Executar consultas de análise ad hoc em vários bancos de dados (Banco de Dados SQL do Azure)
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Neste tutorial, você executa consultas distribuídas em todo o conjunto de bancos de dados de locatários para habilitar relatórios interativos ad hoc. Essas consultas podem extrair insights enterrados nos dados operacionais do dia a dia do aplicativo SaaS Wingtip Tickets. Para fazer essas extrações, implante um banco de dados de análise adicional no servidor de catálogo e use o Elastic Query para habilitar consultas distribuídas.
Neste tutorial, ficará a saber:
- Como implantar um banco de dados de relatórios ad hoc
- Como executar consultas distribuídas em todos os bancos de dados de locatários
Para concluir este tutorial, devem ser cumpridos os seguintes pré-requisitos:
- O aplicativo Wingtip Tickets SaaS Multi-tenant Database é implantado. Para implantar em menos de cinco minutos, consulte Implantar e explorar o aplicativo Wingtip Tickets SaaS Multi-tenant Database
- O Azure PowerShell está instalado. Para obter mais detalhes, veja Introdução ao Azure PowerShell
- O SQL Server Management Studio (SSMS) está instalado. Para baixar e instalar o SSMS, consulte Baixar o SQL Server Management Studio (SSMS).
Padrão de relatórios ad hoc
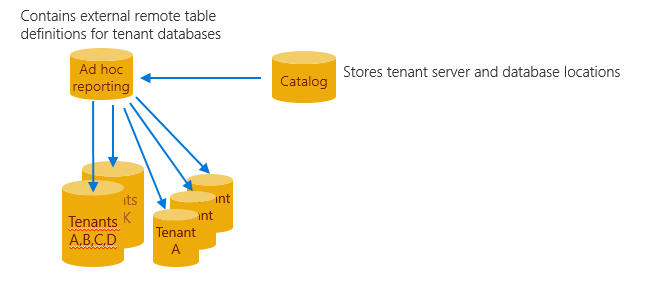
Os aplicativos SaaS podem analisar a grande quantidade de dados do locatário armazenados centralmente na nuvem. As análises revelam informações sobre a operação e o uso do seu aplicativo. Essas informações podem orientar o desenvolvimento de recursos, melhorias de usabilidade e outros investimentos em seus aplicativos e serviços.
Aceder a estes dados numa única base de dados multi-inquilinos é fácil, mas não será tão fácil se houver uma distribuição à escala através de potencialmente milhares de bases de dados. Uma abordagem é usar o Elastic Query, que permite a consulta em um conjunto distribuído de bancos de dados com esquema comum. Esses bancos de dados podem ser distribuídos em diferentes grupos de recursos e assinaturas. No entanto, um login comum deve ter acesso para extrair dados de todos os bancos de dados. O Elastic Query usa um banco de dados de cabeçalho único no qual são definidas tabelas externas que espelham tabelas ou exibições nos bancos de dados distribuídos (locatário). As consultas submetidas para esta base de dados “head” são compiladas para produzir um plano de consultas distribuídas, com partes das consultas enviadas para as bases de dados inquilinas, conforme necessário. O Elastic Query usa o mapa de estilhaços no banco de dados de catálogo para determinar o local de todos os bancos de dados de locatário. A instalação e a consulta são simples usando o Transact-SQL padrão e oferecem suporte a consultas ad hoc de ferramentas como Power BI e Excel.
Ao distribuir consultas entre os bancos de dados do locatário, o Elastic Query fornece informações imediatas sobre os dados de produção em tempo real. No entanto, como o Elastic Query extrai dados de potencialmente muitos bancos de dados, a latência da consulta às vezes pode ser maior do que para consultas equivalentes enviadas a um único banco de dados multilocatário. Certifique-se de criar consultas para minimizar os dados retornados. O Elastic Query geralmente é mais adequado para consultar pequenas quantidades de dados em tempo real, em vez de criar consultas ou relatórios analíticos complexos ou usados com freqüência. Se as consultas não tiverem um bom desempenho, examine o plano de execução para ver qual parte da consulta foi enviada para o banco de dados remoto. E avalie a quantidade de dados que estão sendo retornados. As consultas que exigem processamento analítico complexo podem ser melhor atendidas salvando os dados extraídos do locatário em um banco de dados otimizado para consultas de análise. O Banco de Dados SQL e o Azure Synapse Analytics podem hospedar esse banco de dados de análise.
Esse padrão de análise é explicado no tutorial de análise de locatário.
Obtenha o código-fonte e os scripts do aplicativo Wingtip Tickets SaaS Multi-tenant Database
Os scripts Wingtip Tickets SaaS Multi-tenant Database e o código-fonte do aplicativo estão disponíveis no repositório GitHub WingtipTicketsSaaS-MultitenantDB . Confira as orientações gerais para conhecer as etapas para baixar e desbloquear os scripts SaaS do Wingtip Tickets.
Criar dados de vendas de bilhetes
Para executar consultas em um conjunto de dados mais interessante, crie dados de vendas de tíquetes executando o gerador de tíquetes.
