Desempenho e latência
Este artigo fornece informações básicas sobre como a latência e a taxa de transferência funcionam com o Azure OpenAI e como otimizar seu ambiente para melhorar o desempenho.
Noções básicas sobre taxa de transferência vs latência
Há dois conceitos-chave a serem considerados ao dimensionar um aplicativo: (1) taxa de transferência no nível do sistema medida em tokens por minuto (TPM) e (2) tempos de resposta por chamada (também conhecidos como latência).
Taxa de transferência no nível do sistema
Isso analisa a capacidade geral de sua implantação – quantas solicitações por minuto e o total de tokens que podem ser processados.
Para uma implantação padrão, a cota atribuída à sua implantação determina parcialmente a quantidade de taxa de transferência que você pode alcançar. No entanto, a cota determina apenas a lógica de admissão para chamadas para a implantação e não está impondo diretamente a taxa de transferência. Devido às variações de latência por chamada, talvez não seja possível atingir uma taxa de transferência tão alta quanto sua cota. Saiba mais sobre a gestão de quotas.
Em uma implantação provisionada, uma quantidade definida de capacidade de processamento de modelo é alocada ao seu ponto de extremidade. A quantidade de taxa de transferência que você pode obter no ponto de extremidade é um fator da forma da carga de trabalho, incluindo a quantidade de token de entrada, a quantidade de saída, a taxa de chamada e a taxa de correspondência de cache. O número de chamadas simultâneas e o total de tokens processados podem variar com base nesses valores.
Para todos os tipos de implantação, compreender a taxa de transferência no nível do sistema é um componente fundamental para otimizar o desempenho. É importante considerar a taxa de transferência no nível do sistema para uma determinada combinação de modelo, versão e carga de trabalho, pois a taxa de transferência variará entre esses fatores.
Estimativa da taxa de transferência no nível do sistema
Estimando o TPM com métricas do Azure Monitor
Uma abordagem para estimar a taxa de transferência no nível do sistema para uma determinada carga de trabalho é usar dados históricos de uso de token. Para cargas de trabalho do Azure OpenAI, todos os dados históricos de uso podem ser acessados e visualizados com os recursos de monitoramento nativos oferecidos no Azure OpenAI. Duas métricas são necessárias para estimar a taxa de transferência no nível do sistema para cargas de trabalho do Azure OpenAI: (1) Tokens de Prompt Processados e (2) Tokens de Conclusão Gerados.
Quando combinadas, as métricas de Tokens de Prompt Processados (TPM de entrada) e Tokens de Conclusão Gerados (TPM de saída) fornecem uma visão estimada da taxa de transferência no nível do sistema com base no tráfego real da carga de trabalho. Essa abordagem não leva em conta os benefícios do cache de prompt, portanto, será uma estimativa de taxa de transferência do sistema conservadora. Essas métricas podem ser analisadas usando agregação mínima, média e máxima em janelas de 1 minuto em um horizonte de tempo de várias semanas. Recomenda-se analisar esses dados em um horizonte de tempo de várias semanas para garantir que haja pontos de dados suficientes para avaliar. A captura de tela a seguir mostra um exemplo da métrica Tokens de Prompt Processados visualizada no Azure Monitor, que está disponível diretamente por meio do portal do Azure.
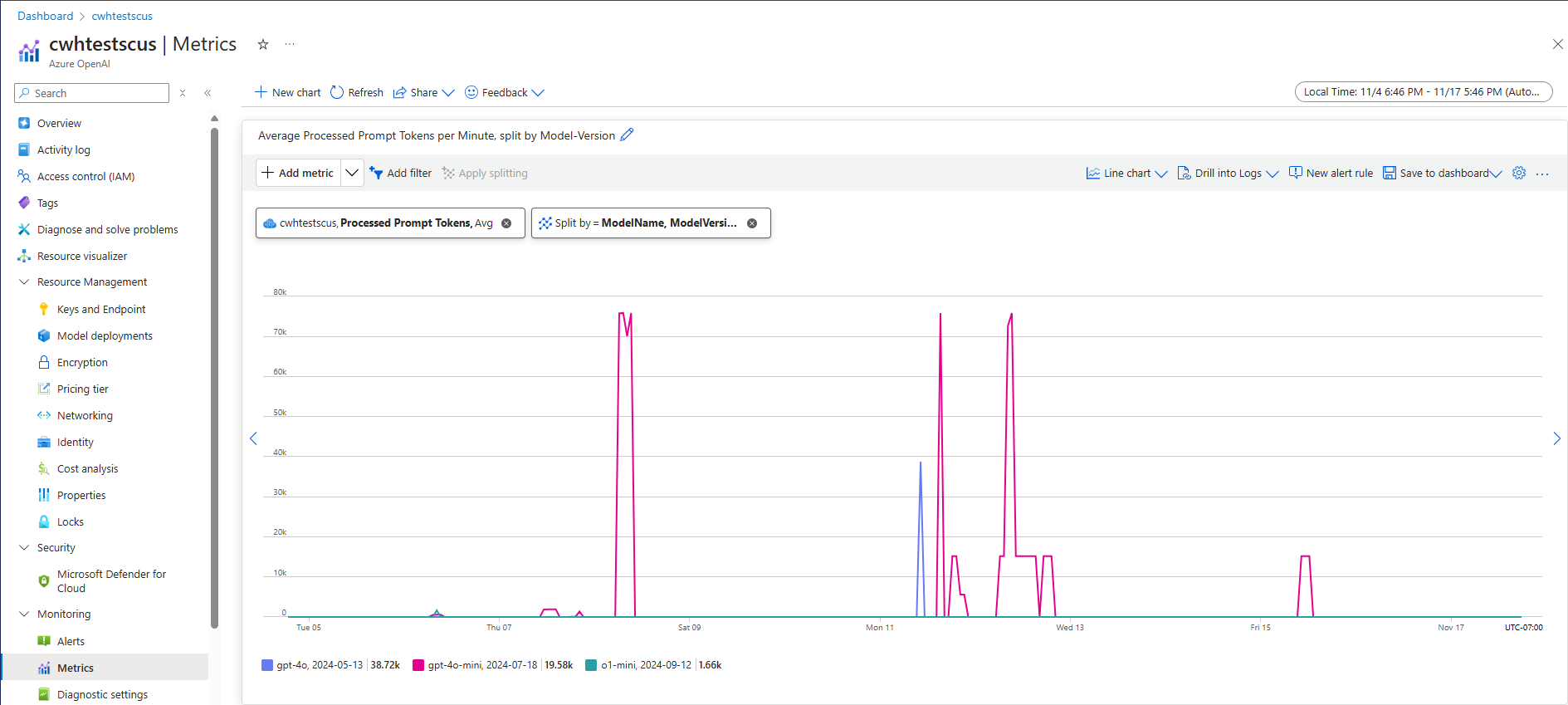
Estimando o TPM a partir dos dados da solicitação
Uma segunda abordagem para a taxa de transferência estimada no nível do sistema envolve a coleta de informações de uso de token de dados de solicitação de API. Esse método fornece uma abordagem mais granular para entender a forma da carga de trabalho por solicitação. A combinação de informações de uso de token por solicitação com o volume de solicitações, medido em solicitações por minuto (RPM), fornece uma estimativa para a taxa de transferência no nível do sistema. É importante observar que quaisquer suposições feitas para a consistência das informações de uso do token entre solicitações e volume de solicitações afetarão a estimativa de taxa de transferência do sistema. Os dados de saída de uso de token podem ser encontrados nos detalhes de resposta da API para uma determinada solicitação de conclusão de chat do Serviço OpenAI do Azure.
{
"body": {
"id": "chatcmpl-7R1nGnsXO8n4oi9UPz2f3UHdgAYMn",
"created": 1686676106,
"choices": [...],
"usage": {
"completion_tokens": 557,
"prompt_tokens": 33,
"total_tokens": 590
}
}
}
Supondo que todas as solicitações para uma determinada carga de trabalho sejam uniformes, os tokens de prompt e os tokens de conclusão dos dados de resposta da API podem ser multiplicados pelo RPM estimado para identificar o TPM de entrada e saída para a carga de trabalho dada.
Como usar estimativas de taxa de transferência no nível do sistema
Depois que a taxa de transferência no nível do sistema tiver sido estimada para uma determinada carga de trabalho, essas estimativas poderão ser usadas para dimensionar implantações Standard e Provisioned. Para implantações padrão, os valores TPM de entrada e saída podem ser combinados para estimar o TPM total a ser atribuído a uma determinada implantação. Para implantações provisionadas, os dados de uso do token de solicitação ou os valores de TPM de entrada e saída podem ser usados para estimar o número de PTUs necessárias para dar suporte a uma determinada carga de trabalho com a experiência da calculadora de capacidade de implantação.
Aqui estão alguns exemplos para o modelo GPT-4o mini:
| Tamanho do prompt (tokens) | Tamanho da geração (tokens) | Pedidos por minuto | TPM de entrada | TPM de saída | Total TPM | PTUs necessárias |
|---|---|---|---|---|---|---|
| 800 | 150 | 30 | 24,000 | 4500 | 28,500 | 15 |
| 5.000 | 50 | 1,000 | 5,000,000 | 50 000 | 5,050,000 | 140 |
| 1,000 | 300 | 500 | 500.000 | 150,000 | 650,000 | 30 |
O número de PTUs é dimensionado aproximadamente linearmente com a taxa de chamada quando a distribuição da carga de trabalho permanece constante.
Latência: Os tempos de resposta por chamada
A definição de alto nível de latência neste contexto é a quantidade de tempo que leva para obter uma resposta de volta do modelo. Para solicitações de conclusão e conclusão de chat, a latência depende em grande parte do tipo de modelo, do número de tokens no prompt e do número de tokens gerados. Em geral, cada token de prompt adiciona pouco tempo em comparação com cada token incremental gerado.
Estimar a latência esperada por chamada pode ser um desafio com esses modelos. A latência de uma solicitação de conclusão pode variar com base em quatro fatores principais: (1) o modelo, (2) o número de tokens no prompt, (3) o número de tokens gerados e (4) a carga geral no sistema de deployment *. Um e três são frequentemente os principais contribuintes para o tempo total. A próxima seção entra em mais detalhes sobre a anatomia de uma chamada de inferência de modelo de linguagem grande.
Melhorar o desempenho
Há vários fatores que você pode controlar para melhorar a latência por chamada do seu aplicativo.
Seleção de modelos
A latência varia de acordo com o modelo que você está usando. Para uma solicitação idêntica, espere que modelos diferentes tenham latências diferentes para a chamada de conclusão do chat. Se o seu caso de uso requer os modelos de menor latência com os tempos de resposta mais rápidos, recomendamos o modelo GPT-4o mini mais recente.
Tamanho da geração e tokens Max
Quando você envia uma solicitação de conclusão para o ponto de extremidade do Azure OpenAI, seu texto de entrada é convertido em tokens que são enviados para seu modelo implantado. O modelo recebe os tokens de entrada e, em seguida, começa a gerar uma resposta. É um processo sequencial iterativo, um token de cada vez. Outra maneira de pensar nisso é como um loop n tokens = n iterationsfor com . Para a maioria dos modelos, gerar a resposta é a etapa mais lenta do processo.
No momento da solicitação, o tamanho de geração solicitado (parâmetro max_tokens) é usado como uma estimativa inicial do tamanho da geração. O tempo de computação para gerar o tamanho completo é reservado pelo modelo à medida que a solicitação é processada. Uma vez concluída a geração, a cota restante é liberada. Maneiras de reduzir o número de tokens:
- Defina o
max_tokensparâmetro em cada chamada o menor possível. - Inclua sequências de parada para evitar a geração de conteúdo extra.
- Gerar menos respostas: Os parâmetros best_of & n podem aumentar muito a latência porque geram várias saídas. Para obter a resposta mais rápida, não especifique esses valores ou defina-os como 1.
Em resumo, reduzir o número de tokens gerados por solicitação reduz a latência de cada solicitação.
Transmissão
A configuração stream: true em uma solicitação faz com que o serviço retorne tokens assim que estiverem disponíveis, em vez de esperar que a sequência completa de tokens seja gerada. Ele não muda o tempo para obter todos os tokens, mas reduz o tempo para a primeira resposta. Esta abordagem proporciona uma melhor experiência do utilizador, uma vez que os utilizadores finais podem ler a resposta à medida que é gerada.
O streaming também é valioso em chamadas grandes que levam muito tempo para serem processadas. Muitos clientes e camadas intermediárias têm tempos limite em chamadas individuais. Chamadas de longa geração podem ser canceladas devido a tempos limite do lado do cliente. Ao transmitir os dados de volta, você pode garantir que os dados incrementais sejam recebidos.
Exemplos de quando usar o streaming:
Bots de chat e interfaces de conversação.
O streaming afeta a latência percebida. Com o streaming habilitado, você recebe tokens de volta em partes assim que eles estiverem disponíveis. Para os usuários finais, essa abordagem geralmente parece que o modelo está respondendo mais rapidamente, embora o tempo total para concluir a solicitação permaneça o mesmo.
Exemplos de quando o streaming é menos importante:
Análise de sentimento, tradução de idiomas, geração de conteúdo.
Há muitos casos de uso em que você está executando alguma tarefa em massa em que você só se preocupa com o resultado final, não com a resposta em tempo real. Se o streaming estiver desativado, você não receberá nenhum token até que o modelo tenha concluído toda a resposta.
Filtragem de conteúdos
O Azure OpenAI inclui um sistema de filtragem de conteúdo que funciona em conjunto com os modelos principais. Este sistema funciona executando tanto o prompt como o preenchimento através de um conjunto de modelos de classificação destinados a detetar e prevenir a saída de conteúdo nocivo.
