Tipos detetáveis de estrangulamento de desempenho de consultas na Base de Dados SQL do Azure
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Ao tentar resolver um estrangulamento no desempenho, comece por determinar se o estrangulamento ocorre enquanto a consulta está no estado de execução ou no estado de espera. Aplicam-se diferentes resoluções dependendo desta determinação. Use o diagrama a seguir para ajudar a entender os fatores que podem causar um problema relacionado à execução ou um problema relacionado à espera. Problemas e resoluções relacionados a cada tipo de problema são discutidos neste artigo.
Você pode usar o Intelligent Insights ou DMVs do SQL Server para detetar esses tipos de gargalos de desempenho.
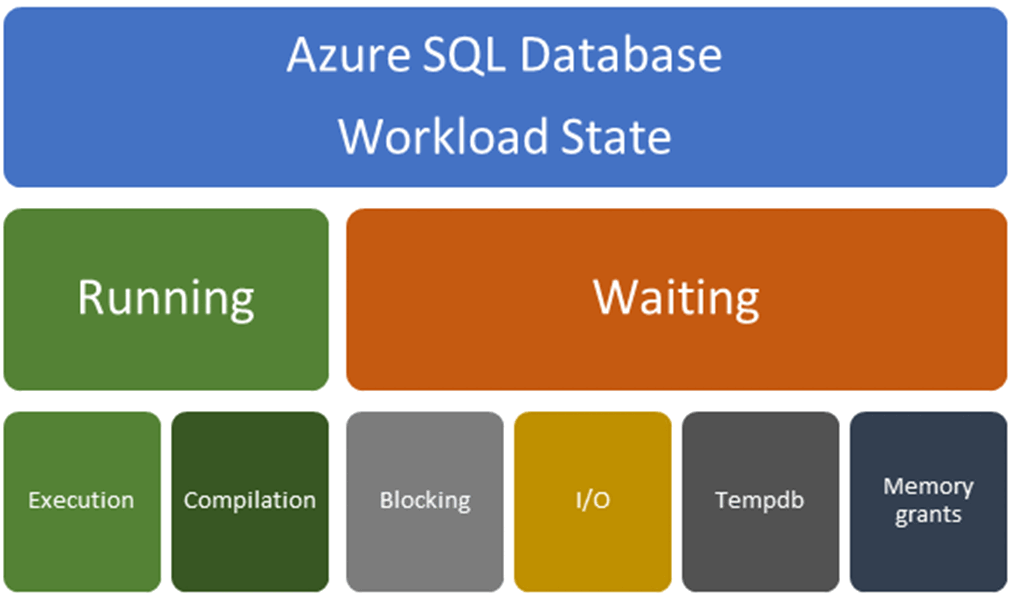
Problemas relacionados à execução: Os problemas relacionados à execução geralmente estão relacionados a problemas de compilação, resultando em um plano de consulta subótimo ou problemas de execução relacionados a recursos insuficientes ou usados em excesso. Problemas relacionados com a espera: Os problemas relacionados com a espera estão geralmente relacionados com:
- Fechaduras (bloqueio)
- E/S
- Contenção relacionada com a
tempdbutilização - Concessão de memória espera
Este artigo é sobre o Banco de Dados SQL do Azure, consulte também Tipos detetáveis de gargalos de desempenho de consulta na Instância Gerenciada SQL do Azure.
Problemas de compilação que resultam em um plano de consulta abaixo do ideal
Um plano subótimo gerado pelo SQL Query Optimizer pode ser a causa do desempenho lento da consulta. O Otimizador de Consulta SQL pode produzir um plano subótimo devido a um índice ausente, estatísticas obsoletas, uma estimativa incorreta do número de linhas a serem processadas ou uma estimativa imprecisa da memória necessária. Se você souber que a consulta foi executada mais rapidamente no passado ou em outro banco de dados, compare os planos de execução reais para ver se eles são diferentes.
Identifique quaisquer índices ausentes usando um destes métodos:
- Use o Intelligent Insights.
- Revise as recomendações no Supervisor de Banco de Dados para bancos de dados únicos e em pool no Banco de Dados SQL do Azure. Você também pode optar por habilitar opções de ajuste automático para ajustar índices para o Banco de Dados SQL do Azure.
- Índices ausentes em DMVs e planos de execução de consulta. Este artigo mostra como detetar e ajustar índices não clusterizados usando solicitações de índice ausentes.
Tente atualizar estatísticas ou reconstruir índices para obter o melhor plano. Habilite a correção automática do plano para mitigar automaticamente esses problemas.
