Tolerância a falhas e eficiência de armazenamento em clusters do Azure Stack HCI e Windows Server
Aplica-se a: Azure Stack HCI, versões 22H2 e 21H2; Windows Server 2022, Windows Server 2019
Importante
O Azure Stack HCI agora faz parte do Azure Local. A renomeação da documentação do produto está em andamento. No entanto, as versões mais antigas do Azure Stack HCI, por exemplo 22H2, continuarão a fazer referência ao Azure Stack HCI e não refletirão a alteração de nome. Mais informações.
Este artigo explica as opções de resiliência disponíveis e descreve os requisitos de escala, a eficiência de armazenamento e as vantagens e compensações gerais de cada uma.
Descrição geral
O Storage Spaces Direct oferece tolerância a falhas, muitas vezes chamada de "resiliência", para seus dados. Sua implementação é semelhante ao RAID, exceto distribuído entre servidores e implementado em software.
Assim como acontece com o RAID, existem algumas maneiras diferentes de os Espaços de Armazenamento fazerem isso, que fazem diferentes compensações entre tolerância a falhas, eficiência de armazenamento e complexidade de computação. Estes se enquadram em duas categorias: "espelhamento" e "paridade", este último às vezes chamado de "codificação de apagamento".
Espelhamento
O espelhamento fornece tolerância a falhas mantendo várias cópias de todos os dados. Isso mais se assemelha ao RAID-1. Como esses dados são distribuídos e colocados não é trivial (veja este blog para saber mais), mas é absolutamente verdadeiro dizer que todos os dados armazenados usando espelhamento são escritos, em sua totalidade, várias vezes. Cada cópia é gravada em hardware físico diferente (unidades diferentes em servidores diferentes) que se presume falhar independentemente.
Você pode escolher entre dois sabores de espelhamento – "bidirecional" e "tridirecional".
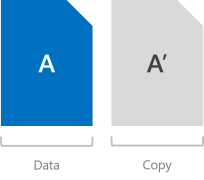
Espelho de duas vias
O espelhamento bidirecional grava duas cópias de tudo. Sua eficiência de armazenamento é de 50% – para gravar 1 TB de dados, você precisa de pelo menos 2 TB de capacidade de armazenamento físico. Da mesma forma, você precisa de pelo menos dois "domínios de falha" de hardware – com Espaços de Armazenamento Diretos, isso significa dois servidores.
Aviso
Se você tiver mais de dois servidores, recomendamos o uso do espelhamento de três vias.
Espelho de três vias
O espelhamento de três vias escreve três cópias de tudo. Sua eficiência de armazenamento é de 33,3% – para gravar 1 TB de dados, você precisa de pelo menos 3 TB de capacidade de armazenamento físico. Da mesma forma, você precisa de pelo menos três domínios de falha de hardware – com Espaços de Armazenamento Diretos, ou seja, três servidores.
O espelhamento de três vias pode tolerar com segurança pelo menos dois problemas de hardware (unidade ou servidor) ao mesmo tempo. Por exemplo, se você estiver reinicializando um servidor quando, de repente, outra unidade ou servidor falhar, todos os dados permanecerão seguros e continuamente acessíveis.

Paridade
A codificação de paridade, muitas vezes chamada de "codificação de apagamento", fornece tolerância a falhas usando aritmética bitwise, que pode ficar notavelmente complicada. A maneira como isso funciona é menos óbvia do que o espelhamento, e há muitos recursos online excelentes (por exemplo, este Guia Dummies de terceiros para codificação de apagamento) que podem ajudá-lo a ter a ideia. Basta dizer que proporciona uma melhor eficiência de armazenamento sem comprometer a tolerância a falhas.
Os Espaços de Armazenamento oferecem dois sabores de paridade – paridade "única" e paridade "dupla", esta última empregando uma técnica avançada chamada "códigos de reconstrução local" em escalas maiores.
Importante
Recomendamos o uso do espelhamento para a maioria das cargas de trabalho sensíveis ao desempenho. Para saber mais sobre como equilibrar o desempenho e a capacidade dependendo da sua carga de trabalho, consulte Planejar volumes.
