Avaliação do Azure OpenAI (Pré-visualização)
A avaliação de grandes modelos linguísticos é um passo crítico para medir o seu desempenho em várias tarefas e dimensões. Isto é especialmente importante para modelos ajustados, onde a avaliação dos ganhos (ou perdas) de desempenho da formação é crucial. Avaliações completas podem ajudar a entender como diferentes versões do modelo podem afetar seu aplicativo ou cenário.
A avaliação do Azure OpenAI permite que os desenvolvedores criem execuções de avaliação para testar em relação aos pares de entrada/saída esperados, avaliando o desempenho do modelo em métricas-chave, como precisão, confiabilidade e desempenho geral.
Apoio às avaliações
Disponibilidade regional
- E.U.A. Leste 2
- E.U.A. Centro-Norte
- Suécia Central
- Oeste da Suíça
Tipos de implantação suportados
- Standard
- Norma global
- Padrão de zona de dados
- Gerenciado provisionado
- Gerenciado por provisionamento global
- Zona de dados provisionada-gerenciada
Pipeline de avaliação
Dados de teste
Você precisa montar um conjunto de dados de verdade básica contra o qual deseja testar. A criação de conjuntos de dados normalmente é um processo iterativo que garante que suas avaliações permaneçam relevantes para seus cenários ao longo do tempo. Esse conjunto de dados de verdade básica é normalmente feito à mão e representa o comportamento esperado do seu modelo. O conjunto de dados também é rotulado e inclui as respostas esperadas.
Nota
Alguns testes de avaliação, como Sentiment e JSON ou XML válidos, não exigem dados de verdade básica.
Sua fonte de dados precisa estar no formato JSONL. Abaixo estão dois exemplos dos conjuntos de dados de avaliação JSONL:
Formato da avaliação
{"question": "Find the degree for the given field extension Q(sqrt(2), sqrt(3), sqrt(18)) over Q.", "subject": "abstract_algebra", "A": "0", "B": "4", "C": "2", "D": "6", "answer": "B", "completion": "B"}
{"question": "Let p = (1, 2, 5, 4)(2, 3) in S_5 . Find the index of <p> in S_5.", "subject": "abstract_algebra", "A": "8", "B": "2", "C": "24", "D": "120", "answer": "C", "completion": "C"}
{"question": "Find all zeros in the indicated finite field of the given polynomial with coefficients in that field. x^5 + 3x^3 + x^2 + 2x in Z_5", "subject": "abstract_algebra", "A": "0", "B": "1", "C": "0,1", "D": "0,4", "answer": "D", "completion": "D"}
Quando você carregar e selecionar seu arquivo de avaliação, uma visualização das três primeiras linhas será retornada:


Você pode escolher qualquer conjunto de dados existente carregado anteriormente ou carregar um novo conjunto de dados.
Criar respostas (opcional)
O prompt que você usa em sua avaliação deve corresponder ao prompt que você planeja usar na produção. Esses prompts fornecem as instruções para o modelo a seguir. Semelhante às experiências de playground, você pode criar várias entradas para incluir exemplos de poucas fotos em seu prompt. Para obter mais informações, consulte técnicas de engenharia de prompt para obter detalhes sobre algumas técnicas avançadas em prompt design e prompt engineering.
Você pode fazer referência aos dados de entrada dentro dos prompts usando o {{input.column_name}} formato, onde column_name corresponde aos nomes das colunas no arquivo de entrada.
Os resultados gerados durante a avaliação serão referenciados nas etapas subsequentes usando o {{sample.output_text}} formato.
Nota
Você precisa usar chaves duplas para garantir que você faça referência aos seus dados corretamente.
Implementação do modelo
Como parte da criação de avaliações, você escolherá quais modelos usar ao gerar respostas (opcional), bem como quais modelos usar ao classificar modelos com critérios de teste específicos.
No Azure OpenAI, você atribuirá implantações de modelo específicas para usar como parte de suas avaliações. Você pode comparar várias implantações de modelo em uma única execução de avaliação.
Você pode avaliar implantações de modelo base ou ajustadas. As implantações disponíveis em sua lista dependem daquelas que você criou em seu recurso do Azure OpenAI. Se não conseguir encontrar a implementação pretendida, pode criar uma nova a partir da página Avaliação do Azure OpenAI.
Critérios de ensaio
Os critérios de teste são usados para avaliar a eficácia de cada saída gerada pelo modelo de destino. Esses testes comparam os dados de entrada com os dados de saída para garantir a consistência. Você tem a flexibilidade de configurar diferentes critérios para testar e medir a qualidade e a relevância da saída em diferentes níveis.

Introdução
Selecione a Avaliação do Azure OpenAI (PREVIEW) no portal do Azure AI Foundry. Para ver essa exibição como uma opção, talvez seja necessário selecionar primeiro um recurso existente do Azure OpenAI em uma região com suporte.
