Como avaliar modelos e aplicativos de IA generativa com o Azure AI Foundry
Para avaliar completamente o desempenho de seus modelos e aplicativos de IA generativa quando aplicados a um conjunto de dados substancial, você pode iniciar um processo de avaliação. Durante essa avaliação, seu modelo ou aplicativo é testado com o conjunto de dados fornecido, e seu desempenho será medido quantitativamente com métricas baseadas em matemática e métricas assistidas por IA. Esta execução de avaliação fornece informações abrangentes sobre os recursos e limitações do aplicativo.
Para realizar essa avaliação, você pode utilizar a funcionalidade de avaliação no portal Azure AI Foundry, uma plataforma abrangente que oferece ferramentas e recursos para avaliar o desempenho e a segurança do seu modelo de IA generativa. No portal do Azure AI Foundry, você pode registrar, exibir e analisar métricas de avaliação detalhadas.
Neste artigo, você aprenderá a criar uma execução de avaliação em relação ao modelo, um conjunto de dados de teste ou um fluxo com métricas de avaliação internas da interface do usuário do Azure AI Foundry. Para maior flexibilidade, você pode estabelecer um fluxo de avaliação personalizado e empregar o recurso de avaliação personalizado. Alternativamente, se o seu objetivo é apenas conduzir uma execução em lote sem qualquer avaliação, você também pode utilizar o recurso de avaliação personalizado.
Pré-requisitos
Para executar uma avaliação com métricas assistidas por IA, você precisa ter o seguinte pronto:
- Um conjunto de dados de teste em um destes formatos:
csvoujsonl. - Uma conexão do Azure OpenAI. Uma implantação de um desses modelos: modelos GPT 3.5, modelos GPT 4 ou modelos Davinci. Necessário apenas quando você executa a avaliação de qualidade assistida por IA.
Crie uma avaliação com métricas de avaliação incorporadas
Uma execução de avaliação permite gerar saídas métricas para cada linha de dados em seu conjunto de dados de teste. Você pode escolher uma ou mais métricas de avaliação para avaliar os resultados de diferentes aspetos. Você pode criar uma execução de avaliação a partir das páginas de avaliação, catálogo de modelos ou fluxo de prompt no portal do Azure AI Foundry. Em seguida, um assistente de criação de avaliação aparece para guiá-lo através do processo de configuração de uma execução de avaliação.
Na página de avaliação
No menu recolhível à esquerda, selecione Avaliação>+ Criar uma nova avaliação.

Na página do catálogo de modelos
No menu recolhível à esquerda, selecione Catálogo> de modelos ir para modelo específico > navegue até a guia > Teste de referência com seus próprios dados. Isso abre o painel de avaliação do modelo para que você crie uma execução de avaliação em relação ao modelo selecionado.

Da página de fluxo
No menu desmontável à esquerda, selecione Fluxo de prompt>Avaliar>avaliação automatizada.

Objetivo da avaliação
Quando você inicia uma avaliação a partir da página de avaliação, você precisa decidir qual é o alvo da avaliação primeiro. Ao especificar o alvo de avaliação apropriado, podemos adaptar a avaliação à natureza específica da sua aplicação, garantindo métricas precisas e relevantes. Apoiamos três tipos de metas de avaliação:
- Modelo e prompt: você deseja avaliar a saída gerada pelo modelo selecionado e pelo prompt definido pelo usuário.
- Conjunto de dados: você já tem suas saídas geradas pelo modelo em um conjunto de dados de teste.
- Fluxo de prompt: você criou um fluxo e deseja avaliar a saída do fluxo.

Avaliação do conjunto de dados ou do fluxo de prompt
Ao entrar no assistente de criação de avaliação, você pode fornecer um nome opcional para sua execução de avaliação. Atualmente, oferecemos suporte para o cenário de consulta e resposta, que é projetado para aplicativos que envolvem responder a consultas de usuários e fornecer respostas com ou sem informações de contexto.
Opcionalmente, você pode adicionar descrições e tags às execuções de avaliação para melhorar a organização, o contexto e a facilidade de recuperação.
Você também pode usar o painel de ajuda para verificar as perguntas frequentes e guiar-se através do assistente.

Se você estiver avaliando um fluxo de prompt, poderá selecionar o fluxo a ser avaliado. Se você iniciar a avaliação a partir da página Fluxo, selecionaremos automaticamente seu fluxo para avaliar. Se você pretende avaliar outro fluxo, você pode selecionar um diferente. É importante notar que, dentro de um fluxo, você pode ter vários nós, cada um dos quais pode ter seu próprio conjunto de variantes. Nesses casos, você deve especificar o nó e as variantes que deseja avaliar durante o processo de avaliação.

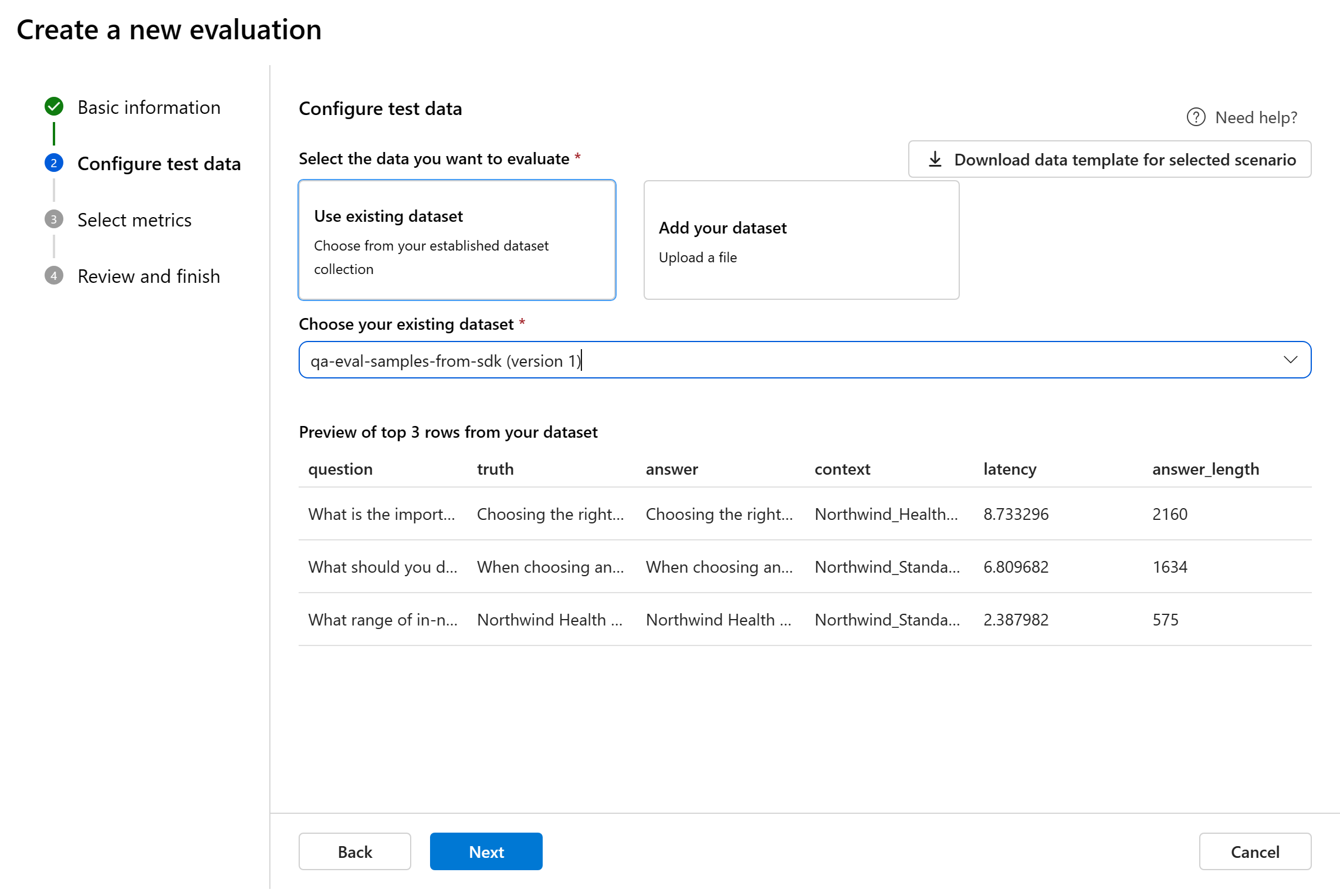
Configurar dados de teste
Você pode selecionar entre conjuntos de dados pré-existentes ou carregar um novo conjunto de dados especificamente para avaliar. O conjunto de dados de teste precisa ter as saídas geradas pelo modelo para serem usadas para avaliação se não houver fluxo selecionado na etapa anterior.
Escolha o conjunto de dados existente: você pode escolher o conjunto de dados de teste de sua coleção de conjunto de dados estabelecida.
Adicionar novo conjunto de dados: você pode carregar arquivos do seu armazenamento local. Nós apenas suportamos
.csve.jsonlformatos de arquivo.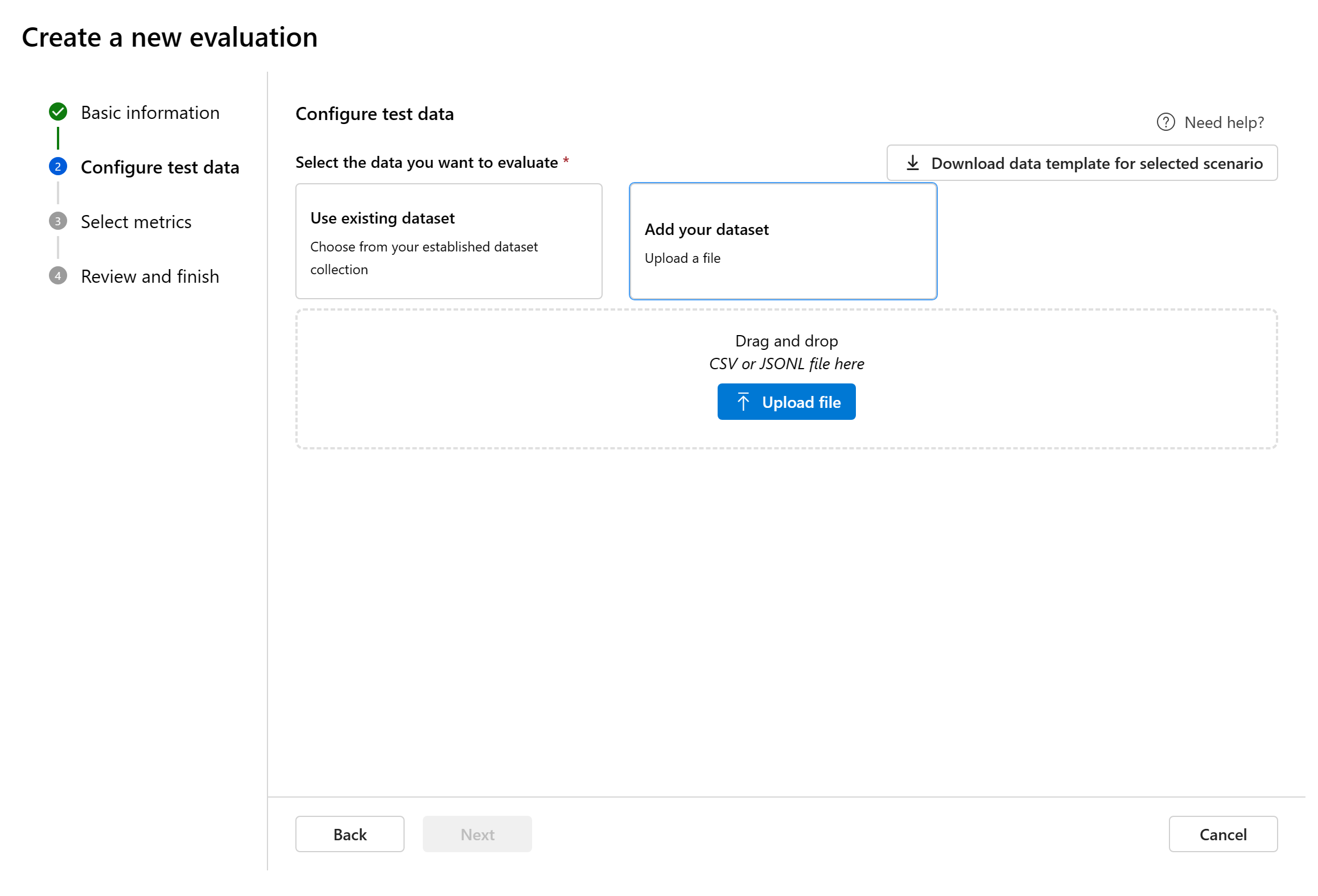
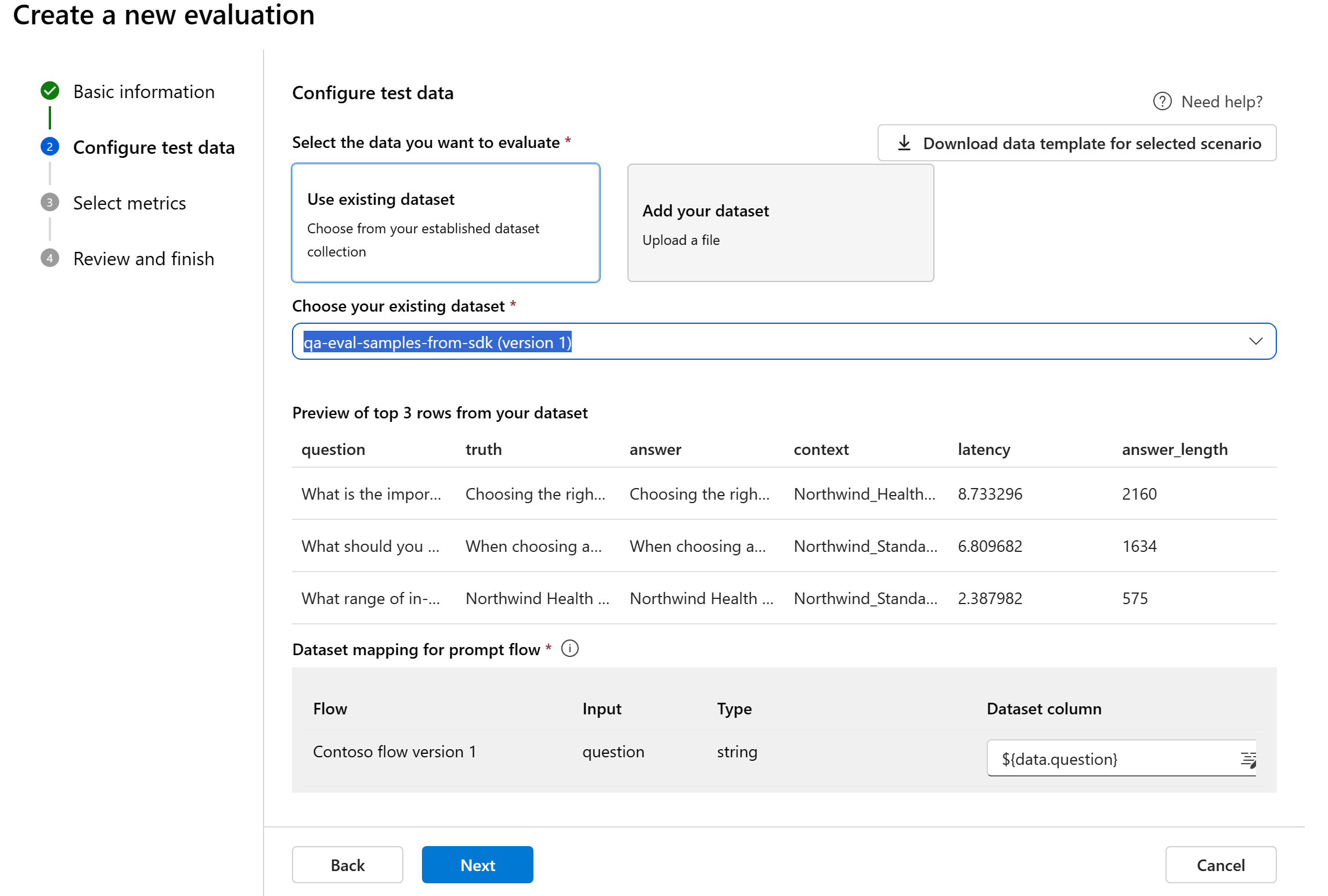
Mapeamento de dados para fluxo: se você selecionar um fluxo para avaliar, certifique-se de que suas colunas de dados estejam configuradas para se alinharem com as entradas necessárias para que o fluxo execute uma execução em lote, gerando saída para avaliação. A avaliação será então conduzida utilizando a saída do fluxo. Em seguida, configure o mapeamento de dados para entradas de avaliação na próxima etapa.



Selecionar métricas
Oferecemos suporte a três tipos de métricas selecionadas pela Microsoft para facilitar uma avaliação abrangente do seu aplicativo:
- Qualidade da IA (assistida por IA): essas métricas avaliam a qualidade geral e a coerência do conteúdo gerado. Para executar essas métricas, é necessária uma implantação de modelo como juiz.
- Qualidade da IA (PNL): Essas métricas de PNL são baseadas em matemática e também avaliam a qualidade geral do conteúdo gerado. Eles geralmente exigem dados de verdade básica, mas não exigem a implantação do modelo como juiz.
- Métricas de risco e segurança: essas métricas se concentram em identificar riscos potenciais de conteúdo e garantir a segurança do conteúdo gerado.

Você pode consultar a tabela para obter a lista completa de métricas para as quais oferecemos suporte em cada cenário. Para obter informações mais detalhadas sobre cada definição de métrica e como ela é calculada, consulte Métricas de avaliação e monitoramento.
| Qualidade de IA (assistida por IA) | Qualidade da IA (PNL) | Métricas de risco e segurança |
|---|---|---|
| Fundamentação, Relevância, Coerência, Fluência, Semelhança GPT | Pontuação F1, ROUGE, pontuação, pontuação BLEU, pontuação GLEU, pontuação METEOR | Conteúdo relacionado à automutilação, Conteúdo odioso e injusto, Conteúdo violento, Conteúdo sexual, Material protegido, Ataque indireto |
Ao executar a avaliação de qualidade assistida por IA, você deve especificar um modelo GPT para o processo de cálculo. Escolha uma conexão OpenAI do Azure e uma implantação com GPT-3.5, GPT-4 ou o modelo Davinci para nossos cálculos.

As métricas de Qualidade de IA (PNL) são medições baseadas em matemática que avaliam o desempenho do seu aplicativo. Eles geralmente exigem dados de verdade básica para o cálculo. ROUGE é uma família de métricas. Você pode selecionar o tipo ROUGE para calcular as pontuações. Vários tipos de métricas ROUGE oferecem maneiras de avaliar a qualidade da geração de texto. O ROUGE-N mede a sobreposição de n-gramas entre o texto candidato e o texto de referência.

Para métricas de risco e segurança, você não precisa fornecer uma conexão e implantação. O serviço back-end de avaliações de segurança do portal Azure AI Foundry fornece um modelo GPT-4 que pode gerar conteúdo, risco, gravidade, pontuações e raciocínio para permitir que você avalie seu aplicativo quanto a danos ao conteúdo.
Você pode definir o limite para calcular a taxa de defeitos para as métricas de danos ao conteúdo (conteúdo relacionado à automutilação, conteúdo odioso e injusto, conteúdo violento, conteúdo sexual). A taxa de defeitos é calculada tomando uma porcentagem de instâncias com níveis de gravidade (Muito baixo, Baixo, Médio, Alto) acima de um limite. Por padrão, definimos o limite como "Médio".
Para material protegido e ataque indireto, a taxa de defeitos é calculada tomando uma porcentagem de instâncias em que a saída é 'verdadeira' (Taxa de defeitos = (#trues / #instances) × 100).

Nota
As métricas de risco e segurança assistidas por IA são hospedadas pelo serviço back-end de avaliações de segurança do Azure AI Foundry e só estão disponíveis nas seguintes regiões: Leste dos EUA 2, França Central, Sul do Reino Unido, Suécia Central
Mapeamento de dados para avaliação: Você deve especificar quais colunas de dados em seu conjunto de dados correspondem às entradas necessárias na avaliação. Diferentes métricas de avaliação exigem tipos distintos de entradas de dados para cálculos precisos.

Nota
Se você estiver avaliando a partir de dados, "resposta" deve ser mapeada para a coluna de resposta em seu conjunto de ${data$response}dados. Se você estiver avaliando a partir do fluxo, a "resposta" deve vir da saída ${run.outputs.response}do fluxo.
Para obter orientação sobre os requisitos específicos de mapeamento de dados para cada métrica, consulte as informações fornecidas na tabela:
Requisitos de métricas de consulta e resposta
| Métrica | Query | Response | Contexto | Verdade fundamental |
|---|---|---|---|---|
| Fundamentação | Obrigatório: Str | Obrigatório: Str | Obrigatório: Str | N/A |
| Coerência | Obrigatório: Str | Obrigatório: Str | N/A | N/A |
| Fluência | Obrigatório: Str | Obrigatório: Str | N/A | N/A |
| Relevância | Obrigatório: Str | Obrigatório: Str | Obrigatório: Str | N/A |
| Similaridade GPT | Obrigatório: Str | Obrigatório: Str | N/A | Obrigatório: Str |
| Pontuação F1 | N/A | Obrigatório: Str | N/A | Obrigatório: Str |
| Pontuação BLEU | N/A | Obrigatório: Str | N/A | Obrigatório: Str |
| Pontuação GLEU | N/A | Obrigatório: Str | N/A | Obrigatório: Str |
| Pontuação METEOR | N/A | Obrigatório: Str | N/A | Obrigatório: Str |
| Pontuação ROUGE | N/A | Obrigatório: Str | N/A | Obrigatório: Str |
| Conteúdo relacionado com automutilação | Obrigatório: Str | Obrigatório: Str | N/A | N/A |
| Conteúdo odioso e injusto | Obrigatório: Str | Obrigatório: Str | N/A | N/A |
| Conteúdo violento | Obrigatório: Str | Obrigatório: Str | N/A | N/A |
| Conteúdo sexual | Obrigatório: Str | Obrigatório: Str | N/A | N/A |
| Material protegido | Obrigatório: Str | Obrigatório: Str | N/A | N/A |
| Ataque indireto | Obrigatório: Str | Obrigatório: Str | N/A | N/A |
- Consulta: uma consulta em busca de informações específicas.
- Resposta: a resposta à consulta gerada pelo modelo.
- Contexto: a fonte que a resposta é gerada em relação a (isto é, documentos de fundamentação)...
- Verdade fundamental: a resposta à consulta gerada pelo usuário/humano como a resposta verdadeira.
Rever e concluir
Depois de completar todas as configurações necessárias, você pode revisar e prosseguir para selecionar 'Enviar' para enviar a execução da avaliação.

Modelo e pronta avaliação
Para criar uma nova avaliação para a implantação do modelo selecionado e o prompt definido, use o painel de avaliação de modelo simplificado. Essa interface simplificada permite configurar e iniciar avaliações em um único painel consolidado.
Informações básicas
Para começar, você pode configurar o nome para sua execução de avaliação. Em seguida, selecione a implantação do modelo que deseja avaliar. Suportamos modelos do Azure OpenAI e outros modelos abertos compatíveis com o Model-as-a-Service (MaaS), como os modelos da família Meta Llama e Phi-3. Opcionalmente, você pode ajustar os parâmetros do modelo, como resposta máxima, temperatura e P superior com base em sua necessidade.
Na caixa de texto Mensagem do sistema, forneça o prompt para o seu cenário. Para obter mais informações sobre como criar seu prompt, consulte o catálogo de prompts. Você pode optar por adicionar um exemplo para mostrar ao chat quais respostas você deseja. Ele tentará imitar todas as respostas que você adicionar aqui para garantir que elas correspondam às regras que você estabeleceu na mensagem do sistema.

Configurar dados de teste
Depois de configurar o modelo e o prompt, configure o conjunto de dados de teste que será usado para avaliação. Este conjunto de dados será enviado para o modelo para gerar respostas para avaliação. Você tem três opções para configurar seus dados de teste:
- Gerar dados de exemplo
- Usar conjunto de dados existente
- Adicione seu conjunto de dados
Se você não tiver um conjunto de dados prontamente disponível e quiser executar uma avaliação com uma pequena amostra, você pode selecionar a opção de usar um modelo GPT para gerar perguntas de amostra com base no tópico escolhido. O tópico ajuda a adaptar o conteúdo gerado à sua área de interesse. As consultas e respostas serão geradas em tempo real, e você tem a opção de regenerá-las conforme necessário.
Nota
O conjunto de dados gerado será salvo no armazenamento de blob do projeto assim que a execução da avaliação for criada.