Paridade única
A paridade única mantém apenas um símbolo de paridade bitwise, que fornece tolerância a falhas contra apenas uma falha de cada vez. Ele mais se assemelha ao RAID-5. Para usar uma única paridade, você precisa de pelo menos três domínios de falha de hardware – com Espaços de Armazenamento Diretos, ou seja, três servidores. Como o espelhamento de três vias oferece mais tolerância a falhas na mesma escala, desencorajamos o uso de paridade única. Mas, ele está lá se você insistir em usá-lo, e é totalmente suportado.
Aviso
Desencorajamos o uso de paridade única porque ele só pode tolerar com segurança uma falha de hardware de cada vez: se você estiver reinicializando um servidor quando, de repente, outra unidade ou servidor falhar, você terá tempo de inatividade. Se você tiver apenas três servidores, recomendamos o uso do espelhamento de três vias. Se tiver quatro ou mais, consulte a secção seguinte.
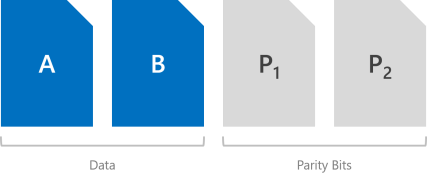
Paridade dupla
A paridade dupla implementa códigos de correção de erros Reed-Solomon para manter dois símbolos de paridade bitwise, fornecendo assim a mesma tolerância a falhas que o espelhamento de três vias (ou seja, até duas falhas ao mesmo tempo), mas com melhor eficiência de armazenamento. Ele mais se assemelha ao RAID-6. Para usar a paridade dupla, você precisa de pelo menos quatro domínios de falha de hardware – com Espaços de Armazenamento Diretos, ou seja, quatro servidores. Nessa escala, a eficiência de armazenamento é de 50% – para armazenar 2 TB de dados, você precisa de 4 TB de capacidade de armazenamento físico.
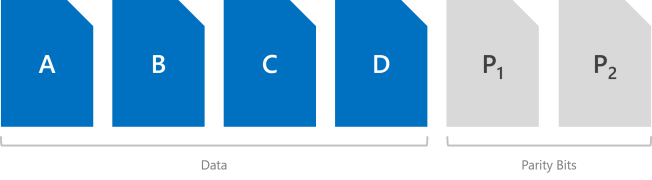
A eficiência de armazenamento de paridade dupla aumenta quanto mais domínios de falha de hardware você tiver, de 50% para 80%. Por exemplo, aos sete (com o Storage Spaces Direct, ou seja, sete servidores) a eficiência salta para 66,7% – para armazenar 4 TB de dados, você precisa de apenas 6 TB de capacidade de armazenamento físico.
Consulte a seção Resumo para obter informações sobre a eficiência dos códigos de reconstrução locais e de partido duplo em todas as escalas.
Códigos de reconstrução locais
Os Espaços de Armazenamento introduzem uma técnica avançada desenvolvida pela Microsoft Research chamada "códigos de reconstrução local", ou LRC. Em grande escala, a paridade dupla usa o LRC para dividir sua codificação/decodificação em alguns grupos menores, para reduzir a sobrecarga necessária para fazer gravações ou recuperar de falhas.
Com as unidades de disco rígido (HDD), o tamanho do grupo é de quatro símbolos; com unidades de estado sólido (SSD), o tamanho do grupo é de seis símbolos. Por exemplo, aqui está a aparência do layout com unidades de disco rígido e 12 domínios de falha de hardware (ou seja, 12 servidores) – há dois grupos de quatro símbolos de dados. Ele atinge 72,7% de eficiência de armazenamento.

Recomendamos este passo a passo detalhado, mas eminentemente legível, de como os códigos de reconstrução locais lidam com vários cenários de falha e por que eles são atraentes, por Claus Joergensen.
Paridade acelerada por espelho
Um volume do Storage Spaces Direct pode ser parte espelhada e parte paridade. Escreve terra primeiro na porção espelhada e são gradualmente movidos para a porção de paridade mais tarde. Efetivamente, isso está usando o espelhamento para acelerar a codificação de eliminação.
Para combinar espelho de três vias e paridade dupla, você precisa de pelo menos quatro domínios de falha, ou seja, quatro servidores.
A eficiência de armazenamento da paridade acelerada por espelho está entre o que você obteria usando todo o espelho ou toda a paridade, e depende das proporções escolhidas.
Importante
Recomendamos o uso do espelhamento para a maioria das cargas de trabalho sensíveis ao desempenho. Para saber mais sobre como equilibrar o desempenho e a capacidade dependendo da sua carga de trabalho, consulte Planejar volumes.
Resumo
Esta seção resume os tipos de resiliência disponíveis no Storage Spaces Direct, os requisitos mínimos de escala para usar cada tipo, quantas falhas cada tipo pode tolerar e a eficiência de armazenamento correspondente.
Tipos de resiliência
| Resiliência | Tolerância a falhas | Eficiência de armazenamento |
|---|---|---|
| Espelho de duas vias | 1 | 50.0% |
| Espelho de três vias | 2 | 33,3% |
| Paridade dupla | 2 | 50.0% - 80.0% |
| Misto | 2 | 33.3% - 80.0% |
Requisitos mínimos de escala
| Resiliência | Domínios de falha mínimos necessários |
|---|---|
| Espelho de duas vias | 2 |
| Espelho de três vias | 3 |
| Paridade dupla | 4 |
| Misto | 4 |
Gorjeta
A menos que você esteja usando tolerância a falhas de chassi ou rack, o número de domínios de falha refere-se ao número de servidores. O número de unidades em cada servidor não afeta os tipos de resiliência que você pode usar, desde que atenda aos requisitos mínimos para Espaços de Armazenamento Diretos.
Eficiência de paridade dupla para implantações híbridas
Esta tabela mostra a eficiência de armazenamento de paridade dupla e códigos de reconstrução local em cada escala para implantações híbridas, que contêm unidades de disco rígido (HDD) e unidades de estado sólido (SSD).
| Domínios de falha | Esquema | Eficiência |
|---|---|---|
| 2 | – | – |
| 3 | – | – |
| 4 | RS 2+2 | 50.0% |
| 5 | RS 2+2 | 50.0% |
| 6 | RS 2+2 | 50.0% |
| 7 | RS 4+2 | 66.7% |
| 8 | RS 4+2 | 66.7% |
| 9 | RS 4+2 | 66.7% |
| 10 | RS 4+2 | 66.7% |
| 11 | RS 4+2 | 66.7% |
| 12 | LRC (8, 2, 1) | 72.7% |
| 13 | LRC (8, 2, 1) | 72.7% |
| 14 | LRC (8, 2, 1) | 72.7% |
| 15 | LRC (8, 2, 1) | 72.7% |
| 16 | LRC (8, 2, 1) | 72.7% |
Eficiência de paridade dupla para implantações totalmente flash
Esta tabela mostra a eficiência de armazenamento de paridade dupla e códigos de reconstrução local em cada escala para implantações totalmente flash, que contêm apenas unidades de estado sólido (SSD). O layout de paridade pode usar tamanhos de grupo maiores e obter melhor eficiência de armazenamento em uma configuração totalmente flash.
| Domínios de falha | Esquema | Eficiência |
|---|---|---|
| 2 | – | – |
| 3 | – | – |
| 4 | RS 2+2 | 50.0% |
| 5 | RS 2+2 | 50.0% |
| 6 | RS 2+2 | 50.0% |
| 7 | RS 4+2 | 66.7% |
| 8 | RS 4+2 | 66.7% |
| 9 | RS 6+2 | 75.0% |
| 10 | RS 6+2 | 75.0% |
| 11 | RS 6+2 | 75.0% |
| 12 | RS 6+2 | 75.0% |
| 13 | RS 6+2 | 75.0% |
| 14 | RS 6+2 | 75.0% |
| 15 | RS 6+2 | 75.0% |
| 16 | LRC (12, 2, 1) | 80.0% |
Exemplos
A menos que você tenha apenas dois servidores, recomendamos o uso de espelhamento de três vias e/ou paridade dupla, pois eles oferecem melhor tolerância a falhas. Especificamente, eles garantem que todos os dados permaneçam seguros e continuamente acessíveis, mesmo quando dois domínios de falha – com Espaços de Armazenamento Diretos, ou seja, dois servidores – são afetados por falhas simultâneas.
Exemplos em que tudo permanece online
Estes seis exemplos mostram o que o espelhamento de três vias e/ou a paridade dupla podem tolerar.
- 1. Uma unidade perdida (inclui unidades de cache)
- 2. Um servidor perdido
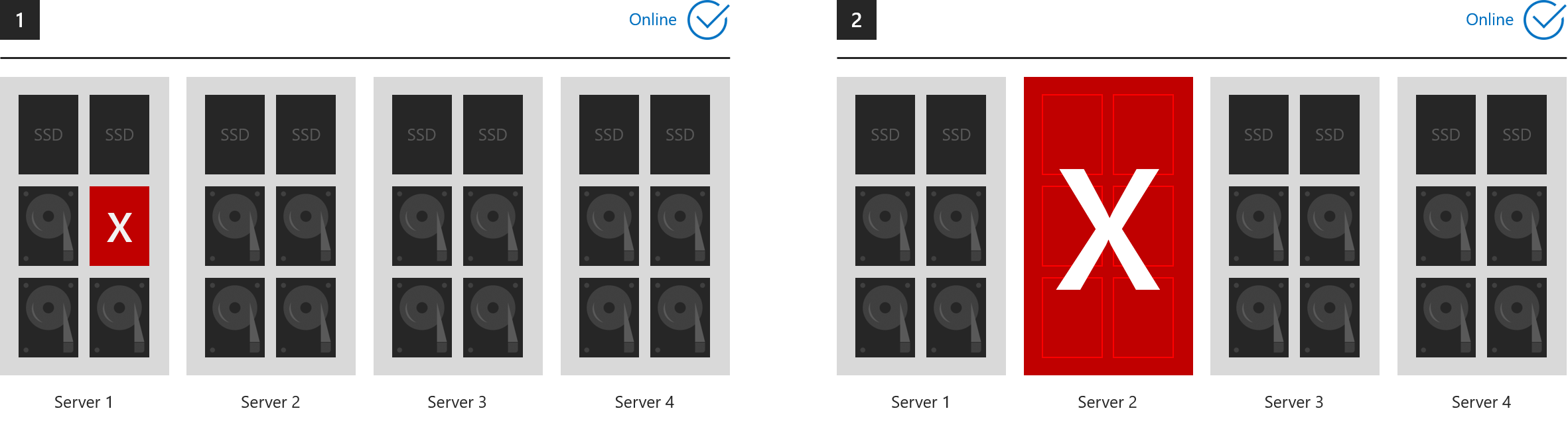
- 3. Um servidor e uma unidade perdida
- 4. Duas unidades perdidas em servidores diferentes

- 5. Mais de duas unidades perdidas, desde que no máximo dois servidores sejam afetados
- 6. Dois servidores perdidos
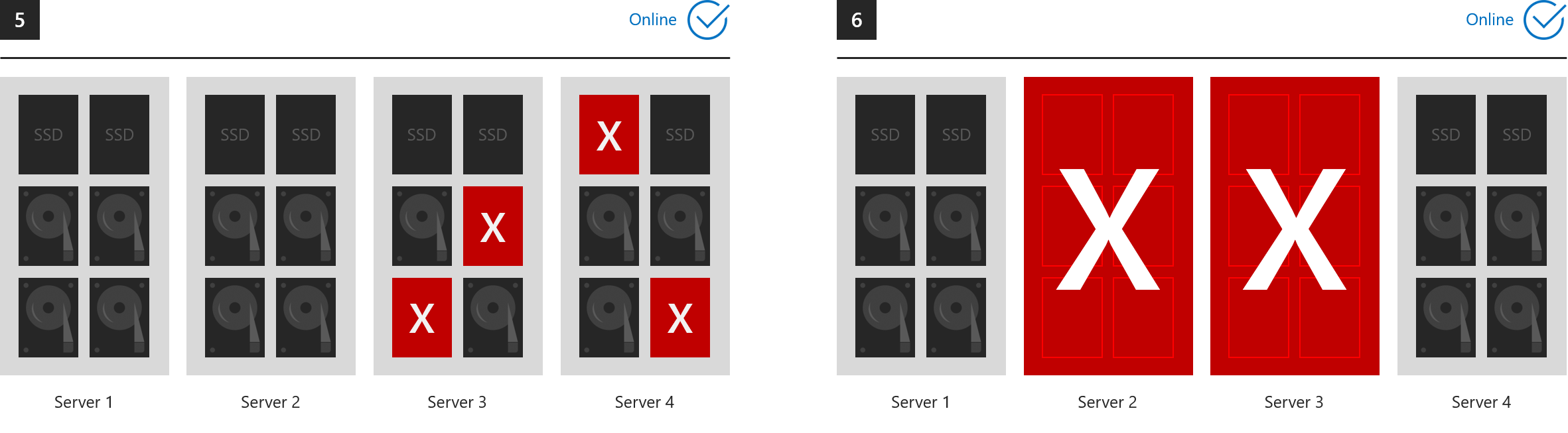
... Em todos os casos, todos os volumes permanecem online. (Verifique se o cluster mantém o quórum.)