Selecionar Nova avaliação
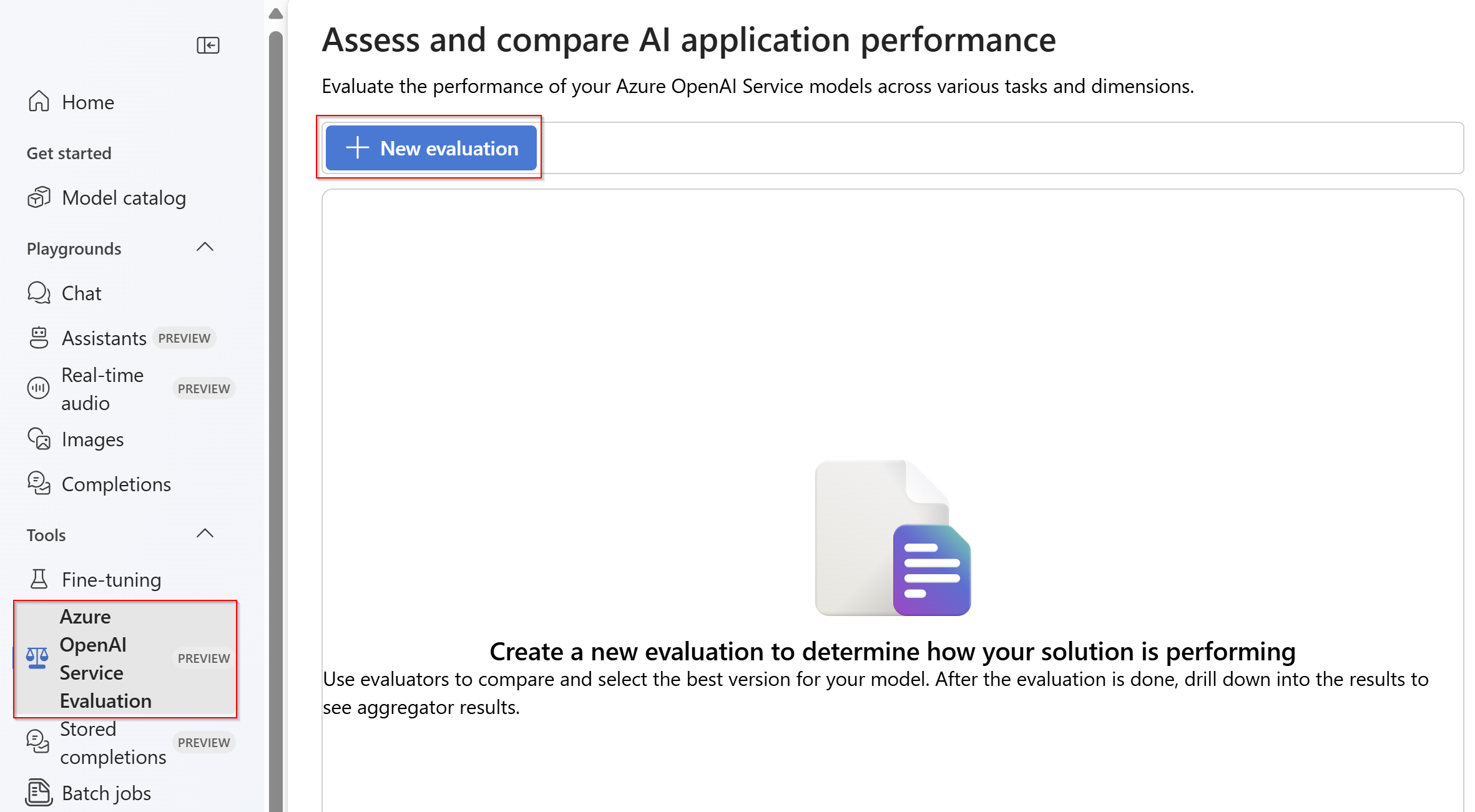
Insira um nome da sua avaliação. Por padrão, um nome aleatório é gerado automaticamente, a menos que você o edite e substitua. Selecione Carregar novo conjunto de dados.
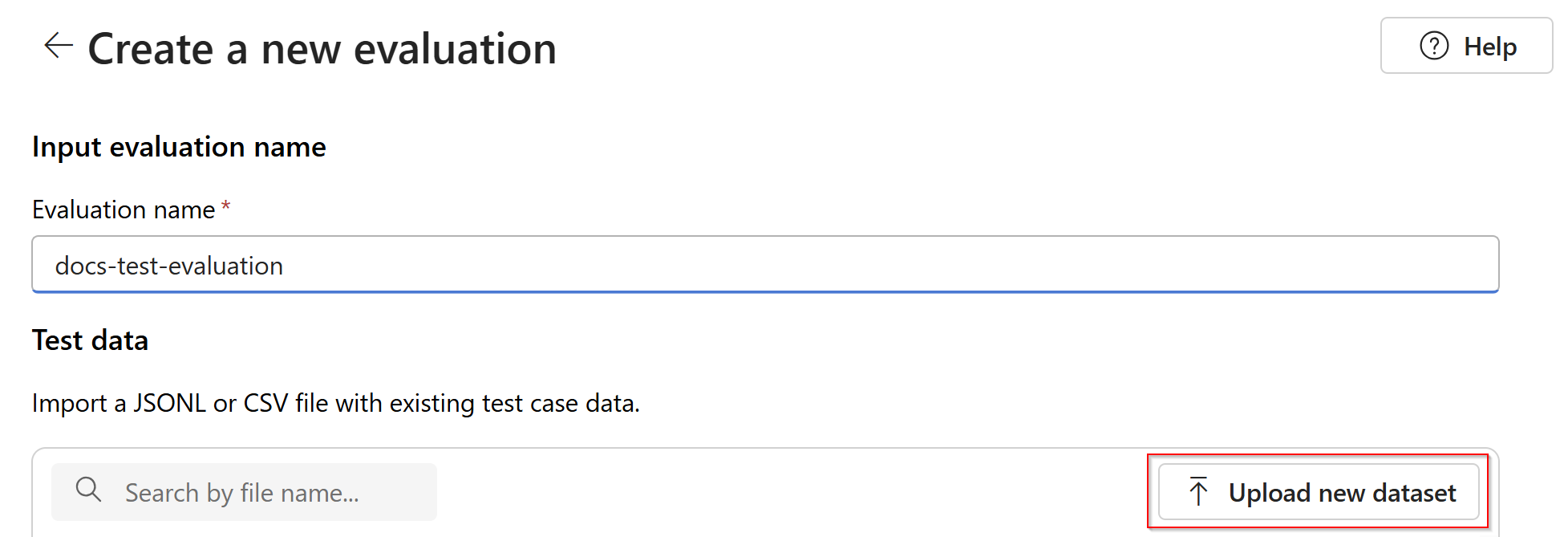
Selecione a sua avaliação que será no
.jsonlformato. Se você precisar de um arquivo de teste de exemplo, você pode salvar essas 10 linhas em um arquivo chamadoeval-test.jsonl:{"input": [{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."}, {"role": "user", "content": "Tokenization is a key step in preprocessing for natural language processing, involving the division of text into smaller components called tokens. These can be words, subwords, or characters, depending on the method chosen. Word tokenization divides text at word boundaries, while subword techniques like Byte Pair Encoding (BPE) or WordPiece can manage unknown words by breaking them into subunits. Character tokenization splits text into individual characters, useful for multiple languages and misspellings. The tokenization method chosen greatly affects model performance and its capacity to handle various languages and vocabularies."}], "output": "Tokenization divides text into smaller units (tokens) for NLP applications, using word, subword (e.g., BPE), or character methods. Each has unique benefits, impacting model performance and language processing capabilities."} {"input": [{"role": "system", "content": "Create a comprehensive yet concise summary that captures the essential technical details and significance of the topic."}, {"role": "user", "content": "Self-attention mechanisms are vital in modern transformer models, allowing them to evaluate the relevance of different parts of an input sequence when processing each element. In self-attention, each position in a sequence learns to focus on all other positions, forming a weighted sum of their values. Attention weights are derived using queries, keys, and values, with compatibility between a query and key determining attention to each value. This mechanism enables capturing long-range dependencies and relationships within a sequence, making it effective for tasks needing context understanding and inter-part relationships."}], "output": "Self-attention is crucial in transformers, enabling each sequence position to evaluate and collect data from all others. It uses queries, keys, and values for attention weights, effectively capturing long-range dependencies and contextual links."} {"input": [{"role": "system", "content": "Synthesize the technical information into a brief, accurate summary that maintains the core concepts and their significance."}, {"role": "user", "content": "The transformer architecture significantly changed natural language processing by introducing a new method for sequence processing. Unlike recurrent neural networks, transformers process whole sequences at once using self-attention. The architecture consists of an encoder and decoder, each with multiple layers of multi-head attention, feed-forward networks, and normalization layers. The encoder processes the input sequence, and the decoder produces the output sequence. Positional encodings are added to retain sequence order information since the model lacks inherent sequence position awareness. This architecture underlies many leading language models like BERT and GPT."