Como uma etapa avançada de solução de problemas, use as dicas do Repositório de Consultas para aplicar dicas de consulta usando o Repositório de Consultas, sem fazer alterações no código.
Este exemplo de ajuste e sugestão de consulta mostra o impacto de um plano de consulta subótimo devido a uma consulta parametrizada, como detetar essa condição e como usar uma dica de consulta para resolver.
Tente alterar o nível de compatibilidade do banco de dados e implementar o processamento inteligente de consultas. O SQL Query Optimizer pode gerar um plano de consulta diferente, dependendo do nível de compatibilidade do seu banco de dados. Níveis de compatibilidade mais altos fornecem recursos de processamento de consultas mais inteligentes.
- Para obter mais informações sobre o processamento de consultas, consulte Guia de arquitetura de processamento de consultas.
- Para alterar os níveis de compatibilidade do banco de dados e ler mais sobre as diferenças entre os níveis de compatibilidade, consulte ALTER DATABASE.
- Para ler mais sobre a estimativa de cardinalidade, consulte Estimativa de cardinalidade
Resolver consultas com os planos de execução de consulta inferiores
As seções a seguir discutem como resolver consultas com um plano de execução de consulta abaixo do ideal.
Consultas com problemas de plano sensível a parâmetros (PSP)
Um problema de plano sensível a parâmetros (PSP) acontece quando o otimizador de consulta gera um plano de execução de consulta que é ideal apenas para um valor de parâmetro específico (ou conjunto de valores) e o plano armazenado em cache não é ideal para valores de parâmetro que são usados em execuções consecutivas. Os planos que não são ideais podem, então, causar problemas de desempenho de consulta e degradar a taxa de transferência geral da carga de trabalho.
Para obter mais informações sobre deteção de parâmetros e processamento de consultas, consulte o Guia de arquitetura de processamento de consultas.
Várias soluções alternativas podem atenuar os problemas do PSP. Cada solução alternativa tem compensações e desvantagens associadas:
- Um novo recurso introduzido com o SQL Server 2022 (16.x) é a otimização do Plano Sensível a Parâmetros, que tenta mitigar a maioria dos planos de consulta subótimos causados pela sensibilidade a parâmetros. Isso é habilitado com o nível de compatibilidade de banco de dados 160 no Banco de Dados SQL do Azure.
- Use a dica de consulta RECOMPILE em cada execução de consulta. Esta solução alternativa negocia o tempo de compilação e o aumento da CPU para uma melhor qualidade do plano. A
RECOMPILEopção muitas vezes não é possível para cargas de trabalho que exigem uma alta taxa de transferência. - Use a dica de consulta OPTION (OTIMIZE FOR...) para substituir o valor real do parâmetro por um valor de parâmetro típico que produz um plano bom o suficiente para a maioria das possibilidades de valor de parâmetro. Esta opção requer uma boa compreensão dos valores ótimos dos parâmetros e das características do plano associadas.
- Use a dica de consulta OPTION (OTIMIZE FOR UNKNOWN) para substituir o valor real do parâmetro e, em vez disso, use a média do vetor de densidade. Você também pode fazer isso capturando os valores dos parâmetros de entrada em variáveis locais e, em seguida, usando as variáveis locais dentro dos predicados em vez de usar os próprios parâmetros. Para esta correção, a densidade média deve ser boa o suficiente.
- Desative totalmente a deteção de parâmetros usando a dica de consulta DISABLE_PARAMETER_SNIFFING .
- Use a dica de consulta KEEPFIXEDPLAN para evitar recompilações no cache. Esta solução alternativa pressupõe que o plano comum suficientemente bom é o que já está em cache. Você também pode desativar as atualizações automáticas de estatísticas para reduzir as chances de que o bom plano seja despejado e um novo plano ruim seja compilado.
- Força o plano usando explicitamente a dica de consulta USE PLAN reescrevendo a consulta e adicionando a dica no texto da consulta. Ou defina um plano específico usando o Repositório de Consultas ou habilitando o ajuste automático.
- Substitua o procedimento único por um conjunto aninhado de procedimentos que podem ser usados com base na lógica condicional e nos valores de parâmetros associados.
- Crie alternativas de execução de cadeia de caracteres dinâmicas para uma definição de procedimento estático.
Para aplicar dicas de consulta, modifique a consulta ou use as dicas do Repositório de Consultas para aplicar a dica sem fazer alterações no código.