Exemplos em que tudo fica offline
Ao longo de sua vida útil, os Espaços de Armazenamento podem tolerar qualquer número de falhas, porque restauram a resiliência total após cada uma delas, dado tempo suficiente. No entanto, no máximo dois domínios de falha podem ser afetados com segurança por falhas a qualquer momento. Seguem-se, portanto, exemplos do que o espelhamento tripartido e/ou a paridade dupla não podem tolerar.
- 7. Unidades perdidas em três ou mais servidores ao mesmo tempo
- 8. Três ou mais servidores perdidos de uma só vez
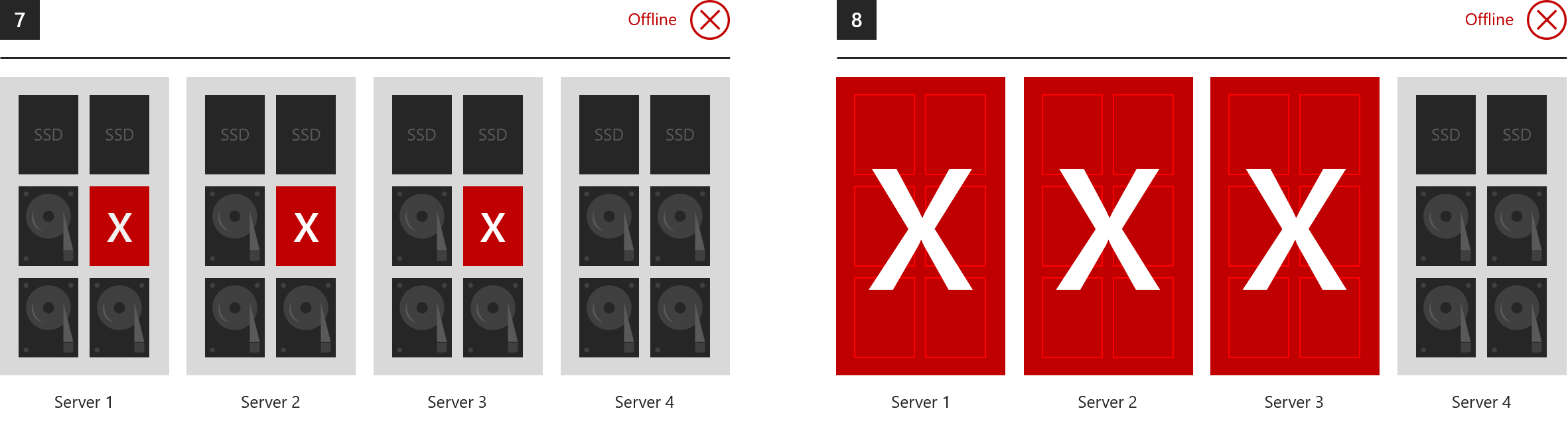
Utilização
Próximos passos
Para mais informações sobre os assuntos mencionados neste artigo, consulte o seguinte: