Tutorial: Parte 3 - Avaliar um aplicativo de chat personalizado com o SDK do Azure AI Foundry
Neste tutorial, você usa o SDK do Azure AI (e outras bibliotecas) para avaliar o aplicativo de chat criado na Parte 2 da série de tutoriais. Nesta terceira parte, você aprende a:
- Criar um conjunto de dados de avaliação
- Avaliar o aplicativo de chat com avaliadores de IA do Azure
- Itere e melhore seu aplicativo
Este tutorial é a terceira parte de um tutorial de três partes.
Pré-requisitos
- Conclua a parte 2 da série de tutoriais para criar o aplicativo de bate-papo.
- Verifique se você concluiu as etapas para adicionar o log de telemetria da parte 2.
Avaliar a qualidade das respostas do aplicativo de bate-papo
Agora que você sabe que seu aplicativo de bate-papo responde bem às suas consultas, inclusive com o histórico de bate-papo, é hora de avaliar como ele se sai em algumas métricas diferentes e mais dados.
Você usa um avaliador com um conjunto de dados de avaliação e a get_chat_response() função alvo e, em seguida, avalia os resultados da avaliação.
Depois de executar uma avaliação, você pode fazer melhorias em sua lógica, como melhorar o prompt do sistema e observar como as respostas do aplicativo de bate-papo mudam e melhoram.
Criar conjunto de dados de avaliação
Use o seguinte conjunto de dados de avaliação, que contém perguntas de exemplo e respostas esperadas (verdade).
Crie um arquivo chamado chat_eval_data.jsonl na pasta de ativos .
Cole este conjunto de dados no arquivo:
{"query": "Which tent is the most waterproof?", "truth": "The Alpine Explorer Tent has the highest rainfly waterproof rating at 3000m"} {"query": "Which camping table holds the most weight?", "truth": "The Adventure Dining Table has a higher weight capacity than all of the other camping tables mentioned"} {"query": "How much do the TrailWalker Hiking Shoes cost? ", "truth": "The Trailewalker Hiking Shoes are priced at $110"} {"query": "What is the proper care for trailwalker hiking shoes? ", "truth": "After each use, remove any dirt or debris by brushing or wiping the shoes with a damp cloth."} {"query": "What brand is TrailMaster tent? ", "truth": "OutdoorLiving"} {"query": "How do I carry the TrailMaster tent around? ", "truth": " Carry bag included for convenient storage and transportation"} {"query": "What is the floor area for Floor Area? ", "truth": "80 square feet"} {"query": "What is the material for TrailBlaze Hiking Pants?", "truth": "Made of high-quality nylon fabric"} {"query": "What color does TrailBlaze Hiking Pants come in?", "truth": "Khaki"} {"query": "Can the warrenty for TrailBlaze pants be transfered? ", "truth": "The warranty is non-transferable and applies only to the original purchaser of the TrailBlaze Hiking Pants. It is valid only when the product is purchased from an authorized retailer."} {"query": "How long are the TrailBlaze pants under warranty for? ", "truth": " The TrailBlaze Hiking Pants are backed by a 1-year limited warranty from the date of purchase."} {"query": "What is the material for PowerBurner Camping Stove? ", "truth": "Stainless Steel"} {"query": "Is France in Europe?", "truth": "Sorry, I can only queries related to outdoor/camping gear and equipment"}
Avaliar com avaliadores de IA do Azure
Agora defina um script de avaliação que irá:
- Gere um wrapper de função de destino em torno da lógica do nosso aplicativo de chat.
- Carregue o conjunto de dados de exemplo
.jsonl. - Execute a avaliação, que assume a função de destino, e mescla o conjunto de dados de avaliação com as respostas do aplicativo de bate-papo.
- Gere um conjunto de métricas assistidas por GPT (relevância, fundamentação e coerência) para avaliar a qualidade das respostas do aplicativo de chat.
- Produza os resultados localmente e registre os resultados no projeto de nuvem.
O script permite que você revise os resultados localmente, emitindo os resultados na linha de comando e para um arquivo json.
O script também registra os resultados da avaliação no projeto de nuvem para que você possa comparar as execuções de avaliação na interface do usuário.
