Etapa de modelagem do ciclo de vida do Processo de Ciência de Dados da Equipe
Este artigo descreve as metas, tarefas e resultados finais associados ao estágio de modelagem do Processo de Ciência de Dados da Equipe (TDSP). Esse processo fornece um ciclo de vida recomendado que sua equipe pode usar para estruturar seus projetos de ciência de dados. O ciclo de vida descreve os principais estágios que sua equipe executa, geralmente iterativamente:
- Compreensão do negócio
- Aquisição e compreensão de dados
- Modelação
- Implementação
- Aceitação do cliente
Aqui está uma representação visual do ciclo de vida do TDSP:
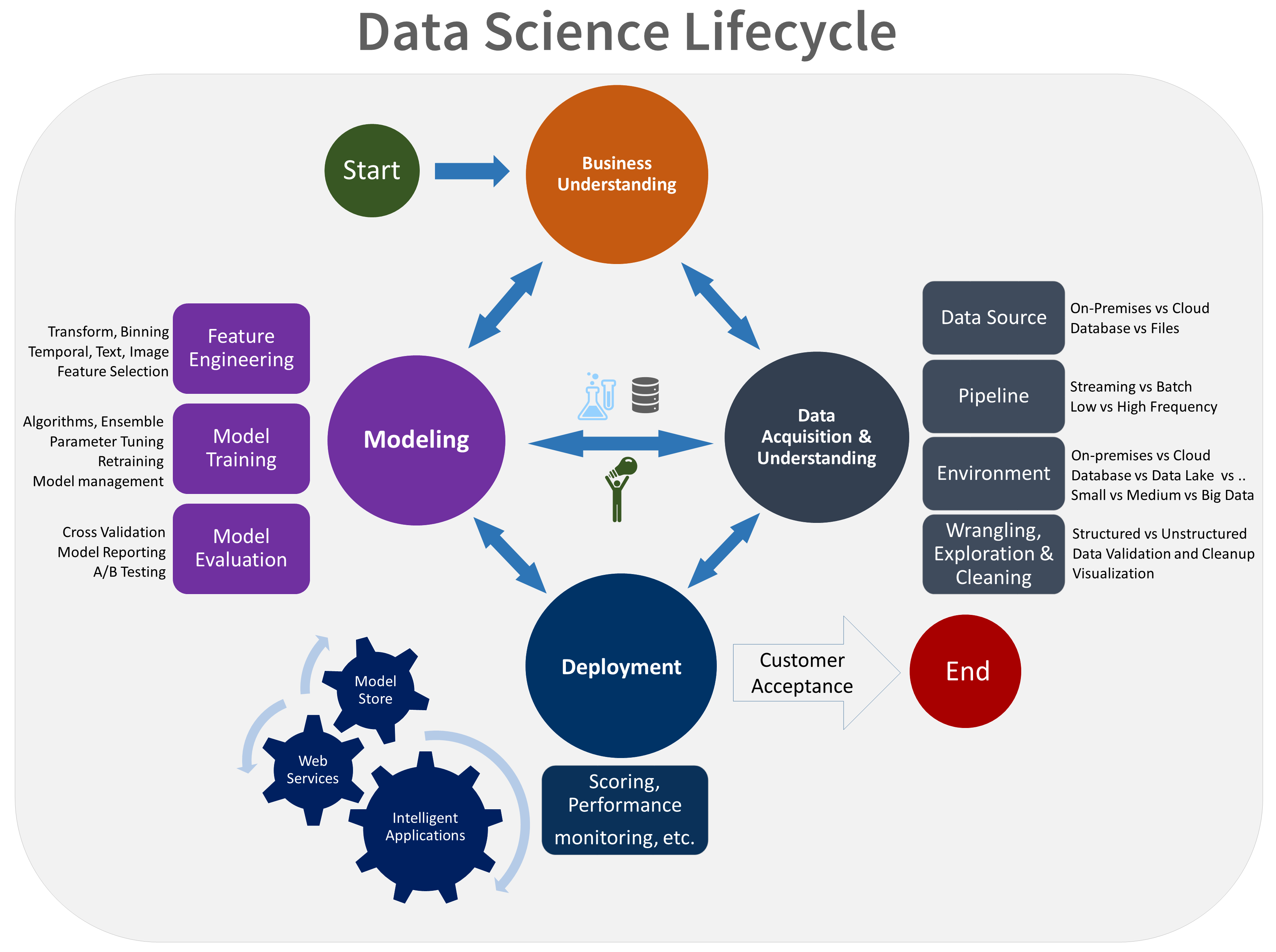
Objetivos
Os objetivos da etapa de modelagem são:
Determine os recursos de dados ideais para o modelo de aprendizado de máquina.
Crie um modelo informativo de aprendizado de máquina que preveja o alvo com mais precisão.
Crie um modelo de aprendizado de máquina adequado para produção.
Como concluir as tarefas
A etapa de modelagem tem três tarefas principais:
Engenharia de recursos: crie recursos de dados a partir dos dados brutos para facilitar o treinamento do modelo.
Treinamento de modelos: encontre o modelo que responde à pergunta com mais precisão comparando as métricas de sucesso dos modelos.
Avaliação do modelo: determine se o seu modelo é adequado para produção.
Desenvolvimento de funcionalidades
A engenharia de recursos envolve a inclusão, agregação e transformação de variáveis brutas para criar os recursos usados na análise. Se você quiser informações sobre como um modelo é construído, então você precisa estudar os recursos subjacentes do modelo.