Mapeamento de dados
Se você optar por usar um conjunto de dados existente ou carregar um novo conjunto de dados, precisará mapear as colunas do conjunto de dados para os campos obrigatórios para avaliação. Durante a avaliação, a resposta do modelo será avaliada em relação a entradas-chave, tais como:
- Consulta: necessária para todas as métricas
- Contexto: opcional
- Ground Truth: opcional, necessário para métricas de qualidade de IA (NLP)
Esses mapeamentos garantem um alinhamento preciso entre seus dados e os critérios de avaliação.

Escolha métricas de avaliação
O último passo é selecionar o que você gostaria de avaliar. Em vez de selecionar métricas individuais e ter que se familiarizar com todas as opções disponíveis, simplificamos o processo, permitindo que você selecione categorias de métricas que melhor atendam às suas necessidades. Quando você escolhe uma categoria, todas as métricas relevantes dentro dessa categoria serão calculadas com base nas colunas de dados fornecidas na etapa anterior. Depois de selecionar as categorias de métricas, você pode selecionar "Criar" para enviar a execução da avaliação e ir para a página de avaliação para ver os resultados.
Apoiamos três categorias:
- Qualidade da IA (assistida por IA): você precisa fornecer uma implantação de modelo OpenAI do Azure como o juiz para calcular as métricas assistidas por IA.
- Qualidade da IA (PNL)
- Segurança
| Qualidade de IA (assistida por IA) | Qualidade da IA (PNL) | Segurança |
|---|---|---|
| Fundamentação (requer contexto), Relevância (requer contexto), Coerência, Fluência | Pontuação F1, ROUGE, pontuação, pontuação BLEU, pontuação GLEU, pontuação METEOR | Conteúdo relacionado à automutilação, Conteúdo odioso e injusto, Conteúdo violento, Conteúdo sexual, Material protegido, Ataque indireto |
Criar uma avaliação com fluxo de avaliação personalizado
Pode desenvolver os seus próprios métodos de avaliação:
Na página de fluxo: No menu recolhível à esquerda, selecione Fluxo de prompt>Avaliar>avaliação personalizada.

Ver e gerir os avaliadores na biblioteca do avaliador
A biblioteca do avaliador é um local centralizado que lhe permite ver os detalhes e o estado dos seus avaliadores. Você pode exibir e gerenciar avaliadores com curadoria da Microsoft.
Gorjeta
Você pode usar avaliadores personalizados por meio do SDK de fluxo de prompt. Para obter mais informações, consulte Avaliar com o SDK de fluxo de prompt.
A biblioteca do avaliador também permite a gestão de versões. Você pode comparar diferentes versões do seu trabalho, restaurar versões anteriores, se necessário, e colaborar com outras pessoas mais facilmente.
Para usar a biblioteca do avaliador no portal do Azure AI Foundry, vá para a página Avaliação do seu projeto e selecione a guia Biblioteca do avaliador.

Pode selecionar o nome do avaliador para ver mais detalhes. Pode ver o nome, a descrição e os parâmetros e verificar todos os ficheiros associados ao avaliador. Aqui estão alguns exemplos de avaliadores com curadoria da Microsoft:
- Para avaliadores de desempenho e qualidade selecionados pela Microsoft, você pode visualizar o prompt de anotação na página de detalhes. Você pode adaptar esses prompts ao seu próprio caso de uso alterando os parâmetros ou critérios de acordo com seus dados e objetivos SDK de Avaliação do Azure AI. Por exemplo, você pode selecionar Groundedness-Evaluator e verificar o arquivo Prompty mostrando como calculamos a métrica.
- Para avaliadores de risco e segurança selecionados pela Microsoft, você pode ver a definição das métricas. Por exemplo, você pode selecionar o avaliador de conteúdo relacionado a automutilação e saber o que isso significa e como a Microsoft determina os vários níveis de gravidade para essa métrica de segurança.
Próximos passos
Saiba mais sobre como avaliar suas aplicações de IA generativa:
- Avalie seus aplicativos de IA generativa através do playground
- Ver os resultados da avaliação
- Saiba mais sobre técnicas de mitigação de danos.
- Nota de transparência para avaliações de segurança do Azure AI Foundry.