Crie um arquivo chamado evaluate.py na sua pasta principal.
Adicione o seguinte código para importar as bibliotecas necessárias, criar um cliente de projeto e definir algumas configurações:
import os import pandas as pd from azure.ai.projects import AIProjectClient from azure.ai.projects.models import ConnectionType from azure.ai.evaluation import evaluate, GroundednessEvaluator from azure.identity import DefaultAzureCredential from chat_with_products import chat_with_products # load environment variables from the .env file at the root of this repo from dotenv import load_dotenv load_dotenv() # create a project client using environment variables loaded from the .env file project = AIProjectClient.from_connection_string( conn_str=os.environ["AIPROJECT_CONNECTION_STRING"], credential=DefaultAzureCredential() ) connection = project.connections.get_default(connection_type=ConnectionType.AZURE_OPEN_AI, include_credentials=True) evaluator_model = { "azure_endpoint": connection.endpoint_url, "azure_deployment": os.environ["EVALUATION_MODEL"], "api_version": "2024-06-01", "api_key": connection.key, } groundedness = GroundednessEvaluator(evaluator_model)Adicione código para criar uma função wrapper que implemente a interface de avaliação para avaliação de consulta e resposta:
def evaluate_chat_with_products(query): response = chat_with_products(messages=[{"role": "user", "content": query}]) return {"response": response["message"].content, "context": response["context"]["grounding_data"]}Por fim, adicione código para executar a avaliação, exiba os resultados localmente e forneça um link para os resultados da avaliação no portal do Azure AI Foundry:
# Evaluate must be called inside of __main__, not on import if __name__ == "__main__": from config import ASSET_PATH # workaround for multiprocessing issue on linux from pprint import pprint from pathlib import Path import multiprocessing import contextlib with contextlib.suppress(RuntimeError): multiprocessing.set_start_method("spawn", force=True) # run evaluation with a dataset and target function, log to the project result = evaluate( data=Path(ASSET_PATH) / "chat_eval_data.jsonl", target=evaluate_chat_with_products, evaluation_name="evaluate_chat_with_products", evaluators={ "groundedness": groundedness, }, evaluator_config={ "default": { "query": {"${data.query}"}, "response": {"${target.response}"}, "context": {"${target.context}"}, } }, azure_ai_project=project.scope, output_path="./myevalresults.json", ) tabular_result = pd.DataFrame(result.get("rows")) pprint("-----Summarized Metrics-----") pprint(result["metrics"]) pprint("-----Tabular Result-----") pprint(tabular_result) pprint(f"View evaluation results in AI Studio: {result['studio_url']}")
Configurar o modelo de avaliação
Como o script de avaliação chama o modelo muitas vezes, convém aumentar o número de tokens por minuto para o modelo de avaliação.
Na Parte 1 desta série de tutoriais, você criou um arquivo .env que especifica o nome do modelo de avaliação, gpt-4o-mini. Tente aumentar o limite de tokens por minuto para este modelo, se você tiver cota disponível. Se você não tem cota suficiente para aumentar o valor, não se preocupe. O script é projetado para lidar com erros de limite.
- No seu projeto no portal do Azure AI Foundry, selecione Modelos + pontos de extremidade.
- Selecione gpt-4o-mini.
- Selecione Editar.
- Se você tiver uma cota para aumentar o limite de taxa de tokens por minuto, tente aumentá-la para 30.
- Selecione Guardar e fechar.
Executar o script de avaliação
A partir da sua consola, inicie sessão na sua conta do Azure com a CLI do Azure:
az loginInstale o pacote necessário:
pip install azure-ai-evaluation[remote]Agora execute o script de avaliação:
python evaluate.py
Interpretar os resultados da avaliação
Na saída do console, você verá uma resposta para cada pergunta, seguida por uma tabela com métricas resumidas. (Você pode ver colunas diferentes em sua saída.)
Se você não conseguiu aumentar o limite de tokens por minuto para seu modelo, poderá ver alguns erros de tempo limite, que são esperados. O script de avaliação é projetado para lidar com esses erros e continuar em execução.
Nota
Você também pode ver muitos WARNING:opentelemetry.attributes: - estes podem ser ignorados com segurança e não afetam os resultados da avaliação.