Para obter mais informações sobre como resolver problemas de PSP, consulte estas postagens de blog:
- Eu cheiro um parâmetro
- Conor vs. SQL dinâmico vs. procedimentos vs. qualidade do plano para consultas parametrizadas
Atividade de compilação causada por parametrização inadequada
Quando uma consulta tem literais, o mecanismo de banco de dados parametriza automaticamente a instrução ou um usuário parametriza explicitamente a instrução para reduzir o número de compilações. Um número elevado de compilações para uma consulta com o mesmo padrão, mas diferentes valores literais, podem resultar na utilização elevada da CPU. Da mesma forma, se apenas parametrizar parcialmente uma consulta que continua a ter literais, o motor da base de dados não parametrizará mais a consulta.
Aqui está um exemplo de uma consulta parcialmente parametrizada:
SELECT *
FROM t1 JOIN t2 ON t1.c1 = t2.c1
WHERE t1.c1 = @p1 AND t2.c2 = '961C3970-0E54-4E8E-82B6-5545BE897F8F';
Neste exemplo, toma @p1, t1.c1 mas t2.c2 continua a tomar GUID como literal. Nesse caso, se você alterar o valor do c2, a consulta será tratada como uma consulta diferente e uma nova compilação acontecerá. Para reduzir compilações neste exemplo, você também parametrizaria o GUID.
A consulta seguinte mostra a contagem de consultas por hash de consulta para determinar se uma consulta está parametrizada corretamente:
SELECT TOP 10
q.query_hash
, count (distinct p.query_id ) AS number_of_distinct_query_ids
, min(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id
JOIN sys.query_store_runtime_stats AS rs
ON rs.plan_id = p.plan_id
JOIN sys.query_store_runtime_stats_interval AS rsi
ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
AND query_parameterization_type_desc IN ('User', 'None')
GROUP BY q.query_hash
ORDER BY count (distinct p.query_id) DESC;
Fatores que afetam as alterações do plano de consulta
Uma recompilação do plano de execução de consulta pode resultar em um plano de consulta gerado que difere do plano armazenado em cache original. Um plano original existente pode ser recompilado automaticamente por vários motivos:
- As alterações no esquema são referenciadas pela consulta
- As alterações de dados nas tabelas são referenciadas pela consulta
- As opções de contexto de consulta foram alteradas
Um plano compilado pode ser ejetado do cache por vários motivos, como:
- Reinicialização da instância
- Alterações de configuração no escopo do banco de dados
- Pressão da memória
- Solicitações explícitas para limpar o cache
Se você usar uma dica RECOMPILE, um plano não será armazenado em cache.
Uma recompilação (ou nova compilação após a remoção do cache) ainda pode resultar na geração de um plano de execução de consulta idêntico ao original. Quando o plano muda em relação ao plano anterior ou original, estas explicações são prováveis:
Design físico alterado: por exemplo, os índices recém-criados cobrem de forma mais eficaz os requisitos de uma consulta. Os novos índices podem ser usados em uma nova compilação se o otimizador de consulta decidir que usar esse novo índice é mais ideal do que usar a estrutura de dados originalmente selecionada para a primeira versão da execução da consulta. Quaisquer alterações físicas nos objetos referenciados podem resultar em uma nova escolha de plano em tempo de compilação.
Diferenças de recursos do servidor: quando um plano em um sistema difere do plano em outro sistema, a disponibilidade de recursos, como o número de processadores disponíveis, pode influenciar qual plano é gerado. Por exemplo, se um sistema tiver mais processadores, um plano paralelo pode ser escolhido. Para obter mais informações sobre paralelismo no Banco de Dados SQL do Azure, consulte Configurar o grau máximo de paralelismo (MAXDOP) no Banco de Dados SQL do Azure.
Estatísticas diferentes: As estatísticas associadas aos objetos referenciados podem ter sido alteradas ou podem ser materialmente diferentes das estatísticas do sistema original. Se as estatísticas mudarem e uma recompilação acontecer, o otimizador de consulta usará as estatísticas a partir de quando elas foram alteradas. As distribuições e frequências dos dados estatísticos revistos podem diferir das da compilação original. Essas alterações são usadas para criar estimativas de cardinalidade. (As estimativas de cardinalidade são o número de linhas que se espera que fluam através da árvore de consulta lógica.) Alterações nas estimativas de cardinalidade podem levá-lo a escolher diferentes operadores físicos e ordens de operações associadas. Mesmo pequenas alterações nas estatísticas podem resultar em um plano de execução de consulta alterado.
