Tutorial: Realizar pesquisa de semelhança vetorial em incorporações do Azure OpenAI usando o Cache do Azure para Redis
Neste tutorial, você percorrerá um caso de uso básico de pesquisa de semelhança vetorial. Você usará incorporações geradas pelo Serviço OpenAI do Azure e os recursos internos de pesquisa vetorial da camada Enterprise do Cache Redis do Azure para consultar um conjunto de dados de filmes para encontrar a correspondência mais relevante.
O tutorial usa o conjunto de dados Wikipedia Movie Plots que apresenta descrições de enredos de mais de 35.000 filmes da Wikipédia cobrindo os anos de 1901 a 2017. O conjunto de dados inclui um resumo do enredo de cada filme, além de metadados como o ano em que o filme foi lançado, o(s) diretor(es), elenco principal e gênero. Você seguirá as etapas do tutorial para gerar incorporações com base no resumo do gráfico e usar os outros metadados para executar consultas híbridas.
Neste tutorial, irá aprender a:
- Criar uma instância do Cache do Azure para Redis configurada para pesquisa vetorial
- Instale o Azure OpenAI e outras bibliotecas Python necessárias.
- Faça o download do conjunto de dados do filme e prepare-o para análise.
- Use o modelo text-embedding-ada-002 (Versão 2) para gerar incorporações.
- Criar um índice de vetor no Cache Redis do Azure
- Use a semelhança cosseno para classificar os resultados da pesquisa.
- Use a funcionalidade de consulta híbrida através do RediSearch para pré-filtrar os dados e tornar a pesquisa vetorial ainda mais poderosa.
Importante
Este tutorial irá guiá-lo através da construção de um Jupyter Notebook. Você pode seguir este tutorial com um arquivo de código Python (.py) e obter resultados semelhantes , mas você precisará adicionar todos os blocos de código neste tutorial no arquivo e executar uma vez para ver os .py resultados. Em outras palavras, o Jupyter Notebooks fornece resultados intermediários à medida que você executa células, mas esse não é um comportamento que você deve esperar ao trabalhar em um arquivo de código Python.
Importante
Se você quiser acompanhar em um bloco de anotações Jupyter concluído, baixe o arquivo do bloco de anotações Jupyter chamado tutorial.ipynb e salve-o na nova pasta redis-vector .
Pré-requisitos
- Uma assinatura do Azure - Crie uma gratuitamente
- Acesso concedido ao Azure OpenAI na subscrição pretendida do Azure. Atualmente, você deve solicitar acesso ao Azure OpenAI. Você pode solicitar acesso ao Azure OpenAI preenchendo o formulário em https://aka.ms/oai/access.
- Python 3.8 ou versão posterior
- Cadernos Jupyter (opcional)
- Um recurso OpenAI do Azure com o modelo text-embedding-ada-002 (Versão 2) implantado. Atualmente, este modelo só está disponível em determinadas regiões. Consulte o guia de implantação de recursos para obter instruções sobre como implantar o modelo.
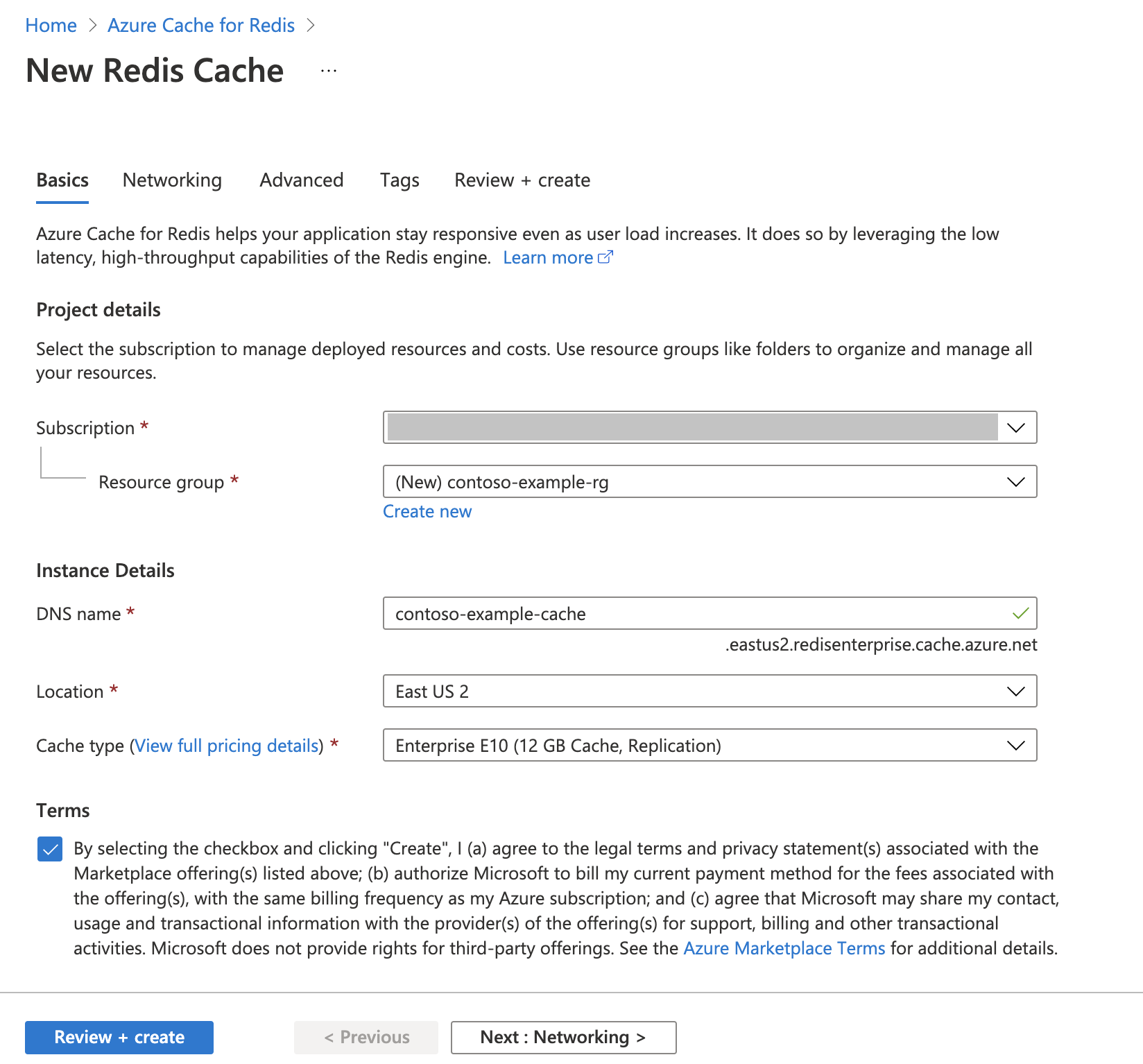
Criar um Cache do Azure para Instância Redis
Siga o Guia de início rápido: criar um guia de cache do Redis Enterprise. Na página Avançado, certifique-se de que adicionou o módulo RediSearch e escolheu a Política de Cluster Empresarial. Todas as outras configurações podem corresponder ao padrão descrito no início rápido.
Leva alguns minutos para o cache ser criado. Enquanto isso, você pode passar para a próxima etapa.
Configurar o ambiente de desenvolvimento
Crie uma pasta em seu computador local chamada redis-vector no local onde você normalmente salva seus projetos.
Crie um novo arquivo python (tutorial.py) ou um bloco de anotações Jupyter (tutorial.ipynb) na pasta.
Instale os pacotes Python necessários:
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
Faça o download do conjunto de dados
Em um navegador da Web, navegue até https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots.
Inicie sessão ou registe-se com o Kaggle. É necessário registar-se para descarregar o ficheiro.
Selecione o link Download no Kaggle para baixar o arquivo archive.zip .
Extraia o arquivo archive.zip e mova o wiki_movie_plots_deduped.csv para a pasta redis-vector .
Importar bibliotecas e configurar informações de conexão
Para fazer uma chamada com êxito no Azure OpenAI, você precisa de um ponto de extremidade e uma chave. Você também precisa de um ponto de extremidade e uma chave para se conectar ao Cache do Azure para Redis.
Vá para o seu recurso do Azure OpenAI no portal do Azure.
Localize Ponto de Extremidade e Chaves na seção Gerenciamento de Recursos. Copie seu endpoint e sua chave de acesso, pois você precisará de ambos para autenticar suas chamadas de API. Um exemplo de ponto de extremidade é:
https://docs-test-001.openai.azure.com. Pode utilizarKEY1ouKEY2.Vá para a página Visão geral do seu recurso Cache do Azure para Redis no portal do Azure. Copie seu ponto de extremidade.
Localize as teclas de acesso na seção Configurações . Copie a sua chave de acesso. Pode utilizar
PrimaryouSecondary.Adicione o seguinte código a uma nova célula de código:
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"Atualize o valor de e
RESOURCE_ENDPOINTcom os valores deAPI_KEYchave e ponto de extremidade de sua implantação do Azure OpenAI.DEPLOYMENT_NAMEdeve ser definido como o nome da sua implantação usando otext-embedding-ada-002 (Version 2)modelo de incorporações eMODEL_NAMEdeve ser o modelo de incorporação específico usado.Atualize
REDIS_ENDPOINTeREDIS_PASSWORDcom o ponto de extremidade e o valor da chave da sua instância do Cache do Azure para Redis.Importante
É altamente recomendável usar variáveis ambientais ou um gerenciador secreto como o Azure Key Vault para passar as informações de chave de API, ponto de extremidade e nome de implantação. Essas variáveis são definidas em texto simples aqui por uma questão de simplicidade.
Execute a célula de código 2.
Importar conjunto de dados para pandas e processar dados