====================================================
'-----Summarized Metrics-----'
{'groundedness.gpt_groundedness': 1.6666666666666667,
'groundedness.groundedness': 1.6666666666666667}
'-----Tabular Result-----'
outputs.response ... line_number
0 Could you specify which tent you are referring... ... 0
1 Could you please specify which camping table y... ... 1
2 Sorry, I only can answer queries related to ou... ... 2
3 Could you please clarify which aspects of care... ... 3
4 Sorry, I only can answer queries related to ou... ... 4
5 The TrailMaster X4 Tent comes with an included... ... 5
6 (Failed) ... 6
7 The TrailBlaze Hiking Pants are crafted from h... ... 7
8 Sorry, I only can answer queries related to ou... ... 8
9 Sorry, I only can answer queries related to ou... ... 9
10 Sorry, I only can answer queries related to ou... ... 10
11 The PowerBurner Camping Stove is designed with... ... 11
12 Sorry, I only can answer queries related to ou... ... 12
[13 rows x 8 columns]
('View evaluation results in Azure AI Foundry portal: '
'https://xxxxxxxxxxxxxxxxxxxxxxx')
Exibir resultados da avaliação no portal do Azure AI Foundry
Quando a execução da avaliação for concluída, siga o link para exibir os resultados da avaliação na página Avaliação no portal do Azure AI Foundry.
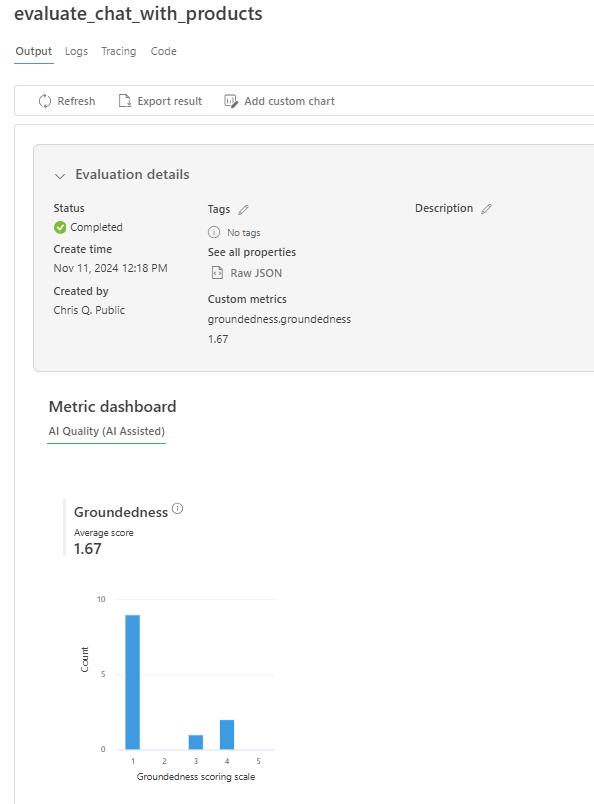
Você também pode examinar as linhas individuais e ver pontuações métricas por linha e exibir o contexto/documentos completos que foram recuperados. Essas métricas podem ser úteis na interpretação e depuração dos resultados da avaliação.
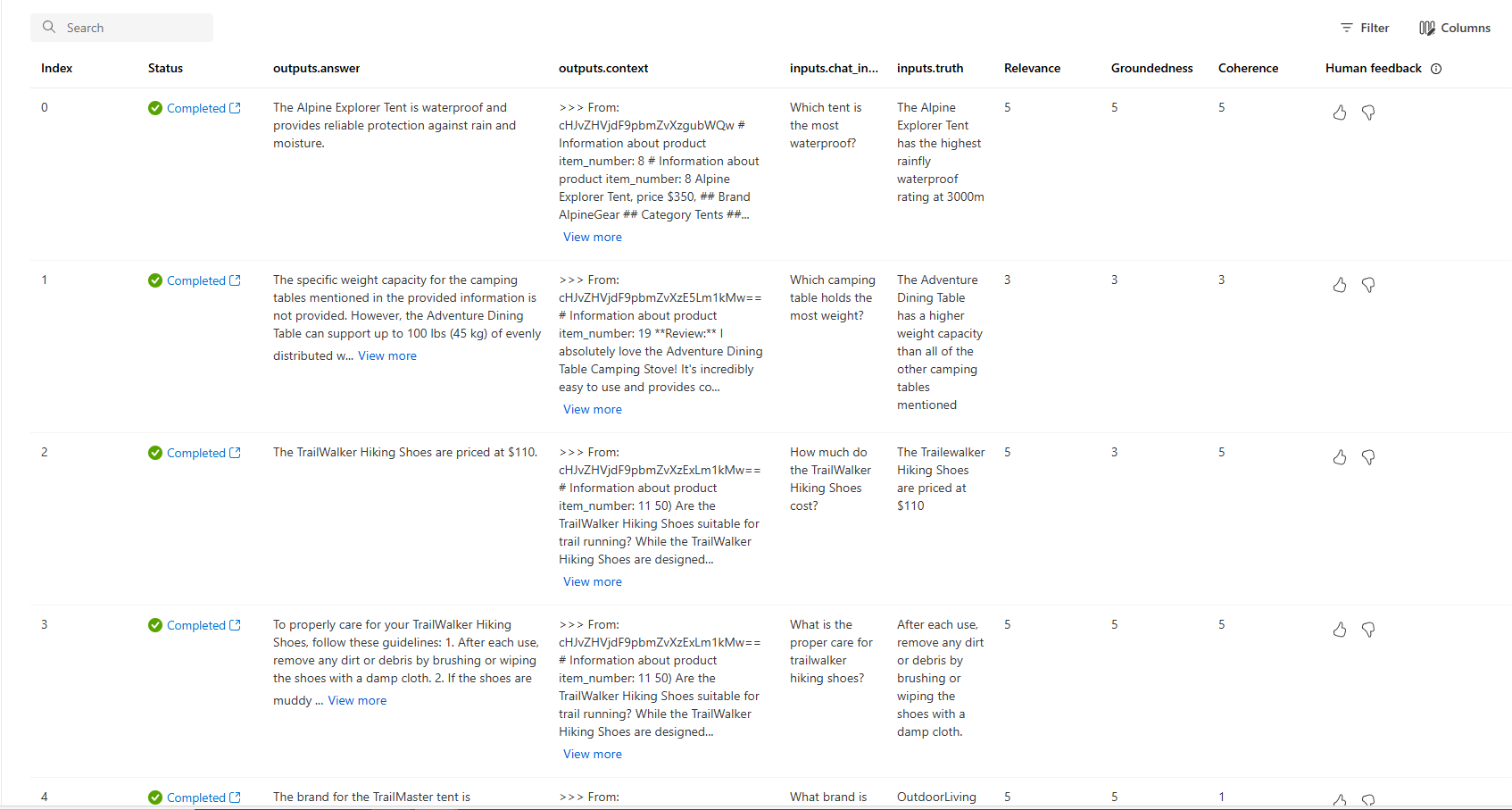
Para obter mais informações sobre os resultados da avaliação no portal do Azure AI Foundry, consulte Como exibir os resultados da avaliação no portal do Azure AI Foundry.
Iterar e melhorar
Observe que as respostas não estão bem fundamentadas. Em muitos casos, o modelo responde com uma pergunta e não com uma resposta. Isso é resultado das instruções do modelo de prompt.
- Em seu arquivo assets/grounded_chat.prompty , encontre a frase "Se a pergunta estiver relacionada a equipamentos e roupas ao ar livre/camping, mas vaga, peça perguntas esclarecedoras em vez de fazer referência a documentos".
- Altere a frase para "Se a pergunta estiver relacionada com equipamento e vestuário para exterior/campismo, mas vaga, tente responder com base nos documentos de referência e, em seguida, peça perguntas esclarecedoras."
- Salve o arquivo e execute novamente o script de avaliação.
Tente outras modificações no modelo de prompt ou tente modelos diferentes, para ver como as alterações afetam os resultados da avaliação.
Clean up resources (Limpar recursos)
Para evitar incorrer em custos desnecessários do Azure, você deve excluir os recursos criados neste tutorial se eles não forem mais necessários. Para gerenciar recursos, você pode usar o portal do Azure.