}], "output": "Transformers are a transformative neural architecture processing sequences with self-attention instead of recurrence. Their encoder-decoder design, with multi-head attention and position encodings, is fundamental to modern language models like BERT and GPT."} {"input": [{"role": "system", "content": "Distill the technical content into a clear, concise summary that preserves the most important concepts and their practical applications."}, {"role": "user", "content": "Cosine similarity is a metric for measuring similarity between vectors by calculating the cosine of the angle between them. The outcome ranges from -1 to 1, with 1 indicating identical orientation, 0 orthogonality, and -1 opposite orientation. In machine learning and NLP, cosine similarity is useful for comparing document vectors, word embeddings, or any high-dimensional representations. It's often preferred over Euclidean distance because it's invariant to vector magnitude, focusing instead on orientation. This makes it particularly useful for comparing documents or embeddings of various lengths or scales."}], "output": "Cosine similarity evaluates vector similarity by computing their angle's cosine, with values from -1 to 1. It's widely used in ML and NLP for comparing document vectors and embeddings due to its magnitude-invariant nature."} {"input": [{"role": "system", "content": "Provide a succinct summary that captures the key technical concepts and their relationships while maintaining clarity and accuracy."}, {"role": "user", "content": "Neural network activation functions are crucial for introducing non-linearity to deep learning models. Commonly used activation functions include ReLU (Rectified Linear Unit), which outputs the input directly if positive and zero otherwise, sigmoid, which compresses values between 0 and 1, and tanh, which normalizes values between -1 and 1. Each function has specific benefits and applications: ReLU avoids vanishing gradients and enables sparse activation, sigmoid is useful for binary classification, and tanh is often used in hidden layers for its zero-centered output. The activation function choice greatly affects model training dynamics and ultimate performance."}], "output": "Activation functions introduce non-linearity to neural networks, with ReLU, sigmoid, and tanh being the most common. Each serves distinct purposes: ReLU prevents vanishing gradients, sigmoid is suitable for binary classification, and tanh offers zero-centered output, all affecting model performance differently."} {"input": [{"role": "system", "content": "Create a focused summary that emphasizes the main technical concepts and their practical implications while maintaining accuracy."