Em seguida, você lerá o arquivo csv em um DataFrame pandas.
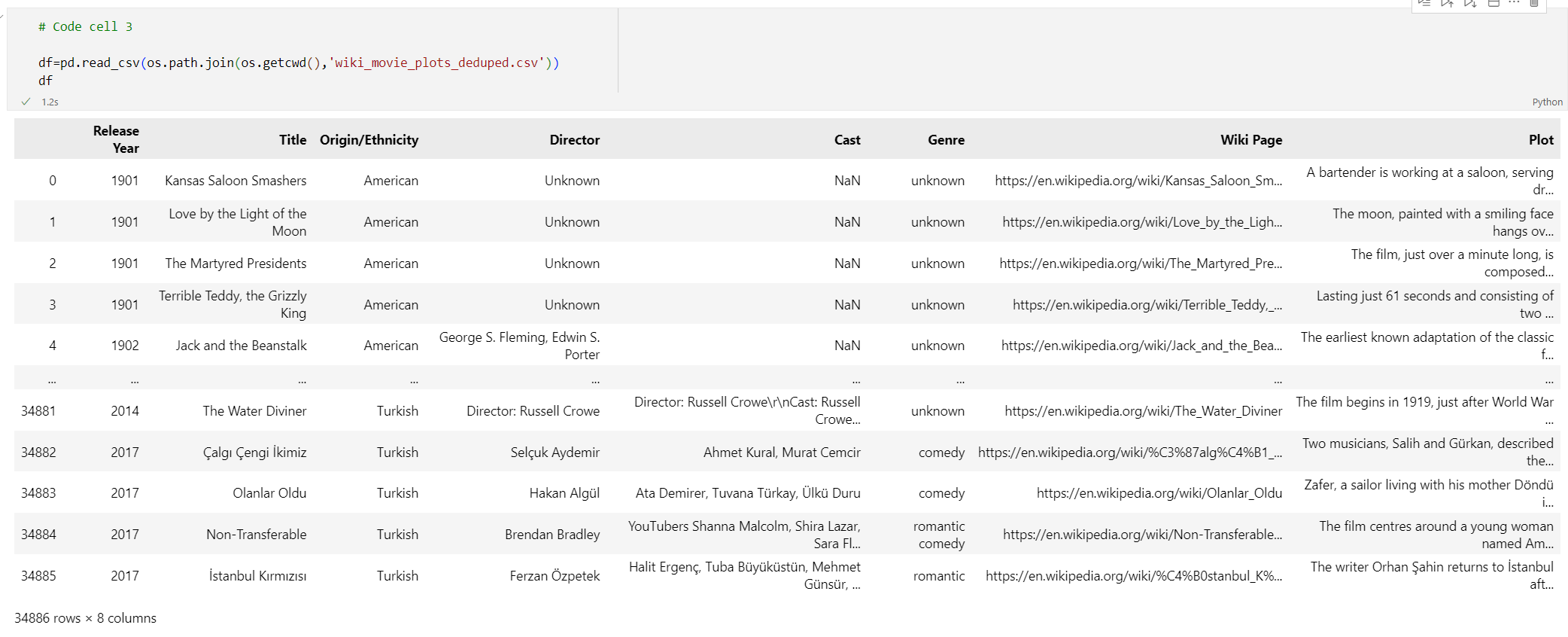
Adicione o seguinte código a uma nova célula de código:
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) dfExecute a célula de código 3. Deverá ver o seguinte resultado:
Em seguida, processe os dados adicionando um
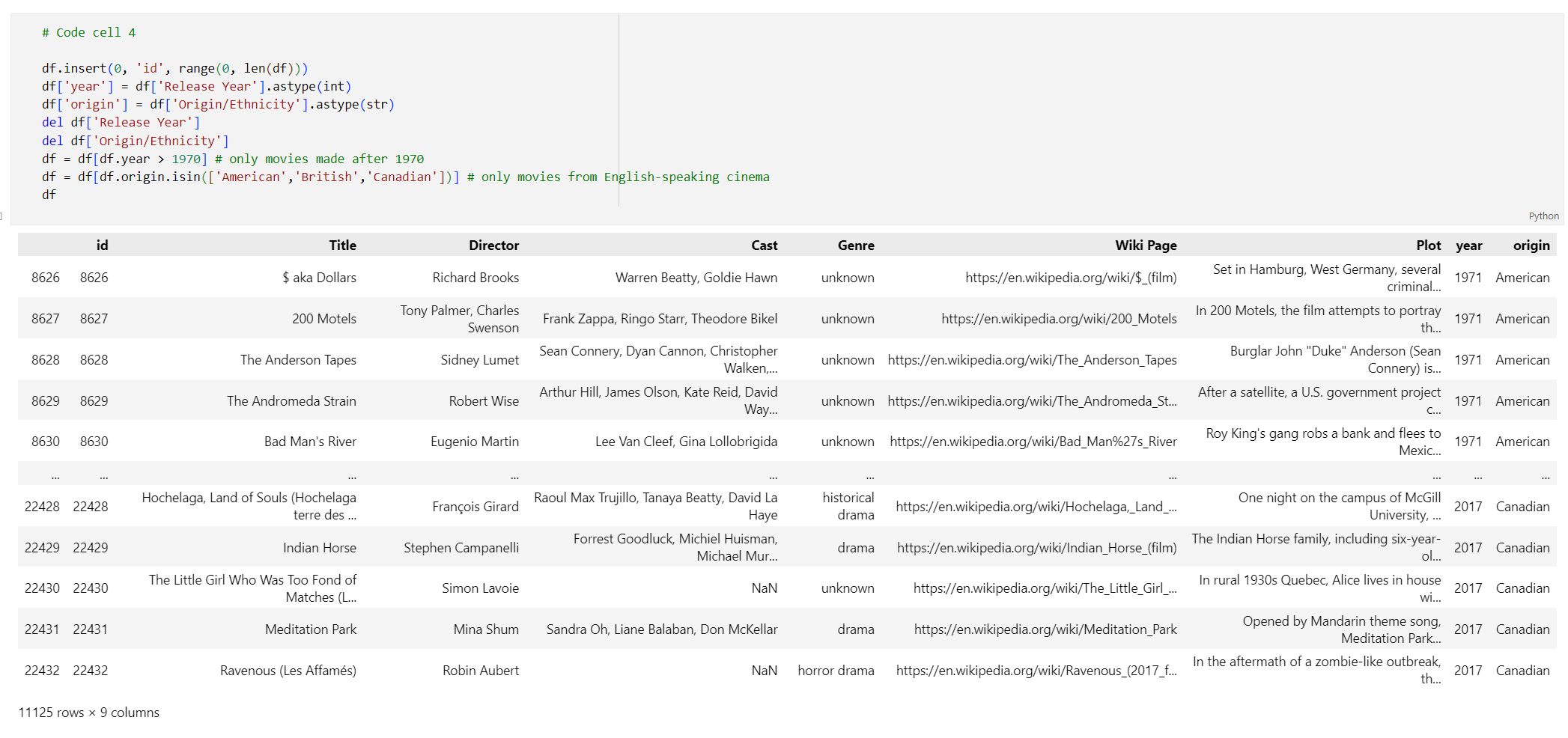
idíndice, removendo espaços dos títulos das colunas e filtrando os filmes para levar apenas filmes feitos após 1970 e de países ou regiões de língua inglesa. Esta etapa de filtragem reduz o número de filmes no conjunto de dados, o que reduz o custo e o tempo necessários para gerar incorporações. Você é livre para alterar ou remover os parâmetros de filtro com base em suas preferências.Para filtrar os dados, adicione o seguinte código a uma nova célula de código:
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema dfExecute a célula de código 4. Deverá ver os seguintes resultados:
Crie uma função para limpar os dados removendo o espaço em branco e a pontuação e, em seguida, use-a no dataframe que contém o gráfico.
Adicione o seguinte código a uma nova célula de código e execute-o:
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))Por fim, remova todas as entradas que contenham descrições de gráfico muito longas para o modelo de incorporações. (Em outras palavras, eles exigem mais tokens do que o limite de token 8192.) e, em seguida, calcular o número de tokens necessários para gerar incorporações. Isso também afeta os preços para a geração incorporada.
Adicione o seguinte código a uma nova célula de código:
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))Execute a célula de código 6. Deverá ver este resultado:
Number of movies: 11125 Number of tokens required:7044844Importante
