Use dashboards to visualize Azure Databricks metrics (Utilizar dashboards para visualizar as métricas do Azure Databricks)
Nota
Este artigo conta com uma biblioteca de código aberto hospedada no GitHub em: https://github.com/mspnp/spark-monitoring.
A biblioteca original suporta o Azure Databricks Runtimes 10.x (Spark 3.2.x) e anteriores.
O Databricks contribuiu com uma versão atualizada para dar suporte ao Azure Databricks Runtimes 11.0 (Spark 3.3.x) e superior na l4jv2 ramificação em: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Observe que a versão 11.0 não é compatível com versões anteriores devido aos diferentes sistemas de registro usados no Databricks Runtimes. Certifique-se de usar a compilação correta para seu Databricks Runtime. A biblioteca e o repositório GitHub estão em modo de manutenção. Não há planos para novos lançamentos, e o suporte a problemas será apenas o melhor esforço. Para quaisquer perguntas adicionais sobre a biblioteca ou o roteiro para monitoramento e registro em log de seus ambientes do Azure Databricks, entre em contato com azure-spark-monitoring-help@databricks.com.
Este artigo mostra como configurar um painel do Grafana para monitorar trabalhos do Azure Databricks em busca de problemas de desempenho.
O Azure Databricks é um serviço de análise baseado no Apache Spark rápido, poderoso e colaborativo que facilita o desenvolvimento e a implantação rápidos de soluções de análise de big data e inteligência artificial (IA). O monitoramento é um componente crítico da operação de cargas de trabalho do Azure Databricks em produção. O primeiro passo é reunir métricas em um espaço de trabalho para análise. No Azure, a melhor solução para gerenciar dados de log é o Azure Monitor. O Azure Databricks não oferece suporte nativo ao envio de dados de log para o Azure Monitor, mas uma biblioteca para essa funcionalidade está disponível no GitHub.
Essa biblioteca permite o registro em log de métricas de serviço do Azure Databricks, bem como métricas de eventos de consulta de streaming da estrutura do Apache Spark. Depois de implantar com êxito essa biblioteca em um cluster do Azure Databricks, você pode implantar ainda mais um conjunto de painéis do Grafana que pode ser implantado como parte do seu ambiente de produção.
Pré-requisitos
Configure seu cluster do Azure Databricks para usar a biblioteca de monitoramento, conforme descrito no Leiame do GitHub.
Implantar o espaço de trabalho do Azure Log Analytics
Para implantar o espaço de trabalho do Azure Log Analytics, siga estas etapas:
Navegue até o
/perftools/deployment/loganalyticsdiretório.Implante o modelo do logAnalyticsDeploy.json Azure Resource Manager. Para obter mais informações sobre como implantar modelos do Resource Manager, consulte Implantar recursos com modelos do Resource Manager e a CLI do Azure. O modelo tem os seguintes parâmetros:
- local: a região onde o espaço de trabalho e os painéis do Log Analytics são implantados.
- serviceTier: A camada de preço do espaço de trabalho. Veja aqui uma lista de valores válidos.
- dataRetention (opcional): o número de dias em que os dados de log são retidos no espaço de trabalho do Log Analytics. O valor predefinido é de 30 dias. Se o nível de preço for
Free, a retenção de dados deve ser de sete dias. - workspaceName (opcional): um nome para o espaço de trabalho. Se não for especificado, o modelo gerará um nome.
az deployment group create --resource-group <resource-group-name> --template-file logAnalyticsDeploy.json --parameters location='East US' serviceTier='Standalone'
Este modelo cria o espaço de trabalho e também cria um conjunto de consultas predefinidas que são usadas pelo painel.
