Este artigo descreve como uma equipa de desenvolvimento utilizou métricas para encontrar estrangulamentos e melhorar o desempenho de um sistema distribuído. O artigo baseia-se no teste de carga real que foi feito para uma aplicação de exemplo. A aplicação é da Linha de Base do Azure Kubernetes Service (AKS) para microsserviços, juntamente com um projeto de teste de carga do Visual Studio utilizado para gerar os resultados.
Este artigo faz parte de uma série. Leia a primeira parte aqui.
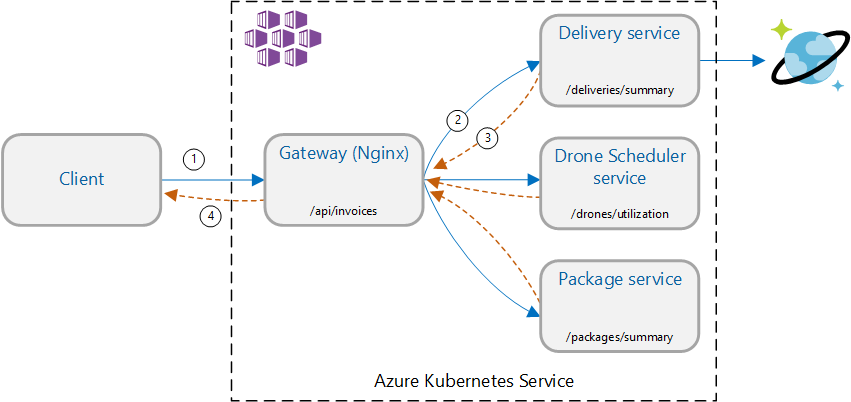
Cenário: chame vários serviços de back-end para obter informações e, em seguida, agregar os resultados.
Este cenário envolve uma aplicação de entrega por drone. Os clientes podem consultar uma API REST para obter as informações mais recentes da fatura. A fatura inclui um resumo das entregas, pacotes e utilização total de drones do cliente. Esta aplicação utiliza uma arquitetura de microsserviços em execução no AKS e as informações necessárias para a fatura são distribuídas por vários microsserviços.
Em vez de o cliente chamar cada serviço diretamente, a aplicação implementa o padrão de Agregação de Gateway . Com este padrão, o cliente faz um único pedido a um serviço de gateway. Por sua vez, o gateway chama os serviços de back-end em paralelo e, em seguida, agrega os resultados num payload de resposta única.
Teste 1: Desempenho da linha de base
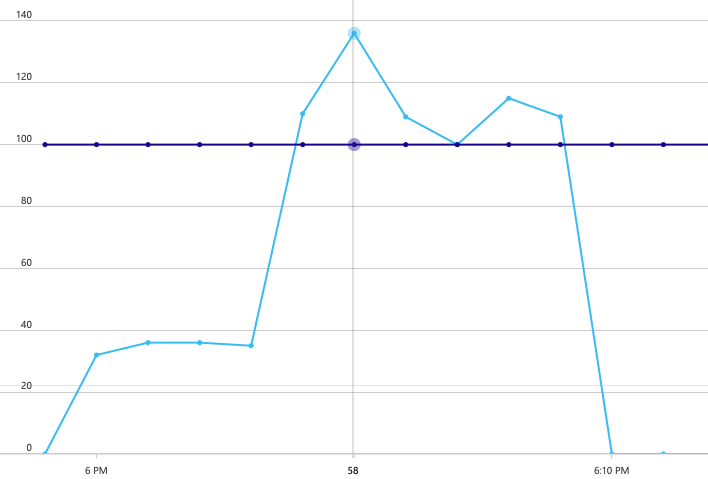
Para estabelecer uma linha de base, a equipa de desenvolvimento começou com um teste de carregamento de passos, aumentando a carga de um utilizador simulado até 40 utilizadores, durante um período total de 8 minutos. O gráfico seguinte, retirado do Visual Studio, mostra os resultados. A linha roxa mostra a carga do utilizador e a linha laranja mostra débito (pedidos médios por segundo).
