Tutorial: Analisar dados nos Logs do Azure Monitor usando um bloco de anotações
Os blocos de notas são ambientes integrados que lhe permitem criar e partilhar documentos com código dinâmico, equações, visualizações e texto. A integração de um bloco de anotações com um espaço de trabalho do Log Analytics permite criar um processo de várias etapas que executa código em cada etapa com base nos resultados da etapa anterior. Você pode usar esses processos simplificados para criar pipelines de aprendizado de máquina, ferramentas de análise avançadas, guias de solução de problemas (TSGs) para necessidades de suporte e muito mais.
A integração de um bloco de anotações com um espaço de trabalho do Log Analytics também permite:
- Execute consultas KQL e código personalizado em qualquer idioma.
- Introduza novos recursos de análise e visualização, como novos modelos de aprendizado de máquina, cronogramas personalizados e árvores de processos.
- Integre conjuntos de dados fora dos Logs do Azure Monitor, como conjuntos de dados locais.
- Aproveite os limites de serviço aumentados usando os limites da API de Consulta em comparação com o portal do Azure.
Neste tutorial, irá aprender a:
- Integrar um bloco de notas com a sua área de trabalho do Log Analytics utilizando a biblioteca de cliente do Azure Monitor Query e a biblioteca de cliente do Azure Identity
- Explore e visualize dados do seu espaço de trabalho do Log Analytics em um bloco de anotações
- Ingerir dados do seu bloco de notas numa tabela personalizada na área de trabalho do Log Analytics (opcional)
Para obter um exemplo de como criar um pipeline de aprendizado de máquina para analisar dados nos Logs do Azure Monitor usando um bloco de anotações, consulte este bloco de anotações de exemplo: Detetar anomalias nos Logs do Azure Monitor usando técnicas de aprendizado de máquina.
Gorjeta
Para contornar limitações relacionadas à API, divida consultas maiores em várias consultas menores.
Pré-requisitos
Para este tutorial, você precisa:
Um espaço de trabalho do Azure Machine Learning com uma instância de computação de CPU com:
- Um caderno.
- Um kernel definido como Python 3.8 ou superior.
As seguintes funções e permissões:
Em Logs do Azure Monitor: a função de Colaborador do Logs Analytics para ler e enviar dados para seu espaço de trabalho do Logs Analytics. Para obter mais informações, consulte Gerenciar o acesso a espaços de trabalho do Log Analytics.
No Azure Machine Learning:
- Uma função de Proprietário ou Colaborador no nível do grupo de recursos para criar um novo espaço de trabalho do Azure Machine Learning, se necessário.
- Uma função de Colaborador no espaço de trabalho do Azure Machine Learning onde você executa seu bloco de anotações.
Para obter mais informações, consulte Gerenciar o acesso a um espaço de trabalho do Azure Machine Learning.
Ferramentas e cadernos
Neste tutorial, você usa estas ferramentas:
| Ferramenta | Description |
|---|---|
| Biblioteca de cliente do Azure Monitor Query | Permite executar consultas somente leitura em dados nos Logs do Azure Monitor. |
| Biblioteca de cliente do Azure Identity | Permite que os clientes do SDK do Azure se autentiquem com o Microsoft Entra ID. |
| Biblioteca de cliente do Azure Monitor Ingestion | Permite enviar logs personalizados para o Azure Monitor usando a API de Ingestão de Logs. Necessário para ingerir dados analisados em uma tabela personalizada no espaço de trabalho do Log Analytics (opcional) |
| Regra de coleta de dados, ponto de extremidade de coleta de dados e um aplicativo registrado | Necessário para ingerir dados analisados em uma tabela personalizada no espaço de trabalho do Log Analytics (opcional) |
Outras bibliotecas de consulta que você pode usar incluem:
- A biblioteca Kqlmagic permite executar consultas KQL diretamente dentro de um bloco de anotações da mesma forma que executa consultas KQL a partir da ferramenta Log Analytics.
- A biblioteca MSTICPY fornece consultas modeladas que invocam séries cronológicas KQL incorporadas e recursos de aprendizado de máquina, além de fornecer ferramentas avançadas de visualização e análises de dados no espaço de trabalho do Log Analytics.