Nível de compatibilidade de banco de dados alterado ou versão do estimador de cardinalidade: alterações no nível de compatibilidade do banco de dados podem habilitar novas estratégias e recursos que podem resultar em um plano de execução de consulta diferente. Além do nível de compatibilidade do banco de dados, um sinalizador de rastreamento desabilitado ou habilitado 4199 ou um estado alterado do QUERY_OPTIMIZER_HOTFIXES de configuração do escopo do banco de dados também pode influenciar as escolhas do plano de execução da consulta em tempo de compilação. Os sinalizadores de rastreamento 9481 (force legacy CE) e 2312 (force default CE) também afetam o plano.
Problemas de limites de recursos
O desempenho lento da consulta não relacionado a planos de consulta subótimos e índices ausentes geralmente estão relacionados a recursos insuficientes ou usados em excesso. Se o plano de consulta for ideal, a consulta (e o banco de dados) pode estar atingindo os limites de recursos para o banco de dados ou pool elástico. Um exemplo pode ser o excesso de taxa de transferência de gravação de log para o nível de serviço.
Detetando problemas de recursos usando o portal do Azure: para ver se os limites de recursos são o problema, consulte Monitoramento de recursos do Banco de Dados SQL. Para bancos de dados únicos e pools elásticos, consulte Recomendações de desempenho do Supervisor de Banco de Dados e Insights de desempenho de consulta.
Detetando limites de recursos usando o Intelligent Insights
Detetando problemas de recursos usando DMVs:
- O sys.dm_db_resource_stats DMV retorna CPU, E/S e consumo de memória para o banco de dados. Existe uma linha para cada intervalo de 15 segundos, mesmo que não haja atividade no banco de dados. Os dados históricos são mantidos durante uma hora.
- O sys.resource_stats DMV retorna dados de uso e armazenamento da CPU para o Banco de Dados SQL do Azure. Os dados são recolhidos e agregados em intervalos de cinco minutos.
- Muitas consultas individuais que, cumulativamente, consomem alta CPU
Se você identificar o problema como recurso insuficiente, poderá atualizar recursos para aumentar a capacidade do banco de dados para absorver os requisitos da CPU. Para obter mais informações, consulte Dimensionar recursos de banco de dados único no Banco de Dados SQL do Azure e Dimensionar recursos de pool elástico no Banco de Dados SQL do Azure.
Problemas de desempenho causados pelo aumento do volume da carga de trabalho
Um aumento no tráfego de aplicativos e no volume de carga de trabalho pode causar maior uso da CPU. Mas é preciso ter cuidado para diagnosticar corretamente esse problema. Quando vir um problema de CPU alta, responda a estas perguntas para determinar se o aumento é causado por alterações no volume de carga de trabalho:
As consultas do aplicativo são a causa do problema de alta CPU?
Para as principais consultas que consomem CPU que você pode identificar:
- Vários planos de execução foram associados à mesma consulta? Em caso afirmativo, porquê?
- Para consultas com o mesmo plano de execução, os tempos de execução foram consistentes? A contagem de execuções aumentou? Nesse caso, o aumento da carga de trabalho provavelmente está causando problemas de desempenho.
Em resumo, se o plano de execução da consulta não foi executado de forma diferente, mas o uso da CPU aumentou junto com a contagem de execução, o problema de desempenho provavelmente está relacionado a um aumento da carga de trabalho.
Nem sempre é fácil identificar uma alteração no volume de trabalho que está gerando um problema de CPU. Considere estes fatores:
Uso de recursos alterado: por exemplo, considere um cenário em que o uso da CPU aumentou para 80% por um longo período de tempo. O uso da CPU por si só não significa que o volume da carga de trabalho mudou. Regressões no plano de execução da consulta e alterações na distribuição de dados também podem contribuir para um maior uso de recursos, mesmo que o aplicativo execute a mesma carga de trabalho.
A aparência de uma nova consulta: um aplicativo pode gerar um novo conjunto de consultas em momentos diferentes.
Aumento ou diminuição do número de solicitações: esse cenário é a medida mais óbvia de uma carga de trabalho. O número de consultas nem sempre corresponde a uma maior utilização de recursos. No entanto, essa métrica ainda é um sinal significativo, supondo que outros fatores estejam inalterados.
Use o Intelligent Insights para detetar aumentos de carga de trabalho e planejar regressões.
- Paralelismo: O paralelismo excessivo pode piorar o desempenho de outras cargas de trabalho simultâneas, privando outras consultas de recursos de CPU e thread de trabalho. Para obter mais informações sobre paralelismo no Banco de Dados SQL do Azure, consulte Configurar o grau máximo de paralelismo (MAXDOP) no Banco de Dados SQL do Azure.
Problemas relacionados com a espera
Depois de eliminar um plano subótimo e problemas relacionados à espera relacionados a problemas de execução, o problema de desempenho geralmente é que as consultas provavelmente estão esperando por algum recurso. Os problemas relacionados com a espera podem ser causados por:
Bloqueio:
Uma consulta pode manter o bloqueio em objetos na base de dados enquanto outros utilizadores tentam aceder aos mesmos objetos. Você pode identificar consultas de bloqueio usando DMVs ou Insights Inteligentes. Para obter mais informações, consulte Compreender e resolver problemas de bloqueio do Banco de Dados SQL do Azure.
Problemas de IO
As consultas podem estar à espera que as páginas sejam escritas nos ficheiros de registo ou de dados. Neste caso, verifique as estatísticas de espera
INSTANCE_LOG_RATE_GOVERNOR,WRITE_LOGouPAGEIOLATCH_*no DMV. Veja como utilizar DMVs para Identificar problemas de desempenho de E/S.Problemas do Tempdb
Se a carga de trabalho utilizar tabelas temporárias ou se existirem esvaziamentos da
tempdbnos planos, as consultas poderão ter um problema com o débito datempdb. Para investigar mais, veja Identificar problemas da tempdb.Problemas relacionados com a memória
Se a carga de trabalho não tiver memória suficiente, a esperança de vida da página pode baixar ou as consultas poderão ter menos memória do que a necessária. Em certos casos, a inteligência incorporada no Otimizador de Consultas corrigirá os problemas relacionados com a memória. Veja como utilizar DMVs para Identificar problemas de concessão de memória. Para obter mais informações e consultas de exemplo, consulte Solucionar problemas de erros de falta de memória com o Banco de Dados SQL do Azure. Se encontrar erros de memória esgotada, veja sys.dm_os_out_of_memory_events.
Métodos para mostrar as principais categorias de espera
Esses métodos são comumente usados para mostrar as principais categorias de tipos de espera:
- Use o Intelligent Insights para identificar consultas com degradação de desempenho devido ao aumento das esperas
- Use o Repositório de Consultas para encontrar estatísticas de espera para cada consulta ao longo do tempo. No Repositório de Consultas, os tipos de espera são combinados em categorias de espera. Você pode encontrar o mapeamento de categorias de espera para tipos de espera em sys.query_store_wait_stats.
- Use sys.dm_db_wait_stats para retornar informações sobre todas as esperas encontradas por threads executados durante uma operação de consulta. Você pode usar esse modo de exibição agregado para diagnosticar problemas de desempenho com o Banco de Dados SQL do Azure e também com consultas e lotes específicos. As consultas podem estar aguardando recursos, esperas de fila ou esperas externas.
- Use sys.dm_os_waiting_tasks para retornar informações sobre a fila de tarefas que estão aguardando algum recurso.
Em cenários de alta CPU, as estatísticas de armazenamento de consultas e espera podem não refletir o uso da CPU se:
- Consultas de alto consumo de CPU ainda estão em execução.
- As consultas de alto consumo de CPU estavam em execução quando ocorreu um failover.
Os DMVs que rastreiam o Repositório de Consultas e as estatísticas de espera mostram resultados apenas para consultas concluídas com êxito e com tempo limite. Eles não mostram dados para instruções atualmente em execução até que as instruções terminem. Use o modo de exibição de gerenciamento dinâmico sys.dm_exec_requests para controlar as consultas em execução no momento e o tempo de trabalho associado.
Próximos passos
- Configure o grau máximo de paralelismo (MAXDOP) na Base de Dados SQL do Azure
- Compreender e resolver problemas de bloqueio da Base de Dados SQL do Azure na Base de Dados SQL do Azure
- Diagnosticar e resolver problemas de CPU elevada na Base de Dados SQL do Azure
- Visão geral do monitoramento e ajuste do Banco de Dados SQL
- Monitorando o desempenho do Banco de Dados SQL do Microsoft Azure usando exibições de gerenciamento dinâmico
- Ajuste índices não clusterizados com sugestões de índice ausentes
- Gestão de recursos na Base de Dados SQL do Azure
- Limites de recursos das bases de dados individuais com o modelo de compra baseado em vCore
- Limites de recursos dos conjuntos elásticos com o modelo de compra baseado em vCore
- Limites de recursos das bases de dados individuais com o modelo de compra de DTUs
- Limites de recursos dos conjuntos elásticos com o modelo de compra baseado DTU