}, {"role": "user", "content": "Batch normalization is a technique that stabilizes and accelerates deep neural network training by normalizing each layer's inputs. It normalizes activations using the mean and variance computed over the current data batch. This normalization reduces internal covariate shift, where the input distribution changes during training. Batch normalization includes learnable parameters (gamma and beta) allowing the network to reverse normalization if necessary. Benefits include enabling higher learning rates, lessening the importance of precise parameter initialization, and serving as a regularizer, potentially removing the need for dropout."}], "output": "Batch normalization stabilizes neural network training by normalizing layer inputs using batch statistics. It addresses internal covariate shift with learnable parameters, allowing higher learning rates and improved training dynamics, while offering regularization benefits."} {"input": [{"role": "system", "content": "Summarize the technical content while preserving the essential concepts and their interconnections, ensuring clarity and precision."}, {"role": "user", "content": "Gradient descent optimization algorithms are foundational to training machine learning models. The basic version updates parameters in the steepest descent direction of the loss function. Variants like Stochastic Gradient Descent (SGD) use random samples to estimate gradients, enhancing computational efficiency. Advanced optimizers like Adam combine momentum (helping overcome local minima) and RMSprop (adapting learning rates for each parameter). These optimizers maintain running averages of gradients and their squares, enabling adaptive learning rates and more efficient training. The optimizer choice can significantly influence model convergence speed and final performance."}], "output": "Gradient descent algorithms optimize ML models by updating parameters based on loss gradients. Variants like SGD use sampling for efficiency, while advanced optimizers like Adam combine momentum with adaptive learning rates for improved training performance."} {"input": [{"role": "system", "content": "Deliver a concise yet comprehensive summary that highlights the key technical aspects and their practical significance."}, {"role": "user", "content": "Cross-validation is a resampling method used to evaluate machine learning models on limited data. The most common form, k-fold cross-validation, involves dividing the dataset into k equal parts, training the model on k-1 folds while validating on the remaining fold, and rotating through all combinations. This provides a more robust model performance assessment than a single train-test split, helping detect overfitting and estimate model generalization to unseen data. Variations include stratified k-fold (maintaining class distribution), leave-one-out (k equals dataset size), and time series cross-validation for temporal data."}], "output": "Cross-validation evaluates ML models by training and testing on different data splits, typically using k-fold methodology. This approach offers better performance assessment than single splits, with variations for different data types and requirements."} {"input": [{"role": "system", "content": "Generate a clear and focused summary that captures the essential technical details while maintaining their relationships and significance."