Considerações sobre a plataforma de aplicativos para cargas de trabalho de missão crítica
Uma área-chave de design de qualquer arquitetura de missão crítica é a plataforma de aplicativos. Plataforma refere-se aos componentes de infraestrutura e serviços do Azure que devem ser provisionados para dar suporte ao aplicativo. Aqui estão algumas recomendações gerais.
Design em camadas. Escolha o conjunto certo de serviços, sua configuração e as dependências específicas do aplicativo. Esta abordagem em camadas ajuda na criação de segmentação lógica e física. É útil para definir funções e funções, atribuir privilégios apropriados e estratégias de implantação. Esta abordagem acaba por aumentar a fiabilidade do sistema.
Um aplicativo de missão crítica deve ser altamente confiável e resistente a falhas regionais e de datacenter. Construir redundância zonal e regional em uma configuração ativo-ativo é a principal estratégia. Ao escolher os serviços do Azure para a plataforma do seu aplicativo, considere o suporte às Zonas de Disponibilidade e os padrões operacionais e de implantação para usar várias regiões do Azure.
Use uma arquitetura baseada em unidades de escala para lidar com o aumento da carga. As unidades de escala permitem agrupar recursos logicamente e uma unidade pode ser dimensionada independentemente de outras unidades ou serviços na arquitetura. Use seu modelo de capacidade e desempenho esperado para definir os limites, o número e a escala de linha de base de cada unidade.
Nessa arquitetura, a plataforma de aplicativo consiste em recursos globais, de carimbo de implantação e regionais. Os recursos regionais são provisionados como parte de um selo de implantação. Cada selo equivale a uma unidade de escala e, caso se torne insalubre, pode ser totalmente substituído.
Os recursos em cada camada têm características distintas. Para obter mais informações, consulte Padrão de arquitetura de uma carga de trabalho típica de missão crítica.
| Características | Considerações |
|---|---|
| Vitalício | Qual é o tempo de vida esperado do recurso, em relação a outros recursos na solução? O recurso deve sobreviver ou partilhar o tempo de vida com todo o sistema ou região, ou deve ser temporário? |
| Estado | Que impacto terá o estado persistente nesta camada na fiabilidade ou capacidade de gestão? |
| Reach | É necessário que o recurso seja distribuído globalmente? O recurso pode se comunicar com outros recursos, globalmente ou em regiões? |
| Dependências | Qual é a dependência de outros recursos, globalmente ou em outras regiões? |
| Limites de escala | Qual é a taxa de transferência esperada para esse recurso nessa camada? Quanta escala é fornecida pelo recurso para atender a essa demanda? |
| Disponibilidade/recuperação de desastres | Qual é o impacto na disponibilidade ou no desastre nessa camada? Isso causaria uma interrupção sistêmica ou apenas um problema de capacidade ou disponibilidade localizada? |
Recursos globais
Certos recursos nessa arquitetura são compartilhados por recursos implantados em regiões. Nessa arquitetura, eles são usados para distribuir o tráfego entre várias regiões, armazenar o estado permanente de todo o aplicativo e armazenar em cache dados estáticos globais.
| Características | Considerações sobre a camada |
|---|---|
| Vitalício | Espera-se que estes recursos sejam duradouros. A sua vida útil abrange a vida útil do sistema ou mais. Muitas vezes, os recursos são gerenciados com dados in-loco e atualizações do plano de controle, supondo que suportem operações de atualização sem tempo de inatividade. |
| Estado | Como esses recursos existem pelo menos durante a vida útil do sistema, essa camada geralmente é responsável por armazenar o estado global replicado geograficamente. |
| Reach | Os recursos devem ser distribuídos globalmente. Recomenda-se que esses recursos se comuniquem com recursos regionais ou outros com baixa latência e a consistência desejada. |
| Dependências | Os recursos devem evitar dependências de recursos regionais, porque a sua indisponibilidade pode ser uma causa de fracasso global. Por exemplo, certificados ou segredos mantidos em um único cofre podem ter impacto global se houver uma falha regional onde o cofre está localizado. |
| Limites de escala | Muitas vezes, esses recursos são instâncias singleton no sistema e, como tal, eles devem ser capazes de dimensionar de modo que possam lidar com a taxa de transferência do sistema como um todo. |
| Disponibilidade/recuperação de desastres | Como os recursos regionais e de carimbo podem consumir recursos globais ou são liderados por eles, é fundamental que os recursos globais sejam configurados com alta disponibilidade e recuperação de desastres para a integridade de todo o sistema. |
Nessa arquitetura, os recursos de camada global são Azure Front Door, Azure Cosmos DB, Azure Container Registry e Azure Log Analytics para armazenar logs e métricas de outros recursos de camada global.