Outras experiências de notebook da Microsoft para análise avançada incluem:
- Blocos de anotações do Azure Synapse Analytics
- Blocos de anotações do Microsoft Fabric
- Blocos de anotações de código do Visual Studio
1. Integre seu espaço de trabalho do Log Analytics ao seu bloco de anotações
Configure seu bloco de anotações para consultar seu espaço de trabalho do Log Analytics:
Instale as bibliotecas de cliente Azure Monitor Query, Azure Identity e Azure Monitor Ingestion juntamente com a biblioteca de análise de dados Pandas, biblioteca de visualização Plotly:
import sys !{sys.executable} -m pip install --upgrade azure-monitor-query azure-identity azure-monitor-ingestion !{sys.executable} -m pip install --upgrade pandas plotlyDefina a
LOGS_WORKSPACE_IDvariável abaixo como a ID do seu espaço de trabalho do Log Analytics. A variável está atualmente definida para usar o espaço de trabalho Demonstração do Azure Monitor, que você pode usar para demonstrar o bloco de anotações.LOGS_WORKSPACE_ID = "DEMO_WORKSPACE"LogsQueryClientConfigure para autenticar e consultar os Logs do Azure Monitor.Este código é configurado
LogsQueryClientpara autenticar usandoDefaultAzureCredential:from azure.core.credentials import AzureKeyCredential from azure.core.pipeline.policies import AzureKeyCredentialPolicy from azure.identity import DefaultAzureCredential from azure.monitor.query import LogsQueryClient if LOGS_WORKSPACE_ID == "DEMO_WORKSPACE": credential = AzureKeyCredential("DEMO_KEY") authentication_policy = AzureKeyCredentialPolicy(name="X-Api-Key", credential=credential) else: credential = DefaultAzureCredential() authentication_policy = None logs_query_client = LogsQueryClient(credential, authentication_policy=authentication_policy)LogsQueryClientnormalmente só suporta autenticação com credenciais de token do Microsoft Entra. No entanto, podemos passar uma política de autenticação personalizada para habilitar o uso de chaves de API. Isso permite que o cliente consulte o espaço de trabalho de demonstração. A disponibilidade e o acesso a este espaço de trabalho de demonstração estão sujeitos a alterações, por isso recomendamos usar seu próprio espaço de trabalho do Log Analytics.Defina uma função auxiliar, chamada
query_logs_workspace, para executar uma determinada consulta no espaço de trabalho do Log Analytics e retornar os resultados como um Pandas DataFrame.import pandas as pd import plotly.express as px from azure.monitor.query import LogsQueryStatus from azure.core.exceptions import HttpResponseError def query_logs_workspace(query): try: response = logs_query_client.query_workspace(LOGS_WORKSPACE_ID, query, timespan=None) if response.status == LogsQueryStatus.PARTIAL: error = response.partial_error data = response.partial_data print(error.message) elif response.status == LogsQueryStatus.SUCCESS: data = response.tables for table in data: my_data = pd.DataFrame(data=table.rows, columns=table.columns) except HttpResponseError as err: print("something fatal happened") print (err) return my_data
2. Explore e visualize dados do seu espaço de trabalho do Log Analytics no seu bloco de anotações
Vamos examinar alguns dados no espaço de trabalho executando uma consulta do bloco de anotações:
Esta consulta verifica a quantidade de dados (em Megabytes) que você ingeriu em cada uma das tabelas (tipos de dados) no espaço de trabalho do Log Analytics a cada hora na semana passada:
TABLE = "Usage" QUERY = f""" let starttime = 7d; // Start date for the time series, counting back from the current date let endtime = 0d; // today {TABLE} | project TimeGenerated, DataType, Quantity | where TimeGenerated between (ago(starttime)..ago(endtime)) | summarize ActualUsage=sum(Quantity) by TimeGenerated=bin(TimeGenerated, 1h), DataType """ df = query_logs_workspace(QUERY) display(df)O DataFrame resultante mostra a ingestão horária em cada uma das tabelas no espaço de trabalho do Log Analytics:
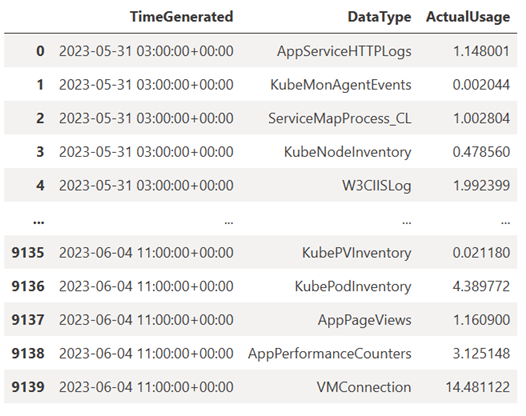
Agora, vamos ver os dados como um gráfico que mostra o uso por hora para vários tipos de dados ao longo do tempo, com base no Pandas DataFrame:
df = df.sort_values(by="TimeGenerated") graph = px.line(df, x='TimeGenerated', y="ActualUsage", color='DataType', title="Usage in the last week - All data types") graph.show()O gráfico resultante tem esta aparência:

Você consultou e visualizou com êxito os dados de log do seu espaço de trabalho do Log Analytics em seu bloco de anotações.