}, {"role": "user", "content": "Transfer learning is a machine learning method where a model developed for one task is reused as the starting point for a model on a second task. This approach is powerful in deep learning, where pre-trained models on large datasets (like ImageNet for computer vision or BERT for NLP) are fine-tuned on specific downstream tasks. Transfer learning reduces the need for large amounts of task-specific training data and computational resources, as the model has already learned useful features from the source domain. Common strategies include feature extraction (freezing pre-trained layers) and fine-tuning (updating all or some pre-trained weights)."}], "output": "Transfer learning reuses models trained on one task for different tasks, particularly effective in deep learning. It leverages pre-trained models through feature extraction or fine-tuning, reducing data and computational needs for new tasks."} {"input": [{"role": "system", "content": "Provide a precise and informative summary that distills the key technical concepts while maintaining their relationships and practical importance."}, {"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random data subsets), boosting (sequentially training models to correct earlier errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree correcting the errors of previous ones. These methods often outperform single models by reducing overfitting and variance while capturing different data aspects."}], "output": "Ensemble methods enhance prediction accuracy by combining multiple models through techniques like bagging, boosting, and stacking. Popular implementations include Random Forests (using multiple trees with random features) and Gradient Boosting (sequential error correction), offering better performance than single models."}Você verá as três primeiras linhas do arquivo como uma visualização:
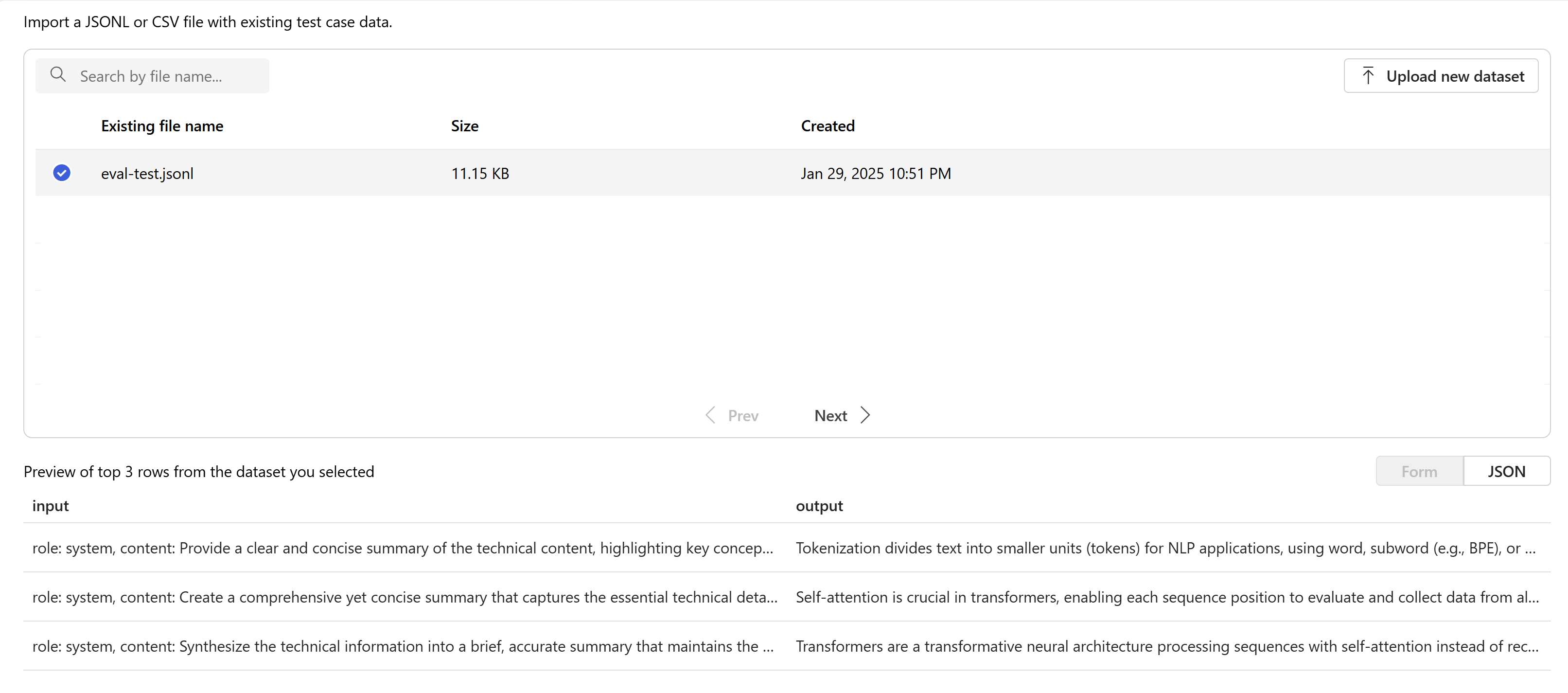
Em Respostas, selecione o botão Criar. Selecione
{{item.input}}na lista suspensa Criar com um modelo . Isso injetará os campos de entrada do nosso arquivo de avaliação em prompts individuais para uma nova execução de modelo que queremos comparar com nosso conjunto de dados de avaliação. O modelo pegará essa entrada e gerará suas próprias saídas exclusivas que, neste caso, serão armazenadas em uma variável chamada{{sample.output_text}}. Em seguida, usaremos esse texto de saída de exemplo mais tarde como parte de nossos critérios de teste. Como alternativa, você pode fornecer sua própria mensagem personalizada do sistema e exemplos de mensagens individuais manualmente.Selecione o modelo que deseja gerar respostas com base na sua avaliação. Se não tiver um modelo, pode criar um. Para este exemplo, estamos usando uma implantação padrão do
gpt-4o-mini.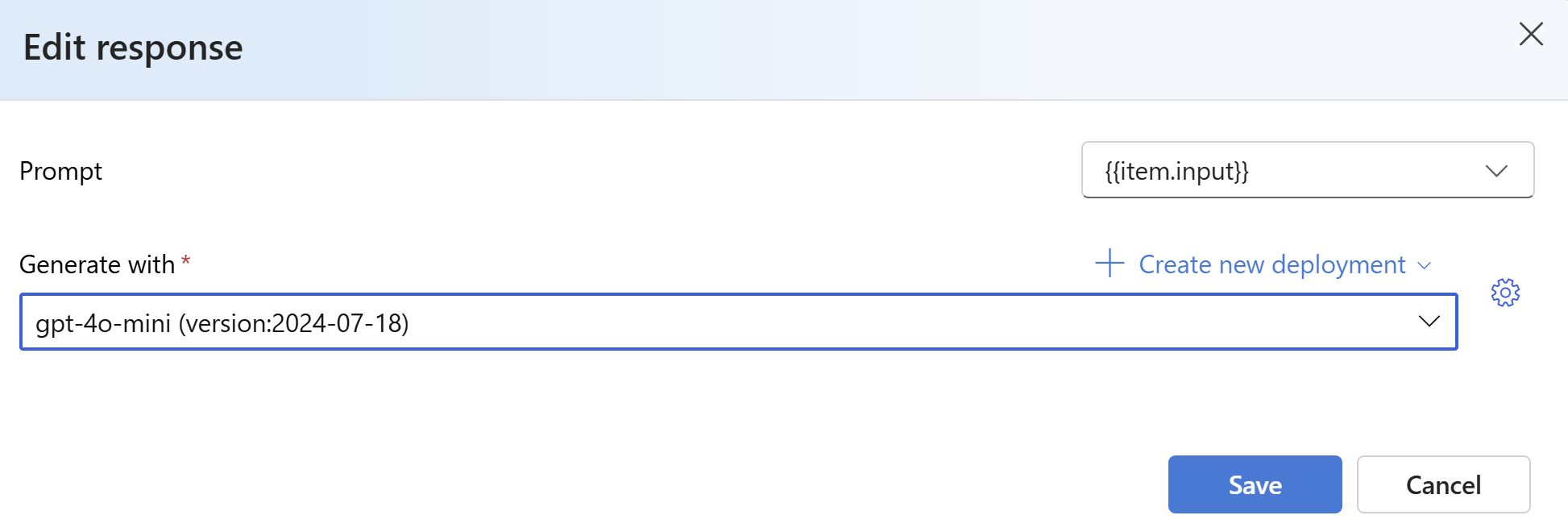
O símbolo settings/sprocket controla os parâmetros básicos que são passados para o modelo. Apenas os seguintes parâmetros são suportados neste momento:




- Temperatura
- Comprimento máximo
- Topo P
Atualmente, o comprimento máximo está limitado a 2048, independentemente do modelo selecionado.