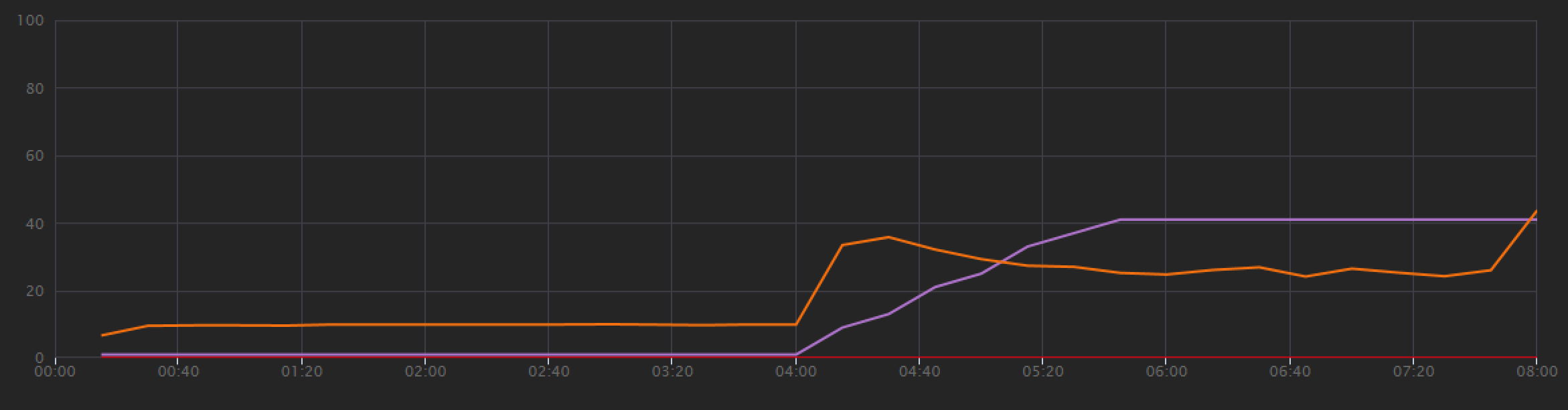
A linha vermelha ao longo da parte inferior do gráfico mostra que não foram devolvidos erros ao cliente, o que é encorajador. No entanto, o débito médio atinge um pico a cerca de metade do teste e, em seguida, cai para o resto, mesmo que a carga continue a aumentar. Isto indica que o back-end não consegue acompanhar. O padrão visto aqui é comum quando um sistema começa a atingir os limites de recursos , depois de atingir um máximo, o débito realmente cai significativamente. A contenção de recursos, erros transitórios ou um aumento da taxa de exceções podem contribuir para este padrão.
Vamos analisar os dados de monitorização para saber o que está a acontecer dentro do sistema. O gráfico seguinte é retirado do Application Insights. Mostra a duração média das chamadas HTTP do gateway para os serviços de back-end.
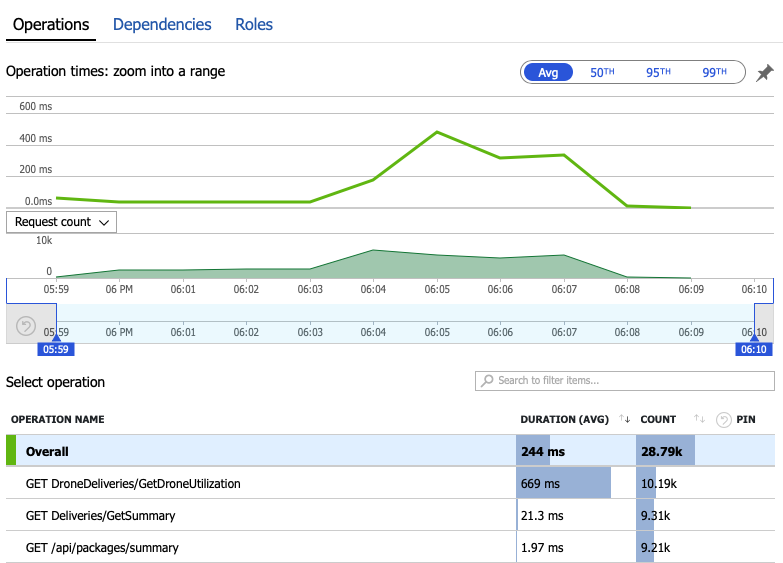
Este gráfico mostra que uma operação em particular, GetDroneUtilization, demora muito mais tempo, em média, por uma ordem de magnitude. O gateway faz estas chamadas em paralelo, pelo que a operação mais lenta determina quanto tempo demora a conclusão de todo o pedido.
Claramente, o próximo passo é investigar a GetDroneUtilization operação e procurar estrangulamentos. Uma possibilidade é o esgotamento de recursos. Talvez este serviço de back-end em particular esteja a ficar sem CPU ou memória. Para um cluster do AKS, estas informações estão disponíveis no portal do Azure através da funcionalidade informações de contentor do Azure Monitor. Os gráficos seguintes mostram a utilização de recursos ao nível do cluster:
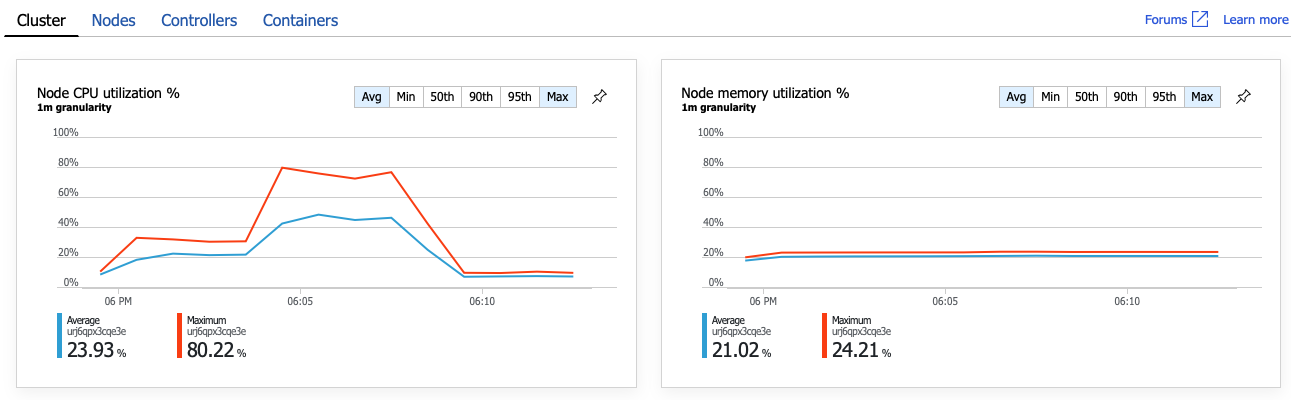
Nesta captura de ecrã, são apresentados os valores médio e máximo. É importante analisar mais do que apenas a média, uma vez que a média pode ocultar picos nos dados. Aqui, a utilização média da CPU permanece abaixo dos 50%, mas existem alguns picos para 80%. Está perto da capacidade, mas ainda dentro das tolerâncias. Outra coisa está a causar o estrangulamento.
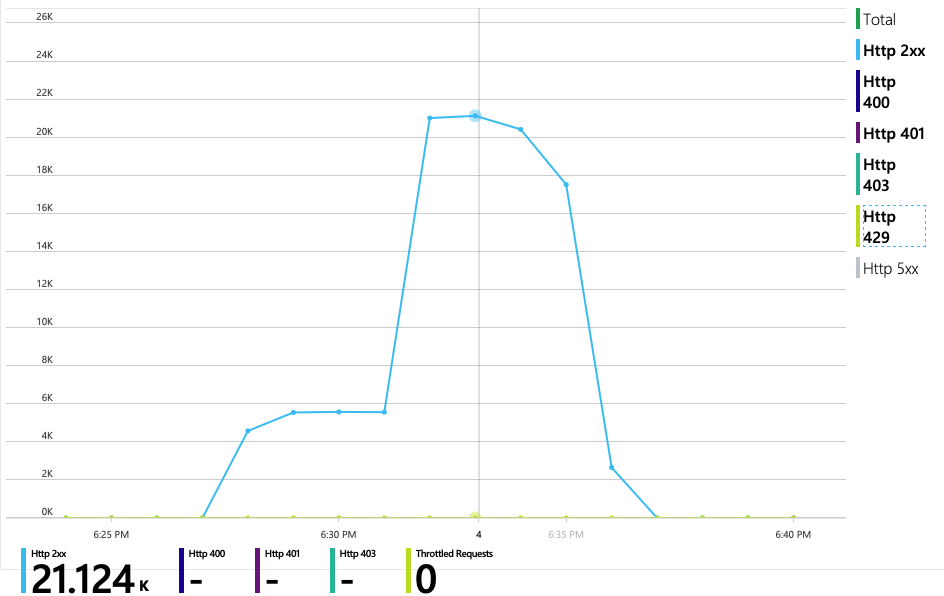
O gráfico seguinte revela o verdadeiro culpado. Este gráfico mostra códigos de resposta HTTP da base de dados de back-end do Serviço de entrega, que neste caso é o Azure Cosmos DB. A linha azul representa os códigos de êxito (HTTP 2xx), enquanto a linha verde representa erros HTTP 429. Um código de retorno HTTP 429 significa que o Azure Cosmos DB está a limitar temporariamente os pedidos, porque o autor da chamada está a consumir mais unidades de recursos (RU) do que o aprovisionado.
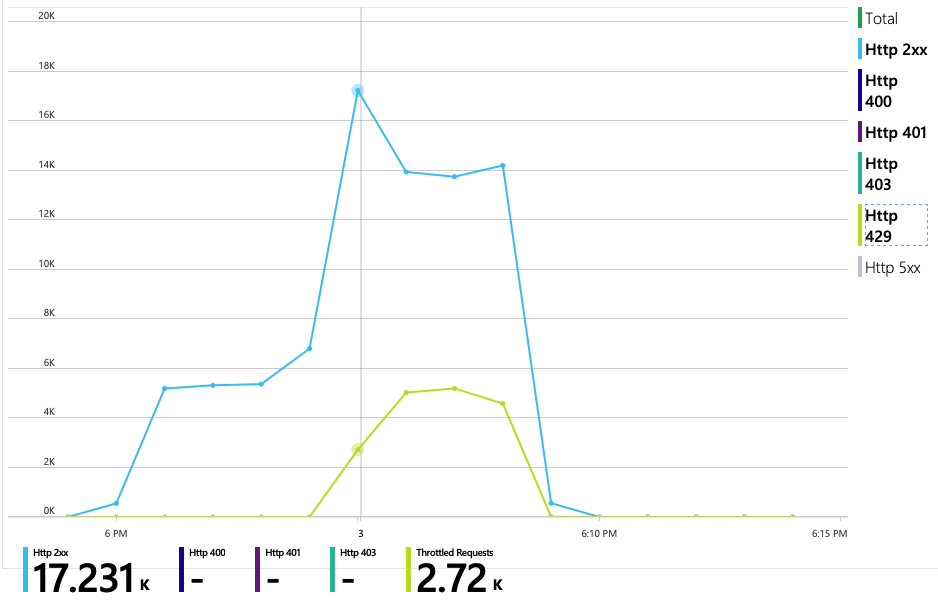
Para obter mais informações, a equipa de desenvolvimento utilizou o Application Insights para ver a telemetria ponto a ponto de uma amostra representativa de pedidos. Eis uma instância:
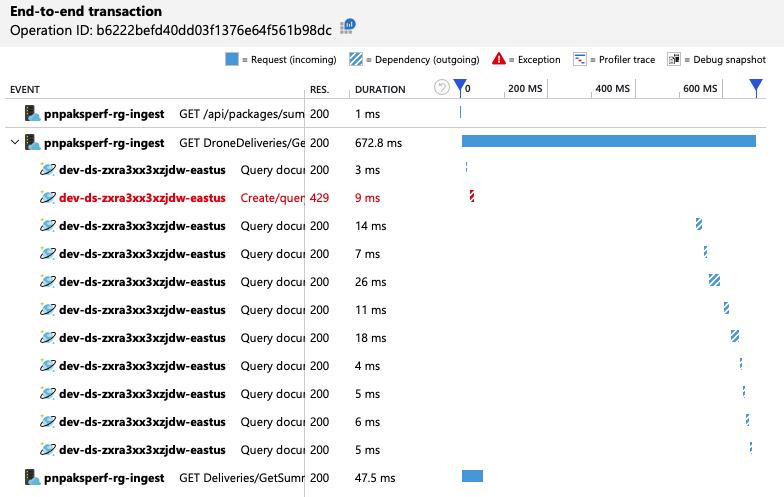
Esta vista mostra as chamadas relacionadas com um único pedido de cliente, juntamente com informações de temporização e códigos de resposta. As chamadas de nível superior são do gateway para os serviços de back-end. A chamada para GetDroneUtilization é expandida para mostrar chamadas para dependências externas , neste caso, para o Azure Cosmos DB. A chamada a vermelho devolveu um erro HTTP 429.
Tenha em atenção o grande intervalo entre o erro HTTP 429 e a chamada seguinte. Quando a biblioteca de cliente do Azure Cosmos DB recebe um erro HTTP 429, este recua automaticamente e aguarda para repetir a operação. O que esta vista mostra é que, durante os 672 ms que esta operação demorou, a maior parte desse tempo foi despendida à espera de repetir o Azure Cosmos DB.
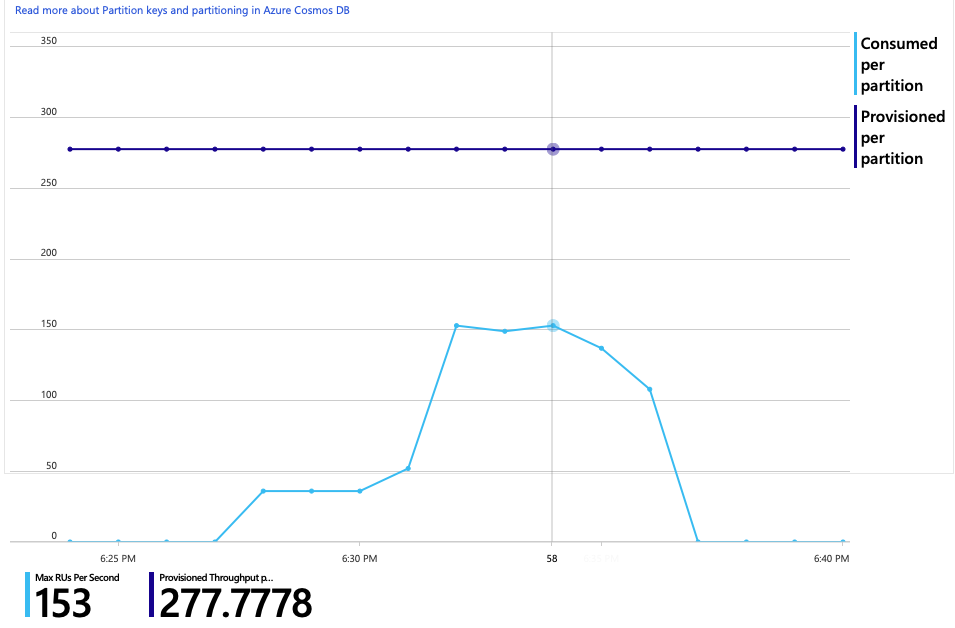
Eis outro gráfico interessante para esta análise. Mostra o consumo de RUs por partição física versus RUs aprovisionadas por partição física:
Para compreender este gráfico, tem de compreender como o Azure Cosmos DB gere as partições. As coleções no Azure Cosmos DB podem ter uma chave de partição. Cada valor de chave possível define uma partição lógica dos dados na coleção. O Azure Cosmos DB distribui estas partições lógicas por uma ou mais partições físicas . A gestão de partições físicas é processada automaticamente pelo Azure Cosmos DB. À medida que armazena mais dados, o Azure Cosmos DB pode mover partições lógicas para novas partições físicas, de modo a distribuir a carga pelas partições físicas.
Para este teste de carga, a coleção do Azure Cosmos DB foi aprovisionada com 900 RUs. O gráfico mostra 100 RU por partição física, o que implica um total de nove partições físicas. Embora o Azure Cosmos DB processe automaticamente a fragmentação de partições físicas, saber que a contagem de partições pode dar informações sobre o desempenho. A equipa de desenvolvimento irá utilizar estas informações mais tarde, uma vez que continuam a otimizar. Quando a linha azul cruza a linha horizontal roxa, o consumo de RUs excedeu as RUs aprovisionadas. É esse o ponto em que o Azure Cosmos DB começará a limitar as chamadas.
Teste 2: Aumentar unidades de recursos
Para o segundo teste de carga, a equipa aumentou horizontalmente a coleção do Azure Cosmos DB de 900 RU para 2500 RU. O débito aumentou de 19 pedidos/segundo para 23 pedidos/segundo e a latência média baixou de 669 ms para 569 ms.
| Metric | Teste 1 | Teste 2 |
|---|---|---|
| Débito (req/seg) | 19 | 23 |
| Latência média (ms) | 669 | 569 |
| Pedidos com êxito | 9,8 K | 11 K |
Estes não são grandes ganhos, mas olhar para o gráfico ao longo do tempo mostra uma imagem mais completa:
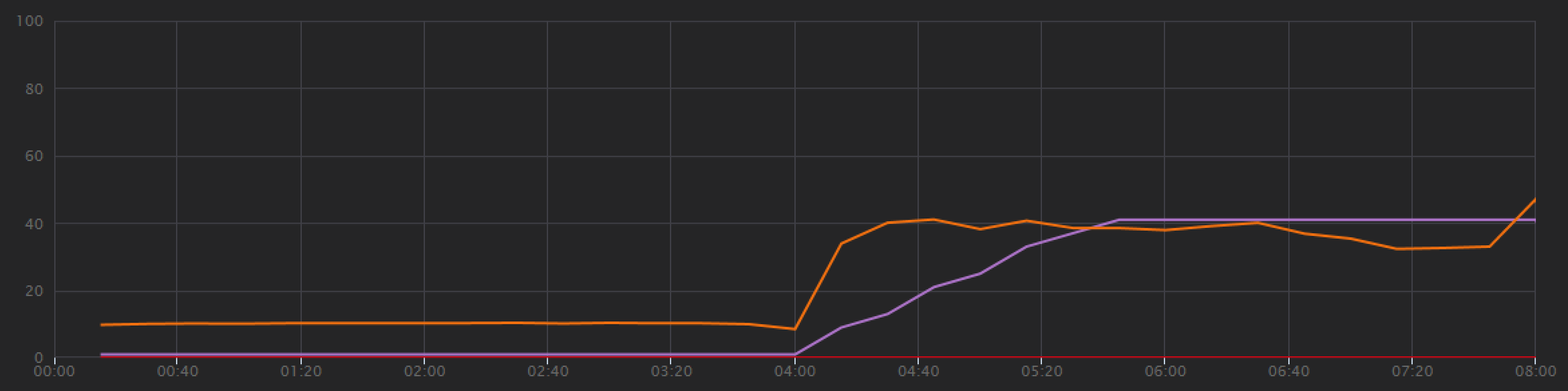
Enquanto o teste anterior mostrou um pico inicial seguido de uma queda acentuada, este teste mostra um débito mais consistente. No entanto, o débito máximo não é significativamente maior.
Todos os pedidos para o Azure Cosmos DB devolveram um estado 2xx e os erros HTTP 429 desapareceram:
O gráfico de consumo de RUs versus RUs aprovisionadas mostra que há bastante espaço. Existem cerca de 275 RUs por partição física e o teste de carga atingiu o pico em cerca de 100 RUs consumidas por segundo.
Outra métrica interessante é o número de chamadas para o Azure Cosmos DB por operação bem-sucedida:
| Metric | Teste 1 | Teste 2 |
|---|---|---|
| Chamadas por operação | 11 | 9 |
Assumindo que não existem erros, o número de chamadas deve corresponder ao plano de consulta real. Neste caso, a operação envolve uma consulta entre partições que atinge todas as nove partições físicas. O valor mais elevado no primeiro teste de carga reflete o número de chamadas que devolveram um erro 429.
Esta métrica foi calculada ao executar uma consulta personalizada do Log Analytics:
let start=datetime("2020-06-18T20:59:00.000Z");
let end=datetime("2020-07-24T21:10:00.000Z");
let operationNameToEval="GET DroneDeliveries/GetDroneUtilization";
let dependencyType="Azure DocumentDB";
let dataset=requests
| where timestamp > start and timestamp < end
| where success == true
| where name == operationNameToEval;
dataset
| project reqOk=itemCount
| summarize
SuccessRequests=sum(reqOk),
TotalNumberOfDepCalls=(toscalar(dependencies
| where timestamp > start and timestamp < end
| where type == dependencyType
| summarize sum(itemCount)))
| project
OperationName=operationNameToEval,
DependencyName=dependencyType,
SuccessRequests,
AverageNumberOfDepCallsPerOperation=(TotalNumberOfDepCalls/SuccessRequests)
Para resumir, o segundo teste de carga mostra melhorias. No entanto, a GetDroneUtilization operação ainda demora cerca de uma ordem de magnitude maior do que a operação mais lenta seguinte. Analisar as transações ponto a ponto ajuda a explicar porquê:
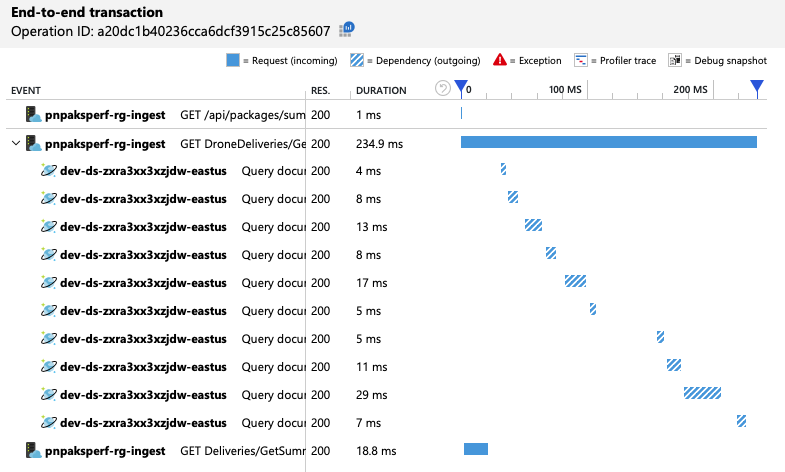
Conforme mencionado anteriormente, a GetDroneUtilization operação envolve uma consulta entre partições para o Azure Cosmos DB. Isto significa que o cliente do Azure Cosmos DB tem de distribuir a consulta a cada partição física e recolher os resultados. Como mostra a vista de transação ponto a ponto, estas consultas estão a ser executadas em série. A operação demora desde que a soma de todas as consultas e este problema só piore à medida que o tamanho dos dados aumenta e são adicionadas mais partições físicas.
Teste 3: Consultas paralelas
Com base nos resultados anteriores, uma forma óbvia de reduzir a latência é emitir as consultas em paralelo. O SDK de cliente do Azure Cosmos DB tem uma definição que controla o grau máximo de paralelismo.
| Valor | Descrição |
|---|---|
| 0 | Sem paralelismo (predefinição) |
| > 0 | Número máximo de chamadas paralelas |
| -1 | O SDK de cliente seleciona um grau ideal de paralelismo |
Para o terceiro teste de carga, esta definição foi alterada de 0 para -1. A tabela seguinte resume os resultados:
| Metric | Teste 1 | Teste 2 | Teste 3 |
|---|---|---|---|
| Débito (req/seg) | 19 | 23 | 42 |
| Latência média (ms) | 669 | 569 | 215 |
| Pedidos com êxito | 9,8 K | 11 K | 20 K |
| Pedidos limitados | 2,72 K | 0 | 0 |
No gráfico de teste de carga, não só o débito geral é muito maior (a linha laranja), como o débito também mantém o ritmo com a carga (a linha roxa).