Implantar o Grafana em uma máquina virtual
O Grafana é um projeto de código aberto que você pode implantar para visualizar as métricas de séries cronológicas armazenadas em seu espaço de trabalho do Azure Log Analytics usando o plug-in Grafana para o Azure Monitor. O Grafana é executado em uma máquina virtual (VM) e requer uma conta de armazenamento, rede virtual e outros recursos. Para implantar uma máquina virtual com a imagem Grafana certificada pela Bitnami e recursos associados, siga estas etapas:
Use a CLI do Azure para aceitar os termos de imagem do Azure Marketplace para Grafana.
az vm image terms accept --publisher bitnami --offer grafana --plan defaultNavegue até o
/spark-monitoring/perftools/deployment/grafanadiretório em sua cópia local do repositório GitHub.Implante o modelo do grafanaDeploy.json Resource Manager da seguinte maneira:
export DATA_SOURCE="https://raw.githubusercontent.com/mspnp/spark-monitoring/master/perftools/deployment/grafana/AzureDataSource.sh" az deployment group create \ --resource-group <resource-group-name> \ --template-file grafanaDeploy.json \ --parameters adminPass='<vm password>' dataSource=$DATA_SOURCE
Quando a implantação estiver concluída, a imagem Bitnami do Grafana será instalada na máquina virtual.
Atualizar a senha do Grafana
Como parte do processo de configuração, o script de instalação do Grafana gera uma senha temporária para o usuário administrador . Necessita desta palavra-passe temporária para iniciar sessão. Para obter a palavra-passe temporária, siga estes passos:
- Inicie sessão no portal do Azure.
- Selecione o grupo de recursos onde os recursos foram implantados.
- Selecione a VM onde o Grafana foi instalado. Se você usou o nome do parâmetro padrão no modelo de implantação, o nome da VM será precedido de sparkmonitoring-vm-grafana.
- Na seção Suporte + solução de problemas, clique em Diagnóstico de inicialização para abrir a página de diagnóstico de inicialização.
- Clique em Log serial na página de diagnóstico de inicialização.
- Procure a seguinte string: "Definindo a senha do aplicativo Bitnami para".
- Copie a palavra-passe para um local seguro.
Em seguida, altere a senha de administrador do Grafana seguindo estas etapas:
- No portal do Azure, selecione a VM e clique em Visão geral.
- Copie o endereço IP público.
- Abra um navegador da Web e navegue até o seguinte URL:
http://<IP address>:3000. - Na tela de login do Grafana, digite admin para o nome de usuário e use a senha do Grafana das etapas anteriores.
- Depois de fazer login, selecione Configuração (o ícone de engrenagem).
- Selecione Administrador do Servidor.
- Na guia Usuários, selecione o login de administrador.
- Atualize a senha.
Criar uma fonte de dados do Azure Monitor
Crie uma entidade de serviço que permita ao Grafana gerenciar o acesso ao seu espaço de trabalho do Log Analytics. Para obter mais informações, consulte Criar uma entidade de serviço do Azure com a CLI do Azure
az ad sp create-for-rbac --name http://<service principal name> \ --role "Log Analytics Reader" \ --scopes /subscriptions/mySubscriptionIDObserve os valores para appId, senha e locatário na saída deste comando:
{ "appId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "displayName": "azure-cli-2019-03-27-00-33-39", "name": "http://<service principal name>", "password": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "tenant": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" }Inicie sessão no Grafana conforme descrito anteriormente. Selecione Configuração (o ícone de engrenagem) e, em seguida, Fontes de dados.
Na guia Fontes de Dados , clique em Adicionar fonte de dados.
Selecione Azure Monitor como o tipo de fonte de dados.
Na seção Configurações, insira um nome para a fonte de dados na caixa de texto Nome.
Na seção Detalhes da API do Azure Monitor, insira as seguintes informações:
- ID da assinatura: sua ID de assinatura do Azure.
- ID do locatário: o ID do locatário anterior.
- ID do cliente: O valor de "appId" do anterior.
- Segredo do cliente: O valor de "senha" de antes.
Na seção Detalhes da API do Azure Log Analytics, marque a caixa de seleção Mesmos detalhes da API do Azure Monitor.
Clique em Salvar & Test. Se a fonte de dados do Log Analytics estiver configurada corretamente, uma mensagem de êxito será exibida.
Criar o painel
Crie os painéis no Grafana seguindo estas etapas:
Navegue até o
/perftools/dashboards/grafanadiretório em sua cópia local do repositório GitHub.Execute o seguintes script:
export WORKSPACE=<your Azure Log Analytics workspace ID> export LOGTYPE=SparkListenerEvent_CL sh DashGen.shA saída do script é um arquivo chamado SparkMonitoringDash.json.
Volte ao painel do Grafana e selecione Criar (o ícone de mais).
Selecione Importar.
Clique em Carregar .json arquivo.
Selecione o arquivo SparkMonitoringDash.json criado na etapa 2.
Na seção Opções, em ALA, selecione a fonte de dados do Azure Monitor criada anteriormente.
Clique em Importar.
Visualizações nos painéis
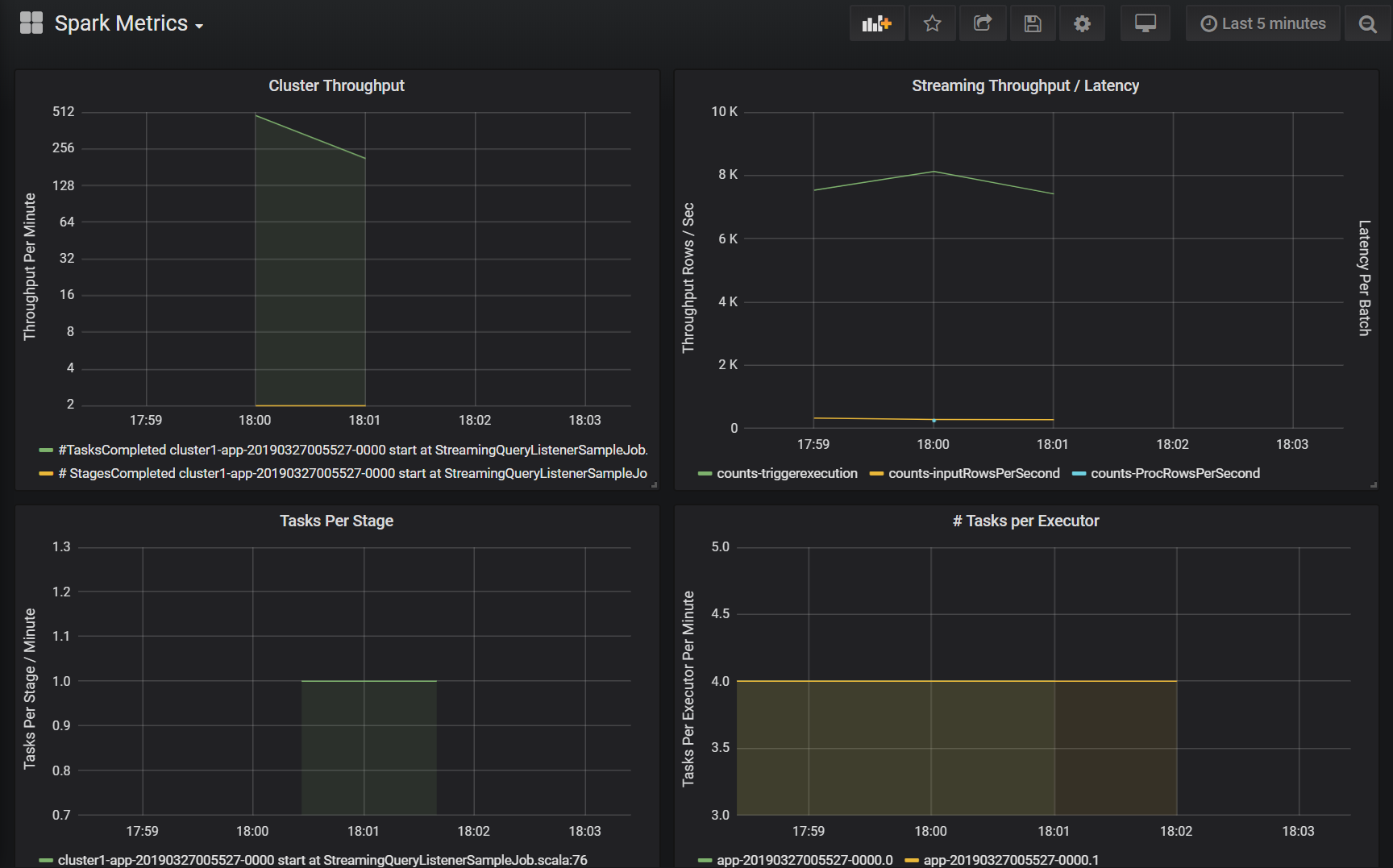
Os painéis do Azure Log Analytics e do Grafana incluem um conjunto de visualizações de séries temporais. Cada gráfico é um gráfico de série temporal de dados métricos relacionados a um trabalho do Apache Spark, estágios do trabalho e tarefas que compõem cada estágio.
As visualizações são:
Latência do trabalho
Essa visualização mostra a latência de execução de um trabalho, que é uma visão grosseira do desempenho geral de um trabalho. Exibe a duração da execução do trabalho do início à conclusão. Observe que a hora de início do trabalho não é a mesma que a hora de envio do trabalho. A latência é representada como percentis (10%, 30%, 50%, 90%) de execução de trabalho indexada por ID de cluster e ID de aplicativo.
Latência do estágio
A visualização mostra a latência de cada estágio por cluster, por aplicativo e por estágio individual. Essa visualização é útil para identificar um estágio específico que está sendo executado lentamente.
Latência da tarefa
Esta visualização mostra a latência de execução da tarefa. A latência é representada como um percentil de execução de tarefas por cluster, nome de estágio e aplicativo.
Somar a execução de tarefas por host
Essa visualização mostra a soma da latência de execução de tarefas por host em execução em um cluster. A visualização da latência de execução de tarefas por host identifica hosts que têm latência geral de tarefas muito maior do que outros hosts. Isso pode significar que as tarefas foram distribuídas de forma ineficiente ou desigual para os hosts.
Métricas de tarefas
Essa visualização mostra um conjunto de métricas de execução para a execução de uma determinada tarefa. Essas métricas incluem o tamanho e a duração de um embaralhamento de dados, a duração das operações de serialização e desserialização e outras. Para obter o conjunto completo de métricas, exiba a consulta do Log Analytics para o painel. Essa visualização é útil para entender as operações que compõem uma tarefa e identificar o consumo de recursos de cada operação. Os picos no gráfico representam operações dispendiosas que devem ser investigadas.
Taxa de transferência do cluster
Essa visualização é uma exibição de alto nível de itens de trabalho indexados por cluster e aplicativo para representar a quantidade de trabalho realizado por cluster e aplicativo. Ele mostra o número de trabalhos, tarefas e estágios concluídos por cluster, aplicativo e estágio em incrementos de um minuto.
Taxa de transferência/latência de streaming
Essa visualização está relacionada às métricas associadas a uma consulta de streaming estruturada. O gráfico mostra o número de linhas de entrada por segundo e o número de linhas processadas por segundo. As métricas de streaming também são representadas por aplicativo. Essas métricas são enviadas quando o evento OnQueryProgress é gerado à medida que a consulta de streaming estruturada é processada e a visualização representa a latência de streaming como a quantidade de tempo, em milissegundos, necessária para executar um lote de consulta.
Consumo de recursos por executor
Em seguida, um conjunto de visualizações para o painel mostra o tipo específico de recurso e como ele é consumido por executor em cada cluster. Essas visualizações ajudam a identificar valores atípicos no consumo de recursos por executor. Por exemplo, se a alocação de trabalho para um determinado executor estiver distorcida, o consumo de recursos será elevado em relação a outros executores em execução no cluster. Isso pode ser identificado por picos no consumo de recursos para um executor.
Métricas de tempo de computação do executor
Em seguida, há um conjunto de visualizações para o painel que mostram a proporção entre o tempo de serialização do executor, o tempo de desserialização, o tempo da CPU e o tempo da máquina virtual Java para o tempo de computação geral do executor. Isso demonstra visualmente o quanto cada uma dessas quatro métricas está contribuindo para o processamento geral do executor.
Métricas aleatórias
O conjunto final de visualizações mostra as métricas de embaralhamento de dados associadas a uma consulta de streaming estruturada em todos os executores. Isso inclui shuffle bytes lidos, shuffle bytes gravados, memória aleatória e uso de disco em consultas onde o sistema de arquivos é usado.
Próximos passos
Recursos relacionados
- Monitorizar o Azure Databricks
- Send Azure Databricks application logs to Azure Monitor (Enviar registos de aplicações do Azure Databricks para o Azure Monitor)
- Arquitetura de análise moderna com o Azure Databricks
- Ingestão, ETL (extrair, transformar, carregar) e pipelines de processamento de fluxo com o Azure Databricks