Esta etapa requer uma combinação criativa de conhecimento de domínio e os insights obtidos na etapa de exploração de dados. A engenharia de recursos é um ato de equilíbrio de encontrar e incluir variáveis informativas, mas ao mesmo tempo tentar evitar muitas variáveis não relacionadas. Variáveis informativas melhoram o seu resultado. Variáveis não relacionadas introduzem ruído desnecessário no modelo. Você também precisa gerar esses recursos para quaisquer novos dados obtidos durante a pontuação. Como resultado, a geração desses recursos só pode depender dos dados disponíveis no momento da pontuação.
Preparação de modelos
Há muitos algoritmos de modelagem que você pode usar, dependendo do tipo de pergunta que você está tentando responder. Para obter orientação sobre como escolher um algoritmo pré-criado, consulte Folha de truques de algoritmo do Aprendizado de Máquina do Azure para o designer do Aprendizado de Máquina do Azure. Outros algoritmos estão disponíveis através de pacotes de código aberto em R ou Python. Embora este artigo se concentre no Azure Machine Learning, a orientação que ele fornece é útil para muitos projetos de aprendizado de máquina.
O processo de treinamento do modelo inclui as seguintes etapas:
Divida os dados de entrada aleatoriamente para modelagem em um conjunto de dados de treinamento e um conjunto de dados de teste.
Crie os modelos usando o conjunto de dados de treinamento.
Avalie o treinamento e o conjunto de dados de teste. Use uma série de algoritmos de aprendizado de máquina concorrentes. Use vários parâmetros de ajuste associados (conhecidos como varreduras de parâmetros) que são voltados para responder à pergunta de interesse com os dados atuais.
Determine a melhor solução para responder à pergunta comparando as métricas de sucesso entre métodos alternativos.
Para obter mais informações, consulte Treinar modelos com Machine Learning.
Nota
Evite vazamentos: você pode causar vazamento de dados se incluir dados de fora do conjunto de dados de treinamento que permite que um modelo ou algoritmo de aprendizado de máquina faça previsões irrealistas. O vazamento é uma razão comum pela qual os cientistas de dados ficam nervosos quando obtêm resultados preditivos que parecem bons demais para serem verdade. Essas dependências podem ser difíceis de detetar. Evitar vazamentos geralmente requer a iteração entre a construção de um conjunto de dados de análise, a criação de um modelo e a avaliação da precisão dos resultados.
Avaliação do modelo
Depois de treinar o modelo, um cientista de dados da sua equipe se concentra na avaliação do modelo.
Faça uma determinação: avalie se o modelo tem desempenho suficiente para a produção. Algumas perguntas-chave a fazer são:
O modelo responde à pergunta com confiança suficiente tendo em conta os dados do teste?
Deve tentar abordagens alternativas?
Você deve coletar mais dados, fazer mais engenharia de recursos ou experimentar outros algoritmos?
Interpretar o modelo: Use o SDK Python do Machine Learning para executar as seguintes tarefas:
Explique localmente todo o comportamento do modelo ou previsões individuais na sua máquina pessoal.
Habilite técnicas de interpretabilidade para recursos projetados.
Explique o comportamento de todo o modelo e previsões individuais no Azure.
Carregue explicações para o histórico de execução do Aprendizado de Máquina.
Use um painel de visualização para interagir com as explicações do modelo, tanto em um bloco de anotações Jupyter quanto no espaço de trabalho do Machine Learning.
Implante um explicador de pontuação ao lado do seu modelo para observar as explicações durante a inferência.
Avalie a equidade: use o pacote Python de código aberto fairlearn com Machine Learning para executar as seguintes tarefas:
Avalie a equidade das previsões do seu modelo. Esse processo ajuda sua equipe a aprender mais sobre equidade no aprendizado de máquina.
Carregue, liste e transfira informações de avaliação de equidade de e para o estúdio de Machine Learning.
Consulte o painel de avaliação de equidade no estúdio de Aprendizado de Máquina para interagir com as perceções de equidade de seus modelos.
Integração com MLflow
O Machine Learning integra-se ao MLflow para dar suporte ao ciclo de vida da modelagem. Ele usa o rastreamento do MLflow para experimentos, implantação de projetos, gerenciamento de modelos e um registro de modelo. Essa integração garante um fluxo de trabalho de aprendizado de máquina contínuo e eficiente. Os seguintes recursos no Machine Learning ajudam a dar suporte a esse elemento do ciclo de vida da modelagem:
Rastrear experimentos: a funcionalidade principal do MLflow é amplamente usada no estágio de modelagem para rastrear vários experimentos, parâmetros, métricas e artefatos.
Implantar projetos: empacotar código com MLflow Projects garante execuções consistentes e fácil compartilhamento entre os membros da equipe, o que é essencial durante o desenvolvimento do modelo iterativo.
Gerenciar modelos: o gerenciamento e o controle de versão de modelos são essenciais nesta fase, pois diferentes modelos são construídos, avaliados e refinados.
Modelos de registro: O registro de modelo é usado para versionamento e gerenciamento de modelos durante todo o seu ciclo de vida.
Literatura revista por pares
Os pesquisadores publicam estudos sobre o TDSP na literatura revisada por pares. As citações fornecem uma oportunidade para investigar outras aplicações ou ideias semelhantes ao TDSP, incluindo o estágio do ciclo de vida da modelagem.
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos seguintes contribuidores.
Autor principal:
- Mark Tabladillo - Brasil | Arquiteto de Soluções Cloud Sênior
Para ver perfis não públicos do LinkedIn, inicie sessão no LinkedIn.
Recursos relacionados
Estes artigos descrevem os outros estágios do ciclo de vida do TDSP: