Converter um banco de dados existente em Hiperescala
Você pode converter um banco de dados existente no Banco de Dados SQL do Azure em Hiperescala usando o portal do Azure, a CLI do Azure, o PowerShell ou o Transact-SQL.
Transição
O processo de conversão é dividido em dois estágios: a conversão do banco de dados, que ocorre enquanto o banco de dados existente está online e, em seguida, uma substituição para o novo banco de dados de Hiperescala.
- O tempo necessário para mover um banco de dados existente para a Hiperescala consiste no tempo para copiar dados e o tempo para reproduzir as alterações feitas no banco de dados de origem durante a cópia de dados. O tempo de cópia de dados é proporcional ao tamanho dos dados. É recomendável converter em Hiperescala durante um período de atividade de gravação inferior para que o tempo para reproduzir as alterações acumuladas seja menor.
- Você experimentará apenas um curto período de inatividade, geralmente de menos de um minuto, durante a transição final para o Hyperscale. Você tem a capacidade de escolher quando a substituição ocorre - assim que o banco de dados estiver pronto ou manualmente em um momento de sua escolha. Por padrão, o processo de conversão em Hypersacle será recortado automaticamente.
Nota
A capacidade de iniciar uma substituição manual para uma conversão em Hiperescala é um recurso de visualização.
Na versão prévia atual, durante uma conversão para Hiperescala, você tem três dias para iniciar a substituição manual após o ponto em que o banco de dados está pronto para substituição. Você pode iniciar uma substituição manual por meio do portal do Azure, da CLI do Azure, do PowerShell ou do T-SQL.
Pré-requisitos
Para converter um banco de dados que faz parte de uma relação de replicação geográfica, como primário ou como secundário, em Hiperescala, você precisa primeiro encerrar a replicação geográfica entre a réplica primária e secundária. Os bancos de dados em um grupo de failover devem ser primeiro removidos do grupo.
Depois que um banco de dados for movido para a Hiperescala, você poderá criar uma nova réplica geográfica da Hiperescala para esse banco de dados ou adicionar o banco de dados a um grupo de failover.
Não há suporte para a conversão direta da camada de serviço Básica para a Hiperescala. Para executar essa conversão, primeiro altere o banco de dados para qualquer camada de serviço diferente de Basic (por exemplo, Uso Geral) e, em seguida, prossiga com a conversão para Hiperescala.
Converter um banco de dados em Hiperescala
Para converter um Banco de Dados SQL do Azure existente em Hiperescala, primeiro identifique seu objetivo de serviço de destino.
Examine limites de recursos para bancos de dados individuais se você não tiver certeza de qual objetivo de serviço é adequado para seu banco de dados. Em muitos casos, você pode escolher um objetivo de serviço com o mesmo número de vCores e a mesma geração de hardware que o banco de dados original. Se necessário, você pode alterar o objetivo de serviço mais tarde com tempo de inatividade mínimo. A cobrança para Hiperescala começa somente após a migração.
Selecione a guia do método preferencial para converter seu banco de dados:
- Portal
- CLI do Azure
- do PowerShell
- Transact-SQL
O portal do Azure permite que você converta em Hiperescala modificando a camada de serviço do banco de dados.

- Navegue até o banco de dados que você deseja converter no portal do Azure.
- Na barra de navegação à esquerda, selecione Computação + Armazenamento.
- Selecione a lista suspensa do nível de serviço para expandir as opções de níveis de serviço.
- Selecione Hyperscale na lista suspensa.
- Examine o da camada de computação e escolha Provisionado ou sem servidor.
- Examine o modo de substituição , uma opção específica para conversão em Hiperescala.
- A migração ocorre depois que o banco de dados é preparado para conversão para Hiperescala.
modo de comutação determina quando a conectividade com o Banco de Dados SQL do Azure existente será interrompida momentaneamente para a conversão para Hyperscale:
- A migração automática executa a migração assim que o banco de dados de Hiperescala estiver pronto.
- Migração manual solicita que você inicie a migração em um momento de sua escolha no portal do Azure. Essa opção é mais útil para cronometrar a substituição para interrupção mínima dos negócios.
- A migração ocorre depois que o banco de dados é preparado para conversão para Hiperescala.
modo de comutação determina quando a conectividade com o Banco de Dados SQL do Azure existente será interrompida momentaneamente para a conversão para Hyperscale:
- Revise a Configuração de Hardware listada. Se desejar, selecione Alterar a configuração para selecionar a configuração de hardware apropriada para sua carga de trabalho.
- Selecione o controle deslizante vCores se desejar alterar o número de vCores disponíveis para seu banco de dados na camada de serviço hiperescala.
- Selecione o controle deslizante High-Availability Réplicas Secundárias se desejar alterar o número de réplicas na camada de serviço hiperescala.
- Selecione Aplicar.
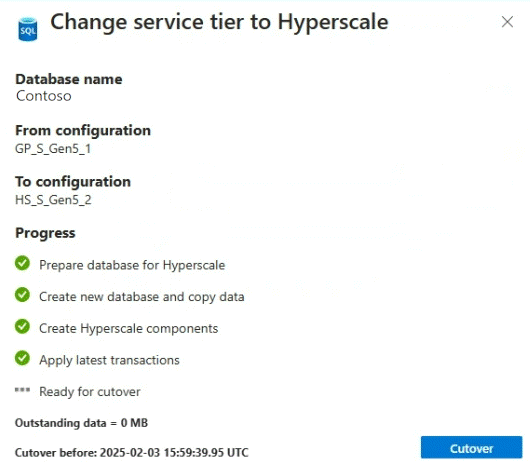
- Monitore a conversão no portal do Azure.
- Navegue até o banco de dados no portal do Azure.
- Na barra de navegação à esquerda, selecione Visão geral.
- Examine a seção Notificações na parte inferior do painel direito. Se as operações estiverem em andamento, uma caixa de notificação será exibida.
- Selecione a caixa de notificação para exibir detalhes.
- O painel operações em andamento é aberto. Examine os detalhes das operações em andamento.
Se você tiver selecionado corte manual, o portal do Azure apresentará um botão de Corte quando o portal estiver pronto para isso.