Há outros recursos fundamentais nesse design, como o Microsoft Entra ID e o DNS do Azure. Foram omitidos nesta imagem por uma questão de brevidade.

Balanceador de carga global
O Azure Front Door é usado como o único ponto de entrada para o tráfego de usuários. O Azure garante que o Azure Front Door entregará o conteúdo solicitado sem erro 99,99% do tempo. Para obter mais detalhes, consulte Limites de serviço da porta da frente. Se o Front Door ficar indisponível, o usuário final verá o sistema inativo.
A instância Front Door envia tráfego para os serviços de back-end configurados, como o cluster de computação que hospeda a API e o SPA frontend. Erros de configuração de back-end no Front Door podem levar a interrupções. Para evitar interrupções devido a configurações incorretas, você deve testar extensivamente as configurações da porta da frente.
Outro erro comum pode vir de certificados TLS mal configurados ou ausentes, o que pode impedir que os usuários usem o front-end ou a Front Door se comunicando com o back-end. A atenuação pode exigir intervenção manual. Por exemplo, você pode optar por reverter para a configuração anterior e reemitir o certificado, se possível. Independentemente disso, espere indisponibilidade enquanto as alterações entram em vigor. O uso de certificados gerenciados oferecidos pela Front door é recomendado para reduzir a sobrecarga operacional, como lidar com a expiração.
O Front Door oferece muitos recursos adicionais além do roteamento de tráfego global. Um recurso importante é o Web Application Firewall (WAF), porque o Front Door é capaz de inspecionar o tráfego que está passando. Quando configurado no modo de prevenção, ele bloqueará o tráfego suspeito antes mesmo de chegar a qualquer um dos back-ends.
Para obter informações sobre os recursos do Front Door, consulte Perguntas frequentes sobre o Azure Front Door.
Para obter outras considerações sobre a distribuição global do tráfego, consulte Orientação de missão crítica em Estrutura bem arquitetada: roteamento global.
Container Registry
O Registro de Contêiner do Azure é usado para armazenar artefatos da Open Container Initiative (OCI), especificamente gráficos de leme e imagens de contêiner. Ele não participa do fluxo de solicitações e só é acessado periodicamente. É necessário que o registro de contêiner exista antes que os recursos de carimbo sejam implantados e não deve depender de recursos de camada regional.
Habilite a redundância de zona e a replicação geográfica de registros para que o acesso em tempo de execução às imagens seja rápido e resiliente a falhas. Em caso de indisponibilidade, a instância pode fazer failover para regiões de réplica e as solicitações são automaticamente redirecionadas para outra região. Espere erros transitórios na extração de imagens até que o failover seja concluído.
Falhas também podem ocorrer se as imagens forem excluídas inadvertidamente, novos nós de computação não poderão extrair imagens, mas os nós existentes ainda poderão usar imagens armazenadas em cache. A principal estratégia para a recuperação de desastres é a reimplantação. Os artefatos em um registro de contêiner podem ser regenerados a partir de pipelines. O registro de contêiner deve ser capaz de suportar muitas conexões simultâneas para dar suporte a todas as suas implantações.
É recomendável usar o SKU Premium para habilitar a replicação geográfica. O recurso de redundância de zona garante resiliência e alta disponibilidade em uma região específica. Em caso de interrupção regional, réplicas em outras regiões ainda estão disponíveis para operações de plano de dados. Com este SKU pode restringir o acesso a imagens através de terminais privados.
Para obter mais detalhes, consulte Práticas recomendadas para o Registro de Contêiner do Azure.