O sistema de filtragem de conteúdo deteta e age em categorias específicas de conteúdo potencialmente nocivo em prompts de entrada e finalizações de saída.
A adição de filtragem de conteúdo vem com um aumento na segurança, mas também na latência. Há muitos aplicativos onde essa troca no desempenho é necessária, no entanto, há certos casos de uso de menor risco em que a desativação dos filtros de conteúdo para melhorar o desempenho pode valer a pena explorar.
Saiba mais sobre como solicitar modificações nas políticas padrão de filtragem de conteúdo.
Separação das cargas de trabalho
Misturar cargas de trabalho diferentes no mesmo ponto de extremidade pode afetar negativamente a latência. Isso ocorre porque (1) eles são agrupados em lote durante a inferência e chamadas curtas podem estar esperando por finalizações mais longas e (2) misturar as chamadas pode reduzir sua taxa de acerto de cache, pois ambos estão competindo pelo mesmo espaço. Quando possível, é recomendável ter implantações separadas para cada carga de trabalho.
Tamanho do prompt
Embora o tamanho do prompt tenha menor influência na latência do que o tamanho da geração, ele afeta o tempo total, especialmente quando o tamanho cresce muito.
Criação de batches
Se você estiver enviando várias solicitações para o mesmo ponto de extremidade, poderá agrupá-las em uma única chamada. Isso reduz o número de solicitações que você precisa fazer e, dependendo do cenário, pode melhorar o tempo de resposta geral. Recomendamos testar este método para ver se ele ajuda.
Como medir sua taxa de transferência
Recomendamos medir sua taxa de transferência geral em uma implantação com duas medidas:
- Chamadas por minuto: o número de chamadas de inferência de API que você está fazendo por minuto. Isso pode ser medido no Azure-monitor usando a métrica Solicitações OpenAI do Azure e dividindo pelo ModelDeploymentName
- Total de tokens por minuto: o número total de tokens sendo processados por minuto pela sua implantação. Isso inclui tokens gerados por prompt. Isso geralmente é dividido em medir ambos para uma compreensão mais profunda do desempenho da implantação. Isso pode ser medido no Azure-Monitor usando a métrica de tokens de Inferência Processada.
Você pode saber mais sobre como monitorar o serviço OpenAI do Azure.
Como medir a latência por chamada
O tempo necessário para cada chamada depende do tempo necessário para ler o modelo, gerar a saída e aplicar filtros de conteúdo. A maneira como você mede o tempo varia se você está usando streaming ou não. Sugerimos um conjunto diferente de medidas para cada caso.
Você pode saber mais sobre como monitorar o serviço OpenAI do Azure.
Não Streaming:
- Tempo de solicitação de ponta a ponta: o tempo total necessário para gerar toda a resposta para solicitações que não são de streaming, conforme medido pelo gateway de API. Esse número aumenta à medida que o tamanho da geração aumenta.
Streaming:
- Tempo de resposta: medida de latência (capacidade de resposta) recomendada para solicitações de streaming. Aplica-se a implantações gerenciadas por PTU e PTU. Calculado como o tempo necessário para que a primeira resposta apareça depois que um usuário envia um prompt, conforme medido pelo gateway de API. Esse número aumenta à medida que o tamanho do prompt aumenta e/ou o tamanho do acerto diminui.
- Tempo médio de taxa de geração de token do primeiro ao último token, dividido pelo número de tokens gerados, conforme medido pelo gateway de API. Isso mede a velocidade de geração de resposta e aumenta à medida que a carga do sistema aumenta. Medida de latência recomendada para solicitações de streaming.
Resumo
Latência do modelo: Se a latência do modelo for importante para você, recomendamos experimentar o modelo GPT-4o mini.
Tokens máximos mais baixos: A OpenAI descobriu que, mesmo nos casos em que o número total de tokens gerados é semelhante, a solicitação com o valor mais alto definido para o parâmetro max token terá mais latência.
Menor total de tokens gerados: quanto menos tokens gerados, mais rápida será a resposta geral. Lembre-se que isso é como ter um loop for com
n tokens = n iterations. Reduza o número de tokens gerados e o tempo de resposta geral irá melhorar em conformidade.Streaming: Habilitar o streaming pode ser útil para gerenciar as expectativas do usuário em determinadas situações, permitindo que o usuário veja a resposta do modelo enquanto ela está sendo gerada, em vez de ter que esperar até que o último token esteja pronto.
A filtragem de conteúdo melhora a segurança, mas também afeta a latência. Avalie se alguma de suas cargas de trabalho se beneficiaria de políticas de filtragem de conteúdo modificadas.