Selecione Adicionar critérios de teste, selecione Adicionar.
Selecione Semelhança> semântica em Comparar adicionar
{{item.output}}em Com adicionar{{sample.output_text}}. Isso pegará a saída de referência original do seu arquivo de avaliação.jsonle a comparará com a saída que será gerada, fornecendo os prompts do modelo com base no seu{{item.input}}.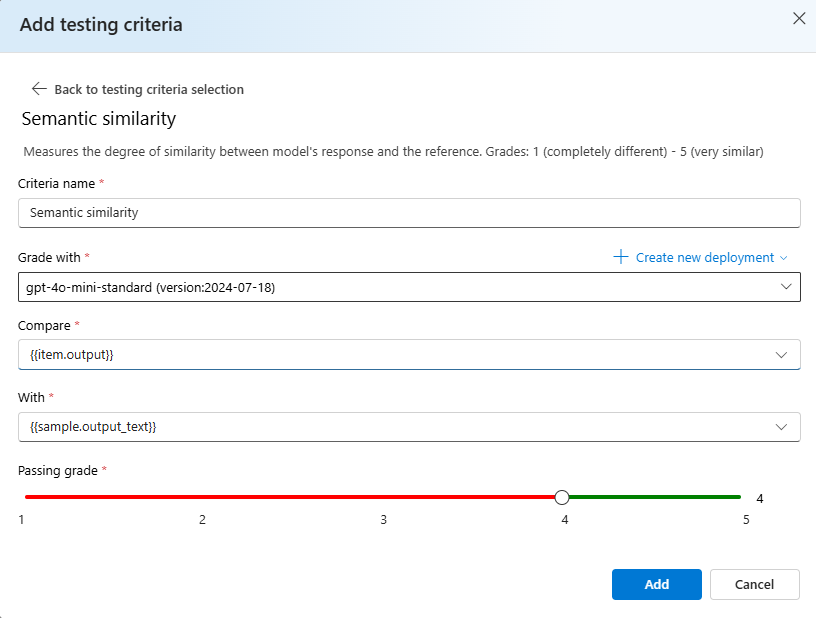
Selecione Adicionar> neste ponto, você pode adicionar critérios de teste adicionais ou selecionar Criar para iniciar a execução do trabalho de avaliação.
Depois de selecionar Criar , você será direcionado para uma página de status do seu trabalho de avaliação.
Uma vez que seu trabalho de avaliação tenha sido criado, você pode selecioná-lo para ver todos os detalhes do trabalho:
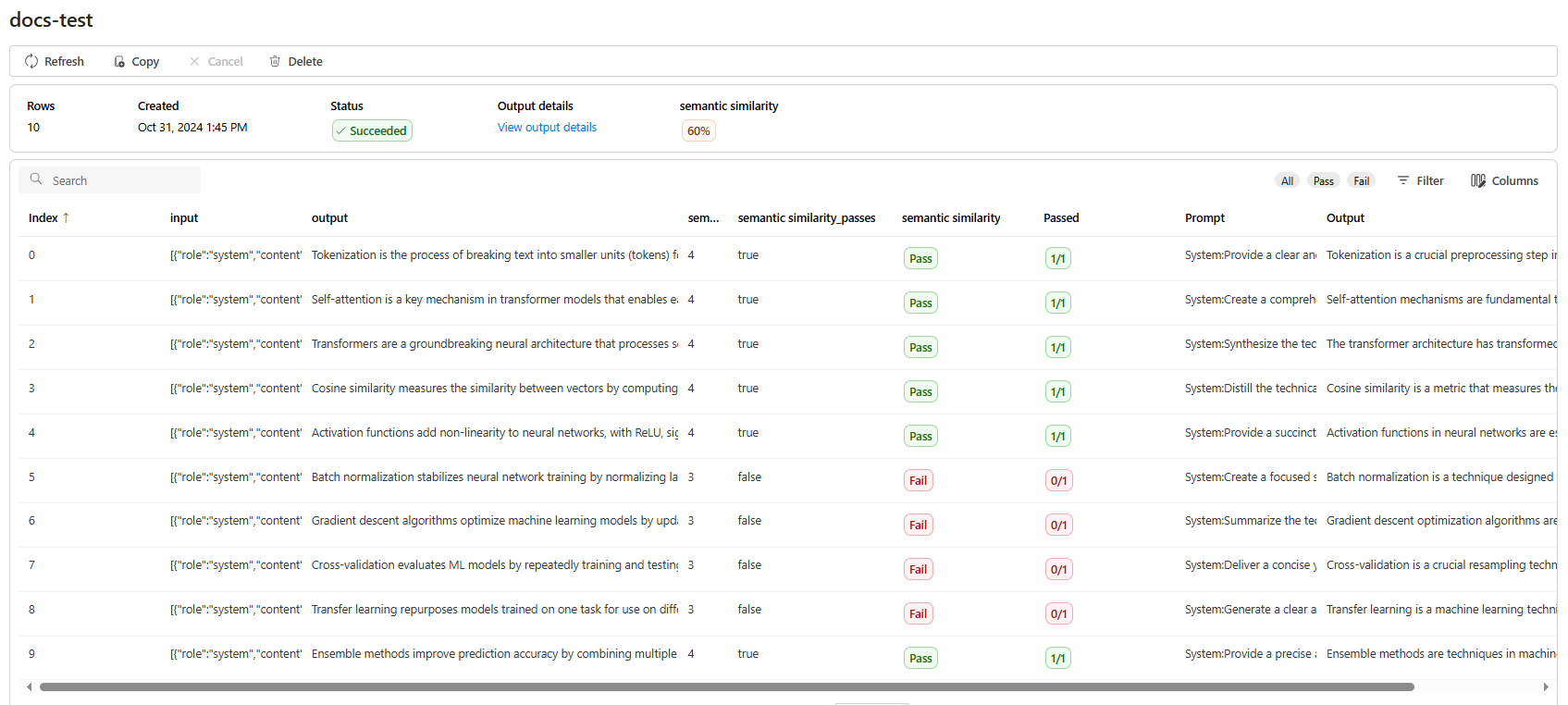
Para semelhança semântica, Exibir detalhes de saída contém uma representação JSON que você pode copiar/colar de seus testes aprovados.
