Personalizar um modelo com ajuste fino
O Serviço OpenAI do Azure permite-lhe adaptar os nossos modelos aos seus conjuntos de dados pessoais utilizando um processo conhecido como ajuste fino. Este passo de personalização permite-lhe tirar melhor partido do serviço, fornecendo:
- Resultados de maior qualidade do que o que você pode obter apenas com a engenharia imediata
- A capacidade de treinar em mais exemplos do que pode caber no limite máximo de contexto de solicitação de um modelo.
- Economia de token devido a prompts mais curtos
- Solicitações de baixa latência, especialmente ao usar modelos menores.
Em contraste com o aprendizado de poucas etapas, o ajuste fino melhora o modelo treinando em muito mais exemplos do que podem caber em um prompt, permitindo que você obtenha melhores resultados em um grande número de tarefas. Como o ajuste fino ajusta os pesos do modelo base para melhorar o desempenho na tarefa específica, você não precisará incluir tantos exemplos ou instruções em seu prompt. Isso significa menos texto enviado e menos tokens processados em cada chamada de API, potencialmente economizando custos e melhorando a latência da solicitação.
Usamos LoRA, ou aproximação de classificação baixa, para ajustar os modelos de forma a reduzir a sua complexidade sem afetar significativamente o seu desempenho. Este método funciona aproximando a matriz original de alto nível com um de classificação inferior, ajustando apenas um subconjunto menor de parâmetros importantes durante a fase de treinamento supervisionado, tornando o modelo mais gerenciável e eficiente. Para os usuários, isso torna o treinamento mais rápido e mais acessível do que outras técnicas.
Há duas experiências exclusivas de ajuste fino no portal do Azure AI Foundry:
- Visualização de Hub/Projeto - suporta modelos de ajuste fino de vários provedores, incluindo Azure OpenAI, Meta Llama, Microsoft Phi, etc.
- Vista centrada no Azure OpenAI - suporta apenas o ajuste fino de modelos do Azure OpenAI, mas tem suporte para funcionalidades adicionais, como a integração de pré-visualização Pesos e Enviesamentos (W&B).
Se você estiver ajustando apenas os modelos do Azure OpenAI, recomendamos a experiência de ajuste fino centrada no Azure OpenAI, que está disponível navegando até https://oai.azure.com.
Pré-requisitos
- Leia o guia de ajuste fino do Azure OpenAI.
- Uma subscrição do Azure. Crie um gratuitamente.
- Um recurso do Azure OpenAI localizado em uma região que dá suporte ao ajuste fino do modelo do Azure OpenAI. Verifique a tabela de resumo do modelo e a disponibilidade da região para obter a lista de modelos disponíveis por região e funcionalidade suportada. Para obter mais informações, consulte Criar um recurso e implantar um modelo com o Azure OpenAI.
- O ajuste fino do acesso requer o Cognitive Services OpenAI Contributor.
- Se você ainda não tiver acesso para exibir a cota e implantar modelos no portal do Azure AI Foundry, precisará de permissões adicionais.
Modelos
Os seguintes modelos suportam ajuste fino:
babbage-002davinci-002-
gpt-35-turbo(0613) -
gpt-35-turbo(1106) -
gpt-35-turbo(0125) -
gpt-4(0613)* -
gpt-4o(2024-08-06) -
gpt-4o-mini(2024-07-18)
* O ajuste fino para este modelo está atualmente em pré-visualização pública.
Ou você pode ajustar um modelo previamente ajustado, formatado como base-model.ft-{jobid}.
Consulte a página de modelos para verificar quais regiões atualmente oferecem suporte ao ajuste fino.
Rever o fluxo de trabalho do portal do Azure AI Foundry
Reserve um momento para analisar o fluxo de trabalho de ajuste fino para usar o portal do Azure AI Foundry:
- Prepare seus dados de treinamento e validação.
- Use o assistente Criar modelo personalizado no portal do Azure AI Foundry para treinar seu modelo personalizado.
- Selecione um modelo base.
- Escolha seus dados de treinamento.
- Opcionalmente, escolha seus dados de validação.
- Opcionalmente, configure os parâmetros da tarefa para seu trabalho de ajuste fino.
- Reveja as suas escolhas e treine o seu novo modelo personalizado.
- Verifique o status do seu modelo personalizado ajustado.
- Implante seu modelo personalizado para uso.
- Use seu modelo personalizado.
- Opcionalmente, analise seu modelo personalizado quanto ao desempenho e ajuste.
Prepare seus dados de treinamento e validação
Os dados de preparação e os conjuntos de dados de validação consistem em exemplos de entrada e saída de como pretende que o modelo seja executado.
Diferentes tipos de modelo exigem um formato diferente de dados de treinamento.
Os dados de treinamento e validação usados devem ser formatados como um documento JSONL (JSON Lines). Para gpt-35-turbo (todas as versões), gpt-4, gpt-4oe gpt-4o-mini, o conjunto de dados de ajuste fino deve ser formatado no formato de conversação usado pela API de conclusão de bate-papo.
Se você quiser um passo a passo para ajustar um gpt-4o-mini modelo (2024-07-18), consulte o tutorial de ajuste fino do Azure OpenAI.
Exemplo de formato de ficheiro
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
Formato de ficheiro de chat multi-turno Azure OpenAI
Vários turnos de uma conversa em uma única linha do seu arquivo de treinamento jsonl também são suportados. Para ignorar o ajuste fino em mensagens de assistente específicas, adicione o par de valores de chave opcional weight . Atualmente weight pode ser definido como 0 ou 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Conclusão do bate-papo com visão
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Além do formato JSONL, os arquivos de dados de treinamento e validação devem ser codificados em UTF-8 e incluir uma marca de ordem de bytes (BOM). O arquivo deve ter menos de 512 MB de tamanho.
Crie seus conjuntos de dados de treinamento e validação
Quanto mais exemplos de treinamento você tiver, melhor. Os trabalhos de ajuste fino não prosseguirão sem pelo menos 10 exemplos de treinamento, mas um número tão pequeno não é suficiente para influenciar visivelmente as respostas do modelo. É uma boa prática fornecer centenas, se não milhares, de exemplos de formação para serem bem sucedidos.
Em geral, dobrar o tamanho do conjunto de dados pode levar a um aumento linear na qualidade do modelo. Mas tenha em mente que exemplos de baixa qualidade podem afetar negativamente o desempenho. Se você treinar o modelo em uma grande quantidade de dados internos, sem primeiro remover o conjunto de dados apenas para os exemplos da mais alta qualidade, você pode acabar com um modelo com um desempenho muito pior do que o esperado.
Usar o assistente Criar modelo personalizado
O portal do Azure AI Foundry fornece o assistente Criar modelo personalizado, para que você possa criar e treinar interativamente um modelo ajustado para seu recurso do Azure.
Abra o portal do Azure AI Foundry em https://oai.azure.com/ e entre com credenciais que têm acesso ao seu recurso do Azure OpenAI. Durante o fluxo de trabalho de entrada, selecione o diretório apropriado, a assinatura do Azure e o recurso do Azure OpenAI.
No portal do Azure AI Foundry, navegue até o painel Ferramentas > de ajuste finoe selecione Ajustar modelo.


O assistente Criar modelo personalizado é aberto.
Selecione o modelo base
O primeiro passo na criação de um modelo personalizado é escolher um modelo base. O painel Modelo base permite que você escolha um modelo base para usar em seu modelo personalizado. A sua escolha influencia tanto o desempenho como o custo do seu modelo.
Selecione o modelo base na lista suspensa Tipo de modelo base e, em seguida, selecione Avançar para continuar.
Você pode criar um modelo personalizado a partir de um dos seguintes modelos base disponíveis:
babbage-002davinci-002gpt-35-turbo(0613)gpt-35-turbo(1106)gpt-35-turbo(0125)gpt-4(0613)Ou você pode ajustar um modelo previamente ajustado, formatado como base-model.ft-{jobid}.

Para obter mais informações sobre nossos modelos básicos que podem ser ajustados, consulte Modelos.
Escolha seus dados de treinamento
A próxima etapa é escolher os dados de treinamento preparados existentes ou carregar novos dados de treinamento preparados para usar ao personalizar seu modelo. O painel Dados de treinamento exibe todos os conjuntos de dados existentes e carregados anteriormente e também fornece opções para carregar novos dados de treinamento.

Se seus dados de treinamento já estiverem carregados no serviço, selecione Arquivos do Azure OpenAI Connection.
- Selecione o arquivo na lista suspensa mostrada.
Para carregar novos dados de treinamento, use uma das seguintes opções:
Selecione Arquivo local para carregar dados de treinamento de um arquivo local.
Selecione Blob do Azure ou outros locais da Web compartilhados para importar dados de treinamento do Blob do Azure ou outro local da Web compartilhado.
Para arquivos de dados grandes, recomendamos que você importe de um repositório de Blob do Azure. Os ficheiros grandes podem tornar-se instáveis quando carregados através de formulários com várias partes porque os pedidos são atómicos e não podem ser repetidos ou retomados. Para obter mais informações sobre o Armazenamento de Blobs do Azure, consulte O que é o Armazenamento de Blobs do Azure?
Nota
Os arquivos de dados de treinamento devem ser formatados como arquivos JSONL, codificados em UTF-8 com uma marca de ordem de bytes (BOM). O arquivo deve ter menos de 512 MB de tamanho.
Carregar dados de treinamento do arquivo local
Você pode carregar um novo conjunto de dados de treinamento para o serviço a partir de um arquivo local usando um dos seguintes métodos:
Arraste e solte o arquivo na área do cliente do painel Dados de treinamento e selecione Carregar arquivo.
Selecione Procurar um arquivo na área do cliente do painel Dados de treinamento , escolha o arquivo a ser carregado na caixa de diálogo Abrir e selecione Carregar arquivo.
Depois de selecionar e carregar o conjunto de dados de treinamento, selecione Avançar para continuar.

Importar dados de treinamento do repositório de Blobs do Azure
Você pode importar um conjunto de dados de treinamento do Blob do Azure ou outro local da Web compartilhado fornecendo o nome e o local do arquivo.
Digite o nome do arquivo para o arquivo.
Para o local do arquivo, forneça a URL de Blob do Azure, a assinatura de acesso compartilhado (SAS) do Armazenamento do Azure ou outro link para um local da Web compartilhado acessível.
Selecione Importar para importar o conjunto de dados de treinamento para o serviço.
Depois de selecionar e carregar o conjunto de dados de treinamento, selecione Avançar para continuar.

Escolha os seus dados de validação
A próxima etapa fornece opções para configurar o modelo para usar dados de validação no processo de treinamento. Se não quiser usar dados de validação, escolha Avançar para continuar com as opções avançadas do modelo. Caso contrário, se você tiver um conjunto de dados de validação, poderá escolher os dados de validação preparados existentes ou carregar novos dados de validação preparados para usar ao personalizar seu modelo.
O painel Dados de validação exibe todos os conjuntos de dados de treinamento e validação existentes e carregados anteriormente e fornece opções pelas quais você pode carregar novos dados de validação.

Se os dados de validação já tiverem sido carregados para o serviço, selecione Escolher conjunto de dados.
- Selecione o arquivo na lista mostrada no painel Dados de validação .
Para carregar novos dados de validação, use uma das seguintes opções:
Selecione Arquivo local para carregar dados de validação de um arquivo local.
Selecione Blob do Azure ou outros locais da Web compartilhados para importar dados de validação do Blob do Azure ou outro local da Web compartilhado.
Para arquivos de dados grandes, recomendamos que você importe de um repositório de Blob do Azure. Os ficheiros grandes podem tornar-se instáveis quando carregados através de formulários com várias partes porque os pedidos são atómicos e não podem ser repetidos ou retomados.
Nota
Semelhante aos arquivos de dados de treinamento, os arquivos de dados de validação devem ser formatados como arquivos JSONL, codificados em UTF-8 com uma marca de ordem de bytes (BOM). O arquivo deve ter menos de 512 MB de tamanho.
Carregar dados de validação do arquivo local
Você pode carregar um novo conjunto de dados de validação para o serviço a partir de um arquivo local usando um dos seguintes métodos:
Arraste e solte o arquivo na área do cliente do painel Dados de validação e selecione Carregar arquivo.
Selecione Procurar um arquivo na área do cliente do painel Dados de validação, escolha o arquivo a ser carregado na caixa de diálogo Abrir e selecione Carregar arquivo.
Depois de selecionar e carregar o conjunto de dados de validação, selecione Avançar para continuar.

Importar dados de validação do repositório de Blobs do Azure
Você pode importar um conjunto de dados de validação do Blob do Azure ou de outro local da Web compartilhado fornecendo o nome e o local do arquivo.
Digite o nome do arquivo para o arquivo.
Para o local do arquivo, forneça a URL de Blob do Azure, a assinatura de acesso compartilhado (SAS) do Armazenamento do Azure ou outro link para um local da Web compartilhado acessível.
Selecione Importar para importar o conjunto de dados de treinamento para o serviço.
Depois de selecionar e carregar o conjunto de dados de validação, selecione Avançar para continuar.

Configurar parâmetros de tarefa
O assistente Criar modelo personalizado mostra os parâmetros para treinar seu modelo ajustado no painel Parâmetros da tarefa. Os seguintes parâmetros estão disponíveis:
| Nome | Tipo | Descrição |
|---|---|---|
batch_size |
integer | O tamanho do lote a ser usado para treinamento. O tamanho do lote é o número de exemplos de treinamento usados para treinar um único passe para frente e para trás. Em geral, descobrimos que lotes maiores tendem a funcionar melhor para conjuntos de dados maiores. O valor padrão, bem como o valor máximo para essa propriedade são específicos para um modelo base. Um tamanho de lote maior significa que os parâmetros do modelo são atualizados com menos frequência, mas com menor variância. |
learning_rate_multiplier |
Número | O multiplicador da taxa de aprendizagem a utilizar na formação. A taxa de aprendizagem de ajuste fino é a taxa de aprendizagem original usada para pré-treinamento multiplicada por esse valor. Taxas de aprendizagem maiores tendem a ter um melhor desempenho com lotes maiores. Recomendamos experimentar valores no intervalo de 0,02 a 0,2 para ver o que produz os melhores resultados. Uma taxa de aprendizagem menor pode ser útil para evitar o sobreajuste. |
n_epochs |
integer | O número de épocas para treinar o modelo. Uma época refere-se a um ciclo completo através do conjunto de dados de treinamento. |
seed |
integer | A semente controla a reprodutibilidade do trabalho. Passar os mesmos parâmetros de semente e trabalho deve produzir os mesmos resultados, mas pode diferir em casos raros. Se uma semente não for especificada, uma será gerada para você |
Beta |
integer | Parâmetro de temperatura para a perda de dpo, normalmente no intervalo de 0,1 a 0,5. Isso controla a atenção que prestamos ao modelo de referência. Quanto menor o beta, mais permitimos que o modelo se afaste do modelo de referência. À medida que a versão beta fica menor quanto mais, ignoramos o modelo de referência. |

Selecione Padrão para usar os valores padrão para o trabalho de ajuste fino ou selecione Personalizado para exibir e editar os valores de hiperparâmetro. Quando os padrões são selecionados, determinamos o valor correto algoritmicamente com base em seus dados de treinamento.
Depois de configurar as opções avançadas, selecione Avançar para revisar suas escolhas e treinar seu modelo ajustado.
Reveja as suas escolhas e treine o seu modelo
O painel Revisão do assistente exibe informações sobre suas opções de configuração.

Se você estiver pronto para treinar seu modelo, selecione Iniciar trabalho de treinamento para iniciar o trabalho de ajuste fino e retornar ao painel Modelos .
Verificar o estado do seu modelo personalizado
O painel Modelos exibe informações sobre seu modelo personalizado na guia Modelos personalizados . A guia inclui informações sobre o status e a ID do trabalho de ajuste fino para seu modelo personalizado. Quando o trabalho for concluído, a guia exibirá a ID do arquivo de resultado. Talvez seja necessário selecionar Atualizar para ver um status atualizado para o trabalho de treinamento modelo.

Depois de iniciar um trabalho de ajuste fino, ele pode levar algum tempo para ser concluído. Seu trabalho pode estar na fila atrás de outros trabalhos no sistema. O treinamento do seu modelo pode levar minutos ou horas, dependendo do tamanho do modelo e do conjunto de dados.
Aqui estão algumas das tarefas que você pode fazer no painel Modelos :
Verifique o status do trabalho de ajuste fino para seu modelo personalizado na coluna Status da guia Modelos personalizados .
Na coluna Nome do modelo, selecione o nome do modelo para exibir mais informações sobre o modelo personalizado. Você pode ver o status do trabalho de ajuste fino, resultados de treinamento, eventos de treinamento e hiperparâmetros usados no trabalho.
Selecione Baixar arquivo de treinamento para baixar os dados de treinamento usados para o modelo.
Selecione Baixar resultados para baixar o arquivo de resultados anexado ao trabalho de ajuste fino do seu modelo e analisar seu modelo personalizado para desempenho de treinamento e validação.
Selecione Atualizar para atualizar as informações da página.
Pontos de verificação
Quando cada época de treinamento se completa, um ponto de verificação é gerado. Um ponto de verificação é uma versão totalmente funcional de um modelo que pode ser implantado e usado como modelo de destino para trabalhos de ajuste fino subsequentes. Os pontos de verificação podem ser particularmente úteis, pois podem fornecer um instantâneo do seu modelo antes que ocorra um sobreajuste. Quando um trabalho de ajuste fino for concluído, você terá as três versões mais recentes do modelo disponíveis para implantação.
Avaliação de segurança GPT-4, GPT-4o e GPT-4o-mini ajuste fino - visualização pública
GPT-4o, GPT-4o-mini e GPT-4 são os nossos modelos mais avançados que podem ser ajustados às suas necessidades. Tal como acontece com os modelos OpenAI do Azure em geral, as capacidades avançadas dos modelos ajustados vêm com desafios de IA responsáveis acrescidos relacionados com conteúdo prejudicial, manipulação, comportamento semelhante ao humano, questões de privacidade e muito mais. Saiba mais sobre riscos, capacidades e limitações na Visão geral das práticas de IA responsável e na Nota de transparência. Para ajudar a mitigar os riscos associados a modelos avançados ajustados, implementamos etapas de avaliação adicionais para ajudar a detetar e prevenir conteúdo nocivo no treinamento e nos resultados de modelos ajustados. Essas etapas são baseadas na filtragem de conteúdo do Microsoft Responsible AI Standard e do Azure OpenAI Service.
- As avaliações são realizadas em espaços de trabalho dedicados, específicos do cliente e privados;
- Os pontos de extremidade de avaliação estão na mesma geografia que o recurso OpenAI do Azure;
- Os dados de treinamento não são armazenados em conexão com a realização de avaliações; apenas a avaliação final do modelo (implantável ou não implantável) é mantida; e ainda
Os filtros de avaliação de modelo ajustados GPT-4o, GPT-4o-mini e GPT-4 são definidos para limites predefinidos e não podem ser modificados pelos clientes; Eles não estão vinculados a nenhuma configuração de filtragem de conteúdo personalizada que você possa ter criado.
Avaliação dos dados
Antes do início do treinamento, seus dados são avaliados quanto a conteúdo potencialmente prejudicial (violência, sexual, ódio e justiça, automutilação – veja as definições de categoria aqui). Se for detetado conteúdo nocivo acima do nível de gravidade especificado, o seu trabalho de formação falhará e receberá uma mensagem a informá-lo das categorias de falha.
Mensagem de exemplo:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Seus dados de treinamento são avaliados automaticamente em seu trabalho de importação de dados como parte do fornecimento do recurso de ajuste fino.
Se o trabalho de ajuste fino falhar devido à deteção de conteúdo nocivo nos dados de treinamento, você não será cobrado.
Avaliação do modelo
Após a conclusão do treinamento, mas antes que o modelo ajustado esteja disponível para implantação, o modelo resultante é avaliado quanto a respostas potencialmente prejudiciais usando as métricas internas de risco e segurança do Azure. Usando a mesma abordagem de teste que usamos para os modelos básicos de linguagem grande, nossa capacidade de avaliação simula uma conversa com seu modelo ajustado para avaliar o potencial de saída de conteúdo nocivo, novamente usando categorias de conteúdo prejudicial especificadas (violência, sexual, ódio e justiça, automutilação).
Se um modelo gerar saída contendo conteúdo detetado como prejudicial acima de uma taxa aceitável, você será informado de que seu modelo não está disponível para implantação, com informações sobre as categorias específicas de danos detetados:
Mensagem de exemplo:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.

Tal como acontece com a avaliação de dados, o modelo é avaliado automaticamente dentro do seu trabalho de ajuste fino como parte do fornecimento da capacidade de ajuste fino. Somente a avaliação resultante (implantável ou não implantável) é registrada pelo serviço. Se a implantação do modelo ajustado falhar devido à deteção de conteúdo nocivo nas saídas do modelo, você não será cobrado pela execução do treinamento.
Implantar um modelo ajustado
Quando o trabalho de ajuste fino for bem-sucedido, você poderá implantar o modelo personalizado no painel Modelos . Você deve implantar seu modelo personalizado para disponibilizá-lo para uso com chamadas de conclusão.
Importante
Depois de implantar um modelo personalizado, se a qualquer momento a implantação permanecer inativa por mais de quinze (15) dias, a implantação será excluída. A implantação de um modelo personalizado estará inativa se o modelo tiver sido implantado há mais de quinze (15) dias e nenhuma conclusão ou chamada de conclusão de bate-papo tiver sido feita para ele durante um período contínuo de 15 dias.
A exclusão de uma implantação inativa não exclui nem afeta o modelo personalizado subjacente, e o modelo personalizado pode ser reimplantado a qualquer momento. Conforme descrito em Preços do Serviço OpenAI do Azure, cada modelo personalizado (ajustado) implantado incorre em um custo de hospedagem por hora, independentemente de serem feitas chamadas de conclusão ou de bate-papo para o modelo. Para saber mais sobre como planejar e gerenciar custos com o Azure OpenAI, consulte as orientações em Planejar o gerenciamento de custos para o Serviço OpenAI do Azure.
Nota
Apenas uma implantação é permitida para um modelo personalizado. Uma mensagem de erro será exibida se você selecionar um modelo personalizado já implantado.
Para implantar seu modelo personalizado, selecione o modelo personalizado a ser implantado e, em seguida, selecione Implantar modelo.

A caixa de diálogo Implantar modelo é aberta. Na caixa de diálogo, digite o nome da implantação e selecione Criar para iniciar a implantação do modelo personalizado.

Você pode monitorar o progresso de sua implantação no painel Implantações no portal do Azure AI Foundry.
Implantação entre regiões
O ajuste fino suporta a implantação de um modelo ajustado em uma região diferente daquela em que o modelo foi originalmente ajustado. Você também pode implantar em uma assinatura/região diferente.
As únicas limitações são que a nova região também deve oferecer suporte ao ajuste fino e, ao implantar a assinatura cruzada, a conta que gera o token de autorização para a implantação deve ter acesso às assinaturas de origem e de destino.
A implantação entre assinaturas/regiões pode ser realizada via Python ou REST.
Usar um modelo personalizado implantado
Depois que seu modelo personalizado for implantado, você poderá usá-lo como qualquer outro modelo implantado. Você pode usar os Playgrounds no portal do Azure AI Foundry para experimentar sua nova implantação. Você pode continuar a usar os mesmos parâmetros com seu modelo personalizado, como temperature e max_tokens, como pode fazer com outros modelos implantados. Para modelos e ajustes finos, babbage-002davinci-002 você usará o playground Completions e a API Completions. Para modelos ajustados, gpt-35-turbo-0613 você usará o playground de bate-papo e a API de conclusão de bate-papo.

Analise seu modelo personalizado
O Azure OpenAI anexa um arquivo de resultado chamado results.csv a cada trabalho de ajuste fino após sua conclusão. Você pode usar o arquivo de resultados para analisar o desempenho de treinamento e validação do seu modelo personalizado. A ID do arquivo de resultado é listada para cada modelo personalizado na coluna ID do arquivo de resultado no painel Modelos do portal do Azure AI Foundry. Você pode usar a ID do arquivo para identificar e baixar o arquivo de resultado do painel Arquivos de dados do portal do Azure AI Foundry.
O arquivo de resultado é um arquivo CSV que contém uma linha de cabeçalho e uma linha para cada etapa de treinamento executada pelo trabalho de ajuste fino. O arquivo de resultados contém as seguintes colunas:
| Nome da coluna | Description |
|---|---|
step |
O número da etapa de treinamento. Uma etapa de treinamento representa uma única passagem, para frente e para trás, em um lote de dados de treinamento. |
train_loss |
A perda para o lote de treinamento. |
train_mean_token_accuracy |
A porcentagem de tokens no lote de treinamento corretamente prevista pelo modelo. Por exemplo, se o tamanho do lote estiver definido como 3 e seus dados contiverem completações [[1, 2], [0, 5], [4, 2]], esse valor será definido como 0,83 (5 de 6) se o modelo previr [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
A perda para o lote de validação. |
validation_mean_token_accuracy |
A porcentagem de tokens no lote de validação corretamente prevista pelo modelo. Por exemplo, se o tamanho do lote estiver definido como 3 e seus dados contiverem completações [[1, 2], [0, 5], [4, 2]], esse valor será definido como 0,83 (5 de 6) se o modelo previr [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
A perda de validação calculada no final de cada época. Quando o treino corre bem, a perda deve diminuir. |
full_valid_mean_token_accuracy |
A precisão média válida do token calculada no final de cada época. Quando o treinamento está indo bem, a precisão do token deve aumentar. |
Você também pode exibir os dados em seu arquivo de results.csv como gráficos no portal do Azure AI Foundry. Selecione o link para seu modelo treinado e você verá três gráficos: perda, precisão média do token e precisão do token. Se você forneceu dados de validação, ambos os conjuntos de dados aparecerão no mesmo gráfico.
Procure que a sua perda diminua ao longo do tempo e que a sua precisão aumente. Se você vir uma divergência entre seus dados de treinamento e validação, isso pode indicar que você está sobreajustando. Tente treinar com menos épocas ou um multiplicador de taxa de aprendizagem menor.
Limpe suas implantações, modelos personalizados e arquivos de treinamento
Quando terminar de usar seu modelo personalizado, você poderá excluir a implantação e o modelo. Você também pode excluir os arquivos de treinamento e validação que carregou para o serviço, se necessário.
Excluir sua implantação de modelo
Importante
Depois de implantar um modelo personalizado, se a qualquer momento a implantação permanecer inativa por mais de quinze (15) dias, a implantação será excluída. A implantação de um modelo personalizado estará inativa se o modelo tiver sido implantado há mais de quinze (15) dias e nenhuma conclusão ou chamada de conclusão de bate-papo tiver sido feita para ele durante um período contínuo de 15 dias.
A exclusão de uma implantação inativa não exclui nem afeta o modelo personalizado subjacente, e o modelo personalizado pode ser reimplantado a qualquer momento. Conforme descrito em Preços do Serviço OpenAI do Azure, cada modelo personalizado (ajustado) implantado incorre em um custo de hospedagem por hora, independentemente de serem feitas chamadas de conclusão ou de bate-papo para o modelo. Para saber mais sobre como planejar e gerenciar custos com o Azure OpenAI, consulte as orientações em Planejar o gerenciamento de custos para o Serviço OpenAI do Azure.
Você pode excluir a implantação do seu modelo personalizado no painel Implantações no portal do Azure AI Foundry. Selecione a implantação a ser excluída e, em seguida, selecione Excluir para excluir a implantação.
Excluir seu modelo personalizado
Você pode excluir um modelo personalizado no painel Modelos no portal do Azure AI Foundry. Selecione o modelo personalizado a ser excluído na guia Modelos personalizados e, em seguida, selecione Excluir para excluir o modelo personalizado.
Nota
Não é possível excluir um modelo personalizado se ele tiver uma implantação existente. Você deve primeiro excluir sua implantação de modelo antes de poder excluir seu modelo personalizado.
Excluir seus arquivos de treinamento
Opcionalmente, você pode excluir arquivos de treinamento e validação que carregou para treinamento e arquivos de resultados gerados durante o treinamento no painel Dados de Gerenciamento>+ índices no portal do Azure AI Foundry. Selecione o arquivo a ser excluído e, em seguida, selecione Excluir para excluir o arquivo.
Ajuste fino contínuo
Depois de criar um modelo ajustado, você pode querer continuar a refiná-lo ao longo do tempo por meio de ajustes mais finos. O ajuste fino contínuo é o processo iterativo de selecionar um modelo já ajustado como modelo base e ajustá-lo ainda mais em novos conjuntos de exemplos de treinamento.
Para executar o ajuste fino em um modelo que você ajustou anteriormente, você usaria o mesmo processo descrito em criar um modelo personalizado, mas em vez de especificar o nome de um modelo base genérico, você especificaria seu modelo já ajustado. Um modelo personalizado e ajustado teria a aparência de gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7

Também recomendamos incluir o suffix parâmetro para facilitar a distinção entre diferentes iterações do seu modelo ajustado.
suffix usa uma cadeia de caracteres e é definido para identificar o modelo ajustado. Com a API OpenAI Python é suportada uma cadeia de até 18 caracteres que será adicionada ao seu nome de modelo ajustado.







Pré-requisitos
- Leia o guia de ajuste fino do Azure OpenAI.
- Uma subscrição do Azure. Crie um gratuitamente.
- Um recurso OpenAI do Azure. Para obter mais informações, consulte Criar um recurso e implantar um modelo com o Azure OpenAI.
- As seguintes bibliotecas Python:
os,json,requests,openai. - A biblioteca OpenAI Python deve ser pelo menos a versão 0.28.1.
- O ajuste fino do acesso requer o Cognitive Services OpenAI Contributor.
- Se você ainda não tiver acesso para exibir a cota e implantar modelos no portal do Azure AI Foundry, precisará de permissões adicionais.
Modelos
Os seguintes modelos suportam ajuste fino:
babbage-002davinci-002-
gpt-35-turbo(0613) -
gpt-35-turbo(1106) -
gpt-35-turbo(0125) -
gpt-4(0613)* -
gpt-4o(2024-08-06) -
gpt-4o-mini(2024-07-18)
* O ajuste fino para este modelo está atualmente em pré-visualização pública.
Ou você pode ajustar um modelo previamente ajustado, formatado como base-model.ft-{jobid}.
Consulte a página de modelos para verificar quais regiões atualmente oferecem suporte ao ajuste fino.
Revise o fluxo de trabalho para o SDK do Python
Reserve um momento para revisar o fluxo de trabalho de ajuste fino para usar o SDK do Python com o Azure OpenAI:
- Prepare seus dados de treinamento e validação.
- Selecione um modelo base.
- Carregue seus dados de treinamento.
- Treine o seu novo modelo personalizado.
- Verifique o estado do seu modelo personalizado.
- Implante seu modelo personalizado para uso.
- Use o seu modelo personalizado.
- Opcionalmente, analise seu modelo personalizado quanto ao desempenho e ajuste.
Prepare seus dados de treinamento e validação
Os dados de preparação e os conjuntos de dados de validação consistem em exemplos de entrada e saída de como pretende que o modelo seja executado.
Diferentes tipos de modelo exigem um formato diferente de dados de treinamento.
Os dados de treinamento e validação usados devem ser formatados como um documento JSONL (JSON Lines). Para gpt-35-turbo-0613 o ajuste fino, o conjunto de dados deve ser formatado no formato de conversação usado pela API de conclusão de bate-papo.
Se você quiser um passo a passo de ajuste gpt-35-turbo-0613 fino, consulte o tutorial de ajuste fino do Azure OpenAI
Exemplo de formato de ficheiro
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
Formato de arquivo de bate-papo multiturno
Vários turnos de uma conversa em uma única linha do seu arquivo de treinamento jsonl também são suportados. Para ignorar o ajuste fino em mensagens de assistente específicas, adicione o par de valores de chave opcional weight . Atualmente weight pode ser definido como 0 ou 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Conclusão do bate-papo com visão
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Além do formato JSONL, os arquivos de dados de treinamento e validação devem ser codificados em UTF-8 e incluir uma marca de ordem de bytes (BOM). O arquivo deve ter menos de 512 MB de tamanho.
Crie seus conjuntos de dados de treinamento e validação
Quanto mais exemplos de treinamento você tiver, melhor. Os trabalhos de ajuste fino não prosseguirão sem pelo menos 10 exemplos de treinamento, mas um número tão pequeno não é suficiente para influenciar visivelmente as respostas do modelo. É uma boa prática fornecer centenas, se não milhares, de exemplos de formação para serem bem sucedidos.
Em geral, dobrar o tamanho do conjunto de dados pode levar a um aumento linear na qualidade do modelo. Mas tenha em mente que exemplos de baixa qualidade podem afetar negativamente o desempenho. Se você treinar o modelo em uma grande quantidade de dados internos, sem primeiro remover o conjunto de dados apenas para os exemplos da mais alta qualidade, você pode acabar com um modelo com um desempenho muito pior do que o esperado.
Carregue seus dados de treinamento
A próxima etapa é escolher os dados de treinamento preparados existentes ou carregar novos dados de treinamento preparados para usar ao personalizar seu modelo. Depois de preparar os dados de treinamento, você pode carregar seus arquivos para o serviço. Há duas maneiras de carregar dados de treinamento:
Para arquivos de dados grandes, recomendamos que você importe de um repositório de Blob do Azure. Os ficheiros grandes podem tornar-se instáveis quando carregados através de formulários com várias partes porque os pedidos são atómicos e não podem ser repetidos ou retomados. Para obter mais informações sobre o armazenamento de Blob do Azure, consulte O que é o armazenamento de Blob do Azure?
Nota
Os arquivos de dados de treinamento devem ser formatados como arquivos JSONL, codificados em UTF-8 com uma marca de ordem de bytes (BOM). O arquivo deve ter menos de 512 MB de tamanho.
O exemplo Python a seguir carrega arquivos de treinamento e validação locais usando o SDK do Python e recupera as IDs de arquivo retornadas.
# Upload fine-tuning files
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-05-01-preview" # This API version or later is required to access seed/events/checkpoint capabilities
)
training_file_name = 'training_set.jsonl'
validation_file_name = 'validation_set.jsonl'
# Upload the training and validation dataset files to Azure OpenAI with the SDK.
training_response = client.files.create(
file=open(training_file_name, "rb"), purpose="fine-tune"
)
training_file_id = training_response.id
validation_response = client.files.create(
file=open(validation_file_name, "rb"), purpose="fine-tune"
)
validation_file_id = validation_response.id
print("Training file ID:", training_file_id)
print("Validation file ID:", validation_file_id)
Criar um modelo personalizado
Depois de carregar seus arquivos de treinamento e validação, você estará pronto para iniciar o trabalho de ajuste fino.
O código Python a seguir mostra um exemplo de como criar um novo trabalho de ajuste fino com o SDK do Python:
Neste exemplo, também estamos passando o parâmetro seed. A semente controla a reprodutibilidade do trabalho. Passar os mesmos parâmetros de semente e trabalho deve produzir os mesmos resultados, mas pode diferir em casos raros. Se uma semente não for especificada, uma será gerada para você.
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
seed = 105 # seed parameter controls reproducibility of the fine-tuning job. If no seed is specified one will be generated automatically.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
Você também pode passar parâmetros opcionais adicionais, como hiperparâmetros, para ter maior controle do processo de ajuste fino. Para o treinamento inicial, recomendamos usar os padrões automáticos que estão presentes sem especificar esses parâmetros.
Os hiperparâmetros suportados atualmente para ajuste fino são:
| Nome | Tipo | Descrição |
|---|---|---|
batch_size |
integer | O tamanho do lote a ser usado para treinamento. O tamanho do lote é o número de exemplos de treinamento usados para treinar um único passe para frente e para trás. Em geral, descobrimos que lotes maiores tendem a funcionar melhor para conjuntos de dados maiores. O valor padrão, bem como o valor máximo para essa propriedade são específicos para um modelo base. Um tamanho de lote maior significa que os parâmetros do modelo são atualizados com menos frequência, mas com menor variância. |
learning_rate_multiplier |
Número | O multiplicador da taxa de aprendizagem a utilizar na formação. A taxa de aprendizagem de ajuste fino é a taxa de aprendizagem original usada para pré-treinamento multiplicada por esse valor. Taxas de aprendizagem maiores tendem a ter um melhor desempenho com lotes maiores. Recomendamos experimentar valores no intervalo de 0,02 a 0,2 para ver o que produz os melhores resultados. Uma taxa de aprendizagem menor pode ser útil para evitar o sobreajuste. |
n_epochs |
integer | O número de épocas para treinar o modelo. Uma época refere-se a um ciclo completo através do conjunto de dados de treinamento. |
seed |
integer | A semente controla a reprodutibilidade do trabalho. Passar os mesmos parâmetros de semente e trabalho deve produzir os mesmos resultados, mas pode diferir em casos raros. Se uma semente não for especificada, uma será gerada para você. |
Para definir hiperparâmetros personalizados com a versão 1.x da API Python do OpenAI:
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01" # This API version or later is required to access fine-tuning for turbo/babbage-002/davinci-002
)
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-35-turbo-0613", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
hyperparameters={
"n_epochs":2
}
)
Verificar o status do trabalho de ajuste fino
response = client.fine_tuning.jobs.retrieve(job_id)
print("Job ID:", response.id)
print("Status:", response.status)
print(response.model_dump_json(indent=2))
Listar eventos de ajuste fino
Para examinar os eventos individuais de ajuste fino que foram gerados durante o treinamento:
Talvez seja necessário atualizar sua biblioteca de cliente OpenAI para a versão mais recente para pip install openai --upgrade executar este comando.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Pontos de verificação
Quando cada época de treinamento se completa, um ponto de verificação é gerado. Um ponto de verificação é uma versão totalmente funcional de um modelo que pode ser implantado e usado como modelo de destino para trabalhos de ajuste fino subsequentes. Os pontos de verificação podem ser particularmente úteis, pois podem fornecer um instantâneo do seu modelo antes que ocorra um sobreajuste. Quando um trabalho de ajuste fino for concluído, você terá as três versões mais recentes do modelo disponíveis para implantação. A época final será representada pelo seu modelo ajustado, as duas épocas anteriores estarão disponíveis como pontos de verificação.
Você pode executar o comando list checkpoints para recuperar a lista de pontos de verificação associados a um trabalho de ajuste fino individual:
Talvez seja necessário atualizar sua biblioteca de cliente OpenAI para a versão mais recente para pip install openai --upgrade executar este comando.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Avaliação de segurança GPT-4, GPT-4o, GPT-4o-mini fine-tuning - visualização pública
GPT-4o, GPT-4o-mini e GPT-4 são os nossos modelos mais avançados que podem ser ajustados às suas necessidades. Tal como acontece com os modelos OpenAI do Azure em geral, as capacidades avançadas dos modelos ajustados vêm com desafios de IA responsáveis acrescidos relacionados com conteúdo prejudicial, manipulação, comportamento semelhante ao humano, questões de privacidade e muito mais. Saiba mais sobre riscos, capacidades e limitações na Visão geral das práticas de IA responsável e na Nota de transparência. Para ajudar a mitigar os riscos associados a modelos avançados ajustados, implementamos etapas de avaliação adicionais para ajudar a detetar e prevenir conteúdo nocivo no treinamento e nos resultados de modelos ajustados. Essas etapas são baseadas na filtragem de conteúdo do Microsoft Responsible AI Standard e do Azure OpenAI Service.
- As avaliações são realizadas em espaços de trabalho dedicados, específicos do cliente e privados;
- Os pontos de extremidade de avaliação estão na mesma geografia que o recurso OpenAI do Azure;
- Os dados de treinamento não são armazenados em conexão com a realização de avaliações; apenas a avaliação final do modelo (implantável ou não implantável) é mantida; e ainda
Os filtros de avaliação de modelo ajustados GPT-4o, GPT-4o-mini e GPT-4 são definidos para limites predefinidos e não podem ser modificados pelos clientes; Eles não estão vinculados a nenhuma configuração de filtragem de conteúdo personalizada que você possa ter criado.
Avaliação dos dados
Antes do início do treinamento, seus dados são avaliados quanto a conteúdo potencialmente prejudicial (violência, sexual, ódio e justiça, automutilação – veja as definições de categoria aqui). Se for detetado conteúdo nocivo acima do nível de gravidade especificado, o seu trabalho de formação falhará e receberá uma mensagem a informá-lo das categorias de falha.
Mensagem de exemplo:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Seus dados de treinamento são avaliados automaticamente em seu trabalho de importação de dados como parte do fornecimento do recurso de ajuste fino.
Se o trabalho de ajuste fino falhar devido à deteção de conteúdo nocivo nos dados de treinamento, você não será cobrado.
Avaliação do modelo
Após a conclusão do treinamento, mas antes que o modelo ajustado esteja disponível para implantação, o modelo resultante é avaliado quanto a respostas potencialmente prejudiciais usando as métricas internas de risco e segurança do Azure. Usando a mesma abordagem de teste que usamos para os modelos básicos de linguagem grande, nossa capacidade de avaliação simula uma conversa com seu modelo ajustado para avaliar o potencial de saída de conteúdo nocivo, novamente usando categorias de conteúdo prejudicial especificadas (violência, sexual, ódio e justiça, automutilação).
Se um modelo gerar saída contendo conteúdo detetado como prejudicial acima de uma taxa aceitável, você será informado de que seu modelo não está disponível para implantação, com informações sobre as categorias específicas de danos detetados:
Mensagem de exemplo:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
Tal como acontece com a avaliação de dados, o modelo é avaliado automaticamente dentro do seu trabalho de ajuste fino como parte do fornecimento da capacidade de ajuste fino. Somente a avaliação resultante (implantável ou não implantável) é registrada pelo serviço. Se a implantação do modelo ajustado falhar devido à deteção de conteúdo nocivo nas saídas do modelo, você não será cobrado pela execução do treinamento.
Implantar um modelo ajustado
Quando o trabalho de ajuste fino é bem-sucedido, o valor da variável no corpo da fine_tuned_model resposta é definido como o nome do seu modelo personalizado. Seu modelo agora também está disponível para descoberta na lista Models API. No entanto, você não pode emitir chamadas de conclusão para seu modelo personalizado até que seu modelo personalizado seja implantado. Você deve implantar seu modelo personalizado para disponibilizá-lo para uso com chamadas de conclusão.
Importante
Depois de implantar um modelo personalizado, se a qualquer momento a implantação permanecer inativa por mais de quinze (15) dias, a implantação será excluída. A implantação de um modelo personalizado estará inativa se o modelo tiver sido implantado há mais de quinze (15) dias e nenhuma conclusão ou chamada de conclusão de bate-papo tiver sido feita para ele durante um período contínuo de 15 dias.
A exclusão de uma implantação inativa não exclui nem afeta o modelo personalizado subjacente, e o modelo personalizado pode ser reimplantado a qualquer momento. Conforme descrito em Preços do Serviço OpenAI do Azure, cada modelo personalizado (ajustado) implantado incorre em um custo de hospedagem por hora, independentemente de serem feitas chamadas de conclusão ou de bate-papo para o modelo. Para saber mais sobre como planejar e gerenciar custos com o Azure OpenAI, consulte as orientações em Planejar o gerenciamento de custos para o Serviço OpenAI do Azure.
Você também pode usar o Azure AI Foundry ou a CLI do Azure para implantar seu modelo personalizado.
Nota
Apenas uma implantação é permitida para um modelo personalizado. Ocorrerá um erro se você selecionar um modelo personalizado já implantado.
Ao contrário dos comandos anteriores do SDK, a implantação deve ser feita usando a API do plano de controle, que requer autorização separada, um caminho de API diferente e uma versão de API diferente.
| variável | Definição |
|---|---|
| token | Há várias maneiras de gerar um token de autorização. O método mais fácil para teste inicial é iniciar o Cloud Shell a partir do portal do Azure. Em seguida, execute o az account get-access-token. Você pode usar esse token como seu token de autorização temporária para testes de API. Recomendamos armazená-lo em uma nova variável de ambiente. |
| subscrição | A ID de assinatura para o recurso associado do Azure OpenAI. |
| resource_group | O nome do grupo de recursos para seu recurso do Azure OpenAI. |
| resource_name | O nome do recurso do Azure OpenAI. |
| model_deployment_name | O nome personalizado para sua nova implantação de modelo ajustado. Este é o nome que será referenciado no seu código ao fazer chamadas de conclusão de chat. |
| fine_tuned_model | Recupere esse valor dos resultados do trabalho de ajuste fino na etapa anterior. Vai parecer .gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83 Você precisará agregar esse valor ao deploy_data json. Como alternativa, você também pode implantar um ponto de verificação, passando o ID do ponto de verificação que aparecerá no formato ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<YOUR_SUBSCRIPTION_ID>"
resource_group = "<YOUR_RESOURCE_GROUP_NAME>"
resource_name = "<YOUR_AZURE_OPENAI_RESOURCE_NAME>"
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"fine_tuned_model">, #retrieve this value from the previous call, it will look like gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83
"version": "1"
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Implantação entre regiões
O ajuste fino suporta a implantação de um modelo ajustado em uma região diferente daquela em que o modelo foi originalmente ajustado. Você também pode implantar em uma assinatura/região diferente.
As únicas limitações são que a nova região também deve oferecer suporte ao ajuste fino e, ao implantar a assinatura cruzada, a conta que gera o token de autorização para a implantação deve ter acesso às assinaturas de origem e de destino.
Abaixo está um exemplo de implantação de um modelo que foi ajustado em uma assinatura/região para outra.
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<DESTINATION_SUBSCRIPTION_ID>"
resource_group = "<DESTINATION_RESOURCE_GROUP_NAME>"
resource_name = "<DESTINATION_AZURE_OPENAI_RESOURCE_NAME>"
source_subscription = "<SOURCE_SUBSCRIPTION_ID>"
source_resource_group = "<SOURCE_RESOURCE_GROUP>"
source_resource = "<SOURCE_RESOURCE>"
source = f'/subscriptions/{source_subscription}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_resource}'
model_deployment_name ="gpt-35-turbo-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2023-05-01"}
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"FINE_TUNED_MODEL_NAME">, # This value will look like gpt-35-turbo-0613.ft-0ab3f80e4f2242929258fff45b56a9ce
"version": "1",
"source": source
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Para implantar entre a mesma assinatura, mas regiões diferentes, você teria apenas que a assinatura e os grupos de recursos seriam idênticos para variáveis de origem e destino e apenas os nomes de recursos de origem e destino precisariam ser exclusivos.
Implantação entre locatários
A conta usada para gerar tokens de acesso com az account get-access-token --tenant deve ter permissões de Colaborador OpenAI dos Serviços Cognitivos para os recursos do Azure OpenAI de origem e destino. Você precisará gerar dois tokens diferentes, um para o locatário de origem e outro para o locatário de destino.
import requests
subscription = "DESTINATION-SUBSCRIPTION-ID"
resource_group = "DESTINATION-RESOURCE-GROUP"
resource_name = "DESTINATION-AZURE-OPENAI-RESOURCE-NAME"
model_deployment_name = "DESTINATION-MODEL-DEPLOYMENT-NAME"
fine_tuned_model = "gpt-4o-mini-2024-07-18.ft-f8838e7c6d4a4cbe882a002815758510" #source fine-tuned model id example id provided
source_subscription_id = "SOURCE-SUBSCRIPTION-ID"
source_resource_group = "SOURCE-RESOURCE-GROUP"
source_account = "SOURCE-AZURE-OPENAI-RESOURCE-NAME"
dest_token = "DESTINATION-ACCESS-TOKEN" # az account get-access-token --tenant DESTINATION-TENANT-ID
source_token = "SOURCE-ACCESS-TOKEN" # az account get-access-token --tenant SOURCE-TENANT-ID
headers = {
"Authorization": f"Bearer {dest_token}",
"x-ms-authorization-auxiliary": f"Bearer {source_token}",
"Content-Type": "application/json"
}
url = f"https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}?api-version=2024-10-01"
payload = {
"sku": {
"name": "standard",
"capacity": 1
},
"properties": {
"model": {
"format": "OpenAI",
"name": fine_tuned_model,
"version": "1",
"sourceAccount": f"/subscriptions/{source_subscription_id}/resourceGroups/{source_resource_group}/providers/Microsoft.CognitiveServices/accounts/{source_account}"
}
}
}
response = requests.put(url, headers=headers, json=payload)
# Check response
print(f"Status Code: {response.status_code}")
print(f"Response: {response.json()}")
Implantar um modelo com a CLI do Azure
O exemplo a seguir mostra como usar a CLI do Azure para implantar seu modelo personalizado. Com a CLI do Azure, você deve especificar um nome para a implantação do seu modelo personalizado. Para obter mais informações sobre como usar a CLI do Azure para implantar modelos personalizados, consulte az cognitiveservices account deployment.
Para executar esse comando da CLI do Azure em uma janela de console, você deve substituir os seguintes <espaços reservados> pelos valores correspondentes para seu modelo personalizado:
| Marcador de Posição | Value |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | O nome ou ID da sua assinatura do Azure. |
| <YOUR_RESOURCE_GROUP> | O nome do seu grupo de recursos do Azure. |
| <YOUR_RESOURCE_NAME> | O nome do recurso do Azure OpenAI. |
| <YOUR_DEPLOYMENT_NAME> | O nome que você deseja usar para sua implantação de modelo. |
| <YOUR_FINE_TUNED_MODEL_ID> | O nome do seu modelo personalizado. |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
Usar um modelo personalizado implantado
Depois que seu modelo personalizado for implantado, você poderá usá-lo como qualquer outro modelo implantado. Você pode usar os Playgrounds no Azure AI Foundry para experimentar sua nova implantação. Você pode continuar a usar os mesmos parâmetros com seu modelo personalizado, como temperature e max_tokens, como pode fazer com outros modelos implantados. Para modelos e ajustes finos, babbage-002davinci-002 você usará o playground Completions e a API Completions. Para modelos ajustados, gpt-35-turbo-0613 você usará o playground de bate-papo e a API de conclusão de bate-papo.
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.chat.completions.create(
model="gpt-35-turbo-ft", # model = "Custom deployment name you chose for your fine-tuning model"
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},
{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},
{"role": "user", "content": "Do other Azure AI services support this too?"}
]
)
print(response.choices[0].message.content)
Analise o seu modelo personalizado
O Azure OpenAI anexa um arquivo de resultado chamado results.csv a cada trabalho de ajuste fino após sua conclusão. Você pode usar o arquivo de resultados para analisar o desempenho de treinamento e validação do seu modelo personalizado. O ID do arquivo de resultado é listado para cada modelo personalizado, e você pode usar o SDK do Python para recuperar o ID do arquivo e baixar o arquivo de resultado para análise.
O exemplo Python a seguir recupera a ID do arquivo do primeiro arquivo de resultado anexado ao trabalho de ajuste fino para seu modelo personalizado e, em seguida, usa o SDK do Python para baixar o arquivo para seu diretório de trabalho para análise.
# Retrieve the file ID of the first result file from the fine-tuning job
# for the customized model.
response = client.fine_tuning.jobs.retrieve(job_id)
if response.status == 'succeeded':
result_file_id = response.result_files[0]
retrieve = client.files.retrieve(result_file_id)
# Download the result file.
print(f'Downloading result file: {result_file_id}')
with open(retrieve.filename, "wb") as file:
result = client.files.content(result_file_id).read()
file.write(result)
O arquivo de resultado é um arquivo CSV que contém uma linha de cabeçalho e uma linha para cada etapa de treinamento executada pelo trabalho de ajuste fino. O arquivo de resultados contém as seguintes colunas:
| Nome da coluna | Description |
|---|---|
step |
O número da etapa de treinamento. Uma etapa de treinamento representa uma única passagem, para frente e para trás, em um lote de dados de treinamento. |
train_loss |
A perda para o lote de treinamento. |
train_mean_token_accuracy |
A porcentagem de tokens no lote de treinamento corretamente prevista pelo modelo. Por exemplo, se o tamanho do lote estiver definido como 3 e seus dados contiverem completações [[1, 2], [0, 5], [4, 2]], esse valor será definido como 0,83 (5 de 6) se o modelo previr [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
A perda para o lote de validação. |
validation_mean_token_accuracy |
A porcentagem de tokens no lote de validação corretamente prevista pelo modelo. Por exemplo, se o tamanho do lote estiver definido como 3 e seus dados contiverem completações [[1, 2], [0, 5], [4, 2]], esse valor será definido como 0,83 (5 de 6) se o modelo previr [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
A perda de validação calculada no final de cada época. Quando o treino corre bem, a perda deve diminuir. |
full_valid_mean_token_accuracy |
A precisão média válida do token calculada no final de cada época. Quando o treinamento está indo bem, a precisão do token deve aumentar. |
Você também pode exibir os dados em seu arquivo de results.csv como gráficos no portal do Azure AI Foundry. Selecione o link para seu modelo treinado e você verá três gráficos: perda, precisão média do token e precisão do token. Se você forneceu dados de validação, ambos os conjuntos de dados aparecerão no mesmo gráfico.
Procure que a sua perda diminua ao longo do tempo e que a sua precisão aumente. Se você vir uma divergência entre seus dados de treinamento e validação, isso pode indicar que você está sobreajustando. Tente treinar com menos épocas ou um multiplicador de taxa de aprendizagem menor.
Limpe suas implantações, modelos personalizados e arquivos de treinamento
Quando terminar de usar seu modelo personalizado, você poderá excluir a implantação e o modelo. Você também pode excluir os arquivos de treinamento e validação que carregou para o serviço, se necessário.
Excluir sua implantação de modelo
Importante
Depois de implantar um modelo personalizado, se a qualquer momento a implantação permanecer inativa por mais de quinze (15) dias, a implantação será excluída. A implantação de um modelo personalizado estará inativa se o modelo tiver sido implantado há mais de quinze (15) dias e nenhuma conclusão ou chamada de conclusão de bate-papo tiver sido feita para ele durante um período contínuo de 15 dias.
A exclusão de uma implantação inativa não exclui nem afeta o modelo personalizado subjacente, e o modelo personalizado pode ser reimplantado a qualquer momento. Conforme descrito em Preços do Serviço OpenAI do Azure, cada modelo personalizado (ajustado) implantado incorre em um custo de hospedagem por hora, independentemente de serem feitas chamadas de conclusão ou de bate-papo para o modelo. Para saber mais sobre como planejar e gerenciar custos com o Azure OpenAI, consulte as orientações em Planejar o gerenciamento de custos para o Serviço OpenAI do Azure.
Você pode usar vários métodos para excluir a implantação para seu modelo personalizado:
Excluir seu modelo personalizado
Da mesma forma, você pode usar vários métodos para excluir seu modelo personalizado:
Nota
Não é possível excluir um modelo personalizado se ele tiver uma implantação existente. Você deve primeiro excluir a implantação do modelo antes de excluir o modelo personalizado.
Excluir seus arquivos de treinamento
Opcionalmente, você pode excluir arquivos de treinamento e validação que carregou para treinamento e arquivos de resultados gerados durante o treinamento de sua assinatura do Azure OpenAI. Você pode usar os seguintes métodos para excluir seus arquivos de treinamento, validação e resultados:
- Azure AI Foundry
- As APIs REST
- O SDK do Python
O exemplo Python a seguir usa o SDK do Python para excluir os arquivos de treinamento, validação e resultados do seu modelo personalizado:
print('Checking for existing uploaded files.')
results = []
# Get the complete list of uploaded files in our subscription.
files = openai.File.list().data
print(f'Found {len(files)} total uploaded files in the subscription.')
# Enumerate all uploaded files, extracting the file IDs for the
# files with file names that match your training dataset file and
# validation dataset file names.
for item in files:
if item["filename"] in [training_file_name, validation_file_name, result_file_name]:
results.append(item["id"])
print(f'Found {len(results)} already uploaded files that match our files')
# Enumerate the file IDs for our files and delete each file.
print(f'Deleting already uploaded files.')
for id in results:
openai.File.delete(sid = id)
Ajuste fino contínuo
Depois de criar um modelo ajustado, você pode querer continuar a refinar o modelo ao longo do tempo por meio de ajustes mais finos. O ajuste fino contínuo é o processo iterativo de selecionar um modelo já ajustado como modelo base e ajustá-lo ainda mais em novos conjuntos de exemplos de treinamento.
Para executar o ajuste fino em um modelo que você ajustou anteriormente, você usaria o mesmo processo descrito em criar um modelo personalizado, mas em vez de especificar o nome de um modelo base genérico, você especificaria o ID do modelo já ajustado. O ID do modelo ajustado tem a seguinte aparência gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-02-01"
)
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7" # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
Também recomendamos incluir o suffix parâmetro para facilitar a distinção entre diferentes iterações do seu modelo ajustado.
suffix usa uma cadeia de caracteres e é definido para identificar o modelo ajustado. Com a API OpenAI Python é suportada uma cadeia de até 18 caracteres que será adicionada ao seu nome de modelo ajustado.
Se você não tiver certeza da ID do seu modelo ajustado existente, essas informações podem ser encontradas na página Modelos do Azure AI Foundry, ou você pode gerar uma lista de modelos para um determinado recurso do Azure OpenAI usando a API REST.
Pré-requisitos
- Leia o guia de ajuste fino do Azure OpenAI.
- Uma subscrição do Azure. Crie um gratuitamente.
- Um recurso OpenAI do Azure. Para obter mais informações, consulte Criar um recurso e implantar um modelo com o Azure OpenAI.
- O ajuste fino do acesso requer o Cognitive Services OpenAI Contributor.
- Se você ainda não tiver acesso para exibir a cota e implantar modelos no portal do Azure AI Foundry, precisará de permissões adicionais.
Modelos
Os seguintes modelos suportam ajuste fino:
babbage-002davinci-002-
gpt-35-turbo(0613) -
gpt-35-turbo(1106) -
gpt-35-turbo(0125) -
gpt-4(0613)* -
gpt-4o(2024-08-06) -
gpt-4o-mini(2024-07-18)
* O ajuste fino para este modelo está atualmente em pré-visualização pública.
Ou você pode ajustar um modelo previamente ajustado, formatado como base-model.ft-{jobid}.
Consulte a página de modelos para verificar quais regiões atualmente oferecem suporte ao ajuste fino.
Revisar o fluxo de trabalho para a API REST
Reserve um momento para revisar o fluxo de trabalho de ajuste fino para usar o REST APIS e Python com o Azure OpenAI:
- Prepare seus dados de treinamento e validação.
- Selecione um modelo base.
- Carregue seus dados de treinamento.
- Treine o seu novo modelo personalizado.
- Verifique o estado do seu modelo personalizado.
- Implante seu modelo personalizado para uso.
- Use o seu modelo personalizado.
- Opcionalmente, analise seu modelo personalizado quanto ao desempenho e ajuste.
Prepare seus dados de treinamento e validação
Os dados de preparação e os conjuntos de dados de validação consistem em exemplos de entrada e saída de como pretende que o modelo seja executado.
Diferentes tipos de modelo exigem um formato diferente de dados de treinamento.
Os dados de treinamento e validação usados devem ser formatados como um documento JSONL (JSON Lines). Para gpt-35-turbo-0613 e outros modelos relacionados, o conjunto de dados de ajuste fino deve ser formatado no formato de conversação usado pela API de conclusão de bate-papo.
Se você quiser um passo a passo de ajuste gpt-35-turbo-0613 fino, consulte o tutorial de ajuste fino do Azure OpenAI.
Exemplo de formato de ficheiro
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
Formato de arquivo de bate-papo multiturno
Vários turnos de uma conversa em uma única linha do seu arquivo de treinamento jsonl também são suportados. Para ignorar o ajuste fino em mensagens de assistente específicas, adicione o par de valores de chave opcional weight . Atualmente weight pode ser definido como 0 ou 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Conclusão do bate-papo com visão
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Além do formato JSONL, os arquivos de dados de treinamento e validação devem ser codificados em UTF-8 e incluir uma marca de ordem de bytes (BOM). O arquivo deve ter menos de 512 MB de tamanho.
Crie seus conjuntos de dados de treinamento e validação
Quanto mais exemplos de treinamento você tiver, melhor. Os trabalhos de ajuste fino não prosseguirão sem pelo menos 10 exemplos de treinamento, mas um número tão pequeno não é suficiente para influenciar visivelmente as respostas do modelo. É uma boa prática fornecer centenas, se não milhares, de exemplos de formação para serem bem sucedidos.
Em geral, dobrar o tamanho do conjunto de dados pode levar a um aumento linear na qualidade do modelo. Mas tenha em mente que exemplos de baixa qualidade podem afetar negativamente o desempenho. Se você treinar o modelo em uma grande quantidade de dados internos sem primeiro remover o conjunto de dados apenas para os exemplos de mais alta qualidade, poderá acabar com um modelo com um desempenho muito pior do que o esperado.
Selecione o modelo base
O primeiro passo na criação de um modelo personalizado é escolher um modelo base. O painel Modelo base permite que você escolha um modelo base para usar em seu modelo personalizado. A sua escolha influencia tanto o desempenho como o custo do seu modelo.
Selecione o modelo base na lista suspensa Tipo de modelo base e, em seguida, selecione Avançar para continuar.
Você pode criar um modelo personalizado a partir de um dos seguintes modelos base disponíveis:
babbage-002davinci-002-
gpt-35-turbo(0613) -
gpt-35-turbo(1106) -
gpt-35-turbo(0125) -
gpt-4(0613) -
gpt-4o(2024-08-06) -
gpt-4o-mini(2023-07-18)
Ou você pode ajustar um modelo previamente ajustado, formatado como base-model.ft-{jobid}.
Para obter mais informações sobre nossos modelos básicos que podem ser ajustados, consulte Modelos.
Carregue seus dados de treinamento
A próxima etapa é escolher os dados de treinamento preparados existentes ou carregar novos dados de treinamento preparados para usar ao ajustar seu modelo. Depois de preparar os dados de treinamento, você pode carregar seus arquivos para o serviço. Há duas maneiras de carregar dados de treinamento:
Para arquivos de dados grandes, recomendamos que você importe de um repositório de Blob do Azure. Os ficheiros grandes podem tornar-se instáveis quando carregados através de formulários com várias partes porque os pedidos são atómicos e não podem ser repetidos ou retomados. Para obter mais informações sobre o armazenamento de Blob do Azure, consulte O que é o armazenamento de Blob do Azure?
Nota
Os arquivos de dados de treinamento devem ser formatados como arquivos JSONL, codificados em UTF-8 com uma marca de ordem de bytes (BOM). O arquivo deve ter menos de 512 MB de tamanho.
Carregar dados de formação
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\training_set.jsonl;type=application/json"
Carregar dados de validação
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\validation_set.jsonl;type=application/json"
Criar um modelo personalizado
Depois de carregar seus arquivos de treinamento e validação, você estará pronto para iniciar o trabalho de ajuste fino. O código a seguir mostra um exemplo de como criar um novo trabalho de ajuste fino com a API REST.
Neste exemplo, também estamos passando o parâmetro seed. A semente controla a reprodutibilidade do trabalho. Passar nos mesmos parâmetros de semente e trabalho deve produzir os mesmos resultados, mas pode diferir em casos raros. Se uma semente não for especificada, uma será gerada para você.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105
}'
Você também pode passar parâmetros opcionais adicionais, como hiperparâmetros , para ter maior controle do processo de ajuste fino. Para o treinamento inicial, recomendamos usar os padrões automáticos que estão presentes sem especificar esses parâmetros.
Os hiperparâmetros suportados atualmente para ajuste fino são:
| Nome | Tipo | Descrição |
|---|---|---|
batch_size |
integer | O tamanho do lote a ser usado para treinamento. O tamanho do lote é o número de exemplos de treinamento usados para treinar um único passe para frente e para trás. Em geral, descobrimos que lotes maiores tendem a funcionar melhor para conjuntos de dados maiores. O valor padrão, bem como o valor máximo para essa propriedade são específicos para um modelo base. Um tamanho de lote maior significa que os parâmetros do modelo são atualizados com menos frequência, mas com menor variância. |
learning_rate_multiplier |
Número | O multiplicador da taxa de aprendizagem a utilizar na formação. A taxa de aprendizagem de ajuste fino é a taxa de aprendizagem original usada para pré-treinamento multiplicada por esse valor. Taxas de aprendizagem maiores tendem a ter um melhor desempenho com lotes maiores. Recomendamos experimentar valores no intervalo de 0,02 a 0,2 para ver o que produz os melhores resultados. Uma taxa de aprendizagem menor pode ser útil para evitar o sobreajuste. |
n_epochs |
integer | O número de épocas para treinar o modelo. Uma época refere-se a um ciclo completo através do conjunto de dados de treinamento. |
seed |
integer | A semente controla a reprodutibilidade do trabalho. Passar os mesmos parâmetros de semente e trabalho deve produzir os mesmos resultados, mas pode diferir em casos raros. Se uma semente não for especificada, uma será gerada para você. |
Verifique o estado do seu modelo personalizado
Depois de iniciar um trabalho de ajuste fino, ele pode levar algum tempo para ser concluído. Seu trabalho pode estar na fila atrás de outros trabalhos no sistema. O treinamento do seu modelo pode levar minutos ou horas, dependendo do tamanho do modelo e do conjunto de dados. O exemplo a seguir usa a API REST para verificar o status do seu trabalho de ajuste fino. O exemplo recupera informações sobre seu trabalho usando a ID do trabalho retornada do exemplo anterior:
curl -X GET $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<YOUR-JOB-ID>?api-version=2024-05-01-preview \
-H "api-key: $AZURE_OPENAI_API_KEY"
Listar eventos de ajuste fino
Para examinar os eventos individuais de ajuste fino que foram gerados durante o treinamento:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/events?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Pontos de verificação
Quando cada época de treinamento se completa, um ponto de verificação é gerado. Um ponto de verificação é uma versão totalmente funcional de um modelo que pode ser implantado e usado como modelo de destino para trabalhos de ajuste fino subsequentes. Os pontos de verificação podem ser particularmente úteis, pois podem fornecer um instantâneo do seu modelo antes que ocorra um sobreajuste. Quando um trabalho de ajuste fino for concluído, você terá as três versões mais recentes do modelo disponíveis para implantação. A época final será representada pelo seu modelo ajustado, as duas épocas anteriores estarão disponíveis como pontos de verificação.
Você pode executar o comando list checkpoints para recuperar a lista de pontos de verificação associados a um trabalho de ajuste fino individual:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/checkpoints?api-version=2024-05-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Avaliação de segurança GPT-4, GPT-4o, GPT-4o-mini fine-tuning - visualização pública
GPT-4o, GPT-4o-mini e GPT-4 são os nossos modelos mais avançados que podem ser ajustados às suas necessidades. Tal como acontece com os modelos OpenAI do Azure em geral, as capacidades avançadas dos modelos ajustados vêm com desafios de IA responsáveis acrescidos relacionados com conteúdo prejudicial, manipulação, comportamento semelhante ao humano, questões de privacidade e muito mais. Saiba mais sobre riscos, capacidades e limitações na Visão geral das práticas de IA responsável e na Nota de transparência. Para ajudar a mitigar os riscos associados a modelos avançados ajustados, implementamos etapas de avaliação adicionais para ajudar a detetar e prevenir conteúdo nocivo no treinamento e nos resultados de modelos ajustados. Essas etapas são baseadas na filtragem de conteúdo do Microsoft Responsible AI Standard e do Azure OpenAI Service.
- As avaliações são realizadas em espaços de trabalho dedicados, específicos do cliente e privados;
- Os pontos de extremidade de avaliação estão na mesma geografia que o recurso OpenAI do Azure;
- Os dados de treinamento não são armazenados em conexão com a realização de avaliações; apenas a avaliação final do modelo (implantável ou não implantável) é mantida; e ainda
Os filtros de avaliação de modelo ajustados GPT-4o, GPT-4o-mini e GPT-4 são definidos para limites predefinidos e não podem ser modificados pelos clientes; Eles não estão vinculados a nenhuma configuração de filtragem de conteúdo personalizada que você possa ter criado.
Avaliação dos dados
Antes do início do treinamento, seus dados são avaliados quanto a conteúdo potencialmente prejudicial (violência, sexual, ódio e justiça, automutilação – veja as definições de categoria aqui). Se for detetado conteúdo nocivo acima do nível de gravidade especificado, o seu trabalho de formação falhará e receberá uma mensagem a informá-lo das categorias de falha.
Mensagem de exemplo:
The provided training data failed RAI checks for harm types: [hate_fairness, self_harm, violence]. Please fix the data and try again.
Seus dados de treinamento são avaliados automaticamente em seu trabalho de importação de dados como parte do fornecimento do recurso de ajuste fino.
Se o trabalho de ajuste fino falhar devido à deteção de conteúdo nocivo nos dados de treinamento, você não será cobrado.
Avaliação do modelo
Após a conclusão do treinamento, mas antes que o modelo ajustado esteja disponível para implantação, o modelo resultante é avaliado quanto a respostas potencialmente prejudiciais usando as métricas internas de risco e segurança do Azure. Usando a mesma abordagem de teste que usamos para os modelos básicos de linguagem grande, nossa capacidade de avaliação simula uma conversa com seu modelo ajustado para avaliar o potencial de saída de conteúdo nocivo, novamente usando categorias de conteúdo prejudicial especificadas (violência, sexual, ódio e justiça, automutilação).
Se um modelo gerar saída contendo conteúdo detetado como prejudicial acima de uma taxa aceitável, você será informado de que seu modelo não está disponível para implantação, com informações sobre as categorias específicas de danos detetados:
Mensagem de exemplo:
This model is unable to be deployed. Model evaluation identified that this fine tuned model scores above acceptable thresholds for [Violence, Self Harm]. Please review your training data set and resubmit the job.
Tal como acontece com a avaliação de dados, o modelo é avaliado automaticamente dentro do seu trabalho de ajuste fino como parte do fornecimento da capacidade de ajuste fino. Somente a avaliação resultante (implantável ou não implantável) é registrada pelo serviço. Se a implantação do modelo ajustado falhar devido à deteção de conteúdo nocivo nas saídas do modelo, você não será cobrado pela execução do treinamento.
Implantar um modelo ajustado
Importante
Depois de implantar um modelo personalizado, se a qualquer momento a implantação permanecer inativa por mais de quinze (15) dias, a implantação será excluída. A implantação de um modelo personalizado estará inativa se o modelo tiver sido implantado há mais de quinze (15) dias e nenhuma conclusão ou chamada de conclusão de bate-papo tiver sido feita para ele durante um período contínuo de 15 dias.
A exclusão de uma implantação inativa não exclui nem afeta o modelo personalizado subjacente, e o modelo personalizado pode ser reimplantado a qualquer momento. Conforme descrito em Preços do Serviço OpenAI do Azure, cada modelo personalizado (ajustado) implantado incorre em um custo de hospedagem por hora, independentemente de serem feitas chamadas de conclusão ou de bate-papo para o modelo. Para saber mais sobre como planejar e gerenciar custos com o Azure OpenAI, consulte as orientações em Planejar o gerenciamento de custos para o Serviço OpenAI do Azure.
O exemplo Python a seguir mostra como usar a API REST para criar uma implantação de modelo para seu modelo personalizado. A API REST gera um nome para a implantação do seu modelo personalizado.
| variável | Definição |
|---|---|
| token | Há várias maneiras de gerar um token de autorização. O método mais fácil para teste inicial é iniciar o Cloud Shell a partir do portal do Azure. Em seguida, execute o az account get-access-token. Você pode usar esse token como seu token de autorização temporária para testes de API. Recomendamos armazená-lo em uma nova variável de ambiente. |
| subscrição | A ID de assinatura para o recurso associado do Azure OpenAI. |
| resource_group | O nome do grupo de recursos para seu recurso do Azure OpenAI. |
| resource_name | O nome do recurso do Azure OpenAI. |
| model_deployment_name | O nome personalizado para sua nova implantação de modelo ajustado. Este é o nome que será referenciado no seu código ao fazer chamadas de conclusão de chat. |
| fine_tuned_model | Recupere esse valor dos resultados do trabalho de ajuste fino na etapa anterior. Vai parecer .gpt-35-turbo-0613.ft-b044a9d3cf9c4228b5d393567f693b83 Você precisará agregar esse valor ao deploy_data json. Como alternativa, você também pode implantar um ponto de verificação, passando o ID do ponto de verificação que aparecerá no formato ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
curl -X POST "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1"
}
}
}'
Implantação entre regiões
O ajuste fino suporta a implantação de um modelo ajustado em uma região diferente daquela em que o modelo foi originalmente ajustado. Você também pode implantar em uma assinatura/região diferente.
As únicas limitações são que a nova região também deve oferecer suporte ao ajuste fino e, ao implantar a assinatura cruzada, a conta que gera o token de autorização para a implantação deve ter acesso às assinaturas de origem e de destino.
Abaixo está um exemplo de implantação de um modelo que foi ajustado em uma assinatura/região para outra.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2023-05-01" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"source": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
Para implantar entre a mesma assinatura, mas regiões diferentes, você teria apenas que a assinatura e os grupos de recursos seriam idênticos para as variáveis de origem e destino e apenas os nomes de recursos de origem e destino precisariam ser exclusivos.
Implantação entre locatários
A conta usada para gerar tokens de acesso com az account get-access-token --tenant deve ter permissões de Colaborador OpenAI dos Serviços Cognitivos para os recursos do Azure OpenAI de origem e destino. Você precisará gerar dois tokens diferentes, um para o locatário de origem e outro para o locatário de destino.
curl -X PUT "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>?api-version=2024-10-01" \
-H "Authorization: Bearer <DESTINATION TOKEN>" \
-H "x-ms-authorization-auxiliary: Bearer <SOURCE TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1",
"sourceAccount": "/subscriptions/{sourceSubscriptionID}/resourceGroups/{sourceResourceGroupName}/providers/Microsoft.CognitiveServices/accounts/{sourceAccount}"
}
}
}'
Implantar um modelo com a CLI do Azure
O exemplo a seguir mostra como usar a CLI do Azure para implantar seu modelo personalizado. Com a CLI do Azure, você deve especificar um nome para a implantação do seu modelo personalizado. Para obter mais informações sobre como usar a CLI do Azure para implantar modelos personalizados, consulte az cognitiveservices account deployment.
Para executar esse comando da CLI do Azure em uma janela de console, você deve substituir os seguintes <espaços reservados> pelos valores correspondentes para seu modelo personalizado:
| Marcador de Posição | Value |
|---|---|
| <YOUR_AZURE_SUBSCRIPTION> | O nome ou ID da sua assinatura do Azure. |
| <YOUR_RESOURCE_GROUP> | O nome do seu grupo de recursos do Azure. |
| <YOUR_RESOURCE_NAME> | O nome do recurso do Azure OpenAI. |
| <YOUR_DEPLOYMENT_NAME> | O nome que você deseja usar para sua implantação de modelo. |
| <YOUR_FINE_TUNED_MODEL_ID> | O nome do seu modelo personalizado. |
az cognitiveservices account deployment create
--resource-group <YOUR_RESOURCE_GROUP>
--name <YOUR_RESOURCE_NAME>
--deployment-name <YOUR_DEPLOYMENT_NAME>
--model-name <YOUR_FINE_TUNED_MODEL_ID>
--model-version "1"
--model-format OpenAI
--sku-capacity "1"
--sku-name "Standard"
Usar um modelo personalizado implantado
Depois que seu modelo personalizado for implantado, você poderá usá-lo como qualquer outro modelo implantado. Você pode usar os Playgrounds no Azure AI Foundry para experimentar sua nova implantação. Você pode continuar a usar os mesmos parâmetros com seu modelo personalizado, como temperature e max_tokens, como pode fazer com outros modelos implantados. Para modelos e ajustes finos babbage-002davinci-002 , você usará o playground Completions e a API Completions. Para modelos ajustados gpt-35-turbo-0613 , você usará o playground de bate-papo e a API de conclusão de bate-papo.
curl $AZURE_OPENAI_ENDPOINT/openai/deployments/<deployment_name>/chat/completions?api-version=2023-05-15 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{"messages":[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Does Azure OpenAI support customer managed keys?"},{"role": "assistant", "content": "Yes, customer managed keys are supported by Azure OpenAI."},{"role": "user", "content": "Do other Azure AI services support this too?"}]}'
Analise o seu modelo personalizado
O Azure OpenAI anexa um arquivo de resultado chamado results.csv a cada trabalho de ajuste fino após sua conclusão. Você pode usar o arquivo de resultados para analisar o desempenho de treinamento e validação do seu modelo personalizado. O ID do arquivo de resultado é listado para cada modelo personalizado e você pode usar a API REST para recuperar o ID do arquivo e baixar o arquivo de resultado para análise.
O exemplo Python a seguir usa a API REST para recuperar a ID do arquivo do primeiro arquivo de resultado anexado ao trabalho de ajuste fino para seu modelo personalizado e, em seguida, baixa o arquivo para seu diretório de trabalho para análise.
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<JOB_ID>?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY")
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/files/<RESULT_FILE_ID>/content?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY" > <RESULT_FILENAME>
O arquivo de resultado é um arquivo CSV que contém uma linha de cabeçalho e uma linha para cada etapa de treinamento executada pelo trabalho de ajuste fino. O arquivo de resultados contém as seguintes colunas:
| Nome da coluna | Description |
|---|---|
step |
O número da etapa de treinamento. Uma etapa de treinamento representa uma única passagem, para frente e para trás, em um lote de dados de treinamento. |
train_loss |
A perda para o lote de treinamento. |
train_mean_token_accuracy |
A porcentagem de tokens no lote de treinamento corretamente prevista pelo modelo. Por exemplo, se o tamanho do lote estiver definido como 3 e seus dados contiverem completações [[1, 2], [0, 5], [4, 2]], esse valor será definido como 0,83 (5 de 6) se o modelo previr [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
A perda para o lote de validação. |
validation_mean_token_accuracy |
A porcentagem de tokens no lote de validação corretamente prevista pelo modelo. Por exemplo, se o tamanho do lote estiver definido como 3 e seus dados contiverem completações [[1, 2], [0, 5], [4, 2]], esse valor será definido como 0,83 (5 de 6) se o modelo previr [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
A perda de validação calculada no final de cada época. Quando o treino corre bem, a perda deve diminuir. |
full_valid_mean_token_accuracy |
A precisão média válida do token calculada no final de cada época. Quando o treinamento está indo bem, a precisão do token deve aumentar. |
Você também pode exibir os dados em seu arquivo de results.csv como gráficos no portal do Azure AI Foundry. Selecione o link para seu modelo treinado e você verá três gráficos: perda, precisão média do token e precisão do token. Se você forneceu dados de validação, ambos os conjuntos de dados aparecerão no mesmo gráfico.
Procure que a sua perda diminua ao longo do tempo e que a sua precisão aumente. Se você vir uma divergência entre seus dados de treinamento e validação, isso pode indicar que você está sobreajustando. Tente treinar com menos épocas ou um multiplicador de taxa de aprendizagem menor.
Limpe suas implantações, modelos personalizados e arquivos de treinamento
Quando terminar de usar seu modelo personalizado, você poderá excluir a implantação e o modelo. Você também pode excluir os arquivos de treinamento e validação que carregou para o serviço, se necessário.
Excluir sua implantação de modelo
Você pode usar vários métodos para excluir a implantação para seu modelo personalizado:
Excluir seu modelo personalizado
Da mesma forma, você pode usar vários métodos para excluir seu modelo personalizado:
Nota
Não é possível excluir um modelo personalizado se ele tiver uma implantação existente. Você deve primeiro excluir a implantação do modelo antes de excluir o modelo personalizado.
Excluir seus arquivos de treinamento
Opcionalmente, você pode excluir arquivos de treinamento e validação que carregou para treinamento e arquivos de resultados gerados durante o treinamento de sua assinatura do Azure OpenAI. Você pode usar os seguintes métodos para excluir seus arquivos de treinamento, validação e resultados:
Ajuste fino contínuo
Depois de criar um modelo ajustado, convém continuar a refiná-lo ao longo do tempo por meio de ajustes mais finos. O ajuste fino contínuo é o processo iterativo de selecionar um modelo já ajustado como modelo base e ajustá-lo ainda mais em novos conjuntos de exemplos de treinamento.
Para executar o ajuste fino em um modelo que você ajustou anteriormente, você usaria o mesmo processo descrito em Criar um modelo personalizado, mas em vez de especificar o nome de um modelo base genérico, você especificaria a ID do modelo já ajustado. O ID do modelo ajustado tem a seguinte aparência gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2023-12-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-35-turbo-0613.ft-5fd1918ee65d4cd38a5dcf6835066ed7",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"suffix": "<additional text used to help identify fine-tuned models>"
}'
Também recomendamos incluir o suffix parâmetro para facilitar a distinção entre diferentes iterações do seu modelo ajustado.
suffix usa uma cadeia de caracteres e é definido para identificar o modelo ajustado. O sufixo pode conter até 40 caracteres (a-z, A-Z, 0-9,- e _) que serão adicionados ao seu nome de modelo ajustado.
Se você não tiver certeza da ID do seu modelo ajustado, essas informações podem ser encontradas na página Modelos do Azure AI Foundry ou você pode gerar uma lista de modelos para um determinado recurso do Azure OpenAI usando a API REST.
Padrão Global (visualização)
O ajuste fino do Azure OpenAI dá suporte a implantações padrão globais no Leste dos EUA2, Centro-Norte dos EUA e Suécia Central para:
gpt-4o-mini-2024-07-18-
gpt-4o-2024-08-06(Novas implantações não estão disponíveis até janeiro de 2025)
As implantações ajustadas padrão global oferecem economia de custos, mas pesos de modelo personalizados podem ser temporariamente armazenados fora da geografia do seu recurso do Azure OpenAI.

Atualmente, as implantações de ajuste fino do Padrão Global não oferecem suporte a resultados estruturados e de visão.
Ajuste fino da visão
O ajuste fino também é possível com imagens em seus arquivos JSONL. Assim como você pode enviar uma ou várias entradas de imagem para finalizações de bate-papo, você pode incluir esses mesmos tipos de mensagem em seus dados de treinamento. As imagens podem ser fornecidas como URLs acessíveis publicamente ou URIs de dados contendo imagens codificadas base64.
Requisitos do conjunto de dados de imagem
- Seu arquivo de treinamento pode conter um máximo de 50.000 exemplos que contêm imagens (não incluindo exemplos de texto).
- Cada exemplo pode ter no máximo 64 imagens.
- Cada imagem pode ter, no máximo, 10 MB.
Formato
As imagens devem ser:
- JPEG
- PNG
- WEBP
As imagens devem estar no modo de imagem RGB ou RGBA.
Não é possível incluir imagens como saída de mensagens com a função de assistente.
Política de moderação de conteúdo
Analisamos as suas imagens antes da formação para garantir que cumprem a nossa Nota de Transparência da política de utilização. Isso pode introduzir latência na validação de arquivos antes do início do ajuste fino.
As imagens que contenham o seguinte serão excluídas do seu conjunto de dados e não serão utilizadas para formação:
- Pessoas
- Faces
- CAPTCHAs
Importante
Para o processo de triagem facial de ajuste fino da visão: Rastreamos rostos/pessoas para pular essas imagens do treinamento do modelo. A capacidade de triagem aproveita a deteção de rosto SEM identificação facial, o que significa que não criamos modelos faciais ou medimos geometria facial específica, e a tecnologia usada para rastrear rostos é incapaz de identificar exclusivamente os indivíduos. Para saber mais sobre dados e Privacidade para rosto, consulte - Dados e privacidade para Face - Serviços de IA do Azure | Microsoft Learn.
Cache de prompt
O ajuste fino do Azure OpenAI dá suporte ao cache de prompt com modelos selecionados. O cache de prompt permite reduzir a latência geral da solicitação e o custo para prompts mais longos que têm conteúdo idêntico no início do prompt. Para saber mais sobre o cache de prompts, consulte Introdução ao cache de prompts.
Otimização de preferência direta (DPO) (visualização)
A otimização direta de preferências (DPO) é uma técnica de alinhamento para modelos de linguagem grande, usada para ajustar os pesos dos modelos com base nas preferências humanas. Difere da aprendizagem por reforço a partir do feedback humano (RLHF) na medida em que não requer o ajuste de um modelo de recompensa e usa preferências de dados binários mais simples para o treinamento. É computacionalmente mais leve e mais rápido do que o RLHF, sendo igualmente eficaz no alinhamento.
Por que o DPO é útil?
O DPO é especialmente útil em cenários onde não há uma resposta correta clara, e elementos subjetivos como tom, estilo ou preferências de conteúdo específicas são importantes. Essa abordagem também permite que o modelo aprenda com exemplos positivos (o que é considerado correto ou ideal) e com exemplos negativos (o que é menos desejado ou incorreto).
Acredita-se que o DPO seja uma técnica que tornará mais fácil para os clientes gerar conjuntos de dados de treinamento de alta qualidade. Embora muitos clientes tenham dificuldade em gerar conjuntos de dados grandes suficientes para ajuste fino supervisionado, eles geralmente têm dados de preferência já coletados com base em logs de usuários, testes A/B ou esforços menores de anotação manual.
Formato do conjunto de dados de otimização de preferência direta
Os arquivos de otimização de preferência direta têm um formato diferente do ajuste fino supervisionado. Os clientes fornecem uma "conversa" contendo a mensagem do sistema e a mensagem inicial do usuário e, em seguida, "conclusão" com dados de preferência emparelhados. Os usuários só podem fornecer duas completações.
Três campos de nível superior: input, preferred_output e non_preferred_output
- Cada elemento do preferred_output/non_preferred_output deve conter pelo menos uma mensagem de assistente
- Cada elemento do preferred_output/non_preferred_output só pode ter funções em (assistente, ferramenta)
{
"input": {
"messages": {"role": "system", "content": ...},
"tools": [...],
"parallel_tool_calls": true
},
"preferred_output": [{"role": "assistant", "content": ...}],
"non_preferred_output": [{"role": "assistant", "content": ...}]
}
Os conjuntos de dados de treinamento devem estar no jsonl formato:
{{"input": {"messages": [{"role": "system", "content": "You are a chatbot assistant. Given a user question with multiple choice answers, provide the correct answer."}, {"role": "user", "content": "Question: Janette conducts an investigation to see which foods make her feel more fatigued. She eats one of four different foods each day at the same time for four days and then records how she feels. She asks her friend Carmen to do the same investigation to see if she gets similar results. Which would make the investigation most difficult to replicate? Answer choices: A: measuring the amount of fatigue, B: making sure the same foods are eaten, C: recording observations in the same chart, D: making sure the foods are at the same temperature"}]}, "preferred_output": [{"role": "assistant", "content": "A: Measuring The Amount Of Fatigue"}], "non_preferred_output": [{"role": "assistant", "content": "D: making sure the foods are at the same temperature"}]}
}
Suporte ao modelo de otimização de preferência direta
-
gpt-4o-2024-08-06suporta otimização de preferência direta em suas respetivas regiões de ajuste fino. A disponibilidade da região mais recente é atualizada na página de modelos
Os usuários podem usar o ajuste fino de preferência com modelos básicos, bem como modelos que já foram ajustados usando ajuste fino supervisionado, desde que sejam de um modelo/versão suportado.
Como usar o ajuste fino da otimização direta de preferências?
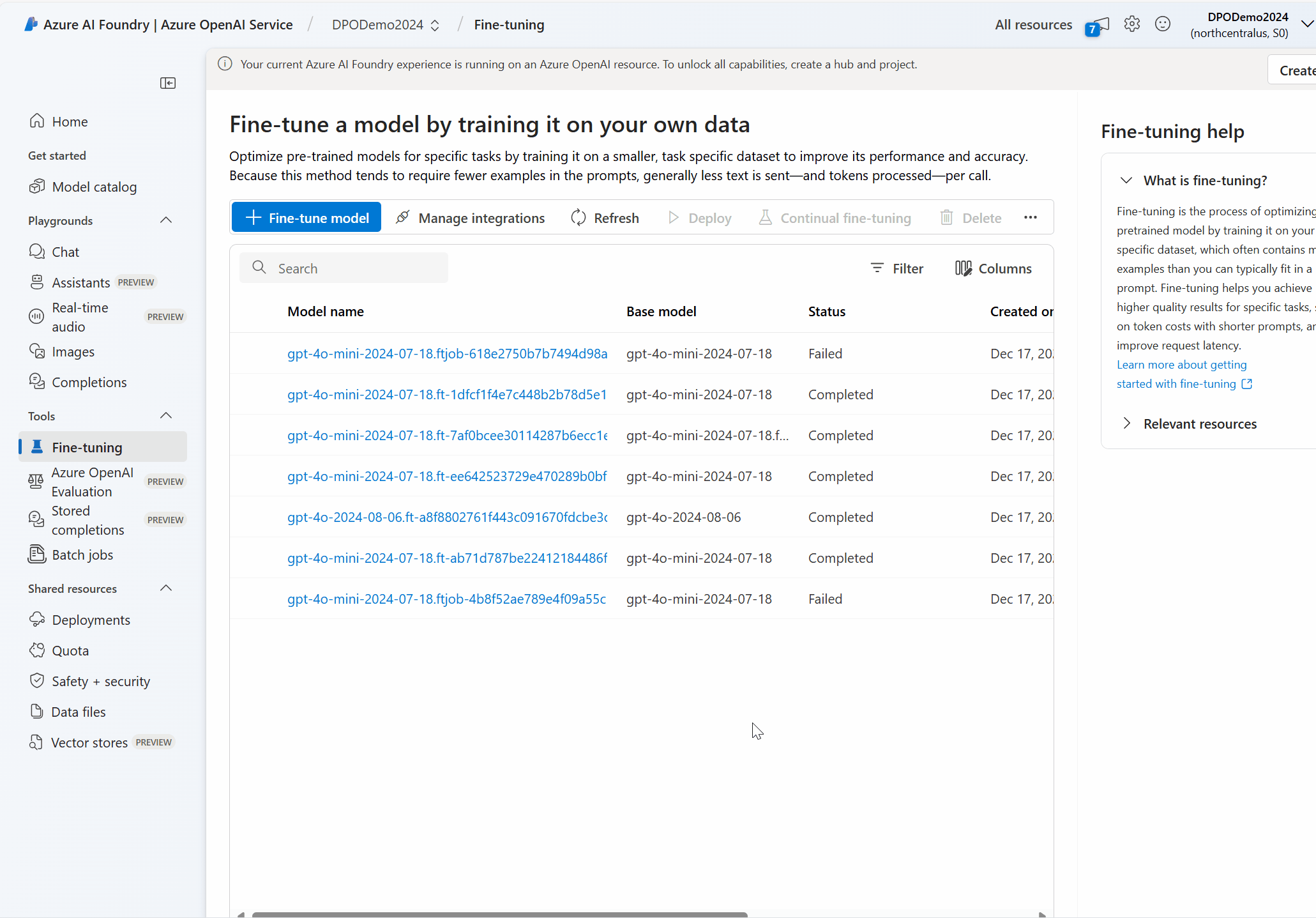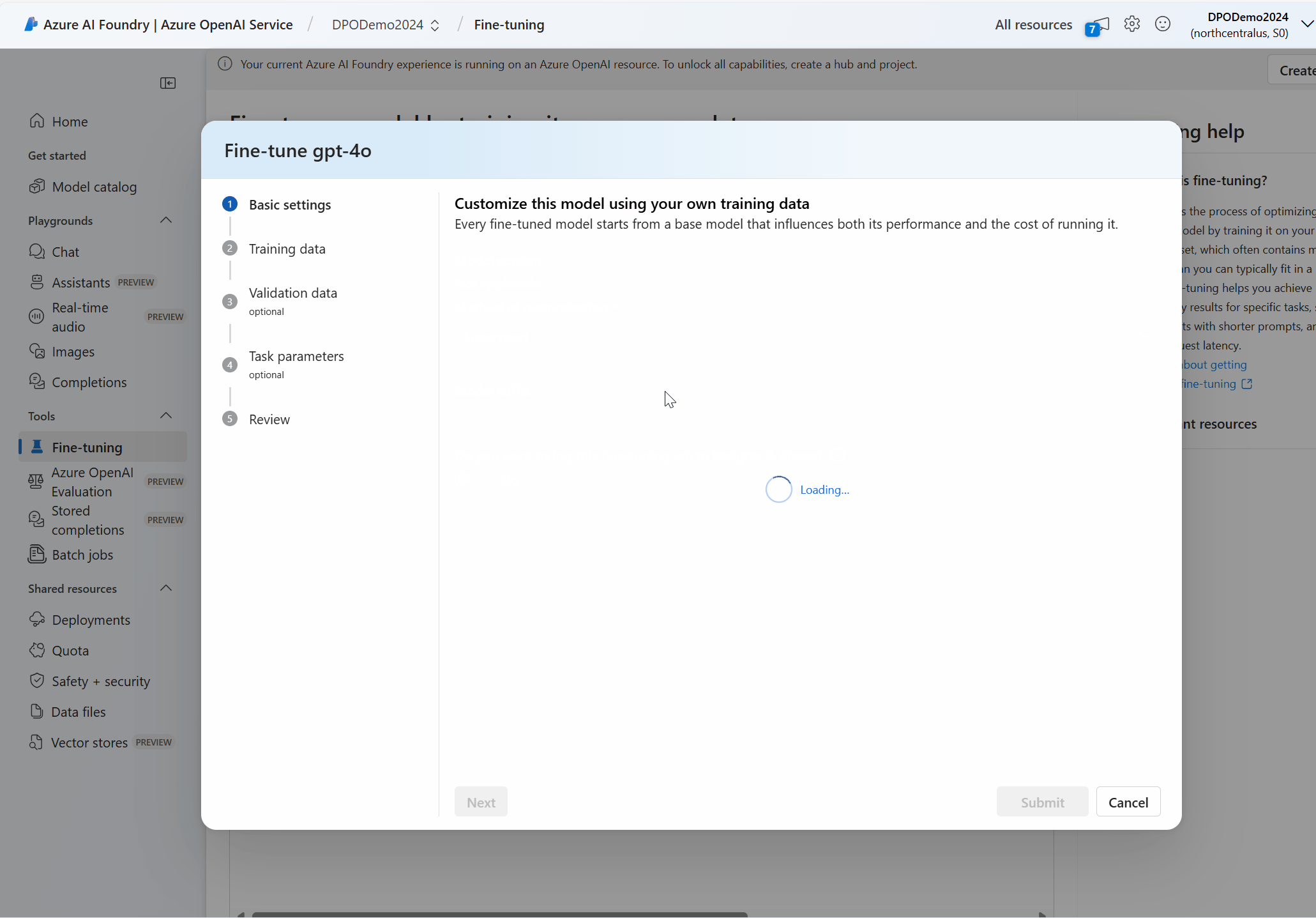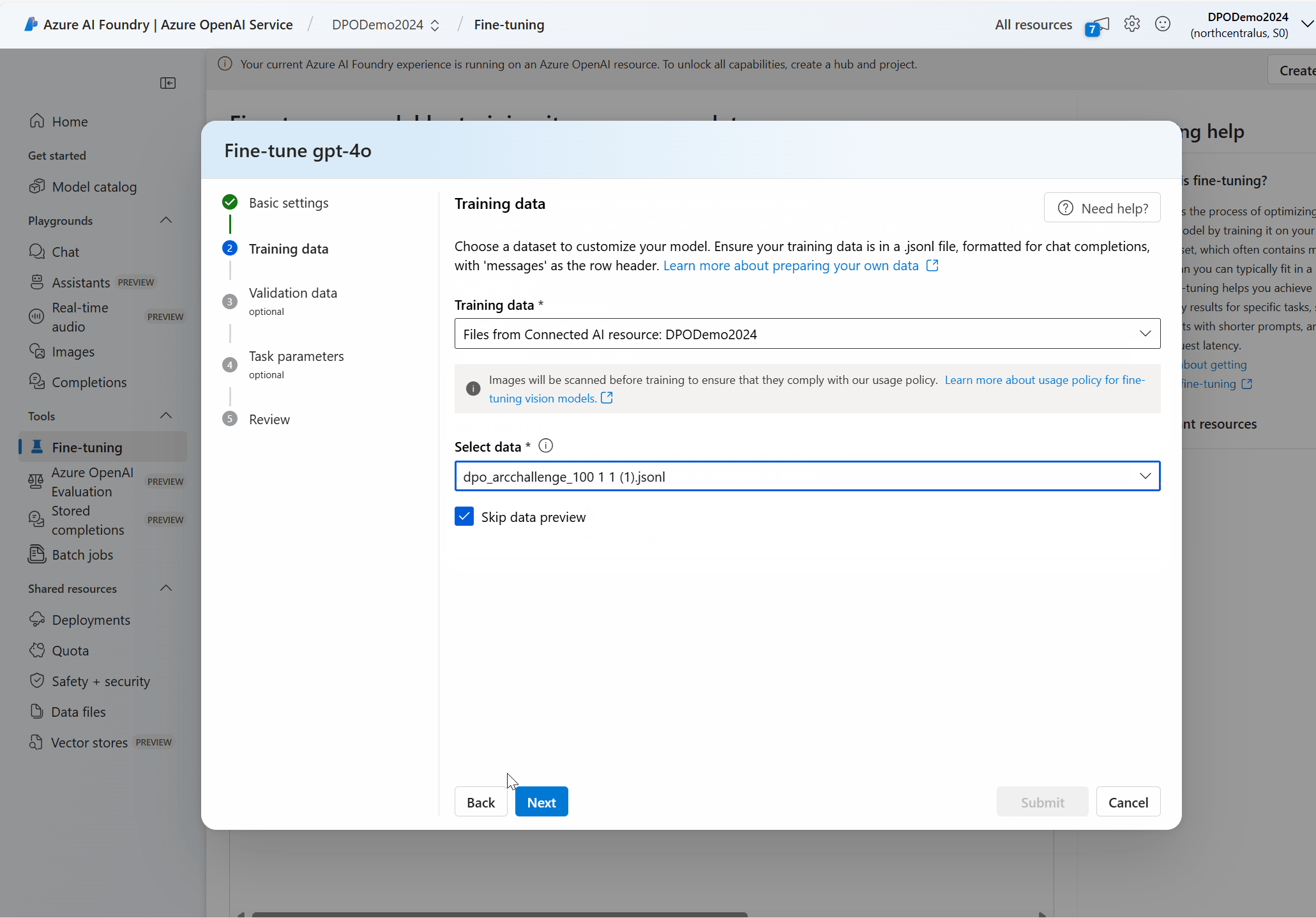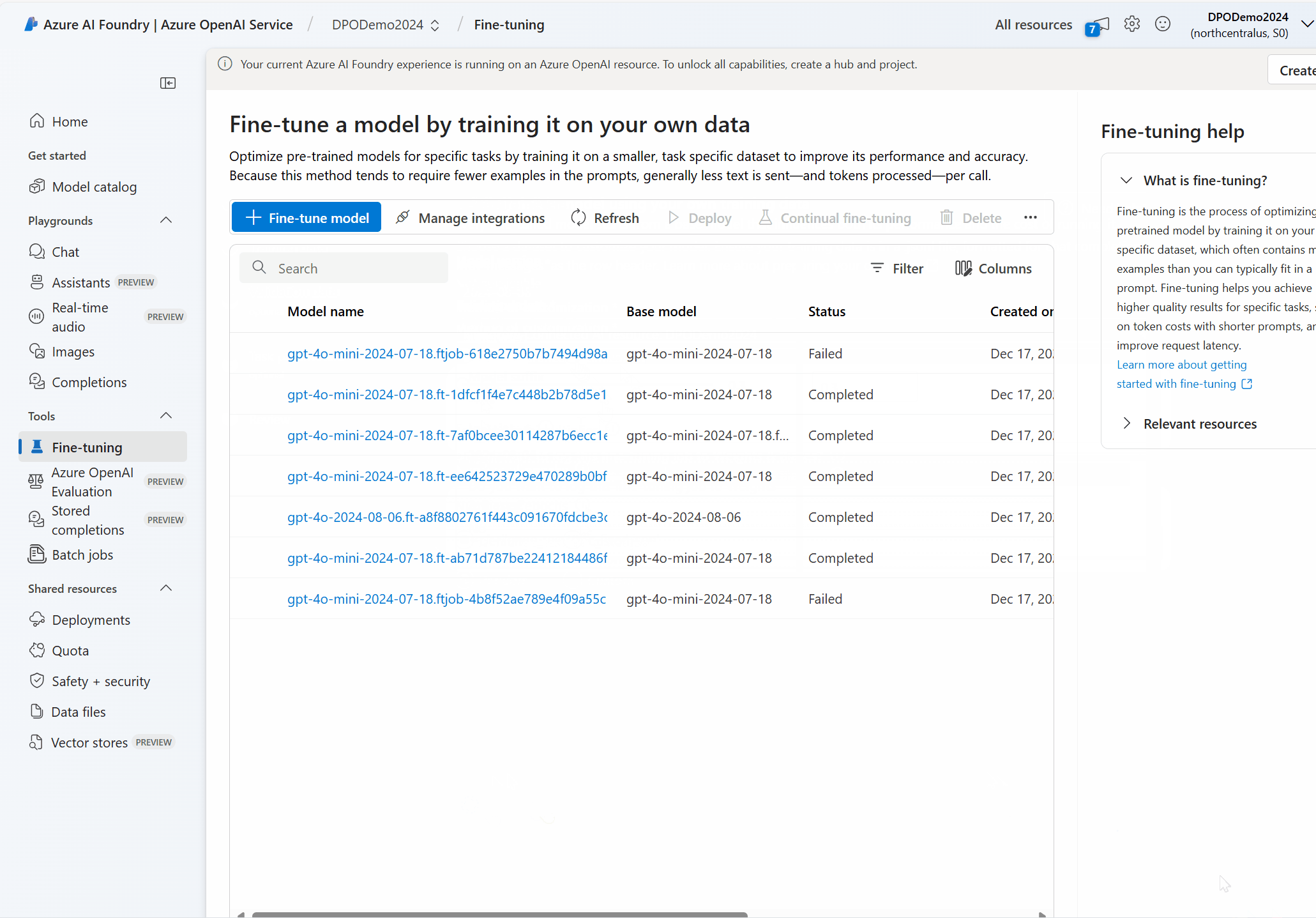
- Prepare
jsonlconjuntos de dados no formato de preferência. - Selecione o modelo e, em seguida, selecione o método de personalização Direct Preference Optimization.
- Carregar conjuntos de dados – formação e validação. Pré-visualização conforme necessário.
- Selecione hiperparâmetros, os padrões são recomendados para experimentação inicial.
- Revise as seleções e crie um trabalho de ajuste fino.
Resolução de Problemas
Como faço para ativar o ajuste fino?
Para acessar com sucesso o ajuste fino, você precisa do Cognitive Services OpenAI Contributor atribuído. Mesmo alguém com permissões de Administrador de Serviço de alto nível ainda precisaria dessa conta explicitamente definida para acessar o ajuste fino. Para obter mais informações, consulte as diretrizes de controle de acesso baseado em função.
Porque é que o meu carregamento falhou?
Se o carregamento do arquivo falhar no portal do Azure AI Foundry, você poderá exibir a mensagem de erro em Arquivos de dados no portal do Azure AI Foundry. Passe o mouse sobre onde está escrito "erro" (na coluna de status) e uma explicação da falha será exibida.

Meu modelo ajustado não parece ter melhorado
Mensagem do sistema ausente: Você precisa fornecer uma mensagem do sistema quando ajustar, você vai querer fornecer essa mesma mensagem do sistema quando usar o modelo ajustado. Se você fornecer uma mensagem de sistema diferente, poderá ver resultados diferentes dos que você ajustou.
Dados insuficientes: enquanto 10 é o mínimo para o pipeline ser executado, você precisa de centenas a milhares de pontos de dados para ensinar ao modelo uma nova habilidade. Poucos pontos de dados correm o risco de sobreajuste e má generalização. Seu modelo ajustado pode ter um bom desempenho nos dados de treinamento, mas mal em outros dados porque memorizou os exemplos de treinamento em vez de padrões de aprendizagem. Para obter melhores resultados, planeje preparar um conjunto de dados com centenas ou milhares de pontos de dados.
Dados incorretos: um conjunto de dados mal organizado ou não representativo produzirá um modelo de baixa qualidade. Seu modelo pode aprender padrões imprecisos ou tendenciosos do seu conjunto de dados. Por exemplo, se você estiver treinando um chatbot para atendimento ao cliente, mas fornecer apenas dados de treinamento para um cenário (por exemplo, devoluções de itens), ele não saberá como responder a outros cenários. Ou, se seus dados de treinamento forem ruins (contiverem respostas incorretas), seu modelo aprenderá a fornecer resultados incorretos.
Ajuste fino com visão
O que fazer se as suas imagens forem ignoradas
Suas imagens podem ser ignoradas pelos seguintes motivos:
- contém CAPTCHAs
- contém pessoas
- contém rostos
Remova a imagem. Por enquanto, não podemos ajustar modelos com imagens que contenham essas entidades.
Problemas comuns
| Problema | Razão/Solução |
|---|---|
| Imagens ignoradas | As imagens podem ser ignoradas pelos seguintes motivos: contém CAPTCHAs, pessoas ou rostos. Remova a imagem. Por enquanto, não podemos ajustar modelos com imagens que contenham essas entidades. |
| URL inacessível | Verifique se o URL da imagem está acessível publicamente. |
| Imagem demasiado grande | Verifique se as suas imagens estão dentro dos nossos limites de tamanho do conjunto de dados. |
| Formato de imagem inválido | Verifique se as suas imagens se enquadram no nosso formato de conjunto de dados. |
Como carregar ficheiros grandes
Seus arquivos de treinamento podem ficar muito grandes. Você pode carregar arquivos de até 8 GB em várias partes usando a API de uploads, em oposição à API de arquivos, que só permite uploads de arquivos de até 512 MB.
Redução dos custos de formação
Se você definir o parâmetro de detalhe de uma imagem como baixo, a imagem será redimensionada para 512 por 512 pixels e será representada apenas por 85 tokens, independentemente de seu tamanho. Isto reduzirá o custo da formação.
{
"type": "image_url",
"image_url": {
"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png",
"detail": "low"
}
}
Outras considerações para o ajuste fino da visão
Para controlar a fidelidade da compreensão da imagem, defina o parâmetro de detalhe de image_url , lowhighou auto para cada imagem. Isso também afetará o número de tokens por imagem que o modelo vê durante o tempo de treinamento e afetará o custo do treinamento.
Próximos passos
- Explore os recursos de ajuste fino no tutorial de ajuste fino do Azure OpenAI.
- Revisar a disponibilidade regional do modelo de ajuste fino
- Saiba mais sobre as cotas do Azure OpenAI