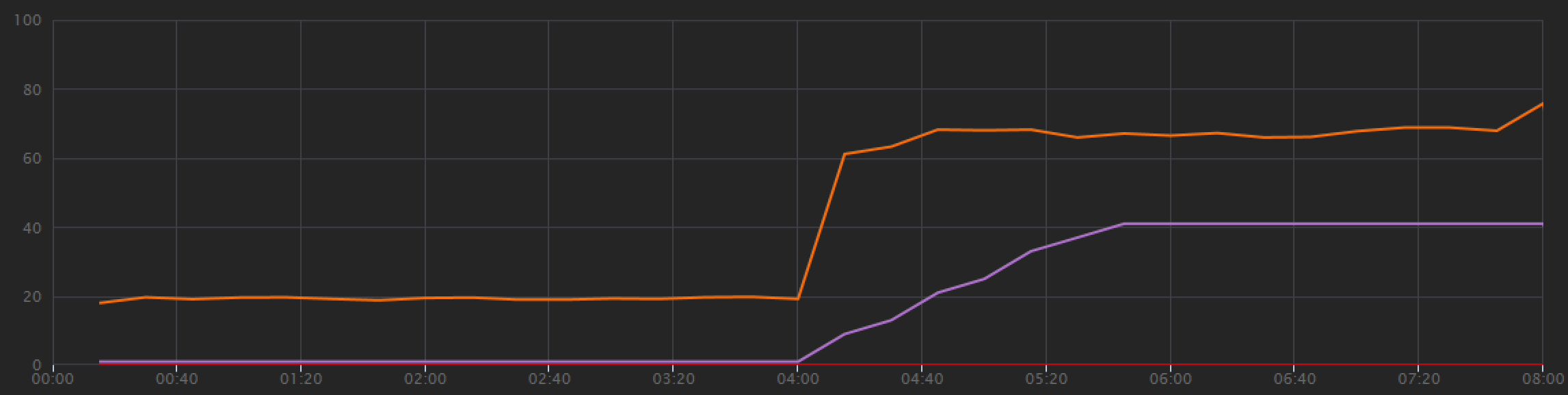
Podemos verificar se o cliente do Azure Cosmos DB está a fazer consultas em paralelo ao analisar a vista de transação ponto a ponto:
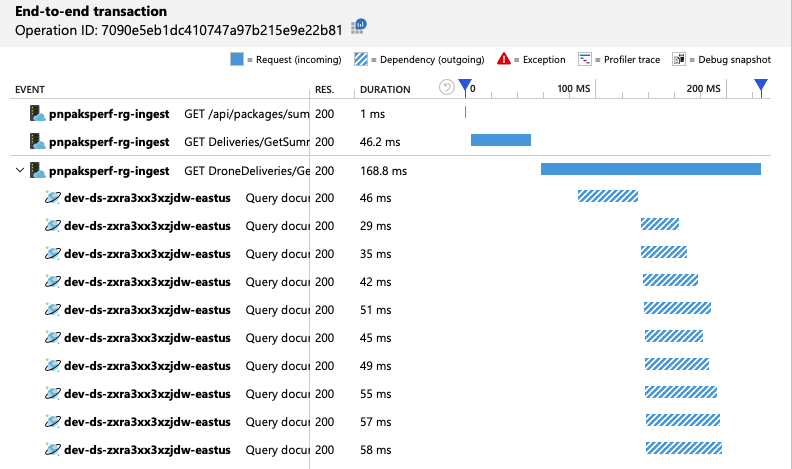
Curiosamente, um efeito colateral do aumento do débito é que o número de RUs consumidas por segundo também aumenta. Embora o Azure Cosmos DB não tenha limitado nenhum pedido durante este teste, o consumo foi próximo do limite de RU aprovisionado:
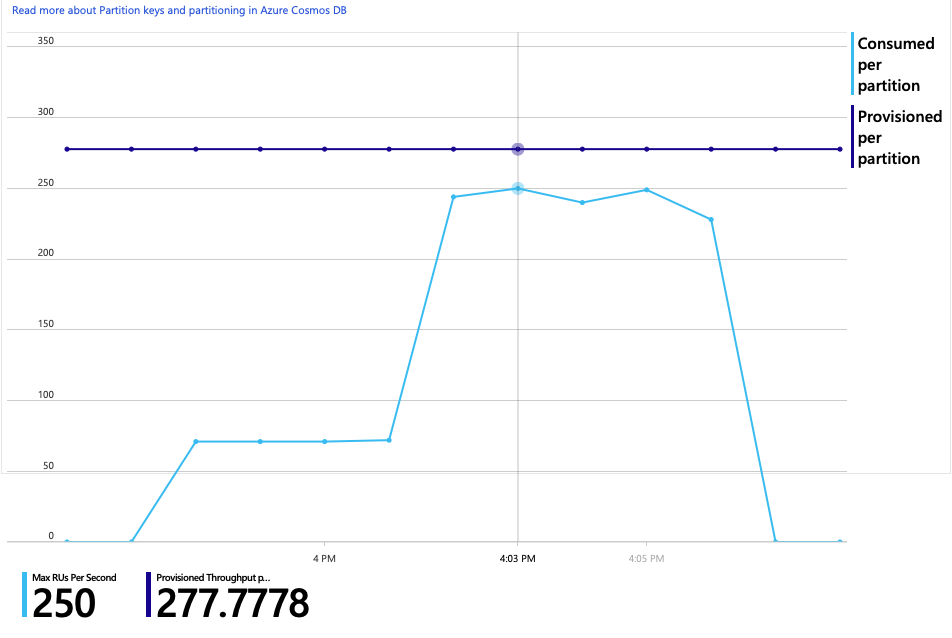
Este gráfico pode ser um sinal para aumentar ainda mais a base de dados. No entanto, verifica-se que podemos otimizar a consulta.
Passo 4: Otimizar a consulta
O teste de carga anterior mostrou um melhor desempenho em termos de latência e débito. A latência média dos pedidos foi reduzida em 68% e o débito aumentou 220%. No entanto, a consulta entre partições é uma preocupação.
O problema das consultas entre partições é que paga por RU em todas as partições. Se a consulta só for executada ocasionalmente , digamos, uma vez por hora, poderá não importar. No entanto, sempre que vir uma carga de trabalho de leitura intensiva que envolva uma consulta entre partições, deve ver se a consulta pode ser otimizada ao incluir uma chave de partição. (Poderá ter de redesenhar a coleção para utilizar uma chave de partição diferente.)
Eis a consulta para este cenário específico:
SELECT * FROM c
WHERE c.ownerId = <ownerIdValue> and
c.year = <yearValue> and
c.month = <monthValue>
Esta consulta seleciona registos que correspondem a um ID de proprietário específico e mês/ano. Na estrutura original, nenhuma destas propriedades é a chave de partição. Isto requer que o cliente acione a consulta para cada partição física e reúna os resultados. Para melhorar o desempenho das consultas, a equipa de desenvolvimento alterou a estrutura para que o ID do proprietário seja a chave de partição da coleção. Desta forma, a consulta pode visar uma partição física específica. (O Azure Cosmos DB processa isto automaticamente; não tem de gerir o mapeamento entre valores de chave de partição e partições físicas.)
Depois de mudar a coleção para a nova chave de partição, houve uma melhoria dramática no consumo de RU, que se traduz diretamente em custos mais baixos.
| Metric | Teste 1 | Teste 2 | Teste 3 | Teste 4 |
|---|---|---|---|---|
| RUs por operação | 29 | 29 | 29 | 3.4 |
| Chamadas por operação | 11 | 9 | 10 | 1 |
A vista de transação ponto a ponto mostra que, conforme previsto, a consulta lê apenas uma partição física:
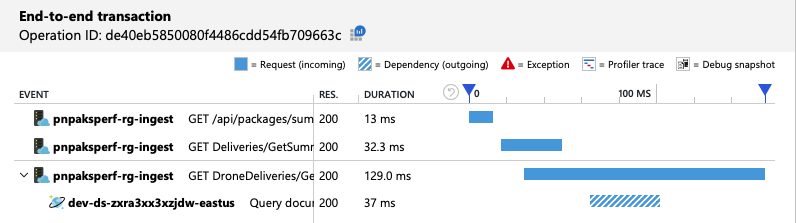
O teste de carga mostra um débito e latência melhorados:
| Metric | Teste 1 | Teste 2 | Teste 3 | Teste 4 |
|---|---|---|---|---|
| Débito (req/seg) | 19 | 23 | 42 | 59 |
| Latência média (ms) | 669 | 569 | 215 | 176 |
| Pedidos com êxito | 9,8 K | 11 K | 20 K | 29 K |
| Pedidos limitados | 2,72 K | 0 | 0 | 0 |
Uma consequência do desempenho melhorado é que a utilização da CPU do nó se torna muito elevada:
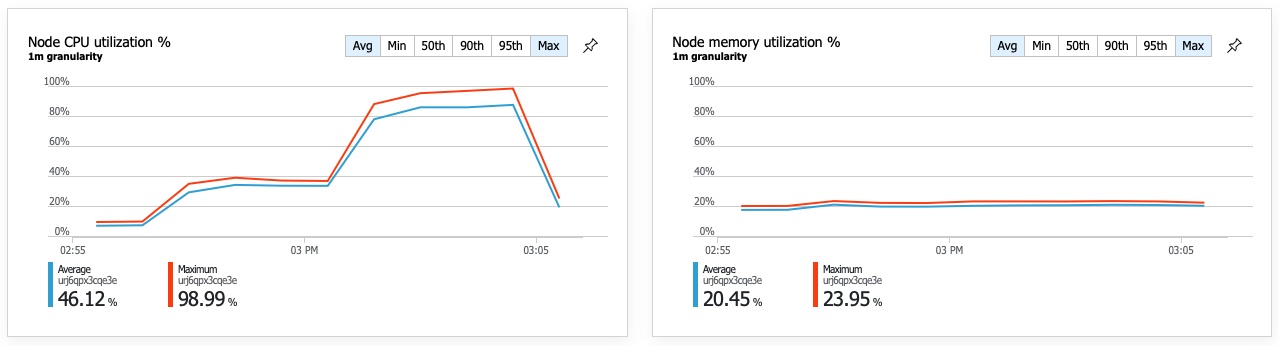
No final do teste de carga, a CPU média atingiu cerca de 90%, e a CPU máxima atingiu os 100%. Esta métrica indica que a CPU é o próximo estrangulamento no sistema. Se for necessário um débito mais elevado, o próximo passo poderá ser aumentar horizontalmente o serviço de Entrega para mais instâncias.
Resumo
Para este cenário, foram identificados os seguintes estrangulamentos:
- Pedidos de limitação do Azure Cosmos DB devido a RUs insuficientes aprovisionadas.
- Latência elevada causada pela consulta de várias partições de base de dados em série.
- Consulta entre partições ineficiente, porque a consulta não incluiu a chave de partição.
Além disso, a utilização da CPU foi identificada como um potencial estrangulamento numa escala mais elevada. Para diagnosticar estes problemas, a equipa de desenvolvimento analisou:
- Latência e débito do teste de carga.
- Erros do Azure Cosmos DB e consumo de RU.
- A vista de transação ponto a ponto no Application Insight.
- Utilização da CPU e da memória nas informações de contentor do Azure Monitor.