Base de Dados
Recomenda-se que todos os estados sejam armazenados globalmente em um banco de dados separado dos selos regionais. Crie redundância implantando o banco de dados entre regiões. Para cargas de trabalho de missão crítica, a sincronização de dados entre regiões deve ser a principal preocupação. Além disso, em caso de falha, as solicitações de gravação no banco de dados ainda devem ser funcionais.
A replicação de dados em uma configuração ativo-ativo é altamente recomendada. O aplicativo deve ser capaz de se conectar instantaneamente com outra região. Todas as instâncias devem ser capazes de lidar com solicitações de leitura e gravação.
Para obter mais informações, consulte Plataforma de dados para cargas de trabalho de missão crítica.
Monitorização global
O Azure Log Analytics é usado para armazenar logs de diagnóstico de todos os recursos globais. É recomendável restringir a cota diária de armazenamento, especialmente em ambientes usados para testes de carga. Além disso, defina a política de retenção. Essas restrições evitarão qualquer gasto excessivo incorrido com o armazenamento de dados que não são necessários além de um limite.
Considerações para serviços fundamentais
É provável que o sistema use outros serviços de plataforma críticos que podem fazer com que todo o sistema esteja em risco, como o DNS do Azure e o ID do Microsoft Entra. O DNS do Azure garante 100% de disponibilidade SLA para solicitações DNS válidas. O Microsoft Entra garante pelo menos 99,99% de tempo de atividade. Ainda assim, você deve estar ciente do impacto no caso de uma falha.
Depender fortemente dos serviços fundamentais é inevitável porque muitos serviços do Azure dependem deles. Espere interrupções no sistema se eles não estiverem disponíveis. Por exemplo:
- O Azure Front Door usa o DNS do Azure para alcançar o back-end e outros serviços globais.
- O Registro de Contêiner do Azure usa o DNS do Azure para fazer failover de solicitações para outra região.
Em ambos os casos, ambos os serviços do Azure serão afetados se o DNS do Azure não estiver disponível. A resolução de nomes para solicitações de usuários do Front Door falhará; As imagens do Docker não serão extraídas do registro. Usar um serviço DNS externo como backup não reduzirá o risco porque muitos serviços do Azure não permitem essa configuração e dependem do DNS interno. Espere uma interrupção total.
Da mesma forma, o Microsoft Entra ID é usado para operações de plano de controle, como a criação de novos nós AKS, extração de imagens do Registro de contêiner ou acesso ao Cofre de Chaves na inicialização do pod. Se o Microsoft Entra ID não estiver disponível, os componentes existentes não devem ser afetados, mas o desempenho geral pode ser degradado. Novos pods ou nós AKS não serão funcionais. Portanto, caso sejam necessárias operações de expansão durante esse período, espere uma experiência menor do usuário.
Recursos de carimbo de implantação regional
Nessa arquitetura, o carimbo de implantação implanta a carga de trabalho e provisiona recursos que participam da conclusão de transações comerciais. Um carimbo normalmente corresponde a uma implantação em uma região do Azure. Embora uma região possa ter mais de um carimbo.
| Características | Considerações |
|---|---|
| Vitalício | Espera-se que os recursos tenham uma vida útil curta (efêmera) com a intenção de que possam ser adicionados e removidos dinamicamente, enquanto os recursos regionais fora do selo continuam a persistir. A natureza efêmera é necessária para fornecer mais resiliência, escala e proximidade com os usuários. |
| Estado | Como os selos são efêmeros e podem ser destruídos a qualquer momento, um selo deve ser apátrida tanto quanto possível. |
| Reach | É capaz de comunicar com recursos regionais e globais. No entanto, a comunicação com outras regiões ou outros selos deve ser evitada. Nessa arquitetura, não há necessidade de que esses recursos sejam distribuídos globalmente. |
| Dependências | Os recursos do selo devem ser independentes. Ou seja, não devem depender de outros selos ou componentes em outras regiões. Espera-se que tenham dependências regionais e globais. O principal componente compartilhado é a camada de banco de dados e o registro de contêiner. Este componente requer sincronização em tempo de execução. |
| Limites de escala | A taxa de transferência é estabelecida por meio de testes. A taxa de transferência do carimbo geral é limitada ao recurso de menor desempenho. A taxa de transferência de selos precisa levar em conta o alto nível estimado de demanda e qualquer failover como resultado de outro carimbo na região ficar indisponível. |
| Disponibilidade/recuperação de desastres | Devido à natureza temporária dos selos, a recuperação de desastres é feita reimplantando o carimbo. Se os recursos estiverem em mau estado, o carimbo, como um todo, pode ser destruído e redistribuído. |
Nessa arquitetura, os recursos de carimbo são o Serviço Kubernetes do Azure, os Hubs de Eventos do Azure, o Cofre da Chave do Azure e o Armazenamento de Blobs do Azure.
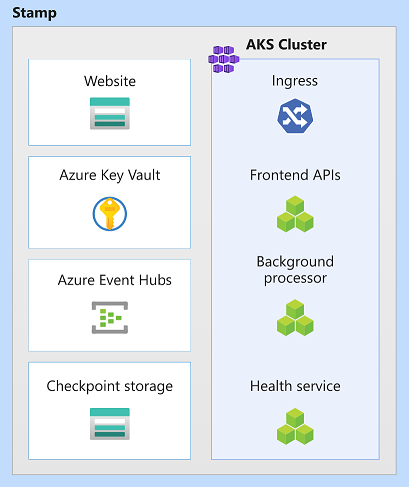
Unidade de escala
Um selo também pode ser considerado como uma unidade de escala (SU). Todos os componentes e serviços dentro de um determinado carimbo são configurados e testados para atender solicitações em um determinado intervalo. Aqui está um exemplo de uma unidade de escala usada na implementação.
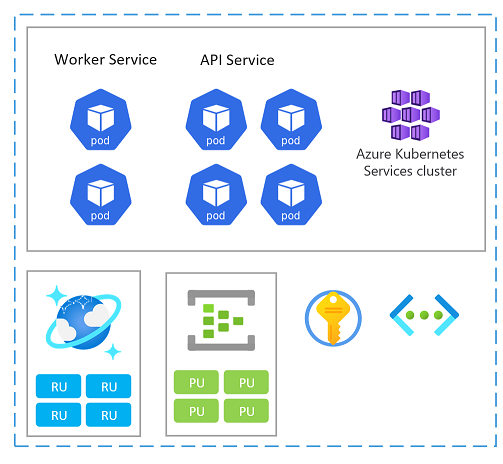
Cada unidade de escala é implantada em uma região do Azure e, portanto, lida principalmente com o tráfego dessa determinada área (embora possa assumir o tráfego de outras regiões quando necessário). Essa dispersão geográfica provavelmente resultará em padrões de carga e horas comerciais que podem variar de região para região e, como tal, cada SU é projetado para aumentar ou diminuir quando ocioso.
Você pode implantar um novo carimbo para dimensionar. Dentro de um carimbo, os recursos individuais também podem ser unidades de escala.
Aqui estão algumas considerações de dimensionamento e disponibilidade ao escolher os serviços do Azure em uma unidade:
Avaliar as relações de capacidade entre todos os recursos em uma unidade de escala. Por exemplo, para lidar com 100 solicitações de entrada, seriam necessários 5 pods de controlador de entrada e 3 pods de serviço de catálogo e 1000 RUs no Azure Cosmos DB. Portanto, ao dimensionar automaticamente os pods de entrada, espere o dimensionamento do serviço de catálogo e das RUs do Azure Cosmos DB dados esses intervalos.
Teste a carga dos serviços para determinar um intervalo dentro do qual as solicitações serão atendidas. Com base nos resultados, configure instâncias mínimas e máximas e métricas de destino. Quando a meta é atingida, você pode optar por automatizar o dimensionamento de toda a unidade.
Analise os limites de escala e as cotas de assinatura do Azure para dar suporte ao modelo de capacidade e custo definido pelos requisitos de negócios. Verifique também os limites de serviços individuais em consideração. Como as unidades normalmente são implantadas juntas, considere os limites de recursos de assinatura necessários para implantações canárias. Para obter mais informações, consulte Limites de serviço do Azure.
Escolha serviços que ofereçam suporte a zonas de disponibilidade para criar redundância. Isso pode limitar suas escolhas tecnológicas. Consulte Zonas de disponibilidade para obter detalhes.