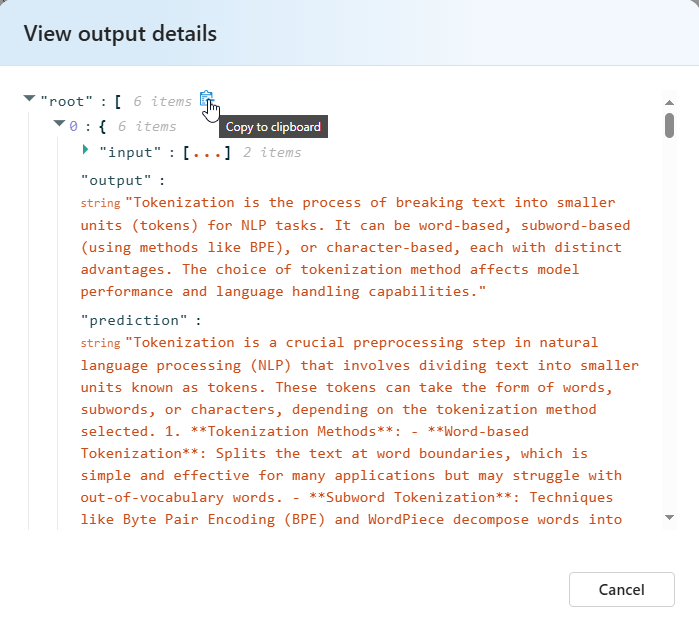




Detalhes dos critérios de teste
O Azure OpenAI Evaluation oferece várias opções de critérios de teste. A seção abaixo fornece detalhes adicionais sobre cada opção.
Factualidade
Avalia a exatidão factual de uma resposta enviada, comparando-a com uma resposta de um perito.
A factualidade avalia a exatidão factual de uma resposta apresentada, comparando-a com uma resposta de um perito. Utilizando um prompt detalhado da cadeia de pensamento (CoT), o classificador determina se a resposta enviada é consistente com, um subconjunto de, um superconjunto de, ou em conflito com a resposta do especialista. Desconsidera diferenças de estilo, gramática ou pontuação, concentrando-se apenas no conteúdo factual. A factualidade pode ser útil em muitos cenários, incluindo, mas não limitado a, verificação de conteúdo e ferramentas educacionais que garantem a precisão das respostas fornecidas pela IA.

Você pode exibir o texto do prompt usado como parte desse critério de teste selecionando a lista suspensa ao lado do prompt. O texto atual do prompt é:
Prompt
You are comparing a submitted answer to an expert answer on a given question.
Here is the data:
[BEGIN DATA]
************
[Question]: {input}
************
[Expert]: {ideal}
************
[Submission]: {completion}
************
[END DATA]
Compare the factual content of the submitted answer with the expert answer. Ignore any differences in style, grammar, or punctuation.
The submitted answer may either be a subset or superset of the expert answer, or it may conflict with it. Determine which case applies. Answer the question by selecting one of the following options:
(A) The submitted answer is a subset of the expert answer and is fully consistent with it.
(B) The submitted answer is a superset of the expert answer and is fully consistent with it.
(C) The submitted answer contains all the same details as the expert answer.
(D) There is a disagreement between the submitted answer and the expert answer.
(E) The answers differ, but these differences don't matter from the perspective of factuality.
Semelhança semântica
Mede o grau de semelhança entre a resposta do modelo e a referência.
Grades: 1 (completely different) - 5 (very similar).

Sentimento
Tenta identificar o tom emocional da saída.

Você pode exibir o texto do prompt usado como parte desse critério de teste selecionando a lista suspensa ao lado do prompt. O texto atual do prompt é:
Prompt
You will be presented with a text generated by a large language model. Your job is to rate the sentiment of the text. Your options are:
A) Positive
B) Neutral
C) Negative
D) Unsure
[BEGIN TEXT]
***
[{text}]
***
[END TEXT]
First, write out in a step by step manner your reasoning about the answer to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character (without quotes or punctuation) on its own line corresponding to the correct answer. At the end, repeat just the letter again by itself on a new line
Verificação de cadeia de caracteres
Verifica se a saída corresponde exatamente à cadeia de caracteres esperada.

A verificação de cadeia de caracteres executa várias operações binárias em duas variáveis de cadeia de caracteres, permitindo diversos critérios de avaliação. Ajuda a verificar várias relações de cadeia de caracteres, incluindo igualdade, contenção e padrões específicos. Este avaliador permite comparações que diferenciam maiúsculas de minúsculas ou minúsculas. Ele também fornece notas especificadas para resultados verdadeiros ou falsos, permitindo resultados de avaliação personalizados com base no resultado da comparação. Eis o tipo de operações suportadas:
-
equals: Verifica se a string de saída é exatamente igual à string de avaliação. -
contains: Verifica se a string de avaliação é uma substring da string de saída. -
starts-with: Verifica se a cadeia de caracteres de saída começa com a cadeia de caracteres de avaliação. -
ends-with: Verifica se a cadeia de caracteres de saída termina com a cadeia de caracteres de avaliação.
Nota
Ao definir certos parâmetros em seus critérios de teste, você tem a opção de escolher entre a variável e o modelo. Selecione a variável se quiser fazer referência a uma coluna nos dados de entrada. Escolha o modelo se quiser fornecer uma cadeia de caracteres fixa.
JSON ou XML válidos
Verifica se a saída é JSON ou XML válido.

Corresponde ao esquema
Garante que a saída siga a estrutura especificada.

Correspondência de critérios
Avalie se a resposta do modelo corresponde aos seus critérios. Classificação: Aprovado ou Reprovado.

Você pode exibir o texto do prompt usado como parte desse critério de teste selecionando a lista suspensa ao lado do prompt. O texto atual do prompt é:
Prompt
Your job is to assess the final response of an assistant based on conversation history and provided criteria for what makes a good response from the assistant. Here is the data:
[BEGIN DATA]
***
[Conversation]: {conversation}
***
[Response]: {response}
***
[Criteria]: {criteria}
***
[END DATA]
Does the response meet the criteria? First, write out in a step by step manner your reasoning about the criteria to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character "Y" or "N" (without quotes or punctuation) on its own line corresponding to the correct answer. "Y" for yes if the response meets the criteria, and "N" for no if it does not. At the end, repeat just the letter again by itself on a new line.
Reasoning:
Qualidade do texto
Avalie a qualidade do texto comparando com o texto de referência.

Resumo:
- Pontuação BLEU: Avalia a qualidade do texto gerado comparando-o com uma ou mais traduções de referência de alta qualidade usando a pontuação BLEU.
- ROUGE Score: Avalia a qualidade do texto gerado comparando-o com resumos de referência usando pontuações ROUGE.
- Cosseno: Também conhecido como semelhança cosseno mede o quão estreitamente duas incorporações de texto - como saídas de modelo e textos de referência - se alinham em significado, ajudando a avaliar a semelhança semântica entre eles. Isto é feito medindo a sua distância no espaço vetorial.
Detalhes:
A pontuação BLEU (BiLingual Evaluation Understudy) é comumente usada no processamento de linguagem natural (PNL) e tradução automática. É amplamente utilizado em casos de uso de resumo de texto e geração de texto. Ele avalia o quão próximo o texto gerado corresponde ao texto de referência. A pontuação da BLEU varia de 0 a 1, com pontuações mais altas indicando melhor qualidade.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) é um conjunto de métricas usadas para avaliar a sumarização automática e a tradução automática. Mede a sobreposição entre o texto gerado e os resumos de referência. O ROUGE centra-se em medidas orientadas para a recolha para avaliar até que ponto o texto gerado abrange o texto de referência. A pontuação ROUGE fornece várias métricas, incluindo: • ROUGE-1: Sobreposição de unigramas (palavras únicas) entre o texto gerado e o texto de referência. • ROUGE-2: Sobreposição de bigramas (duas palavras consecutivas) entre o texto gerado e o texto de referência. • ROUGE-3: Sobreposição de trigramas (três palavras consecutivas) entre o texto gerado e o texto de referência. • ROUGE-4: Sobreposição de quatro gramas (quatro palavras consecutivas) entre o texto gerado e o texto de referência. • ROUGE-5: Sobreposição de cinco gramas (cinco palavras consecutivas) entre o texto gerado e o texto de referência. • ROUGE-L: Sobreposição de L-gramas (L palavras consecutivas) entre o texto gerado e o texto de referência. O resumo de texto e a comparação de documentos estão entre os casos de uso ideais para o ROUGE, particularmente em cenários onde a coerência e a relevância do texto são críticas.
A semelhança cosina mede o quão estreitamente duas incorporações de texto — como saídas de modelo e textos de referência — se alinham em significado, ajudando a avaliar a semelhança semântica entre elas. Assim como outros avaliadores baseados em modelos, você precisa fornecer uma implantação de modelo usando para avaliação.
Importante
Apenas modelos de incorporação são suportados para este avaliador:
text-embedding-3-smalltext-embedding-3-largetext-embedding-ada-002
Prompt personalizado
Usa o modelo para classificar a saída em um conjunto de rótulos especificados. Este avaliador usa um prompt personalizado que você precisará definir.