Consulte os preços do Serviço OpenAI do Azure para calcular o custo de geração de incorporações com base no número de tokens necessários.


Carregue DataFrame em LangChain
Carregue o DataFrame em LangChain usando a DataFrameLoader classe. Uma vez que os dados estão em documentos LangChain, é muito mais fácil usar bibliotecas LangChain para gerar incorporações e realizar pesquisas de similaridade. Defina Plotar como o page_content_column modo para que as incorporações sejam geradas nesta coluna.
Adicione o seguinte código a uma nova célula de código e execute-o:
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
Gere incorporações e carregue-as no Redis
Agora que os dados foram filtrados e carregados no LangChain, você criará incorporações para que possa consultar o enredo de cada filme. O código a seguir configura o Azure OpenAI, gera incorporações e carrega os vetores de incorporação no Cache do Azure para Redis.
Adicione o seguinte código uma nova célula de código:
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")Execute a célula de código 8. Isso pode levar mais de 30 minutos para ser concluído. Um
redis_schema.yamlarquivo também é gerado. Esse arquivo é útil se você quiser se conectar ao seu índice na instância do Cache do Azure para Redis sem gerar incorporações novamente.
Importante
A velocidade com que as incorporações são geradas depende da cota disponível para o Modelo OpenAI do Azure. Com uma cota de 240 mil tokens por minuto, levará cerca de 30 minutos para processar os 7 milhões de tokens no conjunto de dados.
Executar consultas de pesquisa vetorial
Agora que seu conjunto de dados, a API de serviço do Azure OpenAI e a instância do Redis estão configurados, você pode pesquisar usando vetores. Neste exemplo, os 10 principais resultados de uma determinada consulta são retornados.
Adicione o seguinte código ao seu arquivo de código Python:
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Execute a célula de código 9. Deverá ver o seguinte resultado:
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)A pontuação de semelhança é retornada juntamente com a classificação ordinal de filmes por semelhança. Observe que consultas mais específicas têm pontuações de semelhança que diminuem mais rapidamente na lista.
Pesquisas híbridas
Como o RediSearch também possui uma rica funcionalidade de pesquisa além da pesquisa vetorial, é possível filtrar os resultados pelos metadados no conjunto de dados, como gênero de filme, elenco, ano de lançamento ou diretor. Neste caso, filtro com base no gênero
comedy.Adicione o seguinte código a uma nova célula de código:
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Execute a célula de código 10. Deverá ver o seguinte resultado:
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
Com o Cache do Azure para Redis e o Serviço OpenAI do Azure, você pode usar incorporações e pesquisa vetorial para adicionar recursos de pesquisa poderosos ao seu aplicativo.
Clean up resources (Limpar recursos)
Se quiser continuar a usar os recursos criados neste artigo, mantenha o grupo de recursos.
Caso contrário, se tiver terminado os recursos, pode eliminar o grupo de recursos do Azure que criou para evitar cobranças.
Importante
A eliminação de um grupo de recursos é irreversível. Quando elimina um grupo de recursos, todos os recursos nele contidos são eliminados permanentemente. Confirme que não elimina acidentalmente o grupo de recursos ou recursos errados. Se você criou os recursos dentro de um grupo de recursos existente que contém recursos que deseja manter, poderá excluir cada recurso individualmente em vez de excluir o grupo de recursos.
Para eliminar um grupo de recursos
Inicie sessão no Portal do Azure e selecione Grupos de recursos.
Selecione o grupo de recursos que pretende eliminar.
Se houver muitos grupos de recursos, use a caixa Filtrar para qualquer campo... , digite o nome do grupo de recursos criado para este artigo. Selecione o grupo de recursos na lista de resultados.
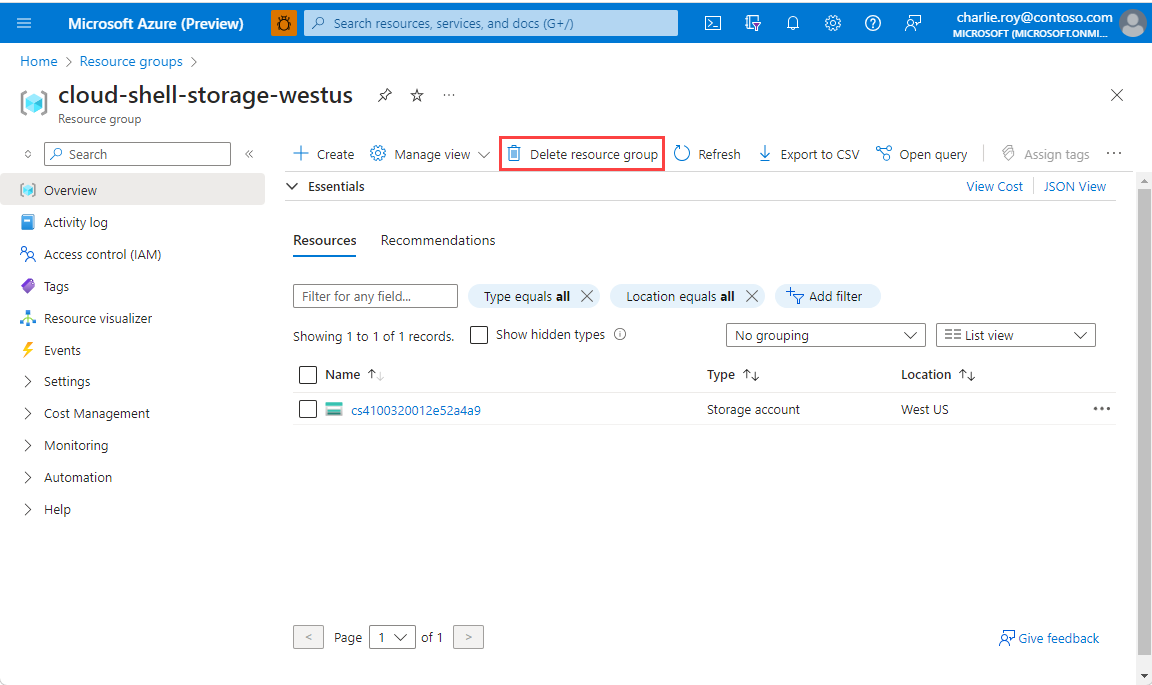
Selecione Eliminar grupo de recursos.
É-lhe pedido que confirme a eliminação do grupo de recursos. Escreva o nome do grupo de recursos para confirmar e, em seguida, selecione Eliminar.
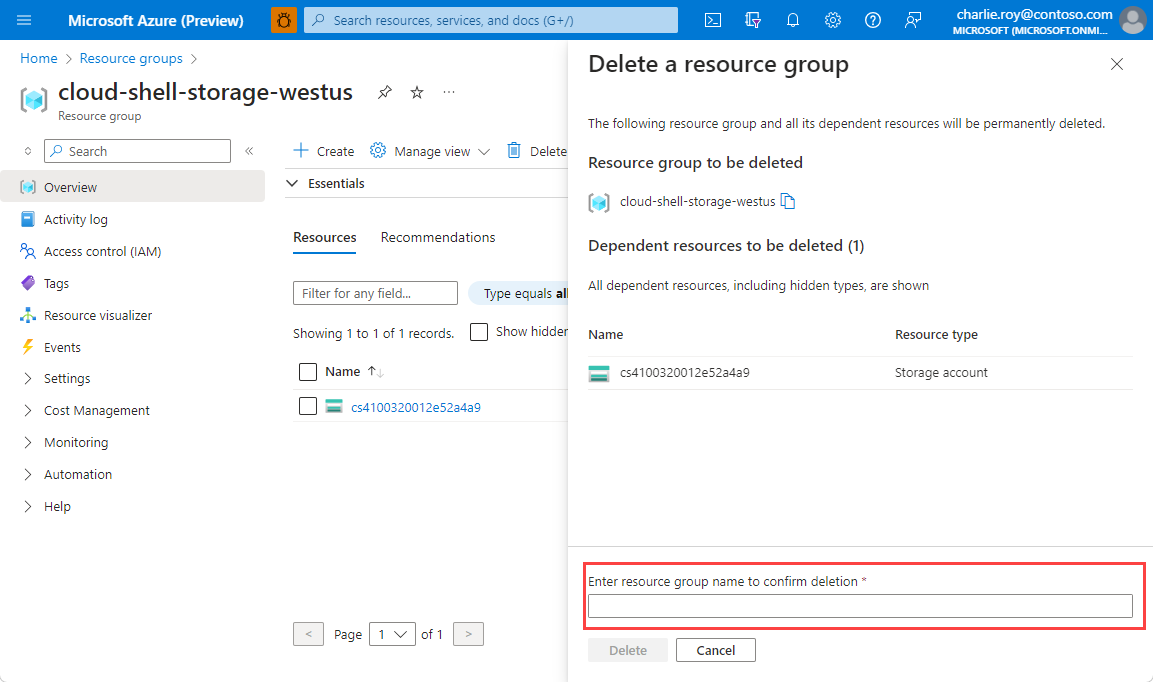
Após alguns instantes, o grupo de recursos e todos os respetivos recursos são eliminados.
Conteúdo relacionado
- Saiba mais sobre a Cache do Azure para Redis
- Saiba mais sobre os recursos de pesquisa vetorial do Cache do Azure para Redis
- Saiba mais sobre incorporações geradas pelo Serviço OpenAI do Azure
- Saiba mais sobre a semelhança de cosseno
- Leia como criar um aplicativo alimentado por IA com OpenAI e Redis
- Crie um aplicativo de perguntas e respostas com respostas semânticas