- No ISE do PowerShell, abra o script ...\Learning Modules\Operational Analytics\Adhoc Reporting\Demo-AdhocReporting.ps1 e defina os seguintes valores:
- $DemoScenario = 1, Compre ingressos para eventos em todos os locais.
- Pressione F5 para executar o script e gerar vendas de ingressos. Enquanto o script está em execução, continue as etapas neste tutorial. Os dados do ticket são consultados na seção Executar consultas distribuídas ad hoc, portanto, aguarde a conclusão do gerador de tíquetes .
Explore as tabelas de inquilinos
No aplicativo Wingtip Tickets SaaS Multi-tenant Database, os locatários são armazenados em um modelo de gerenciamento de locatário híbrido - onde os dados do locatário são armazenados em um banco de dados multilocatário ou em um banco de dados de locatário único e podem ser movidos entre os dois. Ao consultar todos os bancos de dados de locatário, é importante que o Elastic Query possa tratar os dados como se fizessem parte de um único banco de dados lógico fragmentado pelo locatário.
Para atingir esse padrão, todas as tabelas de locatário incluem uma coluna VenueId que identifica a qual locatário os dados pertencem. O VenueId é calculado como um hash do Nome do local, mas pode ser utilizada qualquer abordagem para introduzir um valor exclusivo para esta coluna. Essa abordagem é semelhante à maneira como a chave do locatário é calculada para uso no catálogo. As tabelas que contêm VenueId são usadas pelo Elastic Query para paralelizar consultas e enviá-las para o banco de dados de locatário remoto apropriado. Isso reduz drasticamente a quantidade de dados retornados e resulta em um aumento no desempenho, especialmente quando há vários locatários cujos dados são armazenados em bancos de dados de locatário único.
Implantar o banco de dados usado para consultas distribuídas ad hoc
Este exercício implanta o banco de dados adhocreporting . Este é o banco de dados principal que contém o esquema usado para consulta em todos os bancos de dados de locatário. O banco de dados é implantado no servidor de catálogo existente, que é o servidor usado para todos os bancos de dados relacionados ao gerenciamento no aplicativo de exemplo.
Abra ...\Learning Modules\Operational Analytics\Adhoc Reporting\Demo-AdhocReporting.ps1 no ISE do PowerShell e defina os seguintes valores:
- $DemoScenario = 2, Implantar banco de dados analítico ad hoc.
Pressione F5 para executar o script e criar o banco de dados adhocreporting .
Na próxima seção, você adiciona esquema ao banco de dados para que ele possa ser usado para executar consultas distribuídas.
Configurar o banco de dados 'head' para executar consultas distribuídas
Este exercício adiciona esquema (a fonte de dados externa e definições de tabela externa) ao banco de dados de relatórios ad hoc que permite consultar todos os bancos de dados de locatário.
Abra o SQL Server Management Studio e conecte-se ao banco de dados de relatórios Adhoc criado na etapa anterior. O nome do banco de dados é adhocreporting.
Abra ...\Learning Modules\Operational Analytics\Adhoc Reporting\ Initialize-AdhocReportingDB.sql no SSMS.
Analise o script SQL e observe o seguinte:
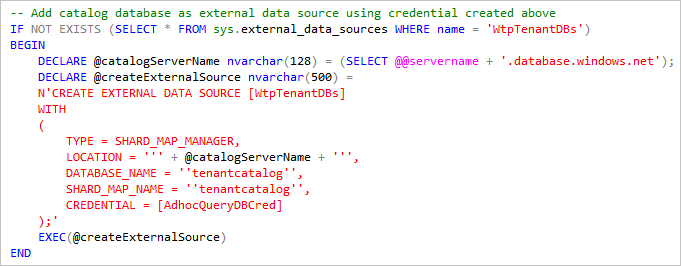
O Elastic Query usa uma credencial de escopo de banco de dados para acessar cada um dos bancos de dados de locatário. Essa credencial precisa estar disponível em todos os bancos de dados e, normalmente, deve receber os direitos mínimos necessários para permitir essas consultas ad hoc.

Usando o banco de dados de catálogo como fonte de dados externa, as consultas são distribuídas para todos os bancos de dados registrados no catálogo quando a consulta é executada. Como os nomes de servidor são diferentes para cada implantação, esse script de inicialização obtém o local do banco de dados de catálogo recuperando o servidor atual (@@servername) onde o script é executado.
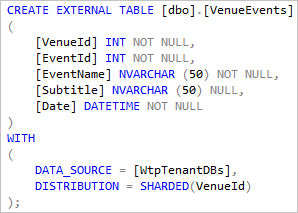
As tabelas externas que fazem referência a tabelas de locatários são definidas com DISTRIBUTION = SHARDED(VenueId). Isso roteia uma consulta para um VenueId específico para o banco de dados apropriado e melhora o desempenho para muitos cenários, conforme mostrado na próxima seção.
A tabela local VenueTypes que é criada e preenchida. Essa tabela de dados de referência é comum em todos os bancos de dados de locatário, portanto, pode ser representada aqui como uma tabela local e preenchida com os dados comuns. Para algumas consultas, isso pode reduzir a quantidade de dados movidos entre os bancos de dados do locatário e o banco de dados adhocreporting .
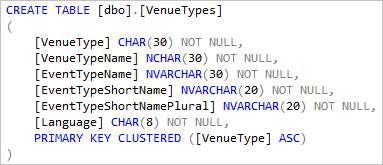
Se você incluir tabelas de referência dessa maneira, atualize o esquema e os dados da tabela sempre que atualizar os bancos de dados do locatário.
Pressione F5 para executar o script e inicializar o banco de dados adhocreporting .
Agora você pode executar consultas distribuídas e coletar informações em todos os locatários!
Executar consultas distribuídas ad hoc
Agora que o banco de dados adhocreporting está configurado, execute algumas consultas distribuídas. Inclua o plano de execução para uma melhor compreensão de onde o processamento da consulta está acontecendo.
Ao inspecionar o plano de execução, passe o mouse sobre os ícones do plano para obter detalhes.
No SSMS, abra ...\Learning Modules\Operational Analytics\Adhoc Reporting\Demo-AdhocReportingQueries.sql.
Verifique se você está conectado ao banco de dados adhocreporting .
Selecione o menu Consulta e clique em Incluir Plano de Execução Real
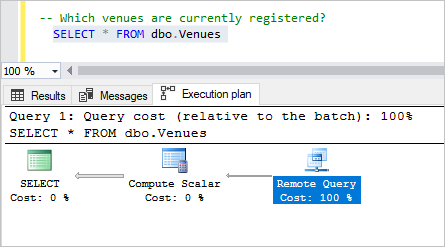
Realce a consulta Que locais estão atualmente registados? e prima F5.
A consulta retorna toda a lista de locais, ilustrando como é rápido e fácil consultar todos os locatários e retornar dados de cada locatário.
Inspecione o plano e veja que todo o custo é a consulta remota, porque estamos simplesmente indo para cada banco de dados de locatários e selecionando as informações do local.
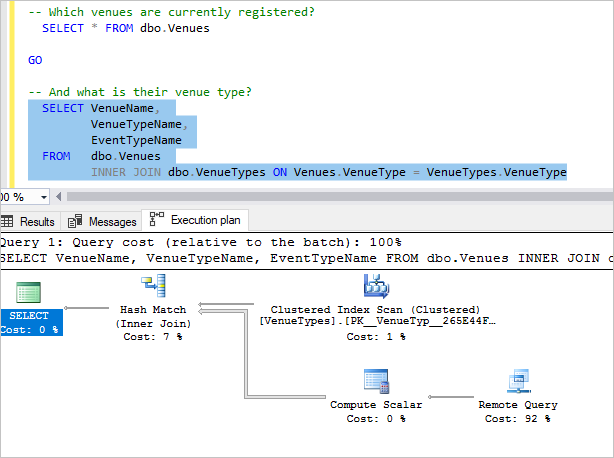
Selecione a próxima consulta e pressione F5.
Essa consulta une dados dos bancos de dados do locatário e da tabela VenueTypes local (local, pois é uma tabela no banco de dados adhocreporting).
Inspecione o plano e veja que a maior parte do custo é a consulta remota, pois consultamos as informações do local de cada locatário (dbo. Venues) e, em seguida, faça uma rápida associação local com a tabela local VenueTypes para exibir o nome amigável.
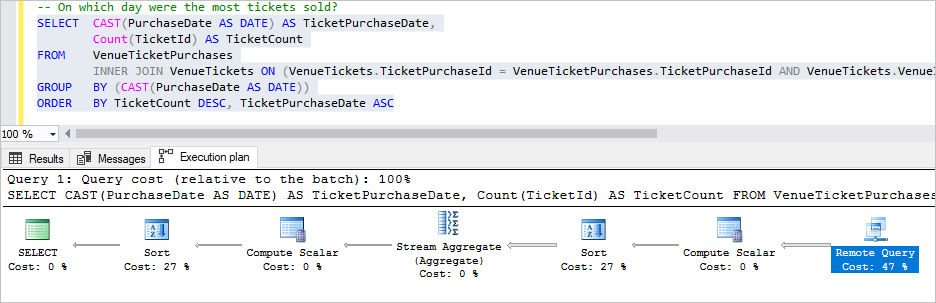
Agora selecione a consulta Em que dia foram mais vendidos os ingressos? e pressione F5.
Esta consulta faz uma junção e agregação um pouco mais complexa. O que é importante notar é que a maior parte do processamento é feito remotamente e, mais uma vez, trazemos de volta apenas as filas de que precisamos, devolvendo apenas uma única fila para a contagem agregada de venda de ingressos de cada local por dia.
Próximos passos
Neste tutorial, ficou a saber como:
- Executar consultas distribuídas em todas as bases de dados do inquilino
- Implante um banco de dados de relatórios ad hoc e adicione esquema a ele para executar consultas distribuídas.
Agora, tente o tutorial do Tenant Analytics para explorar a extração de dados para um banco de dados de análise separado para um processamento de análise mais complexo.