Para obter outras considerações sobre o tamanho de uma unidade e a combinação de recursos, consulte Orientação de missão crítica em Estrutura bem arquitetada: arquitetura de unidade de escala.
Cluster de cálculo
Para contentorizar a carga de trabalho, cada carimbo precisa executar um cluster de computação. Nessa arquitetura, o Serviço Kubernetes do Azure (AKS) é escolhido porque o Kubernetes é a plataforma de computação mais popular para aplicativos modernos e conteinerizados.
O tempo de vida do cluster AKS está ligado à natureza efêmera do selo. O cluster é sem monitoração de estado e não tem volumes persistentes. Ele usa discos efêmeros do sistema operacional em vez de discos gerenciados, porque não se espera que eles recebam manutenção no nível do aplicativo ou do sistema.
Para aumentar a confiabilidade, o cluster é configurado para usar as três zonas de disponibilidade em uma determinada região. Além disso, para habilitar o SLA de tempo de atividade do AKS com disponibilidade garantida de 99,95% de SLA do plano de controle do AKS, o cluster deve usar o nível Standard ou Premium. Consulte os níveis de preços do AKS para saber mais.
Outros fatores, como limites de escala, capacidade de computação e cota de assinatura, também podem afetar a confiabilidade. Se não houver capacidade suficiente ou se forem atingidos limites, as operações de expansão e expansão falharão, mas espera-se que a computação existente funcione.
O cluster tem o dimensionamento automático habilitado para permitir que os pools de nós se expandam automaticamente, se necessário, o que melhora a confiabilidade. Ao usar vários pools de nós, todos os pools de nós devem ser dimensionados automaticamente.
No nível do pod, o Horizontal Pod Autoscaler (HPA) dimensiona pods com base em CPU, memória ou métricas personalizadas configuradas. Teste de carga os componentes da carga de trabalho para estabelecer uma linha de base para os valores de autoscaler e HPA.
O cluster também é configurado para atualizações automáticas de imagem de nó e para ser dimensionado adequadamente durante essas atualizações. Esse dimensionamento permite zero tempo de inatividade enquanto as atualizações estão sendo executadas. Se o cluster em um carimbo falhar durante uma atualização, outros clusters em outros carimbos não deverão ser afetados, mas as atualizações entre carimbos deverão ocorrer em momentos diferentes para manter a disponibilidade. Além disso, as atualizações de cluster são automaticamente roladas pelos nós para que não fiquem indisponíveis ao mesmo tempo.
Alguns componentes, como cert-manager e ingress-nginx, exigem imagens de contêiner de registros de contêiner externos. Se esses repositórios ou imagens não estiverem disponíveis, novas instâncias em novos nós (onde a imagem não é armazenada em cache) podem não ser capazes de iniciar. Esse risco pode ser atenuado importando essas imagens para o Registro de Contêiner do Azure do ambiente.
A observabilidade é fundamental nesta arquitetura porque os selos são efêmeros. As configurações de diagnóstico são definidas para armazenar todos os dados de log e métricas em um espaço de trabalho regional do Log Analytics. Além disso, o AKS Container Insights é habilitado por meio de um Agente OMS no cluster. Esse agente permite que o cluster envie dados de monitoramento para o espaço de trabalho do Log Analytics.
Para obter outras considerações sobre o cluster de computação, consulte Orientação de missão crítica em Estrutura bem arquitetada: orquestração de contêineres e Kubernetes.
Key Vault
O Azure Key Vault é usado para armazenar segredos globais, como cadeias de conexão para o banco de dados e segredos de carimbo, como a cadeia de conexão Hubs de Eventos.
Essa arquitetura usa um driver CSI do Secrets Store no cluster de computação para obter segredos do Cofre de Chaves. Segredos são necessários quando novos pods são gerados. Se o Key Vault não estiver disponível, os novos pods podem não começar. Como resultado, pode haver perturbação; As operações de expansão podem ser afetadas, as atualizações podem falhar, novas implantações não podem ser executadas.
O Key Vault tem um limite para o número de operações. Devido à atualização automática de segredos, o limite pode ser atingido se houver muitos pods. Você pode optar por diminuir a frequência de atualizações para evitar essa situação.
Para obter outras considerações sobre gerenciamento secreto, consulte Orientação de missão crítica em Well-architected Framework: Proteção de integridade de dados.