3. Analise os dados
Como um exemplo simples, vamos pegar as cinco primeiras linhas:
analyzed_df = df.head(5)
Para obter um exemplo de como implementar técnicas de aprendizado de máquina para analisar dados nos Logs do Azure Monitor, consulte este bloco de anotações de exemplo: Detetar anomalias nos Logs do Azure Monitor usando técnicas de aprendizado de máquina.
4. Ingerir dados analisados em uma tabela personalizada no espaço de trabalho do Log Analytics (opcional)
Envie os resultados da análise para uma tabela personalizada no espaço de trabalho do Log Analytics para disparar alertas ou disponibilizá-los para análise posterior.
Para enviar dados para seu espaço de trabalho do Log Analytics, você precisa de uma tabela personalizada, ponto de extremidade de coleta de dados, regra de coleta de dados e um aplicativo Microsoft Entra registrado com permissão para usar a regra de coleta de dados, conforme explicado em Tutorial: Enviar dados para a API de ingestão de Logs do Azure Monitor com Logs (portal do Azure).
Quando você cria sua tabela personalizada:
Carregue este arquivo de exemplo para definir o esquema da tabela:
[ { "TimeGenerated": "2023-03-19T19:56:43.7447391Z", "ActualUsage": 40.1, "DataType": "AzureDiagnostics" } ]
Defina as constantes necessárias para a API de ingestão de logs:
os.environ['AZURE_TENANT_ID'] = "<Tenant ID>"; #ID of the tenant where the data collection endpoint resides os.environ['AZURE_CLIENT_ID'] = "<Application ID>"; #Application ID to which you granted permissions to your data collection rule os.environ['AZURE_CLIENT_SECRET'] = "<Client secret>"; #Secret created for the application os.environ['LOGS_DCR_STREAM_NAME'] = "<Custom stream name>" ##Name of the custom stream from the data collection rule os.environ['LOGS_DCR_RULE_ID'] = "<Data collection rule immutableId>" # immutableId of your data collection rule os.environ['DATA_COLLECTION_ENDPOINT'] = "<Logs ingestion URL of your endpoint>" # URL that looks like this: https://xxxx.ingest.monitor.azure.comIngerir os dados na tabela personalizada no espaço de trabalho do Log Analytics:
from azure.core.exceptions import HttpResponseError from azure.identity import ClientSecretCredential from azure.monitor.ingestion import LogsIngestionClient import json credential = ClientSecretCredential( tenant_id=AZURE_TENANT_ID, client_id=AZURE_CLIENT_ID, client_secret=AZURE_CLIENT_SECRET ) client = LogsIngestionClient(endpoint=DATA_COLLECTION_ENDPOINT, credential=credential, logging_enable=True) body = json.loads(analyzed_df.to_json(orient='records', date_format='iso')) try: response = client.upload(rule_id=LOGS_DCR_RULE_ID, stream_name=LOGS_DCR_STREAM_NAME, logs=body) print("Upload request accepted") except HttpResponseError as e: print(f"Upload failed: {e}")Nota
Quando você cria uma tabela no espaço de trabalho do Log Analytics, pode levar até 15 minutos para que os dados ingeridos apareçam na tabela.
Verifique se os dados agora aparecem na tabela personalizada.


Próximos passos
Saiba mais sobre como:
- Agende um pipeline de aprendizado de máquina.
- Detete e analise anomalias usando o KQL.