de CPU diferente.
Independentemente do tipo de CPU usado, os limites de recursos para um banco de dados ou pool elástico (como o número de núcleos, memória, IOPS máximo de dados, taxa máxima de log e máximo de trabalhadores simultâneos) permanecem os mesmos enquanto o banco de dados permanecer no mesmo objetivo de serviço.
Recursos de computação (CPU e memória)
A tabela a seguir compara recursos de computação em diferentes configurações de hardware e camadas de computação:
| Configuração de hardware | Unidade Central de Processamento | Memória |
|---|---|---|
| série Standard (Gen5) |
Recursos de computação provisionados - Processadores Intel® E5-2673 v4 (Broadwell) de 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) de 2,5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)*, AMD EPYC 7763v (Milão) - Disponibilização de até 128 vCores (hyper-threaded) Computação sem servidor - Processadores Intel® E5-2673 v4 (Broadwell) de 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) de 2,5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)*, AMD EPYC 7763v (Milão) - Autoscale até 80 vCores (hyper-threaded) - A relação memória/vCore adapta-se dinamicamente à memória e ao uso da CPU com base na demanda de carga de trabalho e pode chegar a 24 GB por vCore. Por exemplo, em um determinado momento, uma carga de trabalho pode usar e ser cobrada por 240 GB de memória e apenas 10 vCores. |
Recursos de computação provisionados - 5,1 GB por vCore - Provisionamento de até 625 GB Computação sem servidor - Dimensionamento automático de até 24 GB por vCore - Dimensionamento automático até 240 GB no máximo |
| Série Fsv2 | - Processadores Intel® 8168 (Skylake) - Apresentando uma velocidade de clock turbo sustentada de 3,4 GHz e uma velocidade máxima de clock turbo de um único núcleo de 3,7 GHz. - Provisão de até 72 vCores (hyper-threaded) |
- 1,9 GB por vCore - Provisionamento de até 136 GB |
| Série DC | - Processadores Intel® Xeon® E-2288G - Inclui Intel Software Guard Extension (Intel SGX) - Provisão até 8 vCores (físico) |
4,5 GB por vCore |
* Na sys.dm_user_db_resource_governance visualização de gerenciamento dinâmico, a geração de hardware para bancos de dados usando processadores Intel® SP-8160 (Skylake) aparece como Gen6, a geração de hardware para bancos de dados usando Intel® 8272CL (Cascade Lake) aparece como Gen7 e a geração de hardware para bancos de dados usando Intel® Xeon® Platinum 8370C (Ice Lake) ou AMD® EPYC® 7763v (Milão) aparece como Gen8. Para um determinado tamanho de computação e configuração de hardware, os limites de recursos são os mesmos, independentemente do tipo de CPU (Intel Broadwell, Skylake, Ice Lake, Cascade Lake ou AMD Milan).
Para obter mais informações, consulte os limites de recursos para bancos de dados individuais e pools elásticos.
Para obter recursos e especificações de computação de banco de dados Hyperscale, consulte Recursos de computação Hyperscale.
série Standard (Gen5)
- O hardware da série padrão (Gen5) fornece recursos de computação e memória equilibrados e é adequado para a maioria das cargas de trabalho de banco de dados.
O hardware da série padrão (Gen5) está disponível em todas as regiões públicas do mundo.
Série premium de hiperescala
- As opções de hardware da série Premium usam a mais recente tecnologia de CPU e memória da Intel e AMD. A série Premium proporciona um aumento no desempenho de computação em relação ao hardware da série padrão.
- A opção da série Premium oferece um desempenho de CPU mais rápido em comparação com a série Standard e um número maior de vCores máximos.
- A opção otimizada para memória da série Premium oferece o dobro da quantidade de memória em relação à série Standard.
- Séries Standard, Premium e Premium otimizadas para memória estão disponíveis para pools elásticos Hyperscale .
Para obter mais informações, consulte o anúncio do blog da série premium Hyperscale.
Para as regiões disponíveis, consulte a disponibilidade da série premium hyperscale .
Série Fsv2
- A série Fsv2 é uma configuração de hardware otimizada para computação que oferece baixa latência da CPU e alta velocidade de clock para as cargas de trabalho mais exigentes da CPU. Semelhante às configurações de hardware da série premium Hyperscale , a série Fsv2 é alimentada pela mais recente tecnologia de CPU e memória da Intel e AMD, permitindo que os clientes aproveitem o hardware mais recente enquanto usam bancos de dados e pools elásticos na camada de serviço Geral.
- Dependendo da carga de trabalho, a série Fsv2 pode oferecer mais desempenho de CPU por vCore do que outros tipos de hardware. Por exemplo, o tamanho de instância de computação 72 vCore Fsv2 pode oferecer mais desempenho de CPU do que 80 vCores da série Standard (Gen5), a um custo mais baixo.
- O Fsv2 fornece menos memória e
tempdbpor vCore do que outro hardware, portanto, cargas de trabalho sensíveis a esses limites podem ter um desempenho melhor na série padrão (Gen5).
A série Fsv2 é suportada apenas na camada de Uso Geral. Para regiões onde a série Fsv2 está disponível, consulte de disponibilidade da série Fsv2.
Série DC
- O hardware da série DC usa processadores Intel com tecnologia Software Guard Extensions (Intel SGX).
- A série DC é necessária para Always Encrypted com enclaves seguros cargas de trabalho que exigem proteção de segurança mais forte de enclaves de hardware, em comparação com enclaves de segurança baseada em virtualização (VBS).
- A série DC foi projetada para cargas de trabalho que processam dados confidenciais e exigem recursos confidenciais de processamento de consultas, fornecidos pelo Always Encrypted com enclaves seguros.
- O hardware da série DC fornece recursos de computação e memória equilibrados.
A série DC só é suportada para computação provisionada (sem servidor não é suportada) e não suporta redundância de zona. Para regiões onde a série DC está disponível, veja a disponibilidade da série DC em .
Tipos de oferta do Azure suportados pela série DC
Para criar bancos de dados ou pools elásticos no hardware da série DC, a assinatura deve ser um tipo de oferta paga, incluindo Pay-As-You-Go ou Enterprise Agreement (EA). Para obter uma lista completa dos tipos de oferta do Azure suportados pela série DC, consulte ofertas atuais sem limites de gastos.
Selecionar configuração de hardware
Você pode selecionar a configuração de hardware para um banco de dados ou pool elástico no Banco de dados SQL no momento da criação. Você também pode alterar a configuração de hardware de um banco de dados existente ou pool elástico.
Para selecionar uma configuração de hardware ao criar um Banco de Dados SQL ou pool
Para obter informações detalhadas, consulte Criar um banco de dados SQL.
Na guia Noções básicas, selecione o link Configurar banco de dados na seção Computação + armazenamento, e depois selecione o link Alterar configuração:

Selecione a configuração de hardware desejada:

Para alterar a configuração de hardware de um banco de dados SQL existente ou pool
Para um banco de dados, na página Visão geral, selecione o link Camada de preços:

Para um pool, na página Visão Geral, selecione Configurar.
Siga as etapas para alterar a configuração e selecione a configuração de hardware conforme descrito nas etapas anteriores.
Disponibilidade de hardware
Para obter informações sobre hardware de geração anterior, consulte Disponibilidade de hardware de geração anterior.
série Standard (Gen5)
O hardware da série padrão (Gen5) está disponível em todas as regiões públicas do mundo.
Série premium de hiperescala
O hardware otimizado para memória da série premium e o hardware da série premium da camada de serviço Hyperscale estão disponíveis para bancos de dados únicos e pools elásticos nas seguintes regiões:
- Leste da Austrália **
- Austrália Sudeste
- Sul do Brasil **,*
- Canadá Central **
- Leste do Canadá
- Ásia Oriental
- Europa Norte **
- Europa Oeste **
- França Central
- Alemanha Centro-Oeste
- Índia Central
- Índia Sul
- Leste do Japão **
- Oeste do Japão
- Sudeste Asiático**
- Suíça Norte
- Suécia Central **,*
- Sul do Reino Unido **
- Oeste do Reino Unido *
- Central dos EUA **
- Leste dos EUA **
- Leste dos EUA 2 **
- Centro-Norte dos EUA
- Centro-Sul dos EUA
- Centro-Oeste dos EUA
- Oeste dos EUA 1
- Oeste dos EUA 2 **
- Oeste dos EUA 3 **
* O hardware otimizado para memória da série Premium não está disponível no momento.
** Inclui suporte para redundância de zona .
Série Fsv2
A série Fsv2 está disponível nas seguintes regiões:
- Austrália Central
- Austrália Central 2
- Leste da Austrália
- Austrália Sudeste
- Brasil Sul
- Canadá Central
- Ásia Oriental
- Europa Norte
- Europa Ocidental
- França Central
- Índia Central
- Coreia Central
- Coreia do Sul
- África do Sul Norte
- Sudeste Asiático
- Sul do Reino Unido
- Oeste do Reino Unido
- Leste dos EUA
- Oeste dos EUA 2
Série DC
A série DC está disponível nas seguintes regiões:
- Canadá Central
- Europa Ocidental
- Europa Norte
- Sudeste Asiático
- Sul do Reino Unido
- Oeste dos EUA
- Leste dos EUA
Caso necessite da série DC numa região atualmente sem suporte, envie uma solicitação de suporte. Na página Noções básicas, forneça o seguinte:
- Para tipo de problema, selecione Técnico.
- Forneça a assinatura desejada para o hardware. Selecione Avançar.
- Para tipo de serviço, selecione Banco de dados SQL.
- Para de Recursos , selecione Pergunta geral.
- Para Resumo, forneça a disponibilidade de hardware e a região desejadas.
- Para tipo de problema, selecione Segurança, Privacidade e Conformidade.
- Para o subtipo de problema , selecione Sempre Criptografado .

Hardware da geração anterior
Gen4
O hardware Gen4 foi desativado e está indisponível para provisionamento, escalabilidade para cima ou escalabilidade para baixo. Migre a sua base de dados para uma geração de hardware suportada, para uma ampla gama de vCore e escalabilidade de armazenamento, rede acelerada, melhor desempenho de I/O e latência mínima. Reveja as opções de hardware para bases de dados individuais e opções de hardware para pools elásticos. Para obter mais informações, consulte o suporte terminou para hardware Gen 4 no Banco de Dados SQL do Azure.