Hubs de Eventos
O único serviço com monitoração de estado no carimbo é o agente de mensagens, Hubs de Eventos do Azure, que armazena solicitações por um curto período. O corretor atende à necessidade de buffering e mensagens confiáveis. As solicitações processadas são mantidas no banco de dados global.
Nessa arquitetura, o SKU padrão é usado e a redundância de zona é habilitada para alta disponibilidade.
A integridade dos Hubs de Eventos é verificada pelo componente HealthService em execução no cluster de computação. Realiza verificações periódicas em relação a vários recursos. Isso é útil na deteção de condições insalubres. Por exemplo, se as mensagens não puderem ser enviadas para o hub de eventos, o carimbo ficará inutilizável para quaisquer operações de gravação. O HealthService deve detetar automaticamente essa condição e relatar o estado insalubre à Front Door, que retirará o carimbo da rotação.
Para escalabilidade, recomenda-se ativar a auto-inflação.
Para obter mais informações, consulte Serviços de mensagens para cargas de trabalho de missão crítica.
Para obter outras considerações sobre mensagens, consulte Orientação de missão crítica em Estrutura bem arquitetada: mensagens assíncronas.
Contas de armazenamento
Nessa arquitetura, duas contas de armazenamento são provisionadas. Ambas as contas são implantadas no modo de zona redundante (ZRS).
Uma conta é usada para pontos de verificação de Hubs de Eventos. Se essa conta não for responsiva, o carimbo não poderá processar mensagens de Hubs de Eventos e poderá até afetar outros serviços no selo. Essa condição é verificada periodicamente pelo HealthService, que é um dos componentes do aplicativo em execução no cluster de computação.
O outro é usado para hospedar o aplicativo de página única da interface do usuário. Se o serviço do site estático tiver algum problema, o Front Door detetará o problema e não enviará tráfego para essa conta de armazenamento. Durante esse tempo, o Front Door pode usar conteúdo armazenado em cache.
Para obter mais informações sobre recuperação, consulte Recuperação de desastres e failover de conta de armazenamento.
Recursos regionais
Um sistema pode ter recursos que são implantados na região, mas sobrevivem aos recursos de carimbo. Nessa arquitetura, os dados de observabilidade para recursos de carimbo são armazenados em armazenamentos de dados regionais.
| Características | Consideração |
|---|---|
| Vitalício | Os recursos partilham o tempo de vida da região e vivem os recursos do selo. |
| Estado | O Estado armazenado numa região não pode viver para além da vida útil da região. Se o estado precisar ser compartilhado entre regiões, considere o uso de um armazenamento de dados global. |
| Reach | Os recursos não precisam ser distribuídos globalmente. A comunicação direta com outras regiões deve ser evitada a todo o custo. |
| Dependências | Os recursos podem ter dependências de recursos globais, mas não de recursos de carimbo porque os selos devem ser de curta duração. |
| Limites de escala | Determinar o limite de escala dos recursos regionais combinando todos os selos dentro da região. |
Dados de monitorização dos recursos de carimbo
A implantação de recursos de monitoramento é um exemplo típico de recursos regionais. Nessa arquitetura, cada região tem um espaço de trabalho individual do Log Analytics configurado para armazenar todos os dados de log e métricas emitidos a partir de recursos de carimbo. Como os recursos regionais sobrevivem aos recursos de carimbo, os dados ficam disponíveis mesmo quando o carimbo é excluído.
O Azure Log Analytics e o Azure Application Insights são usados para armazenar logs e métricas da plataforma. É recomendável restringir a cota diária de armazenamento, especialmente em ambientes usados para testes de carga. Além disso, defina a política de retenção para armazenar todos os dados. Essas restrições evitarão qualquer gasto excessivo incorrido com o armazenamento de dados que não são necessários além de um limite.
Da mesma forma, o Application Insights também é implantado como um recurso regional para coletar todos os dados de monitoramento de aplicativos.
Para obter recomendações de design sobre monitoramento, consulte Orientações de missão crítica em Estrutura bem arquitetada: modelagem de integridade.
Próximos passos
Implante a implementação de referência para obter uma compreensão completa dos recursos e sua configuração usados nessa arquitetura.